画像に写っているものを検出する「物体検出」にはR-CNNやSSD,YOLOといったディープラーニングを用いた手法があります。
なかでもYOLOは処理速度が速く精度も高いといわれています。
このYOLOにはいくつかバージョンがあるのですが、今回は最新バージョンであるYOLOXで使える学習データセットを自作したいと思います.
最終的には自分で用意した画像から学習データを作成して、そのデータでYOLOXを学習させ自作のPythonアプリに組み込むところまでやろうと思います。
・【YOLOXで自前のアプリを作る。その1】- YOLOXで学習させるための、COCO形式の自前データセットを作成する。 ← イマココ
・【YOLOXで自前のアプリを作る。その2】- GoogleColaboratoryでYOLOXをとりあえず試す。
・【YOLOXで自前のアプリを作る。その3】- GoogleColaboratoryでYOLOXの学習を行う。
・【YOLOXで自前のアプリを作る。その4】- YOLOXを自作のアプリに組み込む。
【参考URL】
・jsbroks/coco-annotator
・【coco-annotaror】アノテーションツール
・AIのデータを作ろう:アノテーション ~COCO Annotator~
・COCO Annotatorを使って骨格検知用のデータセットを作ってみる
環境
- Docker, Docker-Composeが使える環境
流れ
- 画像の用意
- coco-annotatorのインストールと起動
- ラベルの作成
- 画像のアノテーション
- アノテーションデータの保存
画像の用意
認識したいものが写っている画像を用意してください.
画像は多ければ多いほどよいのですが,100枚くらいでもそこそこ精度が出るようです.
今回は昔飼っていた愛犬の画像を用意しました.超可愛いですね.
今回はアノテーションの段階で学習用のデータと検証用のデータに分けておきます.
画像を8:2くらいの割合で分けてそれぞれ,train用,valid用としておきましょう.
coco-annotatorのインストールと起動
coco-annotator自体はDocker上のサーバーとして動き,ブラウザ経由でwebアプリとして使用するようなものとなっています.なのでまずはcoco-annotatorサーバを立てるところから始めましょう.とはいっても全てdocker上で動くのでメチャクチャ簡単です.
まずは,coco-annotatorのソースを取ってきましょう.
適当なディレクトリに移動してgit cloneします.
git clone https://github.com/jsbroks/coco-annotator
そうしたら,coco-annotatorを起動します.
cd coco-annotator
sudo docker-compose up
これでcoco-annotatorのサーバーが起動します.そしたらブラウザのURL入力欄にlocalhost:5000と入力しwebアプリにアクセスしましょう.
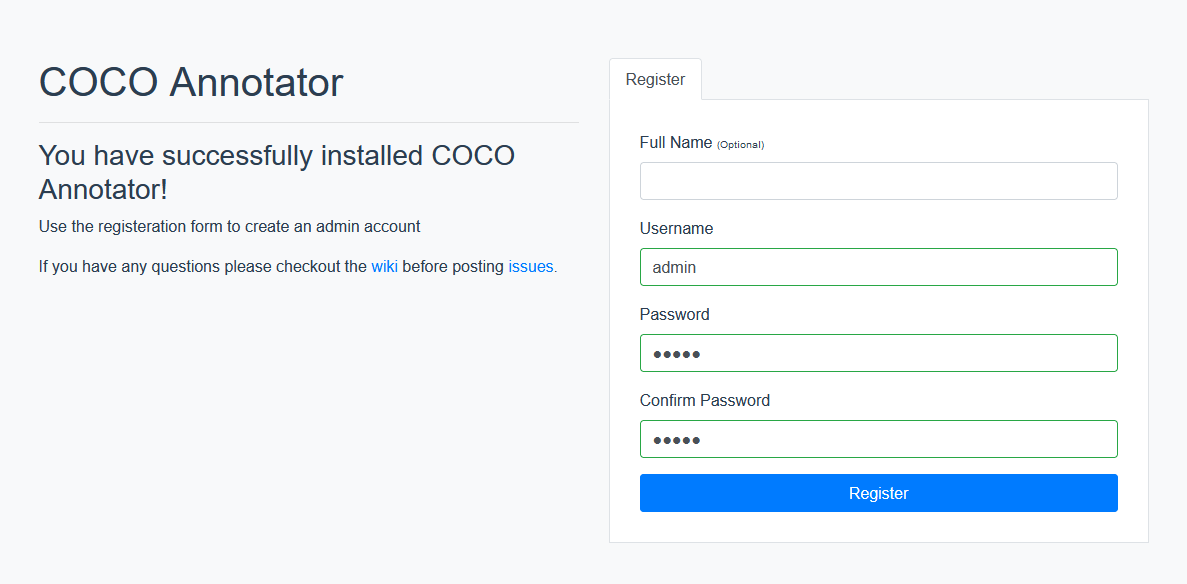
初回はこのような画面が表示されるので適当にUsernameとPasswordを入れてRegisterを押します.

