本記事では LLM の学習工程、特に事後学習と呼ばれるファインチューニングとアライメントがどのように行われるかについて見ていく。
目次
1. 背景と目的
1.1. 背景
- 昨今 OSS の精度が ChatGPT のような Closed LLM に近づきつつある
- スマホに載るような小さい言語モデル(SLM)も登場してきており、コスト面で API を使うよりも SLM を使った方が良いという世界観が来くるかもしれない
- プロンプトエンジニアリングでは指示に従ってくれないなど、限界がある場合がある
1.2. 目的
- 今のうちに事後学習の方法を知っておくことで、業務で使える OSS が出たときに対応できるようにしておきたい!
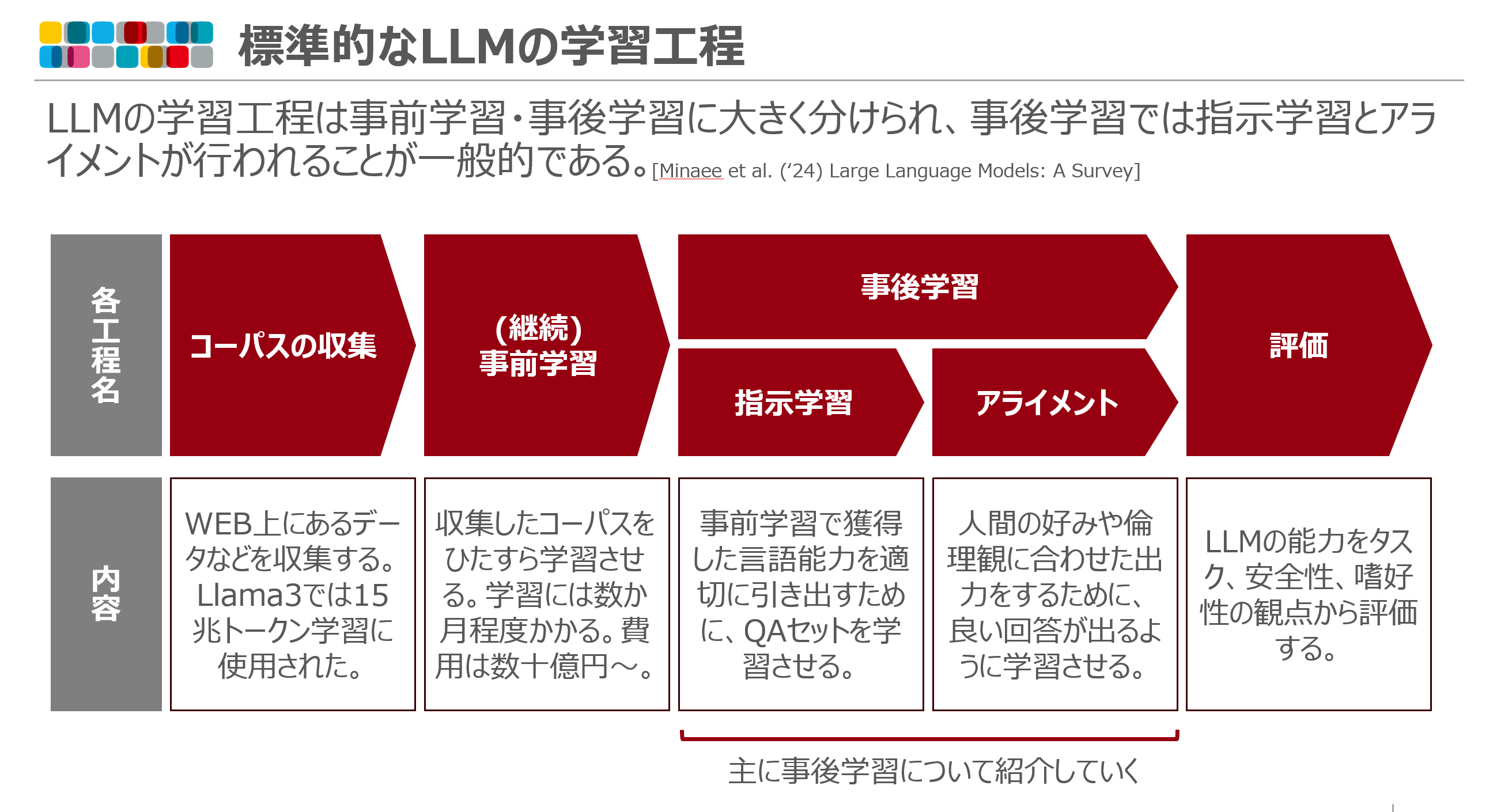
2. LLM の学習工程全体像
LLM の学習工程は事前学習・事後学習に大きく分けられ、事後学習では指示学習とアライメントが行われることが一般的である。
- 事前学習
- 大規模なテキスト(コーパス)を学習させることで LLM に言語能力を獲得させる
- Llama3 のように学習量が大事というグループと、Phi3 のように教科書レベルの質が大事というグループがある模様。
- 「継続事前学習」とは、例えば Llama など英語の文書をメインで学習されたモデルに対し、日本語能力を高めるために追加で日本語の文書を学習させるなど
- 事後学習
事前学習で獲得した言語能力を人間に沿う形で引き出させるようにする学習過程である - 指示学習 - QA 形式のテキストを事前学習と同じ方法で学習させていく。この過程を経て、LLM は人間の問合せに対し回答する方法を学ぶ。 - アライメント - QA 形式だけでは学ばせることが難しい、人間の倫理観への準拠や意図の汲み取りなど目指し行われる
3. 事前学習
事前学習についても知っておくと事後学習の理解が深まるかもしれないので、紹介しておく。
