この記事で話す内容
- pytorchでどのようにニューラルネットの学習プログラムを書くかを示すために、「基本のプログラム」を書きます。
先に結論:ニューラルネットの学習サンプルコード
ニューラルネットを作るときに必ず作る内容:
- 学習データセットのロード用の「データローダ」
- ニューラルネットの学習モデルの構成
- 実際に学習を行うループ
- テストを実施するための関数
例として、「cifer-10」という画像のクラス分けを学習するためのLeNetモデルのソースコードはつぎの通り。
(長いけどそこは諦めて。。。)
lenet_cifer10_train.py
import os
import pickle
import logging # ニューラルネットの学習ログをとるために使用
logger = logging.getLogger(__name__) # ロガーの初期化
from dataclasses import dataclass # ニューラルネットの出力をデータクラスとして出すために使用
from typing import Optional, Tuple # データクラスの変数の型を指定するために使用
from tqdm import tqdm # プログレスバーを出すために使用
import numpy as np
from PIL import Image # 画像を取り扱うために使用
import matplotlib.pyplot as plt # 画像のサンプル表示のために使用
import torch # pytorch本体
import torch.nn as nn # ニューラルネットを構成する際の基本的なモジュールが入っている
import torch.optim as optim # ニューラルネットを最適化するためのoptimizerが入っている
from torchvision import transforms as transforms # 画像前処理のために使用
from torch.utils.tensorboard import SummaryWriter # 学習ログのグラフ化のために使用
# ==== データローダの作成など ============================================================================================
# データセットに対して、idxで指定された際に読み込み方法を指定するためのラッパークラス
class Dataset(torch.utils.data.Dataset):
def __init__(self, data, labels):
# 画像を変換して整形して保持
self.data = np.array(data) # numpy形式に変換
self.data = self.data.reshape(len(data), 3, 32, 32) # dataを整形
self.data = self.data.transpose(0, 2, 3, 1) # data[ミニバッチのindex][チャンネル][画像縦位置][画像横位置]と指定できるように順序交換(畳み込み層に入れる場合には[チャンネル]が2つ目のindexになるようにする)
# ラベルを保持
self.labels = labels
# 画像を前処理するための関数たちを登録
self.transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,0.5,0.5), std=(0.5,0.5,0.5)),
]
)
# 指定されたindexのデータを辞書形式で返却するように設定する
def __getitem__(self, index):
img, label = self.data[index], self.labels[index] # 指定のデータを取得
img = Image.fromarray(img) # 画像に変換
img = self.transform(img) # transformをかける(tensor型に変換してから、正規化)
return {'inputs':img, 'targets':label} # 辞書形式で返却(辞書のkeyはニューラルネットのforwardの引数と同じ名前にする)
# データセットの個数を返すように設定する
def __len__(self):
return len(self.data)
# サンプル表示用の関数。一般には作らなくてOK。
def plot(self, index):
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
img, label = self.data[index], self.labels[index]
plt.imshow(img) # 指定されたindexの画像を描画
plt.title(f'label={classes[label]}') # titleを"label=クラス名"という形式で設定
plt.show() # 表示
# データセットのファイルから、各データローダを生成する関数
def get_dataloader(dataset_path, split_ratio=(0.8, 0.2, 0.0), batch_size=32, thread_num=4):
# 成形されたデータセットの読み込み
logger.info(f'loading {dataset_path}')
