TL;DR
-
COTOHA APIに実装されている
{type: 'kuzure'}の正体をつきとめようとしたが、デフォルト設定との違いが ほぼ無く 、正体がわからないことがわかった。 -
正しい使い方・活用法を知っている人がいればご一報ください。
- コメント で回答いただきました。
-
以降の文章は四苦八苦の記録でしかありません。
- 最後まで読んでも結論は変わりません
ちなみに、テキストファイルに対してAPIを実行するためのコードを実装して公開しました。 Gist
はじめに
COTOHA APIでプレゼント企画 をやっているときき、COTOHA APIを使ってみました。
自然言語処理関連の便利なAPIが提供されているのですが、API リファレンスを読んでいて気になったのが type オプションの kuzure です。
だいたい全てのAPIについて、オプションで選択できるのですが、説明が
SNSなどの崩れた文
しかありません。
 (どのAPIもこの説明です)
(どのAPIもこの説明です)
デフォルトとどれぐらい違う結果を出力するのでしょうか?
気になります。
そういう訳で、調べます。
コード
PythonでAPIを叩くコードを実装しました。
以下の実行環境で動作確認しています。
- macOS Catalina
- Python 3.7.3
動作に用いられるファイルは大きく3つです。
cotoha_api.py
- COTOHA APIを扱うクラスを定義しています
- アクセストークンの取得やポストは requests を使いました
cotoha_api.py
import sys
import os
import json
import configparser
import logging
import requests
logger = logging.getLogger('cotoha_api')
# ソースファイルの場所取得
APP_ROOT = os.path.dirname(os.path.abspath(__file__)) + '/'
class CotohaApi:
"""Cotoha class"""
def __init__(self,
client_id,
client_secret,
developer_api_base_url,
access_token_publish_url,
endpoints=None):
self.client_id = client_id
self.client_secret = client_secret
self.developer_api_base_url = developer_api_base_url
self.access_token_publish_url = access_token_publish_url
self.access_token = self.get_access_token()
self.headers = {
'Content-Type': 'application/json',
'charset': 'UTF-8',
'Authorization': 'Bearer {}'.format(self.access_token)
}
self.endpoints = endpoints
def get_access_token(self):
# アクセストークン取得URL指定
url = str(self.access_token_publish_url)
# ヘッダ指定
headers={
'Content-Type': 'application/json;charset=UTF-8'
}
# リクエストボディ指定
data = {
'grantType': 'client_credentials',
'clientId': self.client_id,
'clientSecret': self.client_secret
}
# レスポンスボディからアクセストークンを取得
r = requests.post(url,
headers=headers,
data=json.dumps(data))
if r.status_code == requests.codes.created:
return r.json()['access_token']
else:
logger.warning('bad status_code {}'.format(r))
raise AssertionError('Not get access token')
def request(self, mode: str, params: dict):
if self.endpoints.get(mode) is None:
raise KeyError(' "{}" is not found in endpoints'.format(mode))
url = self.developer_api_base_url + self.endpoints[mode]
r = requests.post(url,
headers=self.headers,
data=json.dumps(params))
if not r.status_code == requests.codes.ok:
logger.warning('bad request {}'.format(r))
return r.json()
def get_result(self, mode, params):
"""apiをリクエストし、レスポンスに問題がなければ結果を返す"""
logger.info(params)
res = self.request(mode=mode, params=params)
status = res.get('status')
if status == 0:
result = res['result']
logger.info('get result {}'.format(result))
return result
else:
msg = 'status error {}, {}'.format(status, res['message'])
logger.warning(msg=msg)
raise Exception(msg)
def load_cotoha(ini_file='config.ini'):
"""設定ファイルを読み込み、CotohaApiを作成"""
config = configparser.ConfigParser()
config.read(os.path.join(APP_ROOT, ini_file))
CLIENT_ID = config.get('COTOHA API', 'Developer Client id')
CLIENT_SECRET = config.get('COTOHA API', 'Developer Client secret')
DEVELOPER_API_BASE_URL = config.get('COTOHA API', 'Developer API Base URL')
ACCESS_TOKEN_PUBLISH_URL = config.get('COTOHA API', 'Access Token Publish URL')
# {mode: url} の dict
endpoints = dict(config.items('endpoint'))
# COTOHA APIインスタンス生成
cotoha_api = CotohaApi(CLIENT_ID, CLIENT_SECRET, DEVELOPER_API_BASE_URL, ACCESS_TOKEN_PUBLISH_URL,
endpoints=endpoints)
return cotoha_api
cli.py
- ファイルやオプションなど引数を受け取るインタフェースです
- 複数の設定についてコマンドラインで扱うために click を使いました
-
typeやmax_keyword_numといったオプションもコマンドから指定できます -
typeは型判定の関数として標準で使われているため、stypeにしています
-
cli.py
全部のAPIについて載せると長くなるので、一部省略 しています
import logging
import click
from cotoha_api import load_cotoha
logger = logging.getLogger(__name__)