(継続) 事前学習とは、LLM に言語を学ばせ言語能力を獲得させるために大量のテキスト(コーパス) を学習させる工程である。何も知らない子どもに文書だけを読み込ませるというイメージ。教師役もいないため、大規模なコーパスを読み込ませる必要がある模様。
こぼれ話:1000 億以上のパラメータを持つ LLM を作成したLLM 勉強会では、日本語のコーパスを集めているが高品質のテキストを大量に持っていくのはとても大変そうだった...
学習方法としては、文章の次のトークン(厳密には違うがイメージは単語)を予測し、正解できるようにパラメータを更新していくというものである。

4. 事後学習
4.1. 指示学習
指示学習とは、QA 形式のテキストを自己教師あり学習させ、質問に対して人間が求める回答を出すように学習させる工程である。
LLM にチャット能力をつけさせるには、連続的な複数の QA を 1 つのテキストとして学習させる(はず)。
学習データついては例えば、前述の LLM 勉強会で指示学習に使われているデータはこのリンクから見ることができる。

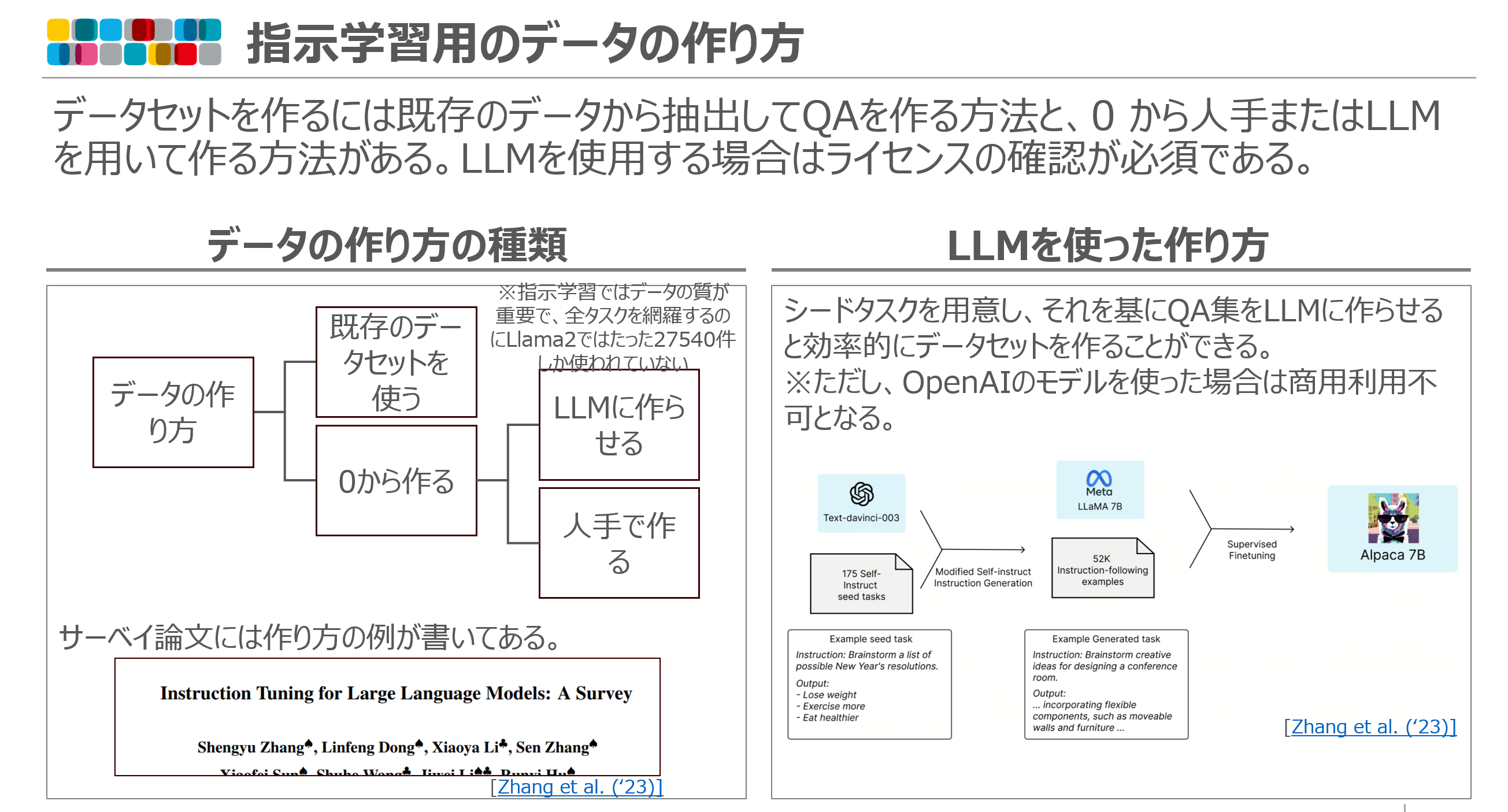
指示学習のサーベイ論文(ある領域の研究全体を調査しまとめた論文)では、指示学習データの作り方が紹介されている。
Instruction Tuning for Large Language Models: A Survey (arXiv: 2308.10792)
データの作り方は次のようなやり方がある
- 既存のデータセットを使う
- 0 から作る
- LLM に作らせる
- 人手で作る
事後学習のデータは最終的に LLM がどのような回答を出すかに大きく関わってくるため、質が重要である、"Quality Is All You Need." とLlama2 のテクニカルレポートでは書かれている。Llama2 では指示学習において、27540 件のアノテーション(QA)しか使われていないらしい。経験が無いと感覚が分かりにくいものの、ユーザーが投げそうな世の中と基本的なタスクをたった約 3 万件の QA で網羅できるかと考えると少ないように感じれるのではないだろうか。