with open(dataset_path, 'rb') as f:
dataset_raw = pickle.load(f, encoding='bytes')
logger.info('completed loading')
# データセット形式に変換
ds = Dataset(dataset_raw[b'data'], dataset_raw[b'labels'])
ds.plot(index=np.random.randint(0, len(ds))) # サンプルとして、ランダムに1件選んで描画
# データセットを指定された比率に合わせて分割
total_size = len(ds)
train_size = int(total_size * split_ratio[0]) # 学習で使用するデータ個数
valid_size = int(total_size * split_ratio[1]) # 検証で使用するデータ個数
test_size = int(total_size * split_ratio[2]) # テストで使用するデータ個数
train_dataset = torch.utils.data.dataset.Subset(ds, range(0, train_size)) # 指定された部分のデータのみを取り出す
valid_dataset = torch.utils.data.dataset.Subset(ds, range(train_size, train_size+valid_size)) # 指定された部分のデータのみを取り出す
test_dataset = torch.utils.data.dataset.Subset(ds, range(train_size+valid_size, total_size)) # 指定された部分のデータのみを取り出す
logger.info(f'data_total_size: {total_size}, train_size: {train_size}, valid_size: {valid_size}, test_size: {test_size}')
# データローダを作成
# データローダは「for hoge in dataloader」のように渡すといい感じにデータをバッチサイズに分割して取り出してくれるクラス。
# 例えばバッチサイズを8に設定すると、「hoge」はデータセットから取り出した8個データが入る。
train = None
valid = None
test = None
if len(train_dataset) != 0:
train = torch.utils.data.DataLoader(
train_dataset, # データセット
batch_size=batch_size, # イテレート時のバッチサイズ
shuffle=True, # イテレート前にデータをシャッフルするか
num_workers=thread_num, # イテレート時に使用するスレッド数
)
if len(valid_dataset) != 0:
valid = torch.utils.data.DataLoader(
valid_dataset, # データセット
batch_size=batch_size, # イテレート時のバッチサイズ
shuffle=False, # イテレート前にデータをシャッフルするか
num_workers=thread_num, # イテレート時に使用するスレッド数
)
if len(test_dataset) != 0:
test = torch.utils.data.DataLoader(
test_dataset, # データセット
batch_size=batch_size, # イテレート時のバッチサイズ
shuffle=False, # イテレート前にデータをシャッフルするか
num_workers=thread_num, # イテレート時に使用するスレッド数
)
return train, valid, test
# ====================================================================================================================
# ==== ニューラルネットのモデル構成 ===================================================================================
class LeNet(nn.Module):
def __init__(self):
# ここにはニューラルネットの構成で使用するモジュールを一通り書き出す。
# Conv2dは畳み込み層、AvgPool2dは平均プーリング層、Flattenは数値を一列に並べてベクトル化する層、Linearは線形層(全結合層)を表している。使い方はググろう。
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, kernel_size=5, padding=0, stride=1) # 32*32 3チャンネル入力 → 28*28 6チャンネル出力
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2) # 28*28 6チャンネル入力 → 14*14 6チャンネル出力
