やりたいこと
以下のテキストでは、AIを用いた画像認識により対象物を分類し、ロボットアームにより仕分けを行っています。
・DOBOT Magician AIx画像認識xロボットアーム制御
前回の記事で触れ合っている対象物を分離した状態で認識し、仕分けるようにしました。
対象物が1種類だけの場合は、これだけでも問題ありませんが、今回は複数種類を判別して、仕分けるようにしたいと思います。
できたもの
手順
学習データの収集
前回の記事で作成したプログラムを使用して、学習データを集めます。手順はテキストの手順と同じです。
学習
テキストと同じ手順です。
分類
前回の記事で作成した領域を分離する手順を今回のプログラムにも適用します。
2値化した画像から領域を分離する手順を実行し、分離した領域から画像を切り抜き、モデルへ入れ、判別します。
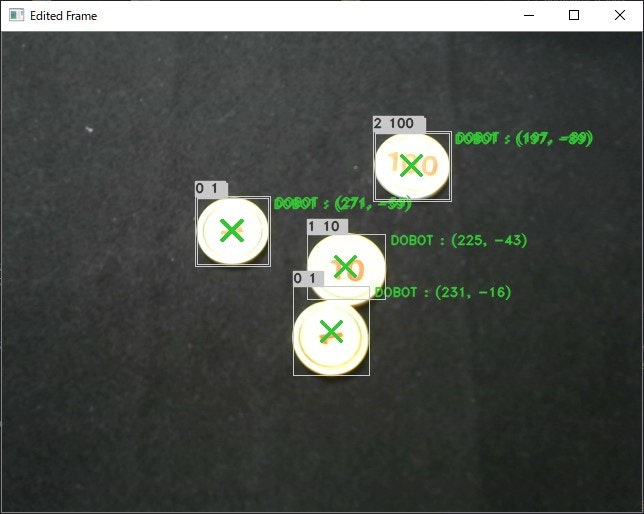
プログラム
以下のようにプログラムを修正してました。
前回の記事に引き続き、一部ソースコードを分割していますのでご注意ください。
classifier.py
import os
import sys, time
from datetime import datetime
from argparse import ArgumentParser
from tensorflow.keras.models import model_from_json
from tensorflow.keras.preprocessing.image import img_to_array, load_img
import cv2
import numpy as np
import cameraSetting as camset
from common import *
import dobotClassifier as dc
from ProcessImage import *
from TransformCoordinate import *
def get_option():
argparser = ArgumentParser()
argparser.add_argument("-d", "--directory",
dest = "load_dir",
type = str,
default = DATA_DIR,
help = "Directory that contains data used for learning.")
argparser.add_argument("-m", "--modelname",
dest = "modelname",
type = str,
default = "model",
help = "Input model name. (***.json, ***_weights.hdf5)")
argparser.add_argument("-s", "--size",
dest = "pic_size",
type = int,
default = PIC_SIZE,
help = "Picture size when training." )
argparser.add_argument("--min",
dest = "min_area_size",
type = int,
default = MIN_AREA_SIZE,
help = "Minimum area size." )
argparser.add_argument("--max",
dest = "max_area_size",
type = int,
default = MAX_AREA_SIZE,
help = "Maximum area size." )
return argparser.parse_args()
# 学習済みモデルを使って仕分ける(3)
if __name__ == '__main__':
args = get_option()
PIC_SIZE = args.pic_size
DATA_DIR = args.load_dir
MIN_AREA_SIZE = args.min_area_size
MAX_AREA_SIZE = args.max_area_size
# 学習したモデルの読み込み(3-1)
if os.path.isfile(MODEL_DIR + args.modelname + ".json") == True:
print("\n - - - model data loading ( " + args.modelname + ".json ) - - - \n")
# モデルを読み込み
model = model_from_json(open(MODEL_DIR + args.modelname + ".json").read())
# パラメーターを読み込み
model.load_weights(MODEL_DIR + args.modelname + "_weights.hdf5")
# モデル構成を表示
model.summary()
else:
# モデルがディレクトリにない場合は、終了する
print("\n No such model file. \"" + MODEL_DIR + args.modelname + ".json\"")
sys.exit()
# VideoCaptureのインスタンスを作成する(3-2)
cap = cv2.VideoCapture(1)
print("\n - - - - - - - - - - ")