また、LLM に作らせる方法は「蒸留」と呼ばれる手法であり、より上位の能力を持つ LLM が出力したデータを学ばせることでその能力を獲得させようというものである。一方で、この教師役の LLM については注意が必要で、例えば OpenAI のモデルを他社モデルの開発に用いることは禁止されている(OpenAI 利用規約リンク)。
アウトプットを使用して、OpenAI と競合するモデルを開発すること。
4.2. アライメント
アライメントとは、人間の好みや倫理観に合わせ、回答を調整する工程である。2022 年に OpenAI によって Reinforcement Learning from Human Feedback (RLHF) と呼ばれる手法が提案され、その有用性が示された。以前の言語モデルの大きな問題点として、差別的な発言をしてしまうということがあったがこの手法により大幅に改善されたものと思われる。
ChatGPT がここまで世の中に広がったのは OpenAI がこのアライメントを徹底的にやっていたために、社会的な偏見を持つ発言をしにくかったからと執筆者としては考えている。そのため、OpenAI の神髄はこのアライメントにあるのでは、と感じている。
ちなみに、GPT-4 ではアライメントに半年かけたと発表されている(参考リンク)。
We’ve spent 6 months iteratively aligning GPT-4 using lessons from our adversarial testing program as well as ChatGPT, resulting in our best-ever results (though far from perfect) on factuality, steerability, and refusing to go outside of guardrails.