@click.group()
@click.argument('file', type=click.File('r'))
@click.option('-v', '--verbose', is_flag=True)
@click.pass_context
def cli(ctx, file, verbose):
if verbose:
set_logger()
logger.info('update logger setting')
ctx.ensure_object(dict)
ctx.obj['cotoha_api'] = load_cotoha()
logger.info('get access token {}'.format(ctx.obj['cotoha_api'].access_token))
text = file.read()
logger.info('load text\n{}'.format(text))
ctx.obj['file'] = text
@cli.command('parse')
@click.option('--stype', default='default', help='default or kuzure')
@click.pass_context
def parse(ctx, stype):
"""構文解析"""
mode = 'parse'
click.echo(mode)
cotoha_api = ctx.obj['cotoha_api']
params = {'sentence': str(ctx.obj['file']), 'type': stype}
result = cotoha_api.get_result(mode, params)
for r in result:
print(r)
@cli.command('ne')
@click.option('--stype', default='default', help='default or kuzure')
@click.pass_context
def ne(ctx, stype):
"""固有表現抽出"""
mode = 'ne'
click.echo(mode)
cotoha_api = ctx.obj['cotoha_api']
params = {'sentence': str(ctx.obj['file']), 'type': stype}
result = cotoha_api.get_result(mode, params)
for r in result:
print(r)
@cli.command('coreference')
@click.option('--stype', default='default', help='default or kuzure')
@click.option('--do_segment', default=False)
@click.pass_context
def coreference(ctx, stype, do_segment):
"""照応解析"""
mode = 'coreference'
click.echo(mode)
cotoha_api = ctx.obj['cotoha_api']
data = str(ctx.obj['file'])
# if array: data = data.splitlines()
params = {'document': data,
'type': stype,
'do_segment': do_segment}
result = cotoha_api.get_result(mode, params)
for c in result.get('coreference'):
print(c)
print(result.get('tokens'))
@cli.command('keyword')
# @click.option('--array', default=False, help='array(string) flag')
@click.option('--stype', default='default', help='default or kuzure')
@click.option('--do_segment', is_flag=True)
@click.option('--max_keyword_num', default=5)
@click.pass_context
def keyword(ctx, stype, do_segment, max_keyword_num):
"""キーワード抽出"""
mode = 'keyword'
click.echo(mode)
cotoha_api = ctx.obj['cotoha_api']
data = str(ctx.obj['file'])
# if array: data = data.splitlines()
params = {'document': data,
'type': stype,
'do_segment': do_segment,
'max_keyword_num': max_keyword_num
}
result = cotoha_api.get_result(mode, params)
for r in result:
print(r)
@cli.command('user_attribute')
# @click.option('--array', default=False, help='array(string) flag')
@click.option('--stype', default='default', help='default or kuzure')
@click.option('--do_segment', is_flag=True)
@click.pass_context
def user_attribute(ctx, stype, do_segment):
"""ユーザ属性推定"""
mode = 'user_attribute'
click.echo(mode)
cotoha_api = ctx.obj['cotoha_api']
data = str(ctx.obj['file'])
# if array: data = data.splitlines()
params = {'document': data,
'type': stype,
'do_segment': do_segment}
result = cotoha_api.get_result(mode, params)
print(result)
if __name__ == '__main__':
cli(obj={})
config.ini
- Developer Client id などを設定を記録しているファイルです
- APIごとのエンドポイントも保存しておきます (beta だったり v1だったりするので)
config.ini
[COTOHA API]
Developer API Base URL: https://api.ce-cotoha.com/api/dev/
Developer Client id: <your developer client id>
Developer Client secret: <your developer client secret>
Access Token Publish URL: <your access token publish url>
[endpoint]
parse: nlp/v1/parse
ne: nlp/v1/ne
coreference: nlp/v1/coreference
(略)
sentiment: nlp/v1/sentiment
summary: nlp/beta/summary
実際の実装は Gist にアップロードしているので、ダウンロードして利用可能です。
(コードにミスがあった時に、基本的にはGistの方を先に最新にすると思います。)
使い方
-
config.iniに自分のIDなどの情報を追加し、保存 -
cli.pyを実行- テキストファイルと利用したいAPIを指定する必要があります
- APIの詳細は
python cli.pyで一覧表示されます
$ python cli.py
>>
Usage: cli.py [OPTIONS] FILE COMMAND [ARGS]...
