はじめに
この記事は情報検索・検索技術 Advent Calendar 2024の2日目の記事です。
「BM25ではクエリを単語のカウントベクトルにして類似度を計算するけれど、クエリもBM25の重みベクトルにしたらどうなるのか?」という疑問が浮かんだので、実験してみました。
具体的には、BM25を用いた検索において、以下の2つの類似度指標を比較しました。
- count-bm25-dot-product: クエリの単語カウントベクトルと文書のBM25重みベクトルの内積
- bm25-bm25-dot-product: クエリのBM25重みベクトルと文書のBM25重みベクトルの内積
簡単に思いつく疑問なので、おそらく過去にも試された方が多くいるとは思うのですが、調べた範囲では意外と事例が見つからなかったのと、やってみたら案外よい結果だったので、紹介できればと思います。
検索分野は独学のため、知識不足な点もあるかもしれません。何かあればご指摘いただけると嬉しいです。
背景
BM25は検索でよく使われる単語の重み付け方法の一つです。
近年では検索に深層学習ベースの密な埋め込みを使うことが多いですが、BM25など単語の表層に基づく検索も、独自用語に強い、計算が早いなどの強みがあり、単体あるいは密な埋め込みと組み合わせて引き続き使われています。
BM25ではクエリ(Q)と検索対象である文書(D)の類似度を、バリエーションはありますが概ね以下のような式で求めます(wikipedia)。
$$
\text{BM25}(Q, D) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})}
$$
この式は、クエリと文書に共通して現れる単語の文書内での重みを、クエリ内での単語の出現回数に応じて合計するものです。つまり、クエリの単語のカウントベクトルと文書のBM25重みベクトルの内積を計算していることになります。BM25のスコアを計算する多くのライブラリではこの方法が採用されています(例: lucene、rank-bm25)。
一方で、BM25以外の手法では、クエリも文書と同じ方法でベクトル化されてから内積やコサイン類似度を計算することが多いです。BM25と並んでよく使われる単語の重み付け手法であるTFIDFでは、クエリの重みベクトルと文書の重みベクトルとのコサイン類似度を計算することが一般的です(例: lucene、langchain.TFIDFRetriever)。また、深層学習ベースの密な埋め込みを用いる手法でも、クエリは文書と同じベクトル空間に埋め込まれてから内積やコサイン類似度が計算されます。
BM25でクエリを重みベクトルにすることは、経験則や何らかの理論に基づいて非推奨とされる可能性もありますが、調査した範囲では強固な根拠は見つかりませんでした。BM25はTFに補正をかけた以外はTFIDFと非常に似た式なので、個人的には、TFIDFとBM25でクエリのベクトル化方法に差をつける根拠はあまりないように思います。むしろ、2、3単語のキーワードリスト的なクエリであれば、単語の重要度を等しく扱う意味でカウントベクトルでも良いのですが、長文のクエリを想定するなら、重みベクトルにしてクエリ側でも単語の重要度に差をつけるほうが自然では? とも考えます。また、クエリと文書でベクトライザを区別する必要がなくなると、若干ですが実装も楽になる1ので、クエリも重みベクトルにして良いならそのほうが良いかもしれません。
そこで、BM25検索において、クエリを重みベクトルにする場合とカウントベクトルにする場合の精度を日本語の検索データセットで比較してみることにしました。
実験1
本格的な比較をする前に、検索ベンチマークMIRACLの日本語版を使用して、いくつかの条件の組み合わせにおける精度を予備的に検証しました。
具体的には、クエリをカウントベクトルにするか重みベクトルにするか、類似度計算を内積にするかコサイン類似度にするか、の違いを検討しました。またベースラインとしてTFIDFについても同様の条件を比較しました(TFIDFの結果は本記事では触れません)。
実装等の詳細は長くなるので別記事にしています。
結果だけ抜粋します。重要な点として、MIRACLのデータセットをすべて使うと計算が終わらなかったため、クエリと文書をそれぞれ100、10000件ずつランダムに取得して精度を求める試行を10回実施しています。下図はその平均値と標準偏差を示しています。
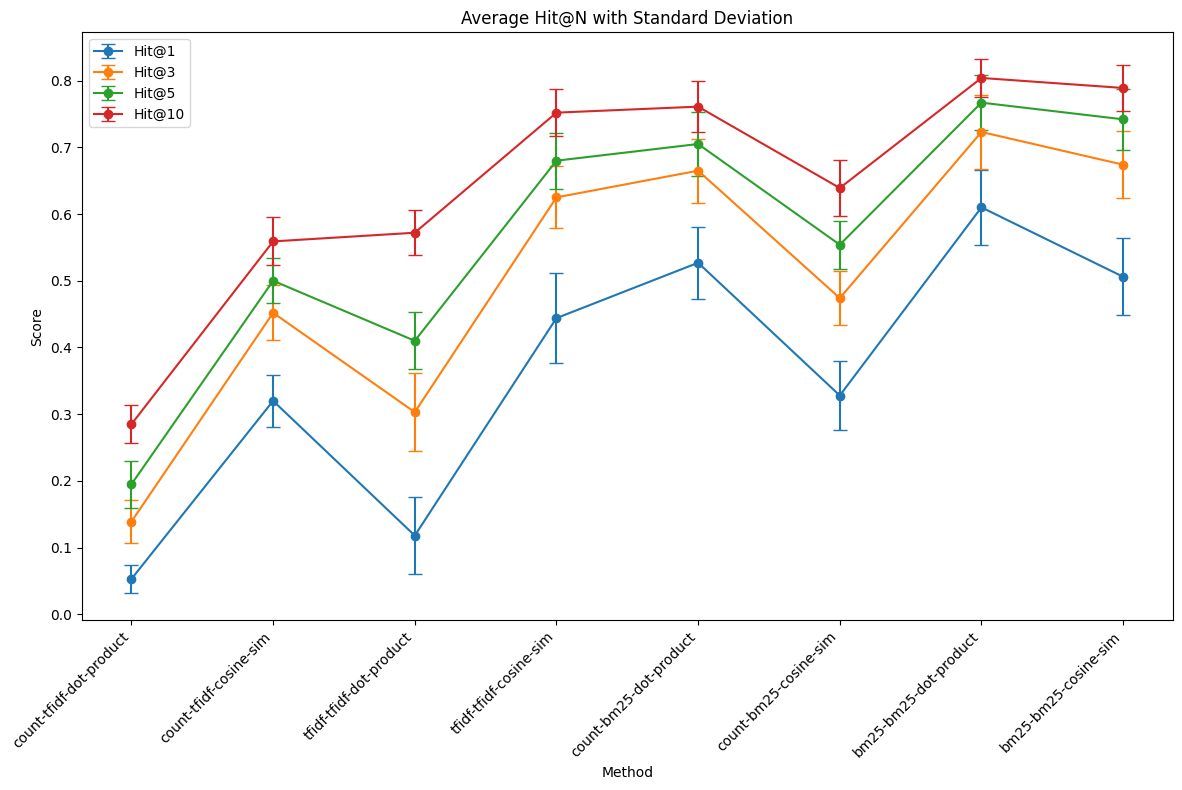
条件名はクエリベクトル-コーパスベクトル-類似度指標の形式で表記されています。
クエリベクトルはcount, tfidf, bm25、コーパスベクトルはtfidf, bm25、類似度指標はdot-product, cosine-simのいずれかです。
例えば、count-bm25-dot-productはクエリのカウントベクトルとコーパスのbm25重みベクトルの内積に基づいて検索順位を算出していることを意味します。
BM25ではコサイン類似度よりも内積のほうが全体的に精度が高かったです。