ラベルの作成
次にラベルの作成を行います.
coco-annotatorではデータセットやアノテーションデータとは別でラベルが管理されているようなので,先にラベルだけ作っておきます.
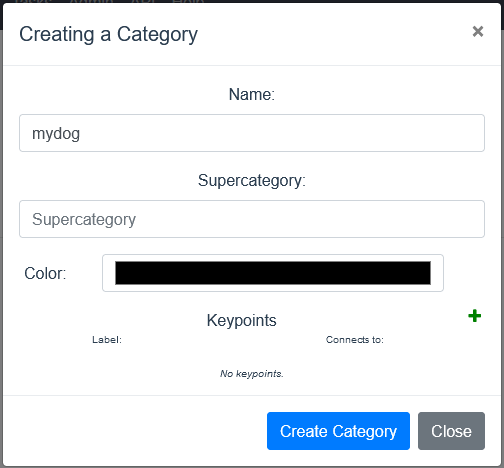
画面上部のCategoriesをクリックした後,Createをクリックでラベルの作成画面が出てきます.

Nameに任意のラベル名を入力してCreate Categoryをクリックでラベルを作成します.今回はmydogとしておきます.
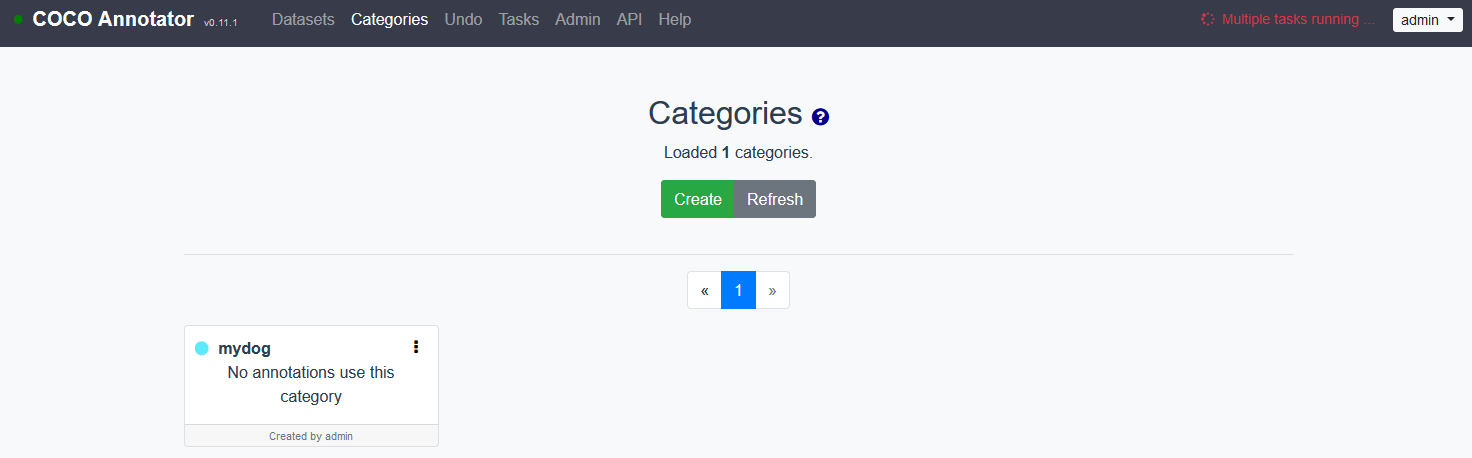
作成できたらこのような画面になります.