アライメントのデータセットは例えば下記のように、質問、適切な回答、するべきでない回答、のようになっている(参考リンク:llm-jp/hh-rlhf-12k-ja)。

4.2.1. アライメント手法 ①:RLHF
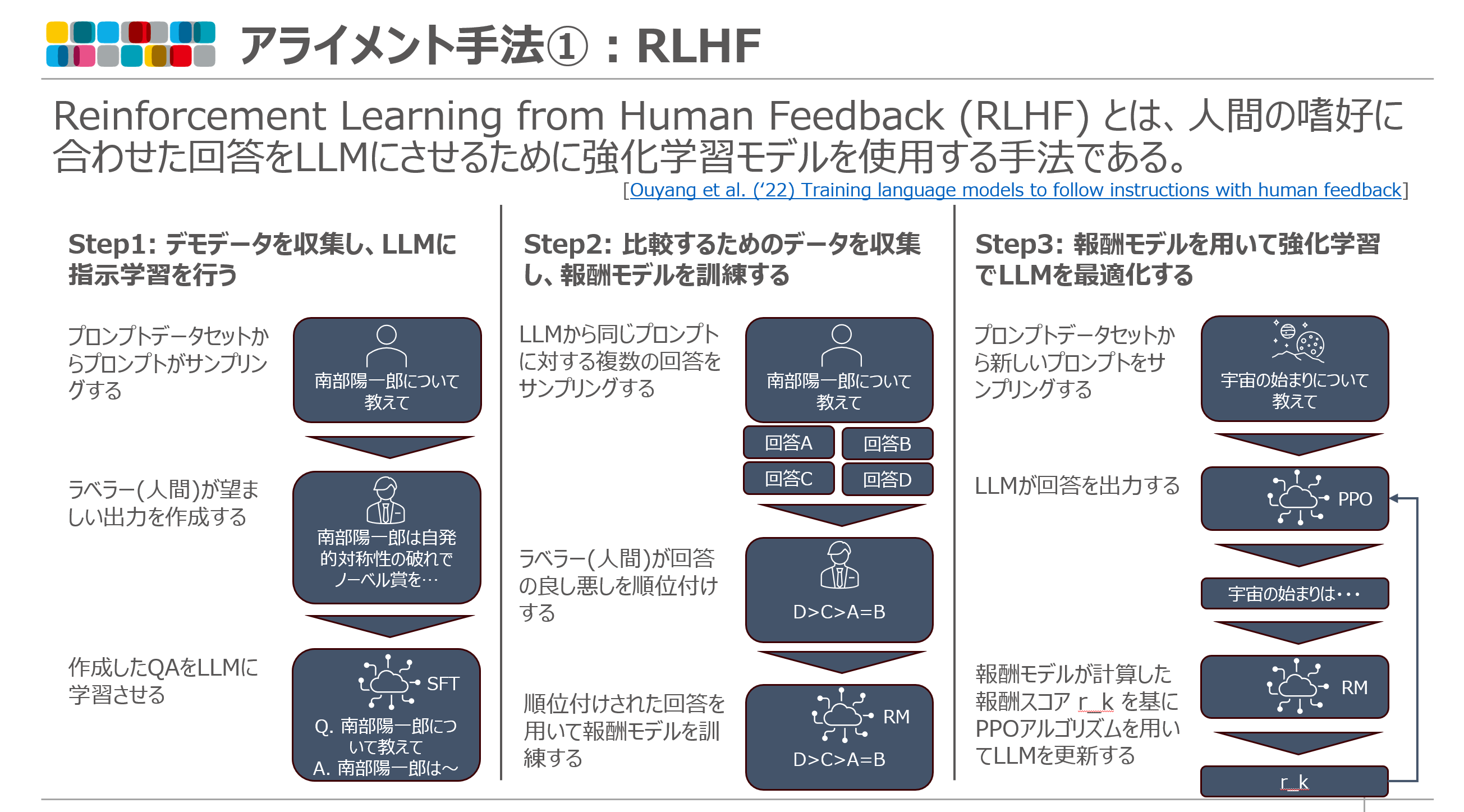
Reinforcement Learning from Human Feedback (RLHF) とは、人間の嗜好に合わせた回答を LLM にさせるために強化学習モデル(報酬モデル)を使用する手法である。
提案論文:Training language models to follow instructions with human feedback(arXiv: 2203.02155)
RLHF は以下の 3 つのステップから成り立っている
Step1: デモデータを収集し、LLM に指示学習を行う
Step2: 比較するためのデータを収集し、報酬モデルを訓練する
Step3: 報酬モデルを用いて強化学習で LLM を最適化する
RLHF の特徴として、アライメントする LLM の他に回答の良し悪しを判断する報酬モデルが必要となることがある(Step2)。この報酬モデルには訓練する LLM と同様のアーキテクチャを持ち事前学習されたモデルなどが使われる。
4.2.2. アライメント手法 ②:DPO
Direct Preference Optimization (DPO) は報酬モデルを使用せずに RLHF と同じ学習をできると確認されている手法である。
提案論文:Direct Preference Optimization: Your Language Model is Secretly a Reward Model (arXiv: 2305.18290)