また、クエリをカウントベクトルにするよりも重みベクトルにするほうが精度が高いという結果でした。Hit@10で、count-bm25-dot-product (0.7610)よりbm25-bm25-dot-product(0.8040)が4%ポイントも高かったです2。
これらはMIRACLという単一のデータセットに基づく結果ですので、実験2で他のデータセットでも確認してみます。
実験2
実験2では複数のデータセットでクエリをカウントベクトルにする場合と重みベクトルにする場合を比較します。
検索データセットは日本語テキスト埋め込みベンチマークJMTEBの検索タスクのうちjagovfaqs_22k、jaqket、nlp_journal_abs_intro、nlp_journal_title_abs、nlp_journal_title_introの5種類を使います。mrtydiはデータセットが大きくて手元のPCで処理が完了しなかったため、結果に含めていません。
評価のために、JMTEBをBM25で評価できるよう変更しました。
類似度計算は実験1を踏まえてコサイン類似度ではなく内積に固定しました。
分かち書きは、形態素解析は時間がかかるため実施せず、文字トリグラムで行いました。
評価指標は、本家に倣いndcg@10にします。
実装は以下で公開しています。
https://github.com/jiroshimaya/JMTEB
結果は以下のとおりでした。
| Model | Avg. | jagovfaqs_22k (ndcg@10) |
jaqket (ndcg@10) |
mrtydi (ndcg@10) |
nlp_journal_abs_intro (ndcg@10) |
nlp_journal_title_abs (ndcg@10) |
nlp_journal_title_intro (ndcg@10) |
|---|---|---|---|---|---|---|---|
| count-bm25-dot-product | NA | 0.5706 | 0.5976 | NA | 0.9915 | 0.9484 | 0.9485 |
| bm25-bm25-dot-product | NA | 0.5875 | 0.5796 | NA | 0.9944 | 0.9506 | 0.9511 |
モデル名は実験1と同様にクエリベクトル-コーパスベクトル-類似度指標の形式で表記されています。
評価できた5個中4個のデータセットでクエリを重みベクトルにする方法(bm25-bm25-dot-product)がカウントベクトルにする方法(count-bm25-dot-product)よりも精度が高かったです。
考察
MIRACLとJMTEBで合わせて6個中5個のデータセットでクエリも重みベクトルにしたほうがBM25検索の精度が高いという結果でした。
ただ、JMTEBのnlp_journal系のスコアはサチり気味で差はほとんどないので、実質3個中2個で勝っている、くらいかもしれません。
今回の検証だけでどんなときでもクエリを重みベクトルにしたほうがよいとまでは言えませんが、パラメータチューニングの感覚で、クエリを重みベクトルにすることを今後試してみてもよいかもしれません。あるいは少なくとも明確に精度が落ちるわけではなさそうなので、クエリと文書のベクトル化方法を区別する実装の手間を減らす目的で、クエリを重みベクトル化する方法を採用するのもありかもしれません。
クエリを重みベクトルにすることが効果的な場合があるとして、その理由はよくわかりませんが、背景でも述べたように、クエリの長さが関係している可能性はあるかもしれません。クエリをカウントベクトルにすることは、クエリに含まれる単語の重要度に頻度以外の差をつけないことになります。BM25が提唱された当時はクエリは2,3単語のキーワードのリストのようなものが主流だったでしょうから、クエリに含まれる単語をすべて同じ重要度で扱うことは自然です。一方で最近では、質問文形式のような、比較的長めのクエリも多いです。クエリが長いと、クエリ側でも単語の重要度に差をつけたほうが、文書との類似度が見えやすくなるような気はします。
この仮説は、クエリが自然文の場合とキーワードリストの場合にデータセットを分けることで検証可能ですので、今後試して見ても面白いかもしれません。あるいはこうした研究は過去に散々やられていそうな気もするので、どなたかご知見ありましたら教えていただけると嬉しく思います。
おわりに
BM25を用いた検索タスクにおいて、クエリをカウントベクトルにする教科書的な方法(count-bm25-dot-product)と、クエリを重みベクトルにする方法(bm25-bm25-dot-product)を比較しました。
MIRACLとJMTEBに含まれる検索データセットで評価したところ、6個中5個で、bm25-bm25-dot-productのほうがスコアが高いという結果でした。