self.conv2 = nn.Conv2d(6, 16, kernel_size=5, padding=0, stride=1) # 14*14 6チャンネル入力 → 10*10 16チャンネル出力
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2) # 10*10 16チャンネル入力 → 5*5 16チャンネル出力
self.flatten = nn.Flatten() # 5*5 25チャンネル入力 → 400(=5*5*25)出力
self.fc1 = nn.Linear(400, 120) # 400入力, 120出力
self.fc2 = nn.Linear(120, 84) # 120入力, 84出力
self.fc3 = nn.Linear(84, 10) # 84入力, 10出力
self.softmax = nn.Softmax(dim=1) # ソフトマックス関数
self.loss = nn.CrossEntropyLoss() # クロスエントロピー損失
def forward(self, inputs, targets):
# ここには順伝搬のやり方を書く。
h = inputs
# 作用
h = torch.sigmoid(self.conv1(h))
h = self.pool1(h)
h = torch.sigmoid(self.conv2(h))
h = self.pool2(h)
h = self.flatten(h)
h = torch.sigmoid(self.fc1(h))
h = torch.sigmoid(self.fc2(h))
h = self.softmax(self.fc3(h))
# 損失を計算
loss = self.loss(h, targets)
# データ形式をdataclassに包んで出力
return SixFullyConnectedNetOutputs(
loss=loss, # 損失の値を記録
hidden_states=h, # 最終層の値を記録
)
# ニューラルネットの出力をまとめるためのデータクラス。
# データクラスとは、メンバー変数のみを持つクラスのこと。少し特殊な書き方をする。
@dataclass
class SixFullyConnectedNetOutputs():
loss: Optional[torch.FloatTensor] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
# ====================================================================================================================
# ==== 学習のループ ==================================================================================================
def train(model, optimizer, train_dataloader, valid_dataloader, save_dir, num_epochs, device):
logger.info('training start')
# tensorboardにログを書き出すためのライターを作成
writer = SummaryWriter(log_dir=save_dir)
# 学習エポックのループ
for epoch in range(1, num_epochs+1):
# train
model.train() # モデルを訓練モードに変更
train_loss_list = []
for batch in tqdm(train_dataloader): # for文のinの後ろのデータをtqdmで包むと、for文の進捗に合わせてプログレスバーが表示される。
inputs = {k: v.to(device) for k, v in batch.items()} # データをgpuに送る
outputs = model(**inputs) # 順伝搬
loss = outputs.loss # 損失値の取り出し
optimizer.zero_grad() # 各パラメータの勾配値をゼロ初期化
loss.backward() # 逆伝搬して各パラメータの勾配値をセット
optimizer.step() # 各パラメータの勾配値を使って勾配降下を実施
train_loss_list.append(loss.item()) # 平均損失をログとして表示するために損失値を記憶
mean_train_loss = np.mean(train_loss_list) # 平均損失を計算
writer.add_scalar('mean_train_loss', mean_train_loss, epoch) # tensorboardに記録
# eval
model.eval() # モデルを評価モードに変更
valid_loss_list = []
valid_acc_list = []
for batch in tqdm(valid_dataloader): # for文のinの後ろのデータをtqdmで包むと、for文の進捗に合わせてプログレスバーが表示される。