画像のアノテーション
画像のアノテーションをして,データセットを作っていきます.
準備
まずは,train用のデータセットを作りましょう
画面上部のDatasetsを押し,Createでデータセットの作成画面を開きます.
Dataset Nameに任意のデータセット名を入力します.今回はmy_dog_trainとしておきます.
Default Catecoriesの入力欄をクリックすると先程作成したラベルが候補として下に出てくるのでそれを選択します.
Create Datasetでデータセットを作成します.
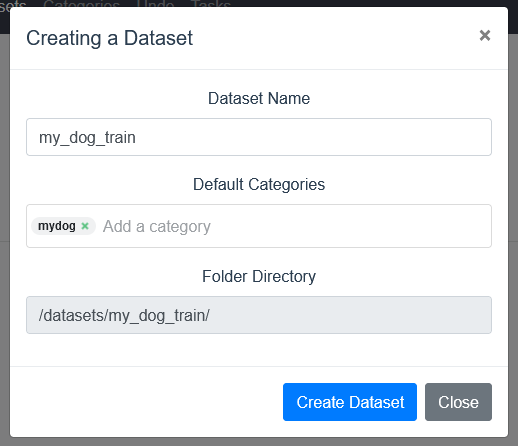
このような画面になるので作成したデータセットをクリックします.
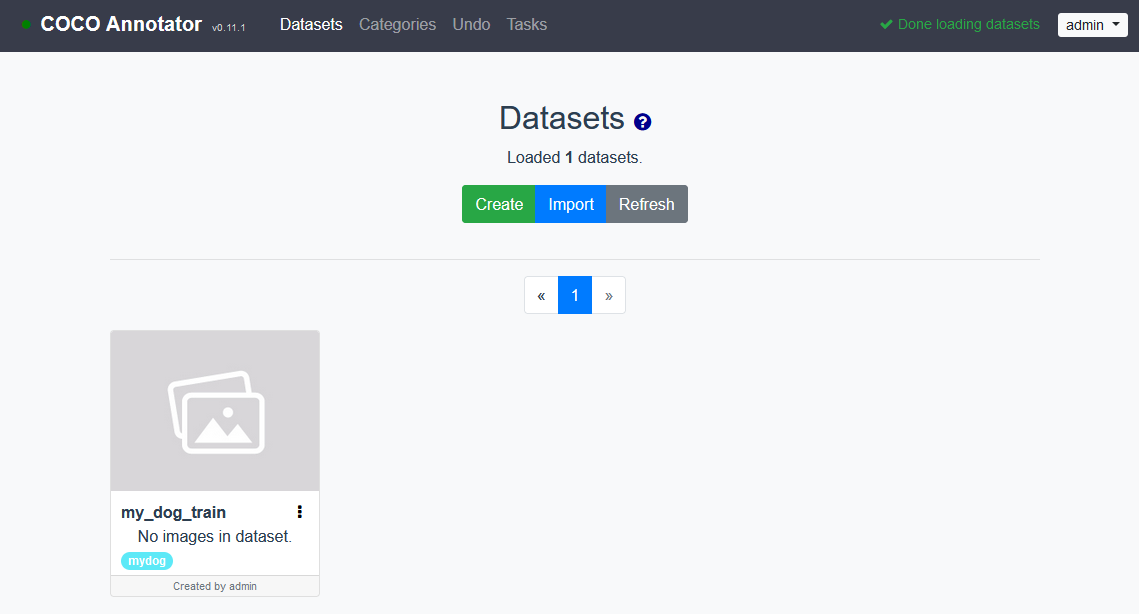
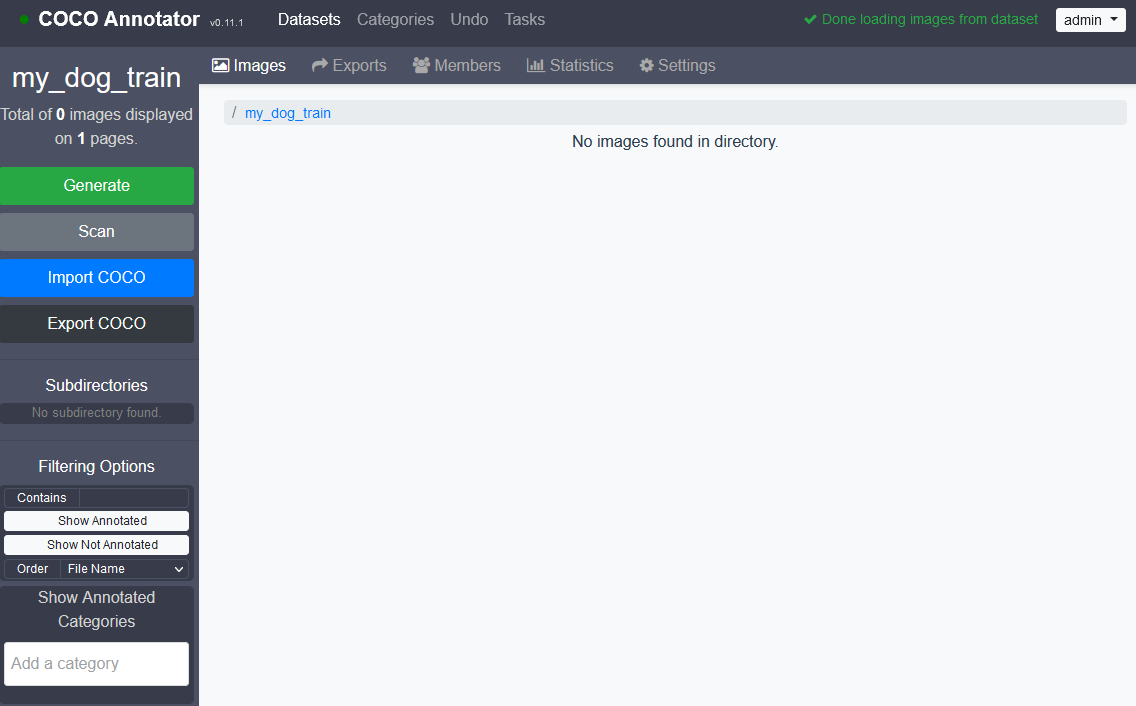
ここで最初に用意していた画像のうち,train用の画像をcoco-annotator/datasets/my_dog_train/の中にコピーし左のScanボタンを押してからブラウザを更新します.
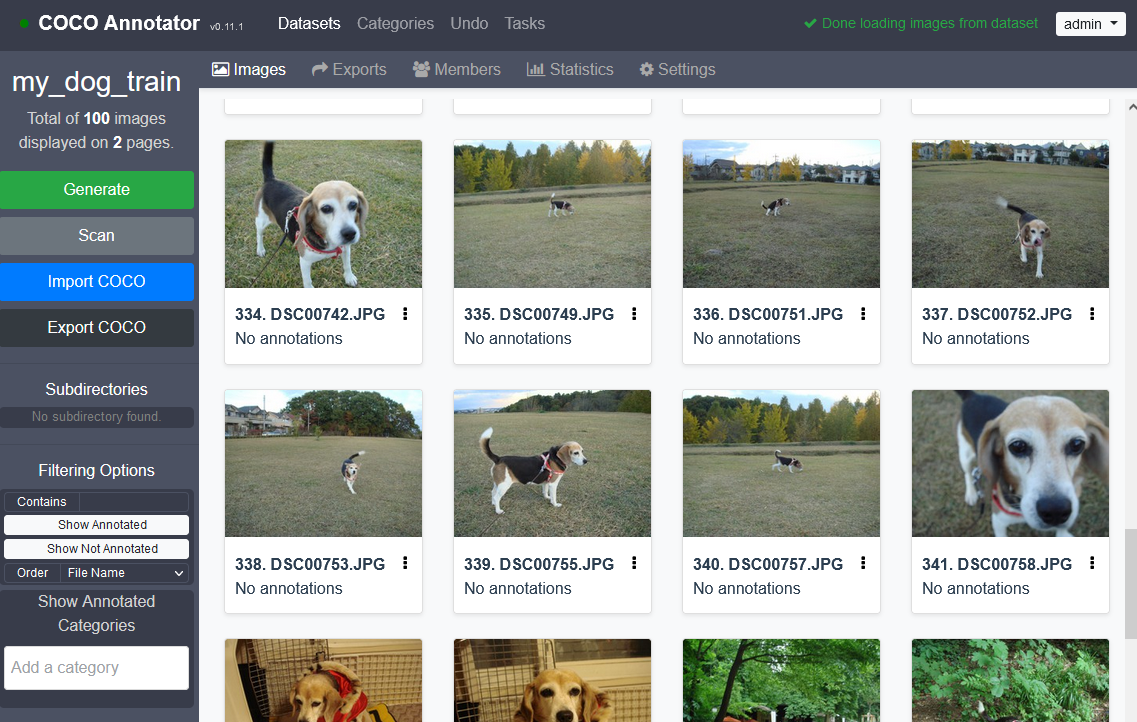
アノテーション
それでは画像をクリックしアノテーションを進めていきましょう.
