今回はactor-criticでbtc/jpyのシステムトレードアルゴリズムを開発します。
actor-criticとは
Qiitaで検索しましょう。似たようなことを書いても長くなるだけです。
データセット
チャートデータは始値、高値、安値、終値の4つの時系列データで構成されていて、そこに出来高も追加して5次元データで表します。今回はbtc/jpyの取引データを1時間おきに蓄積したものを用います。データの中身はこんな感じのcsvで、2011年から2017年くらいまでで約4万レコードあります。
全体はhttps://raw.githubusercontent.com/shiibashi/qiita/master/11/dataset/btc.csv
にあります。
Year,Month,Day,Hour,Minute,Open,High,Low,Close,Volume,Timestamp,Timestamp_diff_1
2011,12,31,9,43,4.247,4.247,4.247,4.247,0.4,1325324580,
2011,12,31,12,1,4.1,4.1,4.1,4.1,0.623628,1325332860,8280.0
2011,12,31,13,15,4.1,4.1,4.1,4.1,6.503072,1325337300,4440.0
2011,12,31,14,27,4.045,4.045,4.044,4.044,2.3793,1325341620,4320.0
2011,12,31,15,22,4.218,4.218,4.218,4.218,0.200462,1325344920,1680.0
加えて、チャート画像も使います。https://qiita.com/shiibass/items/19ff37604cca8eac5939
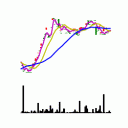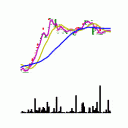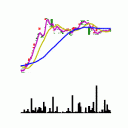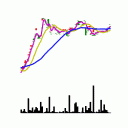
で開発したチャート画像生成を用いて以下のような画像を生成します。
単位時間ごとに生成し、連続で再生すると以下のように時間変化に伴うチャートの変化を表現することができます。単位時間分生成するので4万枚近くの画像もデータセットになります。
実装
実装したコードはここです。
https://github.com/shiibashi/qiita/tree/master/11
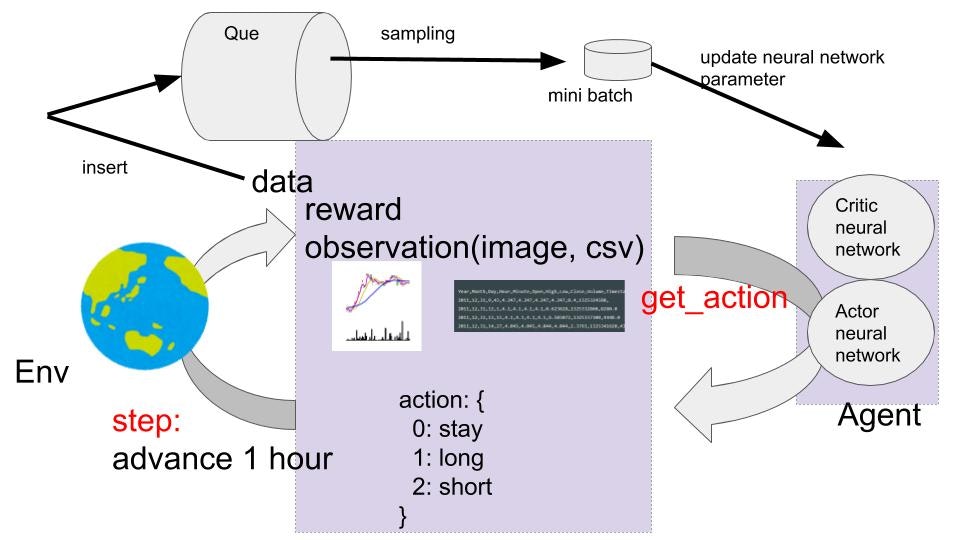
全体イメージとしてはこんな感じです。
- Agentはactorとcriticの2種類の機械学習モデルを持つ
- Agentはobservationを引数としたget_actionメソッドでactionを返す
- actionは3種類の行動がある(様子見, 買いポジ、売りポジ)
- EnvはAgentのactionを引数としたstepメソッドで仮想環境内の時間を進める
- stepメソッドで結果としてrewardと次時間のobservationを得る
- action, reward, observationをdataとしてキューに蓄積する(プログラムではdone_flagというもう一つをインサートしてる)
- キューから一部選択して学習用データとする
- 学習用データでactorとcriticを学習させる
実装上はactorやcriticをどういうモデルにするのか、get_actionの行動選択にノイズを与えて学習の効率化を図るとか、キューからデータを選択するときに効率的に学習が進むように選ぶとか、いろいろあるようですがベースの考え方としては上記だと認識しています。
学習
データセットの一部を取り出して7400時間分を学習環境としました。
推論
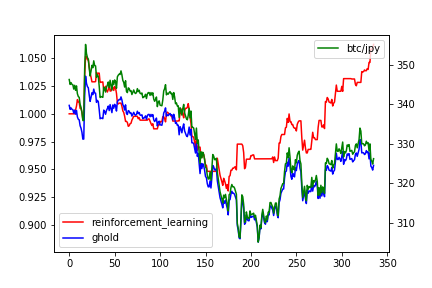
学習期間の後の2週間をテスト環境としました。その環境で推論させた結果が以下になります。横軸は時間軸で1が1時間に相当します。緑(第二軸)がbtc/jpyで345くらいスタートの325くらいエンドの推移になります。青と赤(第一軸)がトレードアルゴリズムの成果を表していて、赤が今回開発した強化学習、青がガチホ(開始時に買ってずっとホールド)になります。複利や手数料などの細かい計算は除外しています。強化学習では下がるときにポジションを決済したり空売りをいれることで損益を抑えるどころか利益を獲得している場面もあります。ガチホでは5%くらいのマイナスで終えていますが、強化学習では5%のプラスで、強化学習の強さがわかります。シストレを導入するメリットはそのほかにもあって、1時間単位ではなく1分単位でも人間では難しい粒度での意思決定が可能であることで、寝てる間も勝負できますし、夜間の暴落も検知すれば即決済で離脱することもできます。
論文紹介
この界隈の論文を紹介します。
Multimodal Deep Learning for Finance: Integrating and Forecasting International Stock Markets
https://arxiv.org/pdf/1903.06478.pdf
マルチモーダルディープラーニングはどの企業でも今後重要になる可能性が高い手法だと考えています。その判断理由としてはどの企業でも保持しているデータ形式はさまざまでしょう。画像や動画、テーブルデータ、テキストデータなど多くのデータからなる事象に対して機械学習をしていくなら当然この技術は必要になってきます。
今回私が実装したものはCSVとImageのマルチモーダルですが、論文では韓国とアメリカのデータセットを同時に学習させています。
Optimistic Bull or Pessimistic Bear: Adaptive Deep Reinforcement Learning for Stock Portfolio Allocation
https://arxiv.org/pdf/1907.01503.pdf
ICML 2019っていうのに出てる論文らしいです。actionの設定やactor-criticの選定など私の設計とかなり似た実装になっています。似たような設計で実装している事例もあるので私の実装の妥当性を多少は認めてもらえるのではないかと思います。残念なことにgithubは公開しておりませんでした。
まとめ
強化学習を用いたシストレを紹介しました。株式市場ではアルゴリズムトレードが盛んで、普通にやって勝てないならアルゴリズムで勝負しにいくのはありだと思います。エンジニアであればアルゴリズム開発やサーバ構築は容易でしょうから、もしかしたら爆益を生み出すかもしれません。興味があればぜひやってみましょう。