はじめに
Twitter のつぶやきデータを Twitter API を利用して取得し、テキストマイニング(WordCloud)によって可視化します。
今回は、佐賀でつぶやかれた「ラーメン」に関するつぶやきデータを取得して可視化します。
手順は、以下になります。
- Twitter アカウントの作成と Twitter API の申請
- Twitter API を利用し、データを取得
- テキストマイニング(WordCloud)
今回のソースファイルはこちら
環境
- Windows 10 Pro
- Python 3.6.9 (anaconda)
- wordcloud 1.5.0
Twitter API を利用するために
Twitter API とは
Twitter アプリで利用できる機能(ツイートやリツイート、「いいね」をつけたりなど)を外部の他のプログラムから利用できるようにする手続き(インターフェース)です。
Twitter アカウントの作成と Twitter API の利用申請
Twitter アカウントの作成
Twitter の公式ページ にアクセスしてアカウントを作成します。
詳しくは以下のサイトをご参照下さい。
Twitter API の利用申請
アカウントを作成したら、Twitter Developer にアクセスして Twitter API の利用申請を行い、「Consumer API Keys」と「アクセストークン情報」を取得します。
詳しくは以下のサイトをご参照下さい。
Twitter API を利用し、データを取得
Twitter でつぶやかれたデータを取得するプログラムを Twitter API を利用し、作成します。
取得できる最大ツイート数は 18,000件(最大 100件/1リクエスト, 最大リクエスト回数 180回/15分)となります。
取得する条件の指定(指定した日付より以前のツイートなど)もできます。
詳細は以下のサイトをご参照下さい。
対象キーワードを設定
今回はつぶやきに「ラーメン」を含むデータを取得します。
つぶやいた場所を絞り込む
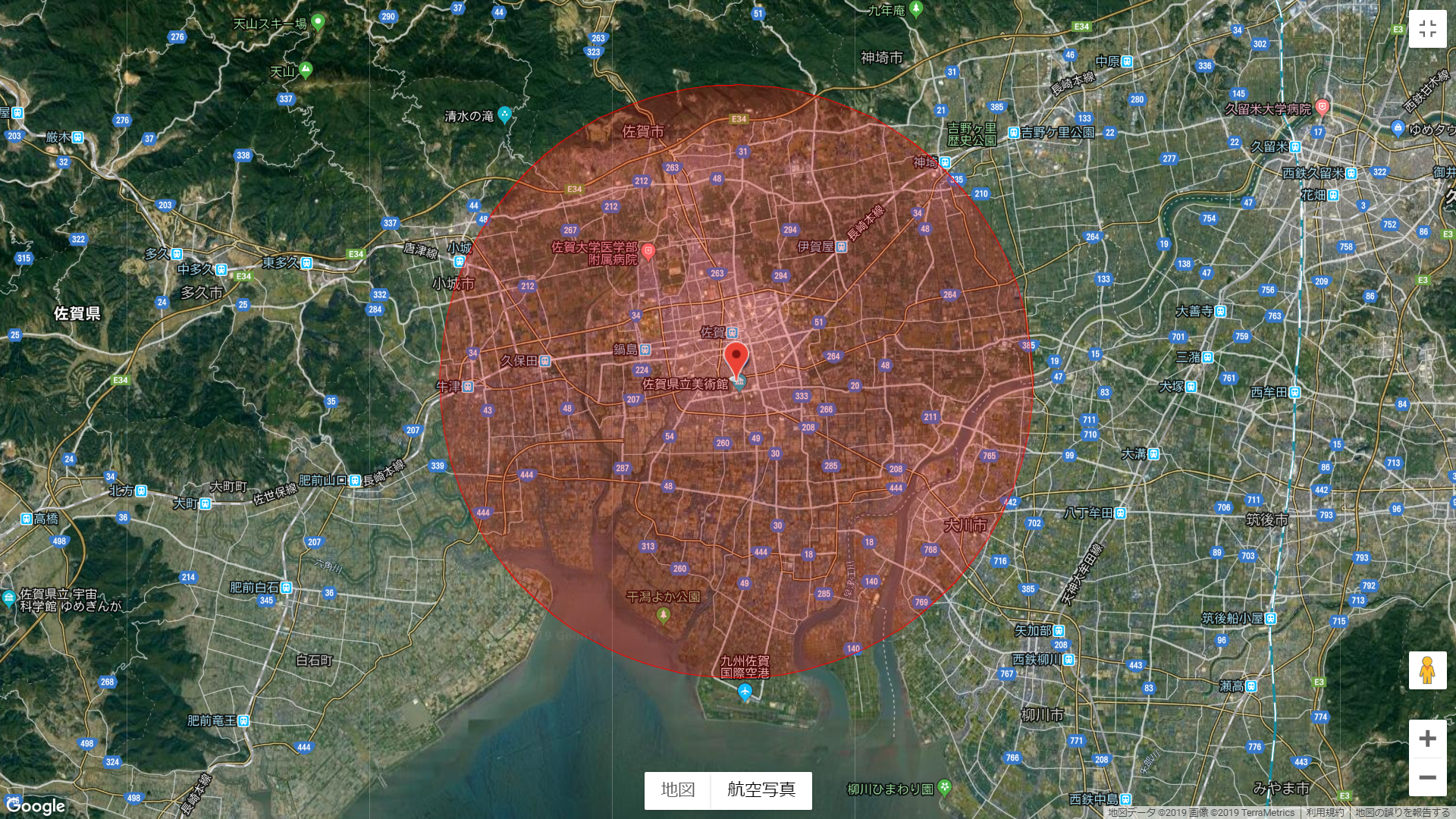
つぶやいた場所は、佐賀県庁(緯度 33.249559・経度 130.299601)を中心に半径 10km とします。
位置情報はジオタグ API から取得しますが、取得できなかった場合は Twitter プロフィールから取得します。
今回の対象エリアは、下図の赤い円の内部。
つぶやきデータを取得する Python プログラム
import json
import pandas as pd
from requests_oauthlib import OAuth1Session
## 以下は取得したアクセストークン情報を入力して下さい。
consumer_api_key= 'xxxxxxxxxxxxxxxx'
consumer_api_secret= 'xxxxxxxxxxxxxxxx'
access_token= 'xxxxxxxxxxxxxxxx'
access_token_secret= 'xxxxxxxxxxxxxxxx'
## twitter API クラス
class TwitterApi:
## コンストラクタ
## 引数 検索キーワード, 1回のリクエストで取得する最大ツイート数
def __init__(self, search_word, count):
## OAuth 認証
self.twitter_api = OAuth1Session(
consumer_api_key, consumer_api_secret,
access_token, access_token_secret)
## API 用 URL
self.url = 'https://api.twitter.com/1.1/search/tweets.json?tweet_mode=extended'
self.params = {
'q': search_word, 'count': count, 'result_type': 'recent',
'exclude': 'retweets', 'geocode': '33.249559,130.299601,10.0km'}
## 取得ツイート数
self.tweet_num = count
## 次のリクエストを実施
def get_next_tweets(self):
req = self.twitter_api.get(self.url, params=self.params)
## 正常に取得できている場合
if req.status_code == 200:
self.x_rate_limit_remaining = req.headers['X-Rate-Limit-Remaining']
self.x_rate_limit_reset = req.headers['X-Rate-Limit-Reset']
## JSON データを辞書型として格納
self.tweets = json.loads(req.text)
self.tweet_num = len(self.tweets['statuses'])
##
if self.tweet_num == 0:
return True
self.max_id = self.tweets['statuses'][0]['id']
self.min_id = self.tweets['statuses'][-1]['id']
next_max_id = self.min_id - 1
self.params['max_id'] = next_max_id
return True
else:
return False
## ツイートデータを取得
def get_tweets_data(self):
## ツイートデータ格納データフレーム
df_tweets = pd.DataFrame([])
while self.tweet_num > 0:
ret = self.get_next_tweets()
## ツイートデータがない場合、ループを抜ける
if self.tweet_num == 0:
break
if ret:
## JSON の辞書型リストを DataFrame に変換
df_temp = pd.io.json.json_normalize(self.tweets['statuses'])
## ツイートデータ格納データフレームに追加
df_tweets = pd.concat([df_tweets, df_temp], axis=0, sort=False)
print('アクセス可能回数 : ', self.x_rate_limit_remaining)
else:
## エラー時はループを抜ける
print('Error! : ', self.tweet_num)
break
## ツイートデータをツイート日時 昇順に並び替えて返す
return df_tweets.sort_values('created_at').reset_index(drop=True)
## メイン
if __name__ == '__main__':
## 検索キーワード「ラーメン」
## 1回のリクエストで取得する最大ツイート数 100
twitter_api = TwitterApi('ラーメン', 100)
## ツイートデータを取得
df_tweets = twitter_api.get_tweets_data()
テキストマイニング(WordCloud)
Twitter より取得したつぶやきデータから名詞と形容詞のみ取り出し、wordcloud を作成します。
「こと」・「もの」などの形式名詞と対象キーワードは除外します。
wordcloud の結果は日本語を表示するので、日本語フォントを指定します。
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
## 除外する単語リスト
ignore_words = ['こと', 'よう', 'そう', 'これ', 'それ', 'もの', 'ここ', 'さん',
'ところ', 'とこ', 'https', 'co', search_word]
## テキストマイニング クラス
class TextMining:
## コンストラクタ
def __init__(self, corpus):
self.corpus = corpus ## コーパス
self.ignore_words = ignore_words ## 除外する単語リスト
## コーパスから単語リストを抽出し、返す
## 引数に品詞リストを指定した場合、その品詞のみ抽出
## 返す単語は基本形(見出し語)
def extract_words(self, word_class=None):
t = Tokenizer()
words = []
## 形態素解析と分かち書き
for i in self.corpus:
tokens = t.tokenize(i)
for token in tokens:
## 品詞を抽出
pos = token.part_of_speech.split(',')[0]
## 対象品詞リストがある場合、指定した品詞のみ抽出
if word_class != None:
## 品詞リストから対象品詞のみ抽出
if pos in word_class:
## 除外する単語を除く
if token.base_form not in self.ignore_words:
words.append(token.base_form)
## 対象品詞リストがない場合、全ての単語を抽出
else:
words.append(token.base_form)
return words
## WordCloud
def word_cloud(self, words, image_file, font_path=japanese_font):
wordcloud = WordCloud(
background_color='white', font_path='./IPAexfont00301/ipaexg.ttf', ## 日本語フォントを指定
width=800, height=400).generate(words)
## 結果をファイルへ保存
wordcloud.to_file(image_file)
return True
## メイン
if __name__ == '__main__':
## テキストマイニング クラス
text_mining = TextMining(df_tweets['full_text'])
## ツイートから対象品詞を抽出し、単語リストを得る
## 引数 対象品詞リスト
words = text_mining.extract_words(['名詞', '形容詞'])
## WordCloud
## 引数 単語データ(スペース区切り), 結果出力ファイル
text_mining.word_cloud(' '.join(words), './wordcloud.png')
wordcloud の結果

ちなみに、博多駅の場合
博多駅(緯度 33.589728・経度 130.420727)を中心に半径 10km の場合

さらに、西鉄久留米駅の場合
西鉄久留米駅(緯度 33.312436・経度 130.521461)を中心に半径 10km の場合
