概要
キーワード検索における類似度を計算するとき、TFIDFであればクエリと文書の重みベクトルのコサイン類似度を、BM25であればクエリの単語カウントベクトルと文書の重みベクトルの内積を求めることが多いのですが、逆に、TFIDFでクエリのカウントベクトルと文書の重みベクトルの内積を指標にしたり、BM25で重みベクトルのコサイン類似度を求めたらどうなるのか気になりました。
そこで、検索ベンチマークmiraclの日本語版を使って、クエリを単語のカウントベクトルにするか重みベクトルにするか、類似度を内積にするかコサイン類似度にするか、といった条件での検索精度を比較しました。
今回検証した範囲では、TFIDFは重みベクトル同士のコサイン類似度が、BM25は重みベクトル同士の内積が、最も検索精度が高いという結果でした。BM25については、よく使われる条件とは異なる条件が高精度という結果だったため、興味深いです。単一のベンチマークに基づくため、他のベンチマークでも同様の傾向が見られるか検証することが今後の課題です。
背景
単語の表層に基づく検索(キーワード検索)は、検索精度においては深層学習ベースの密な埋め込みに基づく検索に劣るものの、計算が速い、固有名詞に強い、密な埋め込みと組み合わせることで密な埋め込み単体での検索精度を上回ることがある、などの理由から、現在でも有効な手法です。
キーワード検索ではクエリと文書を単語の種類数次元のベクトルに変換して、類似度を計算します。ここで、クエリは検索するためにユーザーが入力する文章、文書は検索対象コーパスの文章であるとします。
ベクトルの成分はシンプルに単語の出現数や出現率の場合もあれば、重要度に応じた実数値の場合もあります。重要度の指標としてはTFIDFとBM25がよく用いられます。
ベクトルの類似度を求めるとき、計算方法にいくつかバリエーションが考えられます。ここでは2つの要素を考えます。
1つはベクトルの類似度として、コサイン類似度と内積のどちらを使うかです。ベクトルのサイズで正規化しないか、するか、ということもできます。
もう1つは、クエリをベクトル化するときに、単語のカウントベクトルにするか、重みベクトルにするかです。これは文書の重みベクトルとの内積を計算することを前提にすると、類似度を重みの線形和とするか、ほぼ二乗和1とするかの違いということもできます。定性的には、クエリを重みベクトルにして二乗和を計算したほうが、重みの傾向がより強調されるということになります。
世の中の実装例を眺めると、TFIDFでは、クエリを重みベクトルにして、文書の重みベクトルのとのコサイン類似度を求めている場合がほとんどです。例えば、ElasticSearchで使われるluceneやlangchainのTFIDFRetrieverではそうなっているようです。
BM25では、クエリをカウントベクトルにして、文書の重みベクトルとの内積をとる計算方法がほとんどです。例えば、pythonライブラリのrank-bm25ではそのように計算されています。luceneでもおそらくそうなっていそうです。
このように、TFIDFとBM25は単語を重要度で重み付けるという点では同じですが、類似度の計算は異なる方法が好まれているようです。ただその理由は調査した範囲ではよくわかりませんでした。歴史的な経緯や経験則によるものなのだとすると、TFIDFで重みの線形和をとったり、BM25で重みベクトルのコサイン類似度をとったりすると、検索精度が悪くなってしまうのかどうかが気になりました。
そこで、日本語検索ベンチマークにおける精度が、類似度の計算方法によってどのように変わるかを比較してみることにしました。
方法
比較条件
下記3つの組み合わせによる8通りの条件を比較します。
- 重み指標:TFIDF、BM25
- クエリベクトル:カウント、重み
- 類似度:内積、コサイン
検索コーパス
文章の検索ベンチマークとしてよく使われるmiraclの日本語データセットに基づき評価しました。
評価指標
検索結果の上位n件に少なくとも1つの正解文書が含まれるクエリの割合をHit@nとして、検索精度の指標としました。試行を10回行い、Hit@nの平均と標準偏差を算出しました。各試行では、クエリを100件、コーパスを10000件ランダムに抽出しました。n=1,3,5,10の場合についてプロットし、条件ごとの違いを考察しました。
重みの計算
重みの計算には、TFIDFについてはscikit-learnのTfidfVectorizerを使用しました。パラメータはBM25と条件を揃えるため、ストップワードをなくすなど、コーパス全体から素直に重みを計算するようにしました。また、scikit-learnではTFに単語のカウントが使われますが、今回は文章長で正規化し単語の割合をTFとしました。
BM25については、rank-bm25のBM25Okapiを継承し、ベクトル化機能を持たせたクラスを使用しました。TFを調整するパラメータであるbとkは、初期値(b=0.75、k=1.2)を使用しました。
結果
各条件におけるHit@nの平均値と標準偏差を以下の図に示します。
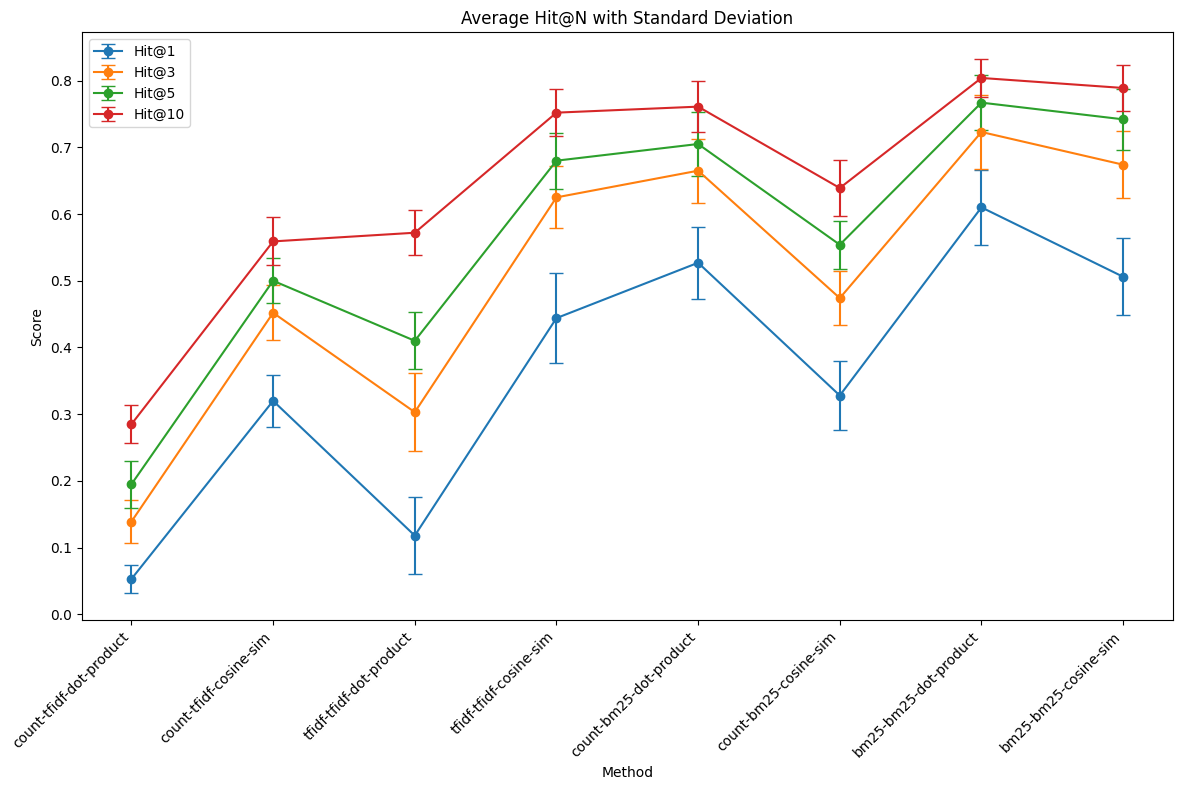
条件名はクエリベクトル-コーパスベクトル-類似度指標の形式で表記されています。
クエリベクトルはcount, tfidf, bm25、コーパスベクトルはtfidf, bm25、類似度指標はdot-product, cosine-simのいずれかです。
例えば、count-bm25-dot-productはクエリのカウントベクトルとコーパスのbm25重みベクトルの内積に基づいて検索順位を算出していることを意味します。
考察
重みがTFIDFかBM25かで傾向が異なるため、それぞれについて考察します。
TFIDF
TFIDFでは、クエリもTFIDF重みベクトルに変換し、コーパスとのコサイン類似度を計算する場合が最も高精度でした。これはTFIDFのよくある実装と一致します。
要因ごとに見ると、内積よりもコサイン類似度が、クエリをカウントベクトルにするよりも重みベクトルにする方が、高精度という傾向が見られました。
内積よりコサイン類似度のほうが精度が高かったことから、ベクトルサイズで正規化したことが精度向上に寄与したと考えられます。TFIDFではTFを出現率にしたとしても、長い文章ほどベクトルも大きくなる傾向があることから、ベクトルサイズの影響は無視したほうが検索に適しているのだと思われます。
クエリを重みベクトルにしたほうが精度が高かったことから、重みの二乗和を計算して、重みの傾向をより強調することが検索精度向上に寄与した可能性があります。TFやIDFの計算式から2乗したほうがいいと説明することは難しいので、経験則的にそうだということなのかもしれません。
BM25
BM25では、クエリをBM25重みでベクトル化し、コーパスとの内積を計算する場合が最も高精度でした。これはBM25のよくある実装とは異なる条件です。単一のコーパスに基づくため、一般化はまだできませんが、興味深い結果です。
要因ごとに見ると、コサイン類似度よりも内積が、クエリをカウントベクトルにするよりも重みベクトルにする方が、高精度という傾向が見られました。
コサイン類似度よりも内積の方が高精度である傾向は、TFIDFとは逆ですが、BM25では重みを計算する時点で、文章長を考慮する計算式になっているため、そのまま使った方が良いということなのかもしれません。
クエリは重みベクトルにした方がカウントベクトルにするよりも高精度でした。クエリをBM25の重みベクトルにすることは、主要なライブラリではあまりやられていませんが、精度向上に向けた検証として、コーパスごとに試す価値は今後出てくるのかもしれません。
制限事項
本結果はmiraclという単一のベンチマークに基づいているため、検索対象のコーパスによっては異なる傾向が見られる可能性があります。また、今回は重みの計算方法のバリエーションを広く検討していません。例えば、TFIDFではTFとして単語の出現回数、出現回数の対数、出現回数の平方根などが使用されることがありますが、今回は単語の出現率に固定しています。BM25のbとkのパラメータも調整可能ですが、今回は一般的に使用される0.75と1.2に固定しています。これらのバリエーションの違いによっても結果が異なる可能性があります。
おわりに
TFIDFとBM25の類似度計算方法のバリエーションを比較検討しました。今回の検証範囲では、
- TFIDFはクエリとコーパスをそれぞれ重みベクトルに変換し、コサイン類似度を計算する方法
- BM25はクエリとコーパスをそれぞれ重みベクトルに変換し、内積を計算する方法
が高精度でした。
特に、BM25で高精度となった条件は、一般の実装例で多く見られる、クエリをカウントベクトル化して内積をとる方法とは異なるため、検証した価値があったと考えます。
