はじめに
この記事では、Tensorflow Hubに公開されている 多言語Universal Sentence Encoder を試してみます。
Universal Sentence Encoderとは
Transformerを自然言語処理の様々なデータセットを使ってマルチタスク学習させて得られた文表現ベクトルのエンコーダーです。今回使うのは多言語バージョンで、英語、フランス語、ドイツ語、スペイン語、イタリア語、中国語、韓国語、日本語のタスクで学習されたものです。
文の類似度の可視化
いくつかの文章を入力して文表現ベクトルを作成し、互いに内積を取ることで各入力文がどれくらい近いかを測ります。結果はヒートマップで可視化します。
スクリプト
Googleが公開しているColabを参考にしたコードです。実行した時にmatplotlibとseabornの文字化けが発生する場合があります。そのときは例えばこの記事に解決法が書いてあります。
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import tf_sentencepiece
module_url = "https://tfhub.dev/google/universal-sentence-encoder-xling-many/1"
embed = hub.Module(module_url)
def plot_similarity(labels, features, rotation):
corr = np.inner(features, features)
sns.set(font_scale=1.2)
g = sns.heatmap(
corr,
xticklabels=labels,
yticklabels=labels,
vmin=0,
vmax=1,
cmap="YlOrRd")
g.set_xticklabels(labels, rotation=rotation)
g.set_title("Semantic Textual Similarity")
plt.show()
def run_and_plot(session_, input_tensor_, messages_, encoding_tensor):
message_embeddings_ = session_.run(
encoding_tensor, feed_dict={input_tensor_: messages_})
plot_similarity(messages_, message_embeddings_, 90)
messages = [
# Smartphones
"I like my smart phone.",
"スマホが好きです。",
"私のスマートフォンは品質が高いです",
"キミのスマホかっこいいね!",
# Weather
"It will rain tomorrow.",
"明日は雨かな?",
"台風の季節ですね。",
"地球温暖化の影響が現れ始めているのかな",
# Food and health
"りんごを一日一個食べると医者いらずですよ",
"イチゴが食べたい",
"ダイエットに効く食品を教えて?",
# Asking about age
"How old are you?",
"何歳ですか",
"いくつですか?",
]
similarity_input_placeholder = tf.placeholder(tf.string, shape=(None))
similarity_message_encodings = embed(similarity_input_placeholder)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
run_and_plot(session, similarity_input_placeholder, messages,
similarity_message_encodings)
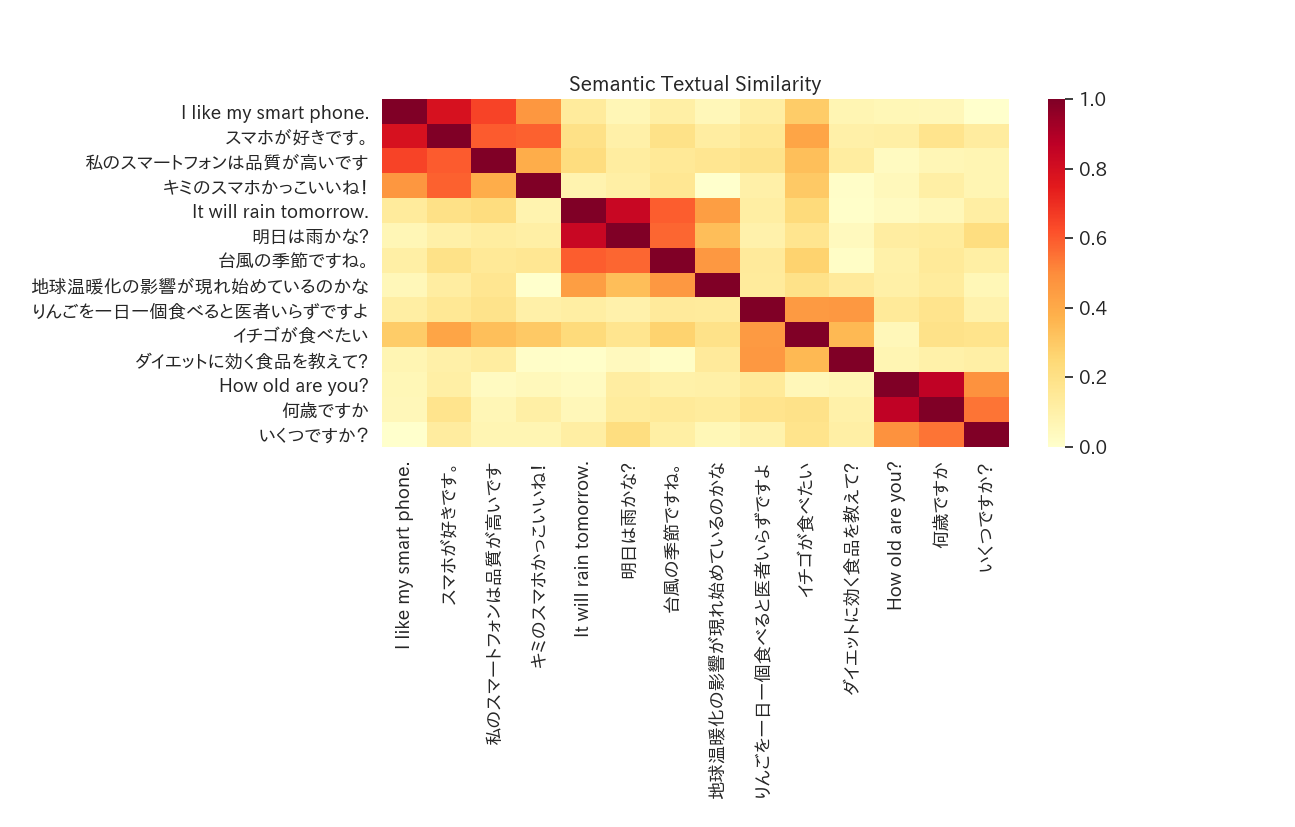
実行結果
言語によらず似た意味の文は似た表現になっていることがわかります。
感想
このエンコーダーを特徴量作成に使えば、英語の大規模なデータセットを使って学習し、日本語や他の言語で推論することもできそうです。