Options:
-v, --verbose
--help Show this message and exit.
Commands:
coreference 照応解析
detect_misrecognition 音声認識誤り検知
keyword キーワード抽出
ne 固有表現抽出
parse 構文解析
remove_filler 言い淀み除去
sentence_type 文タイプ判定
sentiment 感情分析
similarity 類似度算出
summary 要約
user_attribute ユーザ属性推定
例えば固有表現抽出であれば ne を指定します
$python cli.py sample_text.txt ne
kuzure を指定したい場合は --stype kuzure を追加します
$python cli.py sample_text.txt ne --stype kuzure
以降、このコードを実行した結果を実行結果として記載します。
kuzure が実装されたAPI
リクエストボディの type で kuzure が選択可能な機能は以下の通りです。
- 構文解析
- 固有表現抽出
- 照応解析
- キーワード抽出
- 文タイプ判定
- ユーザー属性推定
(言い淀み除去は do_segment に kuzure が選択できますが別物と思われます)
出力を比較して kuzure の正体を突き止める
今回は InstagramとTwitterのテキストを使って、 kuzure かどうかで出力がどう変化するか調査します。
利用するするテキストは案の定コピペというアナログな方法で取得しています。
Instagramのハッシュタグ
Instagramにおける 崩れた文 要素はハッシュタグ (#)ではないでしょうか?
エンテティに対して # がついているのは通常の文章ではありえません。
kuzure によって、この # がうまいこと除去されたり、タグだけ取得できたらうれしい気がします。
検索で引っかかることを目的としている、ハッシュタグが大量についた宣伝 (?) アカウントについて、「キーワード抽出」をしてみます。
monun_cute
- かわいいが大好きな女の子“キューター”のためのコミュニティメディア
- https://www.instagram.com/p/B9Whxa2hkNO/ のテキスト
monun_cute.txt
今シーズンはほんのり透ける
シアーシャツの肌見せがせ正解😋🤍
いつものコーデにマンネリを感じてきたら
シアーシャツを選んでみて👔💭
着回しコーデに大活躍のアイテムだよ🐰💕
photo by
@dazzlin_muse_miki
@moe___u
@__nonbaby
@anna__325
@ra_grm
ありがとうございます😘
ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ
::::::::::୨୧::::::::::୨୧::::::::::୨୧::::::::::::୨୧::::::::::
ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ
monunでは紹介させていただく写真を募集中❣️
@monun_cute をタグ付けするか、
ハッシュタグ#monun_cute をつけてみんなのかわいい写真をシェアしてね📷💫
# monun#モニュン#キューター#かわいい#おしゃれ#おしゃれさんと繋がりたい#インスタ探検隊#トレンドアイテム#手持ち倶楽部#フォトジェニック#l4l#lfl#f4f#fff #春コーデ#コーデ#シアーシャツ#コーティネート #シャツコーデ #トレンドコーデ #春服コーデ #トレンドファッション
デフォルト設定の出力
{'form': 'コーデ', 'score': 20.0}
{'form': 'fff #春コーデ#コーデ#シアーシャツ#コーティネート #シャツコーデ #トレンドコーデ #春服コーデ #トレンドファッション', 'score': 20.0}
{'form': '紹介', 'score': 15.29816}
{'form': 'フォトジェニック', 'score': 12.8053}
{'form': 'cute', 'score': 11.889}
kuzure を指定した時の出力
{'form': 'コーデ', 'score': 20.0}
{'form': 'fff #春コーデ#コーデ#シアーシャツ#コーティネート #シャツコーデ #トレンドコーデ #春服コーデ #トレンドファッション', 'score': 20.0}
{'form': '紹介', 'score': 15.29816}
{'form': 'フォトジェニック', 'score': 12.8053}
{'form': 'cute', 'score': 11.889}
どうやら全く同じ出力のようです。
また、ハッシュタグを含む単語群 (fff #春コーデ#コーデ#〜) が1つのキーワードとして扱われてしまっています。
CANMAKE
- キャンメイク 日本公式アカウントです
- https://www.instagram.com/p/B9S3ofoHz8q/
canmake.txt
テクニックいらずでプロ級仕上げ!