付録
実装
以下に実装コードの詳細を記載します。
BM25Vectorizer
PythonのBM25計算用ライブラリであるrank-bm25には、BM25の重みベクトルを取得するメソッドがないため、このメソッドを追加したクラスを作成します。また、単語のカウントベクトルを取得する機能もないため、これも実装します。メソッド名はscikit-learnに倣ってtransformにしています。
from collections import Counter
from rank_bm25 import BM25Okapi
from scipy.sparse import csr_matrix
class BM25Vectorizer(BM25Okapi):
def __init__(self, corpus, **bm25_params):
super().__init__(corpus, **bm25_params)
self.vocabulary = list(self.idf.keys())
self.word_to_id = {word: i for i, word in enumerate(self.vocabulary)}
#override
def _initialize(self, corpus):
nd = {} # word -> number of documents with word
num_doc = 0
for document in corpus:
self.doc_len.append(len(document))
num_doc += len(document)
frequencies = {}
for word in document:
if word not in frequencies:
frequencies[word] = 0
frequencies[word] += 1
self.doc_freqs.append(frequencies)
for word, freq in frequencies.items():
try:
nd[word]+=1
except KeyError:
nd[word] = 1
self.corpus_size += 1
self.avgdl = num_doc / self.corpus_size
self.nd = nd # add this line
return nd
def transform(self, queries: list[list[str]]) -> csr_matrix:
rows = []
cols = []
data = []
for i, query in enumerate(queries):
query_len = len(query)
query_count = Counter(query)
for word, count in query_count.items():
if word in self.word_to_id:
word_id = self.word_to_id[word]
tf = count
idf = self.idf.get(word, 0)
# BM25 scoring formula
numerator = idf * tf * (self.k1 + 1)
denominator = tf + self.k1 * (1 - self.b + self.b * query_len / self.avgdl)
score = numerator / denominator
rows.append(i)
cols.append(word_id)
data.append(score)
return csr_matrix((data, (rows, cols)), shape=(len(queries), len(self.vocabulary)))
def count_transform(self, queries: list[list[str]]) -> csr_matrix:
rows = []
cols = []
data = []
for i, query in enumerate(queries):
for word in query:
if word in self.word_to_id:
word_id = self.word_to_id[word]
rows.append(i)
cols.append(word_id)
data.append(1) # Count is always 1 for each occurrence
return csr_matrix((data, (rows, cols)), shape=(len(queries), len(self.vocabulary)))
評価関数
以降は、前述のBM25Vectorizerを定義したfastbm25.pyと同じディレクトリに配置したJupyter Notebook上で実行することを前提としています。
まず、必要なライブラリをインポートし、評価用の関数を作成します。
日本語の評価を行うために、分かち書き用の関数(tokenize)も作成します。
また、corpusとクエリおよび正解文書のidを入力として、必要な条件での検索を実行し、hit@nを出力する関数(eval_corpus)を作ります。
from fastbm25 import BM25Vectorizer
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import os
import dotenv
import datasets
import MeCab
import random
import numpy as np
dotenv.load_dotenv()
mecab = MeCab.Tagger('-Owakati')
def tokenize(text: str) -> list[str]:
return mecab.parse(text).strip().split()
def eval_corpus(corpus_texts_tokenized: list[list[str]], corpus_ids: list[str], query_texts_tokenized: list[list[str]], query_positive_ids: list[list])->dict:
"""
Evaluate the performance of different vectorization and similarity methods on a corpus.
This function takes a corpus of texts, query texts, and their corresponding IDs, and evaluates
the performance of various vectorization and similarity calculation methods using Hit@N metric.
Parameters:
- corpus_texts_tokenized (list[str]): List of tokenized corpus texts
- corpus_ids (list[str]): List of corpus document IDs
- query_texts_tokenized (list[str]): List of tokenized query texts
- query_positive_ids (list[list]): List of lists containing positive document IDs for each query
Returns:
- dict: A dictionary containing Hit@N scores for different vectorization and similarity methods,
where N is 1, 3, 5, and 10.
"""
count_vectorizer_params = {
"binary": False,
"ngram_range": (1, 1),
"analyzer": lambda x: x,
"lowercase": False,
"stop_words": None, # all words
"max_df": 1.0, # all words
"min_df": 1, # all words
"max_features": None, # all words
}
tfidf_vectorizer_params = {