# camset.camera_set(cv2, cap, gain = **調整した値**, exposure = **調整した値**.)
camset.camera_get(cv2, cap)
print(" - - - - - - - - - - \n")
print("\n - - - label check ( " + DATA_DIR + " ) - - - \n")
for dir in os.listdir(DATA_DIR):
if dir == ".DS_Store":
continue
elif dir == "photos.npz":
continue
if not(dir in LabelName):
l = len(LabelName)
LabelName.append(dir)
setattr(LabelNumber, LabelName[l], l)
print(getattr(LabelNumber, LabelName[l]), " : ", str(LabelName[l]))
print("\n - - - Start classification - - - \n")
proba_flag = False
# DOBOTの初期化処理
dc.initialize()
dc.set_z(-70)
print()
print(" Press [ H ] key to move Home-Position.")
print(" Press [ P ] key to show probabilities for each label.")
print(" Press [ S ] key to pick up a object.")
print()
print(" Press [ C ] key to Gain, Exposure setting.")
print(" Press [ESC] key to exit.")
print()
while True:
# VideoCaptureから1フレーム読み込む(3-3)
ret, frame = cap.read()
ret, edframe = cap.read()
# 加工なし画像を表示する
cv2.imshow('Raw Frame', frame)
# グレースケールに変換(3-4)
gray = cv2.cvtColor(edframe, cv2.COLOR_BGR2GRAY)
# 2値化(3-5)
retval, bw = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
kernel = np.ones((3,3), np.uint8)
bw = cv2.morphologyEx(bw, cv2.MORPH_OPEN, kernel, iterations = 2)
### 触れ合っているオブジェクトを分けて検知する
# sure background(明確な背景)
s_background = cv2.dilate(bw, kernel, iterations=2)
cv2.imshow("sure background", s_background)
# sure foreground(明確な前景)
dist_transform = cv2.distanceTransform(bw, cv2.DIST_L2, 5)
ret, s_foreground = cv2.threshold(dist_transform, 0.5 * dist_transform.max(), 255, 0)
cv2.imshow("sure foreground", s_foreground)
# Unknown(背景でも前景でもない)
s_foreground = np.uint8(s_foreground)
unknown = cv2.subtract(s_background, s_foreground)
cv2.imshow("Unknown", unknown)
# put label
ret, markers = cv2.connectedComponents(s_foreground)
markers = markers + 1
markers[unknown==255] = -1
markers = cv2.watershed(edframe, markers)
# 輪郭を抽出(3-6)
# contours, hierarchy = cv2.findContours(bw, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
contours, hierarchy = cv2.findContours(markers, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)
cutframe_array = []
result_array = []
image_list = []
# 各輪郭に対する処理
for i, contour in enumerate(contours):
# ノイズを除去する(3-7)
# 輪郭の領域を計算
area = cv2.contourArea(contour)
# ノイズ(小さすぎる領域)と全体の輪郭(大きすぎる領域)を除外
if area < MIN_AREA_SIZE or MAX_AREA_SIZE < area:
continue
# フレーム画像から対象物を切り出す(3-8)
# 回転を考慮した外接矩形を取得する
rect = cv2.minAreaRect(contour)
box = cv2.boxPoints(rect)
box = np.int0(box)
center, size, angle = rect
center = tuple(map(int, center)) # float -> int
size = tuple(map(int, size)) # float -> int
# 回転行列を取得する
rot_mat = cv2.getRotationMatrix2D(center, angle, 1.0)
h, w = frame.shape[:2]
# 切り出す
rotated = cv2.warpAffine(frame, rot_mat, (w, h))
cropped = cv2.getRectSubPix(rotated, size, center)
img_src = rect_preprocess(cropped)
# リサイズする
image = cv2.resize(img_src, dsize=(PIC_SIZE, PIC_SIZE))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = np.asarray(image)
image_list.append(image)
# 画像の前処理(3-9)
image = img_to_array(image)
image = image.astype("float32") / 255.
image = image[None, ...]