キャンメイクのブラシ&アイラッシュカーラーでメイクをランクアップしちゃおう♪
・パウダーチーク用の毛足短め凸型タイプ 「チークブラシ」700円(税抜)
・横長・広めのラウンド型チークブラシ 「ソフトチークブラシ」700円(税抜)
・リキッド・パウダー・クリーム・エマルジョンタイプに使える 「フェイスブラシ」800円(税抜)
・パウダーハイライト用 「ハイライトブラシ」650円(税抜)
・パウダータイプ用のフラット型ブラシ(ケース付き)
「マシュマロフィニッシュフェイスブラシ」600円(税抜)
・幅38㎜の万能サイズ 「アイラッシュカーラー」600円(税抜)
・幅40㎜のワイドなフラットエッジタイプ 「ワイドフィットカーラー」600円(税抜)
どれも使い方は簡単!メイク初心者さんもぜひチェックしてみてね♡
# CANMAKE #CANMAKETOKYO #キャンメイク #かわいいに出会える #プチプラコスメ #コスパコスメ #メイク #メイクブラシ #チークブラシ #ソフトチークブラシ #フェイスブラシ #ハイライトブラシ #マシュマロフィニッシュフェイスブラシ #アイラッシュカーラー #ワイドフィットカーラー #テクニックいらず #メイク上手 #makeup #makeupbrushes #facebrushes #cheekbrushes #highlightsbrushes #eyelashcurlers
デフォルト設定の出力
{'form': 'チェック', 'score': 20.1288}
{'form': 'プチプラコスメ #コスパコスメ #メイク #メイクブラシ #チークブラシ #ソフトチークブラシ #フェイスブラシ #ハイライトブラシ #マシュマロフィニッシュフェイスブラシ #アイラッシュカーラー #ワイドフィットカーラー #テクニックいらず #メイク上手 #makeup #makeupbrushes #facebrushes #cheekbrushes #highlightsbrushes #eyelashcurlers', 'score': 20.0}
{'form': 'ランクアップ', 'score': 18.73196}
{'form': 'ワイド', 'score': 15.63646}
{'form': '初心者さん', 'score': 10.67915}
kuzure を指定した時の出力
{'form': 'チェック', 'score': 20.1288}
{'form': 'プチプラコスメ #コスパコスメ #メイク #メイクブラシ #チークブラシ #ソフトチークブラシ #フェイスブラシ #ハイライトブラシ #マシュマロフィニッシュフェイスブラシ #アイラッシュカーラー #ワイドフィットカーラー #テクニックいらず #メイク上手 #makeup #makeupbrushes #facebrushes #cheekbrushes #highlightsbrushes #eyelashcurlers', 'score': 20.0}
{'form': 'ランクアップ', 'score': 18.73196}
{'form': '使い方', 'score': 18.08021}
{'form': 'ワイド', 'score': 15.63646}
kuzure を指定したところ、初心者さん のかわりに 使い方 がキーワードとして出力されました。
他の出力はほぼ同じです。最初の例と同様、ハッシュタグを含む単語群問題も発生しています。
Instagramの有名人投稿
ハッシュタグを含むテキストのキーワード抽出で、特に差異がみられませんでした。
しかしながら、Instagramに疎いので、ハッシュタグ以外の特徴が思いつきません。
愚直に有名人の投稿について調べてみます。
個人差はありますが、絵文字を多用していたり、文体も比較的 崩れている かなと思います。そこら辺をうまいこと扱えたら良さそうです。
また、ユーザー属性推定も違いがあるか、調べたいと思います。
Naomi Watanabe
- フォロワー数が多い有名人
- 投稿テキストが日本語+英語というバウリンガル仕様なので、日本語だけ使ってみます。
- https://www.instagram.com/p/B8kq45MAr59/
naomi.txt
ドラえもん50周年記念そして40作目の映画となる『映画ドラえもん のび太の新恐竜』にて、ゲスト声優をさせて頂きました🥰🦖見た目は1000%ドラえもんですが、ドラえもん役ではないです🥰(当たり前)
木村拓哉さん演じるジルと通信し、のび太たちを密かに監視する怪しい女、ナタリーを演じます🤐
実写版の時は…是非ドラえもん、もしくはドラミちゃんを演じたいです🥰😂
今回のドラえもんメーク結構頑張りました🥰
3月6日金曜日公開なので、是非劇場に遊びに来てください🦖🦕💖 憧れのドラえもん先輩との写真撮影の時の先輩、アドリブ多で緊張しました😂一緒にお仕事出来て光栄です😭😭 あと、余談だけど
最後の写真、
平成中期生まれの、若くてキャピキャピしたPOPな見た目だけど、冷静にマイク一本で淡々と漫談する、意外と上下関係めちゃ厳しいしゃべり激つよ女性芸人の宣材写真みたい😂(長)
あとハートの指の短さ😂
# ドラえもん
キーワードは相変わらず kuzure で結果が変化しませんでした。
{'form': 'ドラえもん', 'score': 29.282188}
{'form': '余談', 'score': 26.9968}
{'form': '漫談', 'score': 21.5808}
{'form': '緊張', 'score': 21.39}
{'form': '光栄', 'score': 20.6828}
ユーザー属性推定も試してみました。
なぜか性別が男性になっています。映画ドラえもんのはなしをしているからでしょうか?