**count_vectorizer_params,
"norm": None, # no normalization
"use_idf": True,
"smooth_idf": True,
}
# Initialize vectorizers
count_vectorizer = CountVectorizer(**count_vectorizer_params)
count_vectorizer.fit(corpus_texts_tokenized)
tfidf_vectorizer = TfidfVectorizer(**tfidf_vectorizer_params)
tfidf_vectorizer.fit(corpus_texts_tokenized)
bm25_vectorizer = BM25Vectorizer(corpus_texts_tokenized)
# Transform corpus texts
tfidf_corpus_vectors = tfidf_vectorizer.transform(corpus_texts_tokenized) / count_vectorizer.transform(corpus_texts_tokenized).sum(axis=1)
bm25_corpus_vectors = bm25_vectorizer.transform(corpus_texts_tokenized)
# Transform query texts
count_query_vectors_sklearn = count_vectorizer.transform(query_texts_tokenized)
count_query_vectors_rankbm25 = bm25_vectorizer.count_transform(query_texts_tokenized)
tfidf_query_vectors = tfidf_vectorizer.transform(query_texts_tokenized) / count_vectorizer.transform(query_texts_tokenized).sum(axis=1)
bm25_query_vectors = bm25_vectorizer.transform(query_texts_tokenized)
# Calculate similarity matrices
count_tfidf_dot_product = count_query_vectors_sklearn.dot(tfidf_corpus_vectors.T).toarray()
count_tfidf_cosine_sim = cosine_similarity(count_query_vectors_sklearn, tfidf_corpus_vectors)
tfidf_tfidf_dot_product = tfidf_query_vectors.dot(tfidf_corpus_vectors.T).toarray()
tfidf_tfidf_cosine_sim = cosine_similarity(tfidf_query_vectors, tfidf_corpus_vectors)
count_bm25_dot_product = count_query_vectors_rankbm25.dot(bm25_corpus_vectors.T).toarray()
count_bm25_cosine_sim = cosine_similarity(count_query_vectors_rankbm25, bm25_corpus_vectors)
bm25_bm25_dot_product = bm25_query_vectors.dot(bm25_corpus_vectors.T).toarray()
bm25_bm25_cosine_sim = cosine_similarity(bm25_query_vectors, bm25_corpus_vectors)
# Calculate rankings
count_tfidf_dot_product_rank = count_tfidf_dot_product.argsort(axis=1)[:, ::-1]
count_tfidf_cosine_sim_rank = count_tfidf_cosine_sim.argsort(axis=1)[:, ::-1]
tfidf_tfidf_dot_product_rank = tfidf_tfidf_dot_product.argsort(axis=1)[:, ::-1]
tfidf_tfidf_cosine_sim_rank = tfidf_tfidf_cosine_sim.argsort(axis=1)[:, ::-1]
count_bm25_dot_product_rank = count_bm25_dot_product.argsort(axis=1)[:, ::-1]
count_bm25_cosine_sim_rank = count_bm25_cosine_sim.argsort(axis=1)[:, ::-1]
bm25_bm25_dot_product_rank = bm25_bm25_dot_product.argsort(axis=1)[:, ::-1]
bm25_bm25_cosine_sim_rank = bm25_bm25_cosine_sim.argsort(axis=1)[:, ::-1]
# Function to calculate hit@n
def count_hit_at_n(rank_matrix, query_positive_ids, corpus_ids, n=3):
hit_at_n = 0
for i, pos_ids in enumerate(query_positive_ids):
top_n_indices = rank_matrix[i][:n]
top_n_docids = [corpus_ids[idx] for idx in top_n_indices]
if any(docid in pos_ids for docid in top_n_docids):
hit_at_n += 1
return hit_at_n / len(query_positive_ids)
# Calculate hit@n for different n values (1, 3, 5, 10)
n_values = [1, 3, 5, 10]
hit_at_ns = {}
for n in n_values:
hit_at_ns[n] = {
"count-tfidf-dot-product": count_hit_at_n(count_tfidf_dot_product_rank, query_positive_ids, corpus_ids, n=n),
"count-tfidf-cosine-sim": count_hit_at_n(count_tfidf_cosine_sim_rank, query_positive_ids, corpus_ids, n=n),
"tfidf-tfidf-dot-product": count_hit_at_n(tfidf_tfidf_dot_product_rank, query_positive_ids, corpus_ids, n=n),
"tfidf-tfidf-cosine-sim": count_hit_at_n(tfidf_tfidf_cosine_sim_rank, query_positive_ids, corpus_ids, n=n),
"count-bm25-dot-product": count_hit_at_n(count_bm25_dot_product_rank, query_positive_ids, corpus_ids, n=n),
"count-bm25-cosine-sim": count_hit_at_n(count_bm25_cosine_sim_rank, query_positive_ids, corpus_ids, n=n),
"bm25-bm25-dot-product": count_hit_at_n(bm25_bm25_dot_product_rank, query_positive_ids, corpus_ids, n=n),
"bm25-bm25-cosine-sim": count_hit_at_n(bm25_bm25_cosine_sim_rank, query_positive_ids, corpus_ids, n=n),
}