アノテーションの流れは次のとおりとなります.
- 右のメニューにある+マークをクリック
- 画像の検出したい物体の隅2点をクリック(ドラッグではない)
- 右のメニューにある右矢印で次の画像へ
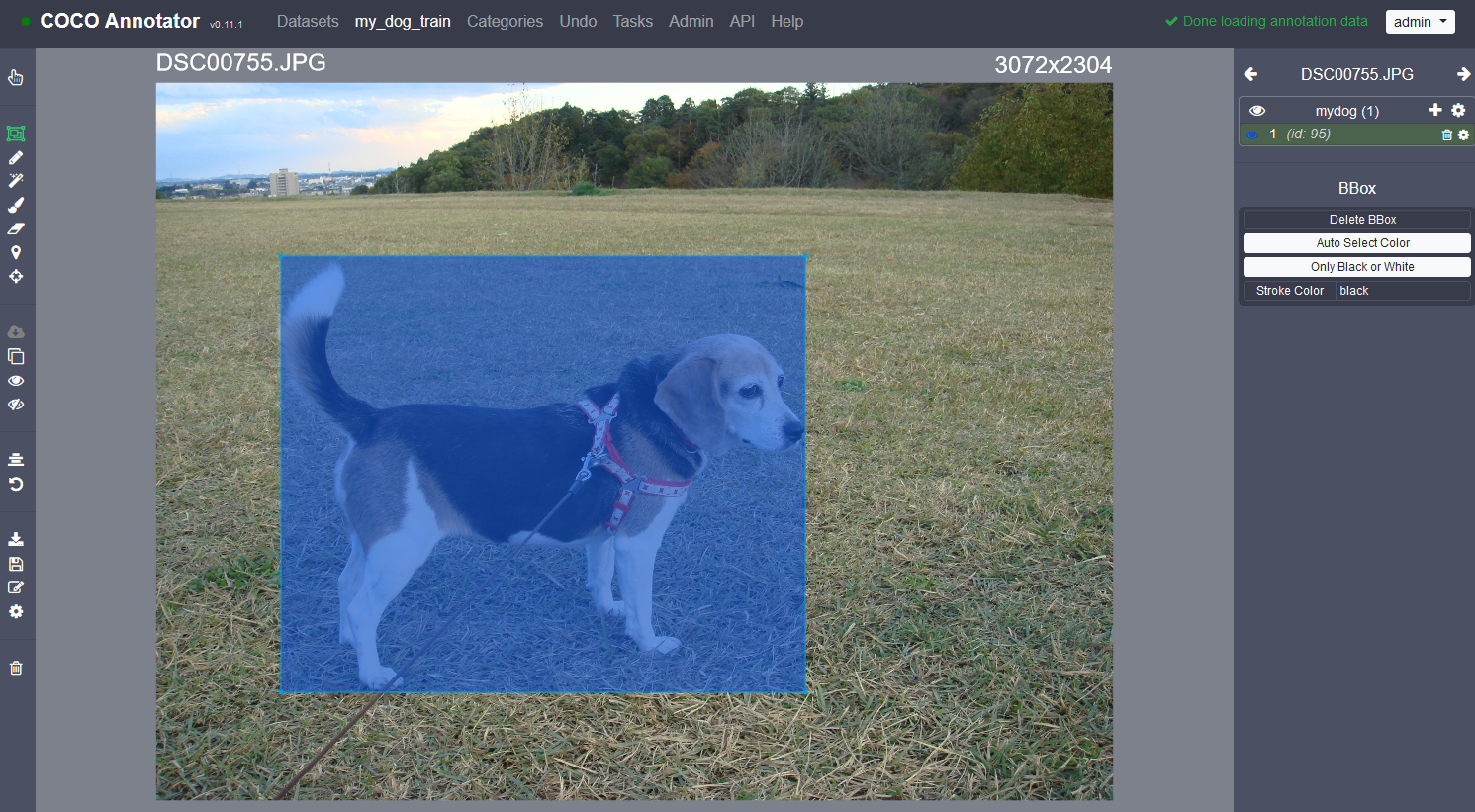
これを地道に繰り返してすべての画像に対してアノテーションを行います.また,coco-annotatorにはキーボードショートカットが設定されていて,左のメニューにある歯車マークから確認することができます.pやnでページ送りできたり,ctrl+zで元に戻せたりします.