inputs = {k: v.to(device) for k, v in batch.items()} # データをgpuに送る
with torch.no_grad():
outputs = model(**inputs) # (逆伝搬しないので勾配関連の処理を省いて)順伝搬
loss = outputs.loss # 損失値の取り出し
acc = torch.sum(torch.argmax(outputs.hidden_states, dim=-1)==inputs['targets']) / len(outputs.hidden_states) # 精度を計算
valid_loss_list.append(loss.item()) # 平均損失をログとして表示するために損失値を記憶
valid_acc_list.append(acc.item()) # 平均精度をログとして表示するために精度値を記憶
mean_valid_loss = np.mean(valid_loss_list) # 平均損失を計算
mean_valid_acc = np.mean(valid_acc_list) # 平均精度を計算
writer.add_scalar('mean_valid_loss', mean_valid_loss, epoch) # tensorboardに記録
writer.add_scalar('mean_valid_acc', mean_valid_acc, epoch) # tensorboardに記録
# エポック終了時にログの表示
logger.info(f'epoch: {epoch}, mean_train_loss: {mean_train_loss:.3E}, mean_valid_loss: {mean_valid_loss:.3E}, mean_valid_acc: {mean_valid_acc:.3f}')
# パラメータの保存
# ここでは総エポック数の1%が経過する度にパラメータを保存するように設定してある
if epoch in [int(num_epochs/100*n) for n in range(101)]:
save_path = os.path.join(save_dir, f'params_{epoch}.pth')
torch.save(model.state_dict(), save_path)
# ====================================================================================================================
# ==== テスト用の関数 ================================================================================================
def test(model, test_dataloader, model_path, device):
# 指定されたモデルのパラメータをセット
model.load_state_dict(torch.load(model_path))
# test
model.eval() # モデルを評価モードに変更
valid_acc_list = []
for batch in tqdm(test_dataloader): # for文のinの後ろのデータをtqdmで包むと、for文の進捗に合わせてプログレスバーが表示される。
inputs = {k: v.to(device) for k, v in batch.items()} # データをgpuに送る
with torch.no_grad():
outputs = model(**inputs) # (逆伝搬しないので勾配関連の処理を省いて)順伝搬
acc = torch.sum(torch.argmax(outputs.hidden_states, dim=-1)==inputs['targets']) / len(outputs.hidden_states) # 精度を計算
valid_acc_list.append(acc.item()) # 平均精度をログとして表示するために精度値を記憶
mean_valid_acc = np.mean(valid_acc_list) # 平均精度を計算
print(mean_valid_acc)
# ====================================================================================================================
if __name__ == '__main__':
# パラメータ、ログなどの保存先の設定
save_dir = './result/'
os.makedirs(save_dir, exist_ok=True)
# ロギングの設定
logging.basicConfig(
filename=os.path.join(save_dir, 'train.log'), # ログファイルの出力場所
level=logging.INFO, # ログ出力レベルの設定
format='%(asctime)s [%(levelname)s] @%(name)s\t%(message)s', # ログ出力フォーマットの設定
)