教科書的な方法が結局強いのだろうかと思っていたらそうでもなく、意外でした。もちろん教科書的な方法が順当に強いデータセットもあったので、絶対的な方法ということではないです(簡単に思いつく方法なので本当に強い効果があるなら主流になっているはずですし)。ただ、個人的には、特に自然文のクエリを想定するなら理にかなっている部分もありそうですので、BM25のチューニング箇所の候補にするくらいはよいかもなと思いました。
おまけ
MIRACLでの評価コード
別記事にまとめたので適宜ご参照ください。
JMTEBでの評価コード
JMTEBの評価コードは深層学習ベースの密な埋め込みでの評価を前提としているため、BM25で評価できるように変更する必要がありました。
変更したコードは以下です。JMTEBはevaluatorとembedderを引数にして評価を実行しますので、これらを適切に変更すればBM25の評価が可能です。
https://github.com/jiroshimaya/JMTEB/tree/main
以下、変更の要点を記載していきます。似たようなことをしたい方の参考になれば幸いです。
evaluator
evaluatorからembedderを呼び出す形になるので、まずevaluatorを見ていきました。
検索の場合はRetrievalEvaluatorというクラスが使われているので、これを変更しました。
encodeメソッドの使い分けとencode前のfit
クエリと文書を同じembedderのメソッド(batch_encode_with_cache)でエンコードしていたのですが、これだとBM25のクエリをカウントベクトルにするという仕様に対応できないため、クエリと文書でembedderの異なるメソッド(batch_encode_query_with_cache、batch_encode_doc_with_cache)を呼び出すようにしました。
また、BM25ではデータセットごとにモデルをfitする必要があるため、embedderのクラス名に応じてfitを行うようにしました。
batch_encode_query_func = model.batch_encode_with_cache
batch_encode_doc_func = model.batch_encode_with_cache
if model.__class__.__name__ in ("BM25Embedder", "TfidfEmbedder"):
doc_text_list = [item.text for item in self.doc_dataset]
model.fit(doc_text_list)
batch_encode_query_func = model.batch_encode_query_with_cache
batch_encode_doc_func = model.batch_encode_doc_with_cache
val_query_embeddings = batch_encode_query_func(
text_list=[item.query for item in self.val_query_dataset],
prefix=self.query_prefix,
cache_path=Path(cache_dir) / "val_query.bin" if cache_dir is not None else None,
overwrite_cache=overwrite_cache,
)
if self.val_query_dataset == self.test_query_dataset:
test_query_embeddings = val_query_embeddings
else:
test_query_embeddings = batch_encode_query_func(
text_list=[item.query for item in self.test_query_dataset],
prefix=self.query_prefix,
cache_path=Path(cache_dir) / "test_query.bin" if cache_dir is not None else None,
overwrite_cache=overwrite_cache,
)
doc_embeddings = batch_encode_doc_func(
text_list=[item.text for item in self.doc_dataset],
prefix=self.doc_prefix,
cache_path=Path(cache_dir) / "corpus.bin" if cache_dir is not None else None,
overwrite_cache=overwrite_cache,
)
テスト用の距離関数の固定
本来はval_datasetでdist_funcごとのスコアを比べて、もっともよかったdist_funcでtest_datasetを評価する、というコードなのですが、BM25ではtest_datasetの評価に使うdist_funcは内積に固定したかったため、初期化時にoptimal_dist_nameが指定された場合はval_datasetでの評価をスキップするようにしました。