すべて終わったらこの様になっているかと思います.
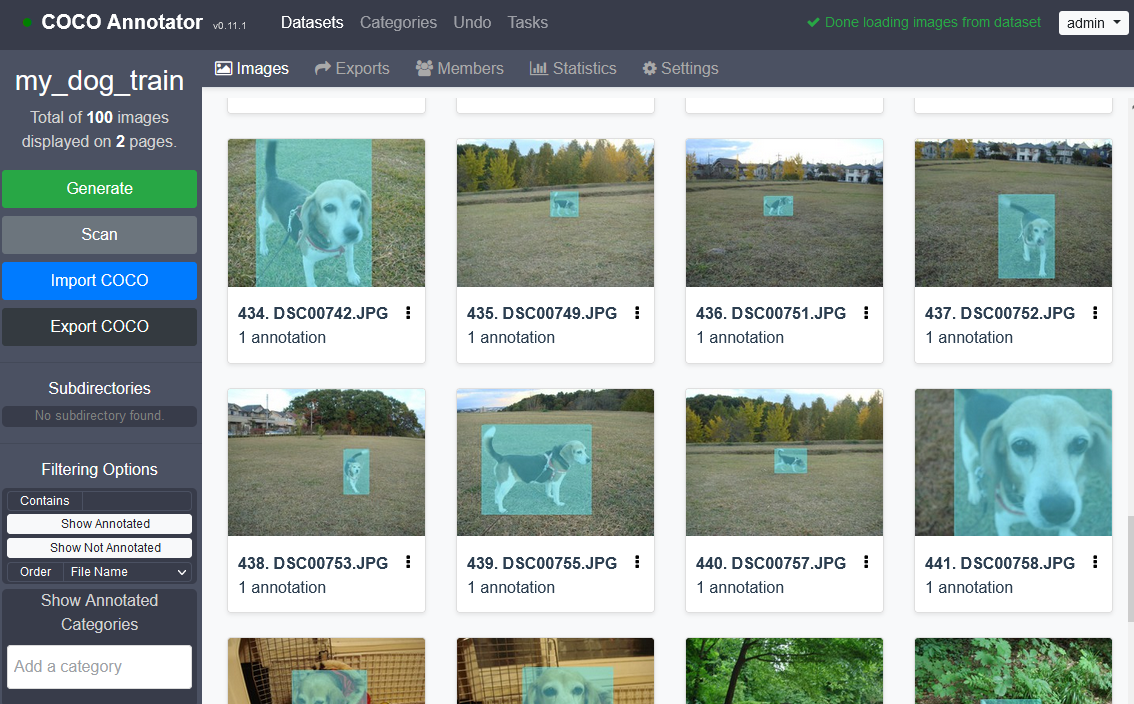
同様の手順で,valid用の画像についてもmy_dog_validという名前でデータセットを作りアノテーションをします.
アノテーションデータの保存
最後に,アノテーションした結果をcoco形式でダウンロードします.