# Print results for each n
print(f"Hit@{n}: count-tfidf-dot-product: {hit_at_ns[n]['count-tfidf-dot-product']:.4f}, count-tfidf-cosine-sim: {hit_at_ns[n]['count-tfidf-cosine-sim']:.4f}, tfidf-tfidf-dot-product: {hit_at_ns[n]['tfidf-tfidf-dot-product']:.4f}, tfidf-tfidf-cosine-sim: {hit_at_ns[n]['tfidf-tfidf-cosine-sim']:.4f}, count-bm25-dot-product: {hit_at_ns[n]['count-bm25-dot-product']:.4f}, count-bm25-cosine-sim: {hit_at_ns[n]['count-bm25-cosine-sim']:.4f}, bm25-bm25-dot-product: {hit_at_ns[n]['bm25-bm25-dot-product']:.4f}, bm25-bm25-cosine-sim: {hit_at_ns[n]['bm25-bm25-cosine-sim']:.4f}")
return hit_at_ns
miraclのダウンロード
HuggingFaceから検索用のベンチマークであるmiraclをダウンロードします。
HuggingFaceのアクセストークンが必要なため、事前にHugging Faceのアカウントページで作成し、.envファイルにHF_ACCESS_TOKENという変数名で保存しておきます。
miraclコーパスは文書(docs)とクエリ(queries)をそれぞれダウンロードし、docsはクエリの正解の文書集合とそれ以外に分けておきます。
# positive_corpus
docs = datasets.load_dataset('miracl/miracl-corpus', "ja")
queries = datasets.load_dataset("miracl/miracl", "ja", token = os.environ["HF_ACCESS_TOKEN"], split="dev")
positive_id_set = set()
for data in queries:
positive_passages = data['positive_passages']
for entry in positive_passages:
docid = entry['docid']
if docid not in positive_id_set:
positive_id_set.add(docid)
# Filter the documents based on corpus_ids
positive_docs = docs['train'].filter(lambda example: example['docid'] in positive_id_set)
docs_without_positive = docs['train'].filter(lambda example: example['docid'] not in positive_id_set)
評価の実行
指定した試行回数(loop_count)だけquery_size件のクエリとadditional_docs_size件のコーパスをランダムに取得し、hit@nを計算します。
最後に平均値と標準偏差を出力します。
hit_at_ns_list = []
query_size = 100
additional_docs_size = 10000
loop_count = 10
for _ in range(loop_count):
# クエリをランダムに100件取得
sampled_indices = random.sample(range(len(queries)), query_size)
sampled_queries = queries.select(sampled_indices)
sampled_query_texts = sampled_queries['query']
sampled_query_texts_tokenized = list(map(tokenize, sampled_query_texts))
sampled_query_positive_ids = []
for query in sampled_queries:
positive_ids = [entry['docid'] for entry in query['positive_passages']]
sampled_query_positive_ids.append(positive_ids)
# positive_textsとidsを取得
sampled_positive_ids_set = set()
for pos_ids in sampled_query_positive_ids:
for docid in pos_ids:
sampled_positive_ids_set.add(docid)
sampled_positive_docs = positive_docs.filter(lambda example: example['docid'] in sampled_positive_ids_set)
sampled_positive_texts_tokenized = list(map(tokenize, sampled_positive_docs['text']))
sampled_positive_ids = sampled_positive_docs['docid']
# additional_textsをランダムに取得
additional_docs_indices = random.sample(range(len(docs_without_positive)), additional_docs_size)
additional_docs = docs_without_positive.select(additional_docs_indices)
additional_texts_tokenized = list(map(tokenize, additional_docs['text']))
additional_ids = additional_docs['docid']
corpus_texts_tokenized = sampled_positive_texts_tokenized + additional_texts_tokenized
corpus_ids = sampled_positive_ids + additional_ids
hit_at_ns = eval_corpus(corpus_texts_tokenized, corpus_ids, sampled_query_texts_tokenized, sampled_query_positive_ids)
hit_at_ns_list.append(hit_at_ns)
# ループ全体の平均と標準偏差を取る
average_hit_at_ns = {n: {key: np.mean([hit_at_ns[n][key] for hit_at_ns in hit_at_ns_list]) for key in hit_at_ns_list[0][n].keys()} for n in hit_at_ns_list[0].keys()}
std_dev_hit_at_ns = {n: {key: np.std([hit_at_ns[n][key] for hit_at_ns in hit_at_ns_list]) for key in hit_at_ns_list[0][n].keys()} for n in hit_at_ns_list[0].keys()}
# 平均結果と標準偏差を表示
for n in average_hit_at_ns:
print(f"Average Hit@{n}: count-tfidf-dot-product: {average_hit_at_ns[n]['count-tfidf-dot-product']:.4f} (std: {std_dev_hit_at_ns[n]['count-tfidf-dot-product']:.4f}), count-tfidf-cosine-sim: {average_hit_at_ns[n]['count-tfidf-cosine-sim']:.4f} (std: {std_dev_hit_at_ns[n]['count-tfidf-cosine-sim']:.4f}), tfidf-tfidf-dot-product: {average_hit_at_ns[n]['tfidf-tfidf-dot-product']:.4f} (std: {std_dev_hit_at_ns[n]['tfidf-tfidf-dot-product']:.4f}), tfidf-tfidf-cosine-sim: {average_hit_at_ns[n]['tfidf-tfidf-cosine-sim']:.4f} (std: {std_dev_hit_at_ns[n]['tfidf-tfidf-cosine-sim']:.4f}), count-bm25-dot-product: {average_hit_at_ns[n]['count-bm25-dot-product']:.4f} (std: {std_dev_hit_at_ns[n]['count-bm25-dot-product']:.4f}), count-bm25-cosine-sim: {average_hit_at_ns[n]['count-bm25-cosine-sim']:.4f} (std: {std_dev_hit_at_ns[n]['count-bm25-cosine-sim']:.4f}), bm25-bm25-dot-product: {average_hit_at_ns[n]['bm25-bm25-dot-product']:.4f} (std: {std_dev_hit_at_ns[n]['bm25-bm25-dot-product']:.4f}), bm25-bm25-cosine-sim: {average_hit_at_ns[n]['bm25-bm25-cosine-sim']:.4f} (std: {std_dev_hit_at_ns[n]['bm25-bm25-cosine-sim']:.4f})")
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 46219.11 examples/s]
Hit@1: count-tfidf-dot-product: 0.0500, count-tfidf-cosine-sim: 0.2900, tfidf-tfidf-dot-product: 0.1500, tfidf-tfidf-cosine-sim: 0.4400, count-bm25-dot-product: 0.5500, count-bm25-cosine-sim: 0.2400, bm25-bm25-dot-product: 0.5900, bm25-bm25-cosine-sim: 0.4800
Hit@3: count-tfidf-dot-product: 0.1400, count-tfidf-cosine-sim: 0.4000, tfidf-tfidf-dot-product: 0.3000, tfidf-tfidf-cosine-sim: 0.6200, count-bm25-dot-product: 0.6900, count-bm25-cosine-sim: 0.4700, bm25-bm25-dot-product: 0.7000, bm25-bm25-cosine-sim: 0.6600
Hit@5: count-tfidf-dot-product: 0.1900, count-tfidf-cosine-sim: 0.4700, tfidf-tfidf-dot-product: 0.4100, tfidf-tfidf-cosine-sim: 0.6900, count-bm25-dot-product: 0.7400, count-bm25-cosine-sim: 0.5700, bm25-bm25-dot-product: 0.7700, bm25-bm25-cosine-sim: 0.7400
Hit@10: count-tfidf-dot-product: 0.3000, count-tfidf-cosine-sim: 0.5300, tfidf-tfidf-dot-product: 0.5400, tfidf-tfidf-cosine-sim: 0.7700, count-bm25-dot-product: 0.7800, count-bm25-cosine-sim: 0.6700, bm25-bm25-dot-product: 0.8200, bm25-bm25-cosine-sim: 0.8000
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 52743.95 examples/s]
Hit@1: count-tfidf-dot-product: 0.0500, count-tfidf-cosine-sim: 0.3200, tfidf-tfidf-dot-product: 0.1100, tfidf-tfidf-cosine-sim: 0.5100, count-bm25-dot-product: 0.5300, count-bm25-cosine-sim: 0.3500, bm25-bm25-dot-product: 0.6700, bm25-bm25-cosine-sim: 0.5400
Hit@3: count-tfidf-dot-product: 0.1000, count-tfidf-cosine-sim: 0.4200, tfidf-tfidf-dot-product: 0.3400, tfidf-tfidf-cosine-sim: 0.6500, count-bm25-dot-product: 0.6700, count-bm25-cosine-sim: 0.4800, bm25-bm25-dot-product: 0.7200, bm25-bm25-cosine-sim: 0.7000
Hit@5: count-tfidf-dot-product: 0.1400, count-tfidf-cosine-sim: 0.4900, tfidf-tfidf-dot-product: 0.4200, tfidf-tfidf-cosine-sim: 0.6800, count-bm25-dot-product: 0.6900, count-bm25-cosine-sim: 0.5300, bm25-bm25-dot-product: 0.7400, bm25-bm25-cosine-sim: 0.7300
Hit@10: count-tfidf-dot-product: 0.2400, count-tfidf-cosine-sim: 0.5600, tfidf-tfidf-dot-product: 0.6200, tfidf-tfidf-cosine-sim: 0.7300, count-bm25-dot-product: 0.7200, count-bm25-cosine-sim: 0.6000, bm25-bm25-dot-product: 0.7700, bm25-bm25-cosine-sim: 0.7500
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 49168.67 examples/s]
Hit@1: count-tfidf-dot-product: 0.0300, count-tfidf-cosine-sim: 0.3500, tfidf-tfidf-dot-product: 0.0400, tfidf-tfidf-cosine-sim: 0.5000, count-bm25-dot-product: 0.5500, count-bm25-cosine-sim: 0.3200, bm25-bm25-dot-product: 0.6100, bm25-bm25-cosine-sim: 0.5200
Hit@3: count-tfidf-dot-product: 0.1200, count-tfidf-cosine-sim: 0.5300, tfidf-tfidf-dot-product: 0.3100, tfidf-tfidf-cosine-sim: 0.6800, count-bm25-dot-product: 0.7300, count-bm25-cosine-sim: 0.4500, bm25-bm25-dot-product: 0.7600, bm25-bm25-cosine-sim: 0.6800
Hit@5: count-tfidf-dot-product: 0.2000, count-tfidf-cosine-sim: 0.5500, tfidf-tfidf-dot-product: 0.4300, tfidf-tfidf-cosine-sim: 0.7200, count-bm25-dot-product: 0.7600, count-bm25-cosine-sim: 0.5800, bm25-bm25-dot-product: 0.8000, bm25-bm25-cosine-sim: 0.7400