この学習方法の嬉しいところは、RLHF では必要だった報酬モデルを用いないところである。報酬モデルから得られるスコアを数式で書き下すことで、報酬モデルの省略を達成している。このため、コストが格段に安くなり技術ハードルが小さい。例えば、前述の LLM 勉強会ではこの DPO を使ってアライメントが行われている。
アライメントの手法としては他にも様々あるものの、他よりも DPO の方が精度が安定しているという話がある(参考記事)。
注意点として、学習する LLM が出したデータでアライメントを行わないと期待した精度が出ないという話がある(Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study (arXiv: 2404.10719))。

4.2.3. Mix 手法:ORPO
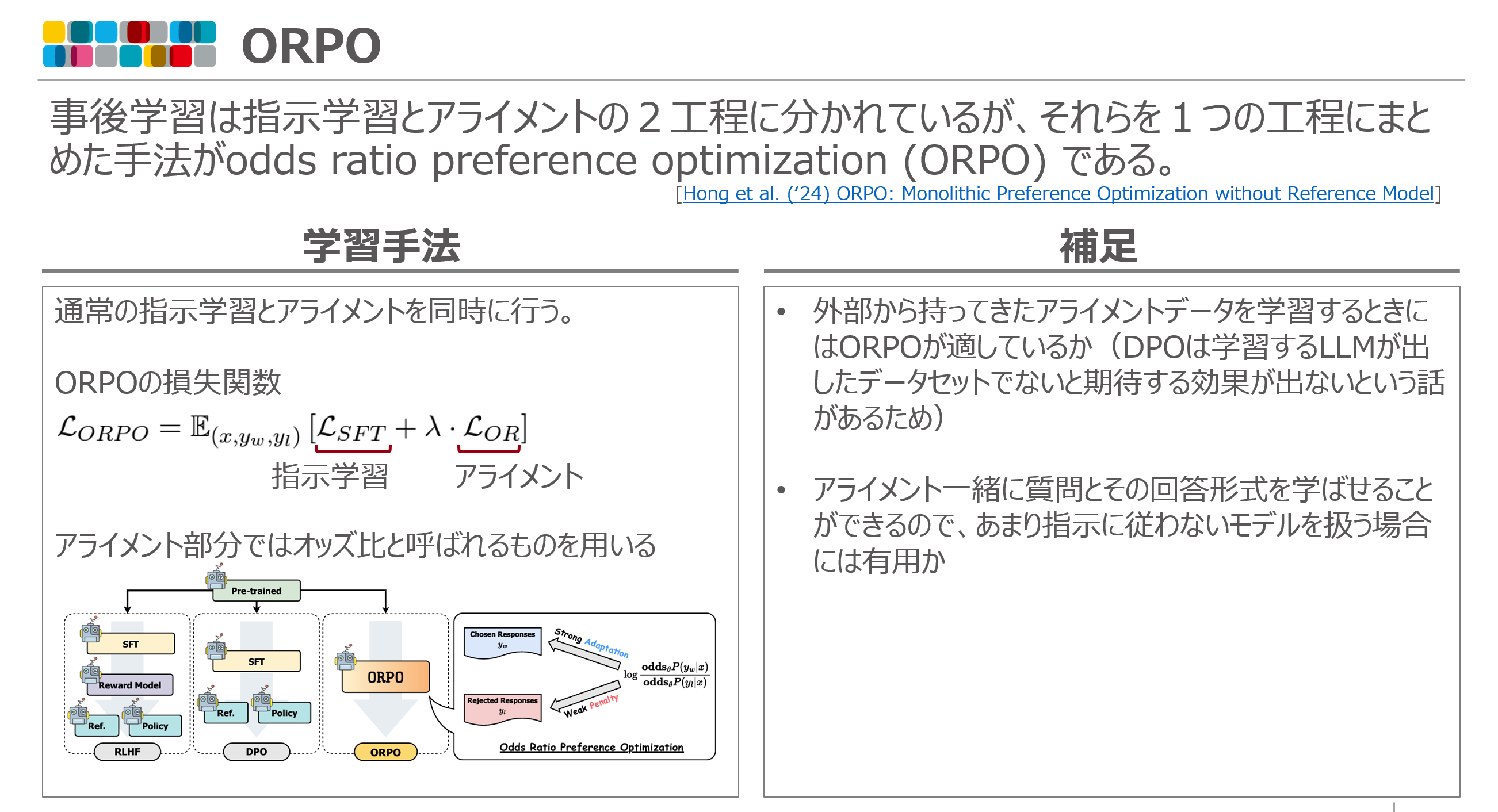
事後学習は指示学習とアライメントの 2 工程に分かれているが、それらを 1 つの工程にまとめた手法が odds ratio preference optimization (ORPO) である。
提案論文:ORPO: Monolithic Preference Optimization without Reference Model (arXiv: 2403.07691)
ORPO の特徴は指示学習とアライメントの工程を一度にできるところである。つまり、アライメント用のデータセットさえ十分にあれば、事前学習モデルを 1 つの学習工程で実用レベルまで引き上げられる可能性がある。ORPO の損失関数を見ると、指示学習とアライメントに対応する項がそれぞれ含まれていることが分かる。
4.2.4. 参考;アライメントで用いられる指標
アライメントの指標で最も有名なのは、おそらく Anthropic が提案した
- Helpful
- Honest
- Harmless