val_results = {}
optimal_dist_name = self.optimal_dist_name
if optimal_dist_name is None:
for dist_name, dist_func in dist_functions.items():
val_results[dist_name], _ = self._compute_metrics(
query_dataset=self.val_query_dataset,
query_embeddings=val_query_embeddings,
doc_embeddings=doc_embeddings,
dist_func=dist_func,
)
sorted_val_results = sorted(val_results.items(), key=lambda res: res[1][self.main_metric], reverse=True)
optimal_dist_name = sorted_val_results[0][0]
csr_matrixへの対応
類似度計算の関数をcsr_matrixの演算に対応させました。この部分は以下のコードも参考にさせていただきました。
https://github.com/hotchpotch/JMTEB/tree/add_splade
embedder
embedderはデータセットを埋め込みに変換するクラスです。既存のembedderを参考に、BM25Embedderというクラスを新たに作りました。
BM25Vectorizer
まずBM25のベクトライザは使いやすいのがなかったので、pythonでのBM25スコア計算によく使われるrank-bm25をベースに自作しました。MIRACLのときに作ったものとほぼ同じですが、JMTEB用に少しマイナーチェンジしています。
class BM25Vectorizer:
# rank-bm25 の実装を参考にした
def __init__(self, k1=1.5, b=0.75, epsilon=0.25, tokenizer: Callable[[list[str]], list[list[str]]] | None = None):
self.k1 = k1
self.b = b
self.epsilon = epsilon
self.tokenizer = tokenizer
def _tokenize_corpus(self, corpus: list[str]) -> list[list[str]]:
return [self.tokenizer(text) for text in corpus]
def fit(self, corpus: list[list[str]] | list[str],
initialize: bool = True,
batch_size: int = 10**4,
show_progress_bar: bool = False):
if initialize:
self.corpus_size = 0
self.doc_len = 0
self.avgdl = 0
self.idf = {}
self.nd: Counter[str] = Counter()
with tqdm.tqdm(total=len(corpus), desc="Fitting BM25") as pbar:
for i in range(0, len(corpus), batch_size):
batch = corpus[i : i + batch_size]
if self.tokenizer is not None:
batch = self._tokenize_corpus(batch)
self._calc_nd(batch)
pbar.update(len(batch))
self._calc_idf(self.nd)
self.vocabulary = list(self.idf.keys())
self.word_to_id = {word: i for i, word in enumerate(self.vocabulary)}
self.idf_array = np.array([self.idf[word] for word in self.vocabulary]) # idfをNumPy配列として保持
def _calc_nd(self, corpus: list[list[str]]):
for document in corpus:
self.nd.update(set(document))
self.doc_len += sum(len(document) for document in corpus)
self.corpus_size += len(corpus)
self.avgdl = self.doc_len / self.corpus_size
def _calc_idf(self, nd):
"""
Calculates frequencies of terms in documents and in corpus.