{'age': '30-39歳', 'civilstatus': '未婚', 'earnings': '1M-3M', 'gender': '男性', 'hobby': ['COOKING', 'INTERNET', 'MOVIE', 'SHOPPING', 'TVGAME'], 'kind_of_occupation': '事務職', 'location': '関東', 'moving': ['RAILWAY'], 'occupation': '会社員'}
kuzure 指定の結果は以下の通りです。大きく変化していません。
hobbyから 'TVGAME' が削除されたぐらいです。
{'age': '30-39歳', 'civilstatus': '未婚', 'earnings': '1M-3M', 'gender': '男性', 'hobby': ['GOURMET', 'INTERNET', 'MOVIE', 'SHOPPING'], 'kind_of_occupation': '事務職', 'location': '関東', 'moving': ['RAILWAY'], 'occupation': '会社員'}
Dream Ami
- インスタのユーザー層 (若い女性) とも一致してそうなので選びました。
- https://www.instagram.com/p/B9W2aFjHfeK/
dreamami.txt
さっきのケーキ、いろいろあって宝島社のみなさんと食べれなかったから、みんなで一緒に食べたよ💛
本も渡したらみんな喜んでくれたぁー🥰💕
そして!!
日付変わって6日‼︎
愛すべき我らがShizukaちゃんの誕生日🎂🎊✨
みんなで一緒にカウントダウン❣️
満面の笑みのしーちゃん可愛い💕プレゼントも似合ってるーー💎👂
おめでとうが混雑して幸せすぎ💜💜💜
ハッシュタグがなく、人名も登場しているので、「固有表現抽出」を実行してみました。
ところどころ変な出力はありますが、「宝島社」のような組織名や 「shizuka」「しーちゃん」
という人物名など、メジャーな固有表現は抽出できています。
{'begin_pos': 15, 'end_pos': 18, 'form': '宝島社', 'std_form': '宝島社', 'class': 'ORG', 'extended_class': '', 'source': 'basic'}
{'begin_pos': 82, 'end_pos': 84, 'form': '6日', 'std_form': '6日', 'class': 'DAT', 'extended_class': '', 'source': 'basic'}
{'begin_pos': 94, 'end_pos': 101, 'form': 'shizuka', 'std_form': 'shizuka', 'class': 'PSN', 'extended_class': '', 'source': 'basic'}
{'begin_pos': 4, 'end_pos': 7, 'form': 'ケーキ', 'std_form': 'ケーキ', 'class': 'ART', 'extended_class': 'Dish', 'source': 'basic'}
{'begin_pos': 27, 'end_pos': 31, 'form': 'なかった', 'std_form': 'なかった', 'class': 'ART', 'extended_class': 'Magazine', 'source': 'basic'}
{'begin_pos': 38, 'end_pos': 41, 'form': '一緒に', 'std_form': '一緒に', 'class': 'ART', 'extended_class': 'Music', 'source': 'basic'}
{'begin_pos': 101, 'end_pos': 104, 'form': 'ちゃん', 'std_form': 'ちゃん', 'class': 'ART', 'extended_class': 'Title_Other', 'source': 'basic'}
{'begin_pos': 118, 'end_pos': 121, 'form': '一緒に', 'std_form': '一緒に', 'class': 'ART', 'extended_class': 'Music', 'source': 'basic'}
{'begin_pos': 137, 'end_pos': 142, 'form': 'しーちゃん', 'std_form': 'しーちゃん', 'class': 'PSN', 'extended_class': 'Person', 'source': 'basic'}
kuzureの固有表現抽出結果(ほぼ同じなので折りたたみ)
ユーザー属性はデフォルト、kuzure それぞれの結果は以下のようになりました。
これまた出力に特に大きな違いはありません。
# default
{'age': '30-39歳', 'civilstatus': '既婚', 'hobby': ['CAMERA', 'COLLECTION', 'COOKING', 'FORTUNE', 'GAMBLE', 'GOURMET', 'GYM', 'IDOL', 'MOVIE', 'SHOPPING', 'SPORT', 'TVDRAMA'], 'location': '近畿'}
# kuzure
{'age': '30-39歳', 'civilstatus': '既婚', 'hobby': ['CAMERA', 'COLLECTION', 'COOKING', 'FORTUNE', 'GAMBLE', 'GOURMET', 'IDOL', 'MOVIE', 'SHOPPING', 'TVDRAMA'], 'location': '近畿', 'moving': ['WALKING']}