Hit@10: count-tfidf-dot-product: 0.2700, count-tfidf-cosine-sim: 0.6000, tfidf-tfidf-dot-product: 0.5900, tfidf-tfidf-cosine-sim: 0.7600, count-bm25-dot-product: 0.8100, count-bm25-cosine-sim: 0.6800, bm25-bm25-dot-product: 0.8200, bm25-bm25-cosine-sim: 0.8100
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 52098.66 examples/s]
Hit@1: count-tfidf-dot-product: 0.0900, count-tfidf-cosine-sim: 0.4000, tfidf-tfidf-dot-product: 0.1500, tfidf-tfidf-cosine-sim: 0.5200, count-bm25-dot-product: 0.6300, count-bm25-cosine-sim: 0.4300, bm25-bm25-dot-product: 0.6500, bm25-bm25-cosine-sim: 0.5700
Hit@3: count-tfidf-dot-product: 0.1300, count-tfidf-cosine-sim: 0.5000, tfidf-tfidf-dot-product: 0.3300, tfidf-tfidf-cosine-sim: 0.7000, count-bm25-dot-product: 0.7300, count-bm25-cosine-sim: 0.5600, bm25-bm25-dot-product: 0.8000, bm25-bm25-cosine-sim: 0.7400
Hit@5: count-tfidf-dot-product: 0.1800, count-tfidf-cosine-sim: 0.5400, tfidf-tfidf-dot-product: 0.4800, tfidf-tfidf-cosine-sim: 0.7100, count-bm25-dot-product: 0.7400, count-bm25-cosine-sim: 0.5800, bm25-bm25-dot-product: 0.8400, bm25-bm25-cosine-sim: 0.8300
Hit@10: count-tfidf-dot-product: 0.2500, count-tfidf-cosine-sim: 0.5900, tfidf-tfidf-dot-product: 0.6000, tfidf-tfidf-cosine-sim: 0.8200, count-bm25-dot-product: 0.8000, count-bm25-cosine-sim: 0.6700, bm25-bm25-dot-product: 0.8600, bm25-bm25-cosine-sim: 0.8500
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 48303.25 examples/s]
Hit@1: count-tfidf-dot-product: 0.0400, count-tfidf-cosine-sim: 0.3300, tfidf-tfidf-dot-product: 0.1100, tfidf-tfidf-cosine-sim: 0.4500, count-bm25-dot-product: 0.4900, count-bm25-cosine-sim: 0.3200, bm25-bm25-dot-product: 0.6300, bm25-bm25-cosine-sim: 0.4900
Hit@3: count-tfidf-dot-product: 0.1700, count-tfidf-cosine-sim: 0.4300, tfidf-tfidf-dot-product: 0.3200, tfidf-tfidf-cosine-sim: 0.6200, count-bm25-dot-product: 0.6400, count-bm25-cosine-sim: 0.4500, bm25-bm25-dot-product: 0.6900, bm25-bm25-cosine-sim: 0.6900
Hit@5: count-tfidf-dot-product: 0.1900, count-tfidf-cosine-sim: 0.4900, tfidf-tfidf-dot-product: 0.4100, tfidf-tfidf-cosine-sim: 0.6900, count-bm25-dot-product: 0.6800, count-bm25-cosine-sim: 0.5800, bm25-bm25-dot-product: 0.7600, bm25-bm25-cosine-sim: 0.7300
Hit@10: count-tfidf-dot-product: 0.3200, count-tfidf-cosine-sim: 0.5600, tfidf-tfidf-dot-product: 0.5900, tfidf-tfidf-cosine-sim: 0.7400, count-bm25-dot-product: 0.7400, count-bm25-cosine-sim: 0.6500, bm25-bm25-dot-product: 0.7900, bm25-bm25-cosine-sim: 0.7800
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 47342.50 examples/s]
Hit@1: count-tfidf-dot-product: 0.0600, count-tfidf-cosine-sim: 0.2900, tfidf-tfidf-dot-product: 0.1300, tfidf-tfidf-cosine-sim: 0.4000, count-bm25-dot-product: 0.5000, count-bm25-cosine-sim: 0.3100, bm25-bm25-dot-product: 0.5800, bm25-bm25-cosine-sim: 0.4300
Hit@3: count-tfidf-dot-product: 0.1700, count-tfidf-cosine-sim: 0.4400, tfidf-tfidf-dot-product: 0.2400, tfidf-tfidf-cosine-sim: 0.6000, count-bm25-dot-product: 0.6500, count-bm25-cosine-sim: 0.4700, bm25-bm25-dot-product: 0.7400, bm25-bm25-cosine-sim: 0.6300
Hit@5: count-tfidf-dot-product: 0.2000, count-tfidf-cosine-sim: 0.5100, tfidf-tfidf-dot-product: 0.3900, tfidf-tfidf-cosine-sim: 0.6400, count-bm25-dot-product: 0.7000, count-bm25-cosine-sim: 0.5200, bm25-bm25-dot-product: 0.7600, bm25-bm25-cosine-sim: 0.7500
Hit@10: count-tfidf-dot-product: 0.2900, count-tfidf-cosine-sim: 0.5400, tfidf-tfidf-dot-product: 0.5600, tfidf-tfidf-cosine-sim: 0.7500, count-bm25-dot-product: 0.7700, count-bm25-cosine-sim: 0.6100, bm25-bm25-dot-product: 0.7900, bm25-bm25-cosine-sim: 0.7700
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 25747.28 examples/s]