# GPUデバイスを使用する場合に、どのGPUを使うかを設定(GPUが使えない場合はCPUを使うように設定)
gpu_id = 0
device = torch.device(f'cuda:{gpu_id}' if torch.cuda.is_available() else 'cpu')
# データのロード
train_dataloader, valid_dataloader, test_dataloader = get_dataloader(
dataset_path='./cifar-10-batches-py/data_batch_1', # データが分かれて面倒なので、ここではbatch1というデータだけを使用
split_ratio=(0.7, 0.1, 0.2), # 分割割合(学習データ、検証データ、テストデータ)を設定
)
# 学習モデルの生成
model = LeNet()
model.to(device) # モデルをGPU(もしくはCPU)用のメモリに送る
# 最適化器の設定
optimizer = optim.Adam(model.parameters(), lr=0.0001) # lrは学習レート
# トレーニング(モデル保存を含む)
num_epochs = 10
train(
model=model,
optimizer=optimizer,
train_dataloader=train_dataloader,
valid_dataloader=valid_dataloader,
save_dir='./result/',
num_epochs=num_epochs,
device=device,
)
# テスト
test(
model=model,
test_dataloader=test_dataloader,
model_path=f'./result/params_{num_epochs}.pth',
device=device,
)
上のプログラム実行方法
1. 環境構築(installするもの)
- pytorch(ニューラルネットを書くために使用)
- tensorbard(ニューラルネットの学習ログを取るために使用)
- tqdm(学習の進行度をプログレスバーとして使うのに使用)
- matplotlib(学習データのサンプル画像を表示するために使用)
2. データセットの用意
- CIFAR-10(画像データセット)
http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz

3. ディレクトリ構成
workspace/ ← 適当なフォルダでOK
├ lenet_cifer10_train.py ← ページの下に書いてあるソースコード
├ cifar-10-python.tar.gz ← ダウンロードしたデータセット
└ result/ ← 学習結果を入れるためのフォルダ
4. cifer-10の解凍
workspace上で tar -zxvf cifar-10-python.tar.gz を使って解凍するだけ
5. 実行
ターミナル上でworkspaceに入り、python lenet_cifer10_train.pyを実行するだけ。
実行結果の例
ターミナル上
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 219/219 [00:19<00:00, 11.36it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 32/32 [00:15<00:00, 2.02it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 219/219 [00:17<00:00, 12.39it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 32/32 [00:15<00:00, 2.09it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 219/219 [00:17<00:00, 12.61it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 32/32 [00:15<00:00, 2.09it/s]
(中略)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 32/32 [00:15<00:00, 2.12it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 63/63 [00:15<00:00, 4.07it/s]
0.1840277777777778
- 「学習→検証」という順のプログラムが10回分計算され、それぞれプログレスバーが表示される。
- 最後に学習後のテストの結果のAccuracyが表示される。
生成されるデータ
workspace/
├ lenet_cifer10_train.py
├ cifar-10-python.tar.gz
├ cifar-10-batches-py/
└ result/
├ params_1.pth ← 学習エポック1回目の後のニューラルネットのパラメータ
├ params_2.pth ← 学習エポック1回目の後のニューラルネットのパラメータ
├ …
├ params_10.pth ← 学習エポック10回目の後のニューラルネットのパラメータ