kanechikadaiki
- EXIT 兼近大樹
- チャラ芸人なら 崩れている文 なはず。と思ったらハッシュタグ芸人でした。
- https://www.instagram.com/p/B9OiRjhn0ov/
kanechi.txt
ひなまつり。
# ミニモニひなまちゅり
# チャラいりさま
# ギャルなさま
# 結局生まれてから今日までひなまつりになんかイベしたことねぇ
# 女の子2人いたのにうちの家族その概念なかったわ
# ごーにんばやしはひげちょんぱー
# って歌ってたけどなにがおもしろい?
# 今ならこう自分に問いかけることができるよ
# そうみんな自らとの対話を忘れるな
# 自分を見つめる事ができた時それが大人ってやつなんじゃないかな?
# 本当の自分の事をしれば
# 弱さも強さもしれば
# きっと自分も他者もまとめて好きになれるんだ
# は?
# つーか
# 俺のお雛様どこ?
# あぁこのハッシュタグの羅列をわざわざ読んでるぽまえらか
# ゲボいべ?(キモいの最上級)
# バジュい?(ゲボいを越えてきた時)
キーワードに関しては相変わらず kuzure で変化なしなのですが、ぽまえら1 がとってこれるのは不思議です。
1行1ハッシュタグで、きれいに改行しているのもあってか、# はついていません。
{'form': 'ギャル', 'score': 22.294}
{'form': 'ぽまえら', 'score': 20.0}
{'form': 'やつ', 'score': 20.0}
{'form': '自分', 'score': 16.7252}
{'form': '羅列', 'score': 11.5525}
ちなみにユーザー属性の結果は以下の通りです。
Dream Amiさんといい、既婚はどこで判断されているのでしょうか。。
不思議です。
# default
{'civilstatus': '既婚', 'gender': '男性', 'hobby': ['COLLECTION', 'COOKING', 'FORTUNE', 'GAMBLE', 'GYM', 'IDOL', 'INTERNET', 'SMARTPHONE_GAME', 'RAILWAY', 'SPORT', 'SPORTWATCHING', 'TVDRAMA']}
# kuzure
{'civilstatus': '既婚', 'gender': '男性', 'hobby': ['COLLECTION', 'COOKING', 'FORTUNE', 'GAMBLE', 'GYM', 'IDOL', 'INTERNET', 'SMARTPHONE_GAME', 'RAILWAY', 'SPORT', 'SPORTWATCHING', 'TVDRAMA']}
Twitterのスラング
続いて、Twitterのテキストで検証します。
Twitterの投稿(Tweet)は研究でも、崩れた文としてよく例にあげられます。
以下のスライドのように、その崩れている要素は色々考えられそうです。
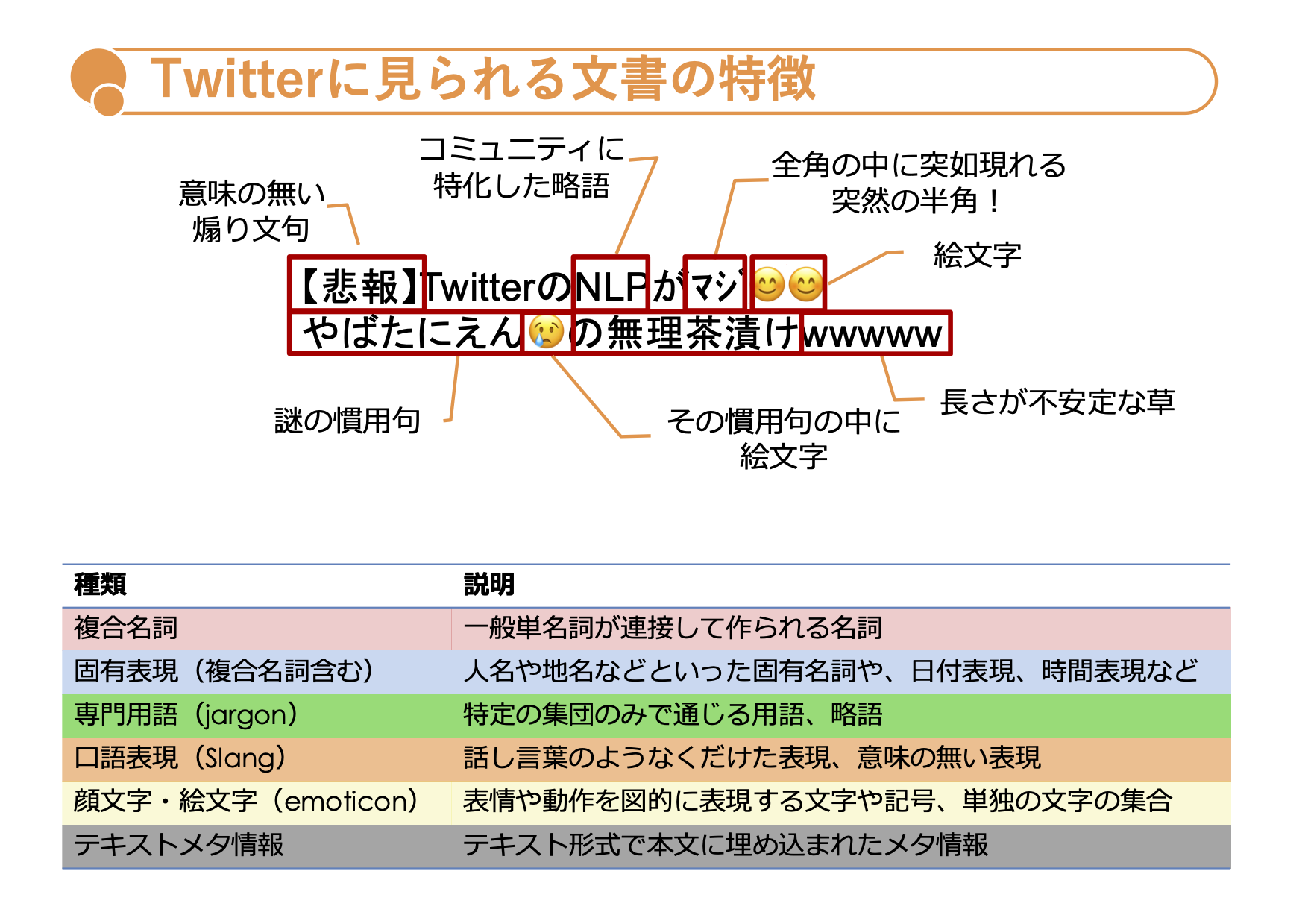
https://speakerdeck.com/hottolink_rd/20190827-aws-ml-at-loft-number-5-by-hottolink (20190827 AWS ML@Loft#5 by Hottolink) より
kuzure はこういった文を前処理せずとも対応できるという意味なのでしょうか?
調べます。
Instagramに引き続き、近年のTwitterでなにが流行ってるのか、把握している自信はないので、
ついっぷるトレンドを駆使してトレンドに上がっているツイートを選びました。
ヒプマイ
音楽原作キャラクターラッププロジェクト『ヒプノシスマイク』