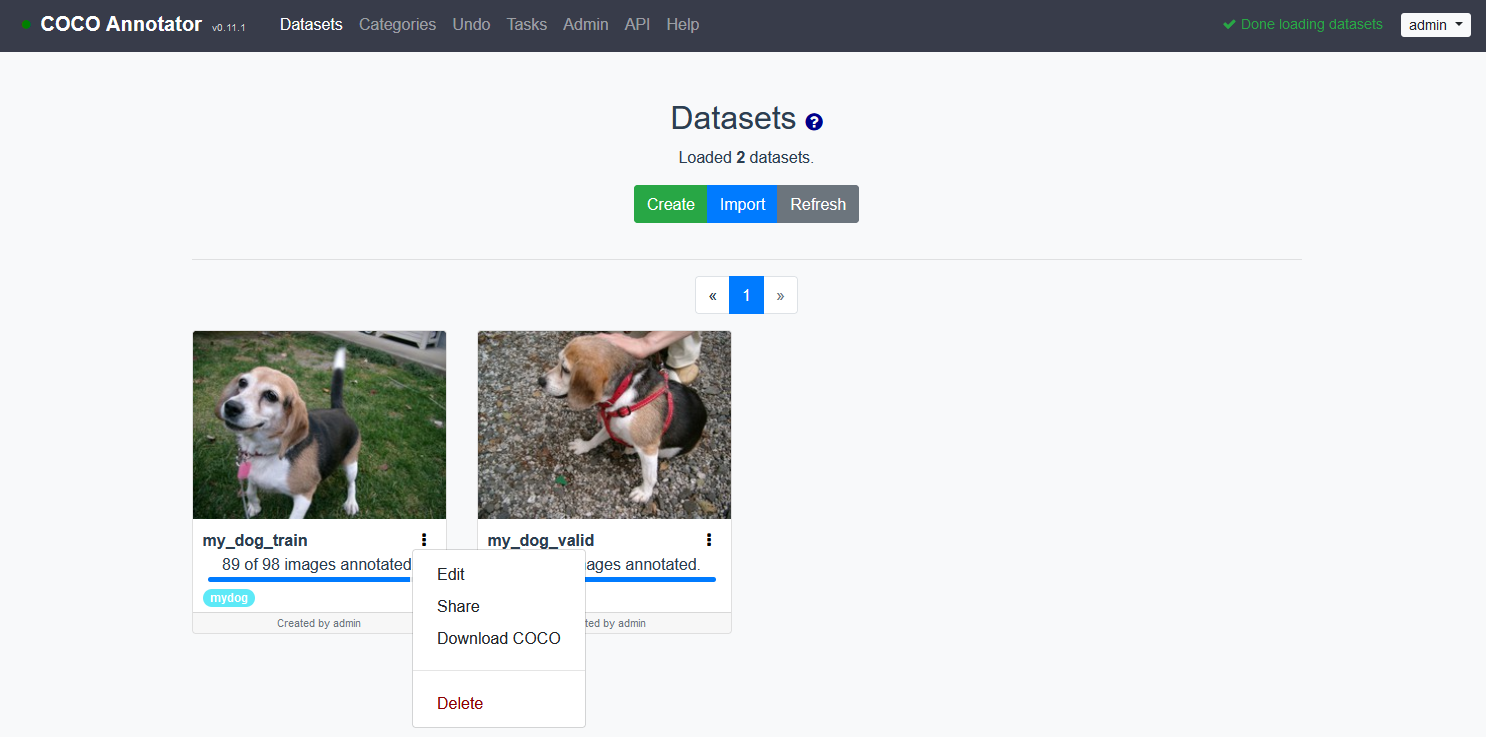
画面上部のDatasetsボタンからデータセットの一覧に戻ります.
データセットの右のメニューボタンからDownload COCOを選択してダウンロードします.
my_dog_train.jsonとmy_dog_valid.jsonという名前でアノテーションデータが保存されるかと思います.
coco-annotator/datasets/my_dog_trainとcoco-annotator/datasets/my_dog_validのなかにある画像と,このmy_dog_train.json,my_dog_valid.jsonは学習に使うのでわかるように保管しておきましょう.