├ train.log ← 学習ログ
└ events.out.tfevents.* ← 学習ログ(tensorboardの)
resultディレクトリ内のログファイル
result/train.log
2022-11-16 00:03:28,412 [INFO] @__main__ loading ./cifar-10-batches-py/data_batch_1
2022-11-16 00:03:28,464 [INFO] @__main__ completed loading
2022-11-16 00:03:35,005 [INFO] @__main__ data_total_size: 10000, train_size: 7000, valid_size: 1000, test_size: 2000
2022-11-16 00:03:35,023 [INFO] @__main__ training start
2022-11-16 00:04:10,198 [INFO] @__main__ epoch: 1, mean_train_loss: 2.303E+00, mean_valid_loss: 2.304E+00, mean_valid_acc: 0.083
2022-11-16 00:04:43,227 [INFO] @__main__ epoch: 2, mean_train_loss: 2.303E+00, mean_valid_loss: 2.303E+00, mean_valid_acc: 0.083
2022-11-16 00:05:15,924 [INFO] @__main__ epoch: 3, mean_train_loss: 2.302E+00, mean_valid_loss: 2.303E+00, mean_valid_acc: 0.083
2022-11-16 00:05:48,227 [INFO] @__main__ epoch: 4, mean_train_loss: 2.302E+00, mean_valid_loss: 2.301E+00, mean_valid_acc: 0.174
2022-11-16 00:06:38,056 [INFO] @__main__ epoch: 5, mean_train_loss: 2.296E+00, mean_valid_loss: 2.291E+00, mean_valid_acc: 0.181
2022-11-16 00:07:30,855 [INFO] @__main__ epoch: 6, mean_train_loss: 2.278E+00, mean_valid_loss: 2.268E+00, mean_valid_acc: 0.185
2022-11-16 00:08:13,482 [INFO] @__main__ epoch: 7, mean_train_loss: 2.260E+00, mean_valid_loss: 2.256E+00, mean_valid_acc: 0.187
2022-11-16 00:08:46,812 [INFO] @__main__ epoch: 8, mean_train_loss: 2.252E+00, mean_valid_loss: 2.249E+00, mean_valid_acc: 0.187
2022-11-16 00:09:19,214 [INFO] @__main__ epoch: 9, mean_train_loss: 2.247E+00, mean_valid_loss: 2.245E+00, mean_valid_acc: 0.190
2022-11-16 00:09:51,881 [INFO] @__main__ epoch: 10, mean_train_loss: 2.244E+00, mean_valid_loss: 2.242E+00, mean_valid_acc: 0.189
- データセットのデータ量などが最初に出力される。
- 各エポックの「学習時の平均損失」、「検証時の平均損失」、「検証時の平均精度」が出力される。
tensorboard
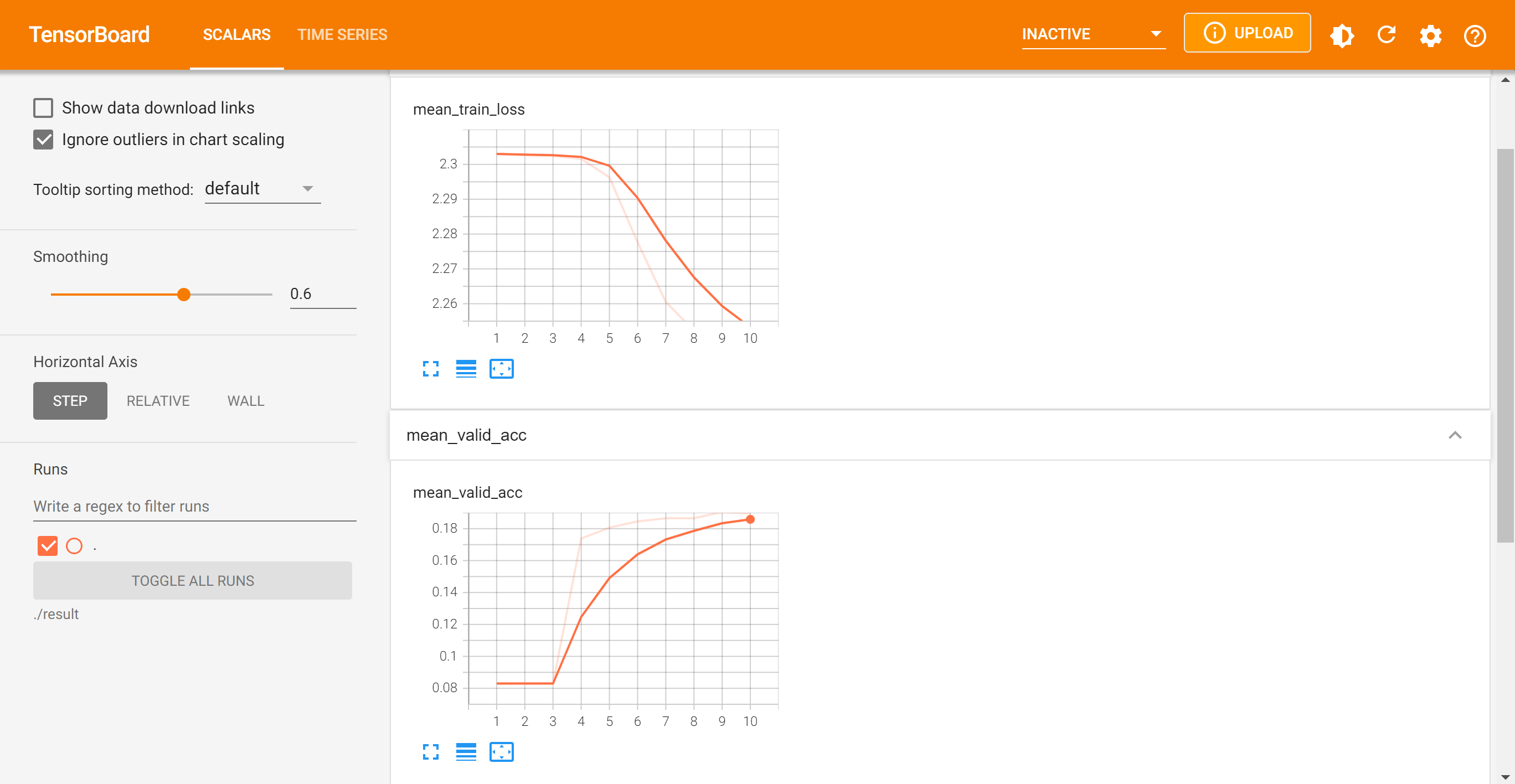
workspace上でtensorboard --logdir ./resultを実行すると次のような表示が出るので、ブラウザでhttp://localhost:6006/にアクセス!
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.9.0 at http://localhost:6006/ (Press CTRL+C to quit)
アクセスすると、次のように「学習時の平均損失」、「検証時の平均損失」、「検証時の平均精度」のグラフが見れるよ。
最後に
- ニューラルネットワークのプログラムをちゃんと書こうとすると、案外結構書かないといけない。。。
- kerasとかで書くならもっと簡単に書けるけど、研究とかで使いたいならpytorchでがりがり書くしかない気がする。
- pytorch lightning ( https://www.pytorchlightning.ai/ ) ってものがあり、これを使えばpytorchでもある程度簡単に書けるんですが、初心者はまずはちゃんと一通りの面倒な書き方を覚えたほうがいいと思う。次回あたりpytorch lightningの使い方の記事で書くかも。