- 流行りの "ぴえん" が含まれている。韻を踏んでいるので崩れている文体っぽい。
- https://twitter.com/hypnosismic/status/1236975614101295114
hipumai.txt
4th ライブのJK解禁ぴえん😭
ドドッと2種新規絵ぇえ‼️
表裏裏表表裏裏表して腱鞘炎👐
オリ特a.k.a俺得は先着でーす🧚🏻♂️
アーイ🙌
結果
キーワード抽出、固有表現抽出について、kuzure 指定による大きな変化はありませんでした。
ちなみに固有表現抽出をしたら、 オリ特a.k.a が住所扱いになりました。
{'begin_pos': 18, 'end_pos': 21, 'form': 'ドドッ', 'std_form': 'ドドッ', 'class': 'ART', 'extended_class': '', 'source': 'basic'}
{'begin_pos': 0, 'end_pos': 3, 'form': '4th', 'std_form': '4th', 'class': 'NUM', 'extended_class': 'Ordinal_Number', 'source': 'basic'}
{'begin_pos': 8, 'end_pos': 10, 'form': 'jk', 'std_form': 'jk', 'class': 'NUM', 'extended_class': 'School_Age', 'source': 'basic'}
{'begin_pos': 32, 'end_pos': 39, 'form': '表裏裏表表裏裏', 'std_form': '表裏裏表表裏裏', 'class': 'ART', 'extended_class': 'Product', 'source': 'basic'}
{'begin_pos': 42, 'end_pos': 45, 'form': '腱鞘炎', 'std_form': '腱鞘炎', 'class': 'OTH', 'extended_class': 'Animal_Disease', 'source': 'basic'}
{'begin_pos': 48, 'end_pos': 56, 'form': 'オリ特a.k.a', 'std_form': 'オリ特a.k.a', 'class': 'LOC', 'extended_class': 'Address', 'source': 'basic'}
"ネコチャン" つぶやき
- トレンドに入っていた、一般ユーザーのつぶやき
- 半角文字の「ネコチャン」を使っている
- https://twitter.com/maho_24/status/1236927278111580160
neko.txt
ここ5年ほど、家の周りにお花を届けてくれる野良ネコチャンが…お花を運んでるとこに…初めて遭遇した…。しずしず…持ってきて…くれてた…。(惜しむべくは今日のは枯れかけてた😂)
結果
kuzure 関係なく ネコチャン は ネコチャン に変換されました。(野良ネコチャンで1つのキーワード扱いですが)
{'form': 'お花', 'score': 26.9968}
{'form': '野良ネコチャン', 'score': 20.884607}
{'form': '遭遇', 'score': 10.7576}
{'form': 'とこ', 'score': 10.0}
{'form': '周り', 'score': 9.84774}
検索避け表記
いよいよ仮説がネタ切れしたので、少し違う角度で攻めてみます。
崩れた文字 として、古の時代から引き継がれている 検索避け が目的の表記が、kuzure の使い道として考えられるんじゃないでしょうか?