の 3H preference criteria である(参考文献:General Language Assistant as a Laboratory for Alignment (arXiv: 2112.00861))。
ただ、粒度が粗いためかこれが業界のコンセンサスになっている雰囲気は無いように感じる。アライメントの指標は論文によって異なることが多く、実業務でアライメントをやる場合は既存データセットや先行研究を調べる必要がありそう。下記の画像ではアライメントで用いられる観点を 2 つの論文を参考に挙げてみた。
参考文献:
- A Survey on Evaluation of Large Language Models (arXiv: 2307.03109)
- Taxonomy of Risks posed by Language Models

4.2.5. アライメント手法は結局何を使えばよい?
あくまで執筆者の主観であるが、外部から学習データを取ってきた場合は ORPO、LLM の出力から得た場合は RLHF を選択するのが良いのではないかと考える。

5. まとめ
- 質問に対し言語モデルに適切に回答させるための事後学習には、大きく分けて指示学習とアライメントの2つの工程がある
- 指示学習は QA 形式のデータを学習させることで、ユーザーの質問に対し回答ができるようにする
- アライメントは質問と良い・悪い回答を学習させることで、より人間の嗜好や価値観にあった回答をできるようにする
- アライメントには RLHF、DPO など多くのモデルが提案されているものの、やる目的は基本的に同じ
- 指示学習とアライメント2つの工程を1つにまとめた ORPO と呼ばれる手法が提案されている
ここまで読んでいただきありがとうございました!どなたかのお役に立てれば幸いです。
間違い等があればご連絡いただけるとありがたいです!