This algorithm sets a floor on the idf values to eps * average_idf
"""
# collect idf sum to calculate an average idf for epsilon value
idf_sum = 0
# collect words with negative idf to set them a special epsilon value.
# idf can be negative if word is contained in more than half of documents
negative_idfs = []
for word, freq in nd.items():
idf = math.log(self.corpus_size - freq + 0.5) - math.log(freq + 0.5)
self.idf[word] = idf
idf_sum += idf
if idf < 0:
negative_idfs.append(word)
self.average_idf = idf_sum / len(self.idf)
eps = self.epsilon * self.average_idf
for word in negative_idfs:
self.idf[word] = eps
def transform(self, queries: list[list[str]] | list[str], show_progress_bar: bool = False) -> csr_matrix:
rows = []
cols = []
data = []
if self.tokenizer is not None:
queries = self._tokenize_corpus(queries)
enumerate_queries = tqdm.tqdm(enumerate(queries)) if show_progress_bar else enumerate(queries)
for i, query in enumerate_queries:
query_len = len(query)
query_count = Counter(query)
for word, count in query_count.items():
if word in self.word_to_id:
word_id = self.word_to_id[word]
tf = count
idf = self.idf.get(word, 0)
# BM25 scoring formula
numerator = idf * tf * (self.k1 + 1)
denominator = tf + self.k1 * (1 - self.b + self.b * query_len / self.avgdl)
score = numerator / denominator
rows.append(i)
cols.append(word_id)
data.append(score)
return csr_matrix((data, (rows, cols)), shape=(len(queries), len(self.vocabulary)))
def count_transform(self, queries: list[list[str]] | list[str], show_progress_bar: bool = False) -> csr_matrix:
rows = []
cols = []
data = []
if self.tokenizer is not None:
queries = self._tokenize_corpus(queries)
enumerate_queries = tqdm.tqdm(enumerate(queries)) if show_progress_bar else enumerate(queries)
for i, query in enumerate_queries:
for word in query:
if word in self.word_to_id:
word_id = self.word_to_id[word]
rows.append(i)
cols.append(word_id)
data.append(1) # Count is always 1 for each occurrence
return csr_matrix((data, (rows, cols)), shape=(len(queries), len(self.vocabulary)))
トーカナイザ
トーカナイザも同じファイルで定義しています。高速化のため、文字トリグラムです。
def tokenize_with_ngrams(text: str, ngram_range: tuple[int, int] = (3, 3)) -> list[str]:
"""
指定された範囲のn-gramを生成する関数
:param text: 入力テキスト
:param ngram_range: n-gramの範囲 (start, end)
:return: n-gramのリスト
"""
ngrams = []
for i in range(ngram_range[0], ngram_range[1] + 1):
ngrams.extend([''.join(text[j:j+i]) for j in range(len(text)-i+1)])
return ngrams
BM25Embedder
BM25EmbedderはBM25Vectorizerのラッパー的な位置づけです。変更したRetrievalEvaluatorと整合するように、fit、batch_encode_query_with_cache、batch_encode_doc_with_cacheというメソッドを定義すればよいです。
batch_encode_query_with_cacheはBM25Embedderの初期化時に渡したフラグuse_count_vector_for_queryがtrueのときはカウントベクトル、falseのときは重みベクトルを返すようにしておきます。
init.pyへの追記
他のソースコードから呼び出せるように、__init__.pyにBM25Embedderを追記します。
from jmteb.embedders.bm25_embedder import BM25Embedder
実行
以下のような感じで実行できます。
poetry run python -m jmteb \
--embedder BM25Embedder \
--embedder.use_count_vector_for_query true \ # queryを単語カウントベクトルにするときはtrue、重みベクトルにするときはfalse
--evaluators src/jmteb/configs/tasks/jagovfaqs_22k.jsonnet