例えばpixivを検索避けするとき「p/i/x/i/v」等、スラッシュや記号等で区切ったり、「vixip」等逆にしたり、「pxv」等と子音を繋げたりするのが一般的である。
また、伏字という方法や「某」・「ある」表現もある。(例:ピクシブ→ピ○シブ、某イラストコミュニケーションサイト)
これを突破できてしまったら、検索よけが意味を為さないので困るなと思いつつ2、
検索避けした企業名を企業名として固有表現抽出できるか検証します。
この記事 の文において、イニシャル部分を Иττ に変換して例文をつくりました。
Иττコミュニケーションズ株式会社は、Иττグループの40年以上にわたる自然言語処理解析技術の研究成果を手軽に利用できるAPIサービスにおいて、3つのAPIを追加します。
(元記事から括弧など一部情報を削っています)
変換しても企業名として取得できるのか、固有表現抽出をしてみます。
{'begin_pos': 1, 'end_pos': 17, 'form': 'ττコミュニケーションズ株式会社', 'std_form': 'ττコミュニケーションズ株式会社', 'class': 'ORG', 'extended_class': '', 'source': 'basic'}
{'begin_pos': 20, 'end_pos': 26, 'form': 'ττグループ', 'std_form': 'ττグループ', 'class': 'ORG', 'extended_class': '', 'source': 'basic'}
{'begin_pos': 27, 'end_pos': 30, 'form': '40年', 'std_form': '40年', 'class': 'TIM', 'extended_class': 'Periodx', 'source': 'basic'}
{'begin_pos': 72, 'end_pos': 74, 'form': '3つ', 'std_form': '3つ', 'class': 'NUM', 'extended_class': 'Countx', 'source': 'basic'}
ττコミュニケーションズ株式会社 、 ττグループ になってしまいました。TT兄弟
また、今までの結果と同様、kuzureによる出力の違いはありませんでした。
次に Иττ を N/T/T にして再度実行しました。
{'begin_pos': 4, 'end_pos': 19, 'form': 'tコミュニケーションズ株式会社', 'std_form': 'tコミュニケーションズ株式会社', 'class': 'ORG', 'extended_class': '', 'source': 'basic'}
{'begin_pos': 25, 'end_pos': 30, 'form': 'tグループ', 'std_form': 'tグループ', 'class': 'ORG', 'extended_class': '', 'source': 'basic'}
{'begin_pos': 0, 'end_pos': 3, 'form': 'n/t', 'std_form': 'n/t', 'class': 'ART', 'extended_class': 'Product_Other', 'source': 'basic'}
{'begin_pos': 31, 'end_pos': 34, 'form': '40年', 'std_form': '40年', 'class': 'TIM', 'extended_class': 'Periodx', 'source': 'basic'}
{'begin_pos': 76, 'end_pos': 78, 'form': '3つ', 'std_form': '3つ', 'class': 'NUM', 'extended_class': 'Countx', 'source': 'basic'}
tコミュニケーションズ株式会社 と n/t で2つの固有表現として分割されました。スラッシュが区切り文字として認識されたのでしょうか。
また、n/t が 製品名_その他 として抽出されました。
ττコミュニケーションズ も n/t も、未知語を固有表現として取得できるという意味では、柔軟な対応ができるAPIかなと思います。
結論
COTOHA APIの kuzureについて検証した結果、kuzure はよくわからない存在だということがわかりました。
(別にCOTOHA APIに苦言を呈したい訳ではないので)弁解すると、デフォルトの状態でも、半角カタカナや絵文字に対して、十分に対応できている気がします。
もしかしたら今回調べていないケースで威力を発揮するのかもしれません。
もし、正しい使い方・活用法を知っている人がいればご一報ください。
-
ぽまいら(https://www.weblio.jp/content/ぽまいら) の表記揺れと思われます ↩
-
Google検索において、スラッシュ区切りの
p/i/x/i/vでもpixivがヒットするなど、検索避けが意味がないケースは今現在多々あります ↩