Hit@1: count-tfidf-dot-product: 0.0700, count-tfidf-cosine-sim: 0.2600, tfidf-tfidf-dot-product: 0.2100, tfidf-tfidf-cosine-sim: 0.4800, count-bm25-dot-product: 0.5500, count-bm25-cosine-sim: 0.3800, bm25-bm25-dot-product: 0.6800, bm25-bm25-cosine-sim: 0.6200
Hit@3: count-tfidf-dot-product: 0.1700, count-tfidf-cosine-sim: 0.4400, tfidf-tfidf-dot-product: 0.3700, tfidf-tfidf-cosine-sim: 0.6500, count-bm25-dot-product: 0.7000, count-bm25-cosine-sim: 0.5200, bm25-bm25-dot-product: 0.7700, bm25-bm25-cosine-sim: 0.7600
Hit@5: count-tfidf-dot-product: 0.2400, count-tfidf-cosine-sim: 0.4800, tfidf-tfidf-dot-product: 0.4400, tfidf-tfidf-cosine-sim: 0.7500, count-bm25-dot-product: 0.7700, count-bm25-cosine-sim: 0.6100, bm25-bm25-dot-product: 0.7800, bm25-bm25-cosine-sim: 0.7900
Hit@10: count-tfidf-dot-product: 0.3200, count-tfidf-cosine-sim: 0.5700, tfidf-tfidf-dot-product: 0.5900, tfidf-tfidf-cosine-sim: 0.8000, count-bm25-dot-product: 0.8000, count-bm25-cosine-sim: 0.7100, bm25-bm25-dot-product: 0.7900, bm25-bm25-cosine-sim: 0.8000
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 52497.54 examples/s]
Hit@1: count-tfidf-dot-product: 0.0700, count-tfidf-cosine-sim: 0.2800, tfidf-tfidf-dot-product: 0.1100, tfidf-tfidf-cosine-sim: 0.3000, count-bm25-dot-product: 0.4100, count-bm25-cosine-sim: 0.2600, bm25-bm25-dot-product: 0.4800, bm25-bm25-cosine-sim: 0.4600
Hit@3: count-tfidf-dot-product: 0.1300, count-tfidf-cosine-sim: 0.4100, tfidf-tfidf-dot-product: 0.2600, tfidf-tfidf-cosine-sim: 0.5300, count-bm25-dot-product: 0.5700, count-bm25-cosine-sim: 0.4000, bm25-bm25-dot-product: 0.5900, bm25-bm25-cosine-sim: 0.5800
Hit@5: count-tfidf-dot-product: 0.1700, count-tfidf-cosine-sim: 0.4300, tfidf-tfidf-dot-product: 0.3200, tfidf-tfidf-cosine-sim: 0.5900, count-bm25-dot-product: 0.6100, count-bm25-cosine-sim: 0.4800, bm25-bm25-dot-product: 0.6700, bm25-bm25-cosine-sim: 0.6500
Hit@10: count-tfidf-dot-product: 0.2800, count-tfidf-cosine-sim: 0.4800, tfidf-tfidf-dot-product: 0.5100, tfidf-tfidf-cosine-sim: 0.6900, count-bm25-dot-product: 0.6800, count-bm25-cosine-sim: 0.5600, bm25-bm25-dot-product: 0.7600, bm25-bm25-cosine-sim: 0.7200
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 44676.36 examples/s]
Hit@1: count-tfidf-dot-product: 0.0600, count-tfidf-cosine-sim: 0.3500, tfidf-tfidf-dot-product: 0.1700, tfidf-tfidf-cosine-sim: 0.4800, count-bm25-dot-product: 0.5500, count-bm25-cosine-sim: 0.3200, bm25-bm25-dot-product: 0.6400, bm25-bm25-cosine-sim: 0.5200
Hit@3: count-tfidf-dot-product: 0.1800, count-tfidf-cosine-sim: 0.5000, tfidf-tfidf-dot-product: 0.3800, tfidf-tfidf-cosine-sim: 0.6200, count-bm25-dot-product: 0.6600, count-bm25-cosine-sim: 0.4700, bm25-bm25-dot-product: 0.7500, bm25-bm25-cosine-sim: 0.6700
Hit@5: count-tfidf-dot-product: 0.2700, count-tfidf-cosine-sim: 0.5100, tfidf-tfidf-dot-product: 0.4400, tfidf-tfidf-cosine-sim: 0.6700, count-bm25-dot-product: 0.7100, count-bm25-cosine-sim: 0.5400, bm25-bm25-dot-product: 0.7800, bm25-bm25-cosine-sim: 0.7600
Hit@10: count-tfidf-dot-product: 0.3200, count-tfidf-cosine-sim: 0.5500, tfidf-tfidf-dot-product: 0.5900, tfidf-tfidf-cosine-sim: 0.7300, count-bm25-dot-product: 0.7600, count-bm25-cosine-sim: 0.6200, bm25-bm25-dot-product: 0.8100, bm25-bm25-cosine-sim: 0.8100
Filter: 100%|██████████| 1728/1728 [00:00<00:00, 49130.34 examples/s]
Hit@1: count-tfidf-dot-product: 0.0100, count-tfidf-cosine-sim: 0.3300, tfidf-tfidf-dot-product: 0.0000, tfidf-tfidf-cosine-sim: 0.3600, count-bm25-dot-product: 0.5100, count-bm25-cosine-sim: 0.3500, bm25-bm25-dot-product: 0.5700, bm25-bm25-cosine-sim: 0.4300
Hit@3: count-tfidf-dot-product: 0.0800, count-tfidf-cosine-sim: 0.4500, tfidf-tfidf-dot-product: 0.1800, tfidf-tfidf-cosine-sim: 0.5800, count-bm25-dot-product: 0.6100, count-bm25-cosine-sim: 0.4700, bm25-bm25-dot-product: 0.7100, bm25-bm25-cosine-sim: 0.6300