# 分類する(3-10)
result = model.predict_classes(image)
proba = model.predict_proba(image)
result_num = int(result[0])
# 輪郭に外接する長方形を取得する。(3-11)
x, y, width, height = cv2.boundingRect(contour)
# 長方形を描画する(3-12)
cv2.rectangle(edframe, (x, y), (x+width, y+height), draw_white, thickness=1)
# ラベルを表示する(3-13)
label = str(result_num) + " " + LabelName[result_num]
cv2.rectangle(edframe, (x, y-15), (x+len(label)*10, y), draw_white, -1, cv2.LINE_AA)
cv2.putText(edframe, label, (x, y-4), font, FONT_SIZE, draw_black, FONT_WIDTH, cv2.LINE_AA)
# 「P」キーが押されたときの処理(3-14)
if proba_flag == True:
# 回転を考慮した外接矩形を表示
cv2.drawContours(edframe, [box], 0, draw_red, 1)
# 確率を表示
for n in LabelName:
cnt = getattr(LabelNumber, n)
proba_str = "[{:<6}] {:>5.2f}%".format(n, proba[0, cnt] * 100.)
if cnt == np.argmax(proba):
cv2.putText(edframe, proba_str, (x+width+5, y+30+(20*cnt)), font, FONT_SIZE, draw_red, FONT_WIDTH, cv2.LINE_AA)
else:
cv2.putText(edframe, proba_str, (x+width+5, y+30+(20*cnt)), font, FONT_SIZE, draw_white, FONT_WIDTH, cv2.LINE_AA)
# 外接矩形の中心点を描画(3-15)
mp_x = int(center[0])
mp_y = int(center[1])
cv2.drawMarker(edframe, (mp_x, mp_y), draw_green, cv2.MARKER_TILTED_CROSS, thickness = 2)
# 中心点の座標をカメラ座標系からロボット座標系へ変換(3-16)
transform_pos = transform_coordinate(mp_x, mp_y)
lavel = "DOBOT : " + str(transform_pos)
cv2.putText(edframe, lavel, (x+width+5, y+10), font, FONT_SIZE, draw_green, FONT_WIDTH, cv2.LINE_AA)
# 描画した画像を表示
cv2.imshow('Edited Frame', edframe)
# キー入力を1ms待つ
k = cv2.waitKey(1)
# 「ESC(27)」キーを押す
# プログラムを終了する
if k == 27:
break
# 「C」キーを押す
# WEBカメラのゲイン値、露出の値を調整する
elif k == ord('c'):
g = input("gain : ")
e = input("exposure : ")
print("\n - - - - - - - - - - ")
camset.camera_set(cv2, cap, gain = float(g), exposure = float(e))
camset.camera_get(cv2, cap)
print(" - - - - - - - - - - \n")
# 「P」キーを押す
# 各ラベルの確率を画面上に表示する/再度押すと消える
elif k == ord('p'):
proba_flag = not(proba_flag)
# 「H」キーを押す
# DOBOTをホームポジションに移動させる(位置リセット)
elif k == ord('h'):
dc.move_home()
# DOBOTで仕分け(3-17)
# 「S」キーを押す
# 最後に取得した矩形とその結果を元にDOBOTでピックアップする
elif k == ord('s'):
print(str(result_num) + " " + LabelName[result_num] + " - " + str(transform_pos))
while dc.dobot_classifier(result_num, transform_pos[0], transform_pos[1]) != True:
pass
# 終了処理(3-18)
# DOBOTの終了処理
dc.finalize()
# キャプチャをリリースして、ウィンドウをすべて閉じる
cap.release()
cv2.destroyAllWindows()