Hit@5: count-tfidf-dot-product: 0.1700, count-tfidf-cosine-sim: 0.5300, tfidf-tfidf-dot-product: 0.3600, tfidf-tfidf-cosine-sim: 0.6600, count-bm25-dot-product: 0.6500, count-bm25-cosine-sim: 0.5500, bm25-bm25-dot-product: 0.7700, bm25-bm25-cosine-sim: 0.7000
Hit@10: count-tfidf-dot-product: 0.2600, count-tfidf-cosine-sim: 0.6100, tfidf-tfidf-dot-product: 0.5300, tfidf-tfidf-cosine-sim: 0.7300, count-bm25-dot-product: 0.7500, count-bm25-cosine-sim: 0.6200, bm25-bm25-dot-product: 0.8300, bm25-bm25-cosine-sim: 0.8000
Average Hit@1: count-tfidf-dot-product: 0.0530 (std: 0.0215), count-tfidf-cosine-sim: 0.3200 (std: 0.0392), tfidf-tfidf-dot-product: 0.1180 (std: 0.0579), tfidf-tfidf-cosine-sim: 0.4440 (std: 0.0676), count-bm25-dot-product: 0.5270 (std: 0.0537), count-bm25-cosine-sim: 0.3280 (std: 0.0519), bm25-bm25-dot-product: 0.6100 (std: 0.0559), bm25-bm25-cosine-sim: 0.5060 (std: 0.0577)
Average Hit@3: count-tfidf-dot-product: 0.1390 (std: 0.0318), count-tfidf-cosine-sim: 0.4520 (std: 0.0412), tfidf-tfidf-dot-product: 0.3030 (std: 0.0581), tfidf-tfidf-cosine-sim: 0.6250 (std: 0.0465), count-bm25-dot-product: 0.6650 (std: 0.0482), count-bm25-cosine-sim: 0.4740 (std: 0.0403), bm25-bm25-dot-product: 0.7230 (std: 0.0548), bm25-bm25-cosine-sim: 0.6740 (std: 0.0506)
Average Hit@5: count-tfidf-dot-product: 0.1950 (std: 0.0350), count-tfidf-cosine-sim: 0.5000 (std: 0.0341), tfidf-tfidf-dot-product: 0.4100 (std: 0.0427), tfidf-tfidf-cosine-sim: 0.6800 (std: 0.0422), count-bm25-dot-product: 0.7050 (std: 0.0476), count-bm25-cosine-sim: 0.5540 (std: 0.0358), bm25-bm25-dot-product: 0.7670 (std: 0.0412), bm25-bm25-cosine-sim: 0.7420 (std: 0.0458)
Average Hit@10: count-tfidf-dot-product: 0.2850 (std: 0.0284), count-tfidf-cosine-sim: 0.5590 (std: 0.0359), tfidf-tfidf-dot-product: 0.5720 (std: 0.0334), tfidf-tfidf-cosine-sim: 0.7520 (std: 0.0357), count-bm25-dot-product: 0.7610 (std: 0.0383), count-bm25-cosine-sim: 0.6390 (std: 0.0425), bm25-bm25-dot-product: 0.8040 (std: 0.0284), bm25-bm25-cosine-sim: 0.7890 (std: 0.0342)
グラフ作成
matplotlibでグラフを作成します。
import matplotlib.pyplot as plt
# グラフの設定
fig, ax = plt.subplots(figsize=(12, 8))
# 各Hit@Nについてプロット
for n in average_hit_at_ns:
x = list(average_hit_at_ns[n].keys())
y = list(average_hit_at_ns[n].values())
yerr = list(std_dev_hit_at_ns[n].values())
ax.errorbar(x, y, yerr=yerr, label=f'Hit@{n}', fmt='-o', capsize=5)
# グラフのラベルとタイトル
ax.set_xlabel('Method')
ax.set_ylabel('Score')
ax.set_title('Average Hit@N with Standard Deviation')
ax.legend()
# x軸のラベルを回転
plt.xticks(rotation=45, ha='right')
# グラフを表示
plt.tight_layout()
plt.show()
検定
本文には含めませんでしたが、検定を実行する場合のコードです。
試行ごとにデータが対応するので対応のあるt検定を行っています。
8条件のペアワイズすべてを検定すると検定数が多くなりすぎ、多重検定の影響が無視できなくなりそうなので、注目する条件を絞って検定します。
以下ではbm25のクエリカウントベクトルの内積と重みベクトルのコサイン類似度の条件を比較しています。p<0.001で有意なようです。
有意だからといって、同じベンチマークからのサンプリングでは結果が似ることもあり得るため、ベンチマーク自体のバリエーションを増やすことが必要だと思います。
from scipy.stats import ttest_rel
# Hit@10の結果を抽出
hit_at_10_results = {key: [hit_at_ns[10][key] for hit_at_ns in hit_at_ns_list] for key in hit_at_ns_list[0][10].keys()}
# 比較するメソッドのペアを定義
method_pairs = [
('count-bm25-dot-product', 'bm25-bm25-dot-product'),
]
# t検定を実行して結果を表示
for method1, method2 in method_pairs:
t_stat, p_value = ttest_rel(hit_at_10_results[method1], hit_at_10_results[method2])
print(f"t検定結果 ({method1} vs {method2}): t値 = {t_stat:.4f}, p値 = {p_value:.4f}")
t検定結果 (count-bm25-dot-product vs bm25-bm25-dot-product): t値 = -5.6530, p値 = 0.0003
参考資料
- 本記事に至るまでに筆者が過去に色々検討した記事
-
Python: scikit-learn と色々な TF-IDF の定義について
- scikit-learnのTFIDFの計算方法が若干クセがあるため、この記事で勉強しました。
-
現代版 TF-IDF である Okapi BM25 の原理について(前半)
- 後半と合わせて、キーワード検索が解決したい課題ベースで、BM25の式の成り立ちを解説してくれている。この記事を読むと、クエリはカウントベクトルで良いような気がしてくるが、今回はクエリは重みベクトルにしたほうが良さそうという結果だったので不思議。
-
厳密には、IDFは二乗されますが、TFに相当する部分は計算方法によっては二乗と厳密に一致しないこともあります。 ↩