概要
計算社会科学入門 というこの分野の教科書的な書籍が発売された。しかしこの書籍ではどの様にデータ(特にtwitterなどの大規模データ)を集めるのかという記事は少なかった。そのため前書の内容を補完する意味で、twitterのサンプリングデータをもし、BigQueryに入れて活用するならどうするかと言ったHowToを書く。
計算社会科学
計算社会学入門の冒頭には、同分野に関して、
計算社会学とは、人間の相互関係によって成り立つ社会をデータに基づいて解明していく学問である。
とある。
その中で、SNSは特に人間関係の相互関係(フォローフォロイー、返信)などの興味深いデータがある。しかし、前書ではではどの様にSNS上のデータを集めるのかに対して、その概要を述べるにとどまっている(第四章にその記述がある)。
この記事では、計算科学入門では触れられなかった、それでは例えばtwitterからデータを集めるとしたらどうするのか?という観点で詳細を書くことにする。
何故ならば計算社会科学はデータを使った分析なので、まずデータを集める必要がある。しかし後述するtwitterのサンプリングデータでも一日50万件程度あり、そのハンドリングにはある程度エンジニアリングスキルが必要だからだ(そのノウハウは余り表には出てこない)。
データの収集と倫理
計算社会学入門で、データ収集やアルゴリズムに関する倫理についての一章を割いて説明している(第11章)。また、twitterの開発者ポリシーに従う必要がある。
今回作るものアーキテクチャー
今回は、twitterのsampling dataを使ってtwitter社が公開している全tweetの1%サンプルを、GCP(Google Cloud Platform) にあるBigQueryに保存するというシステムを開発する。
スケルトンプログラムは、こちらのgithubに用意しました。
図にすると以下のようなデータの流れになる。
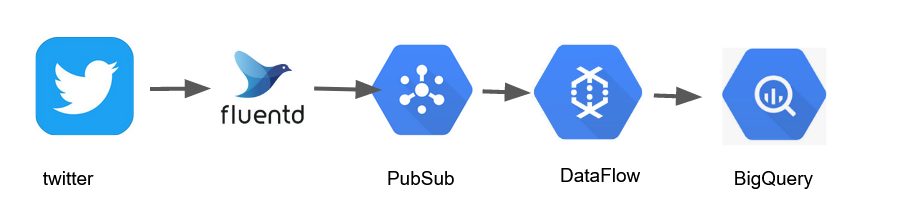
- twitterからのstreaming sampleはfluendで受ける。
- そのデータは、GCPのPubSubに投げる。
- dataflowを使って、tweet,引用tweet,ReTweet,投稿Userでテーブルを作る
- そのデータをBigQueryに格納する
という手順でデータを収集する。技術的には fluned でBigQueryにtweetを保存までできるが、データの収集と、データの整形と保存に関してそれぞれ責任を分担したいので上記のような構造を選択した(単一責任の原則から着想を得ました)。
何故tweetにuserを入れずにuserテーブルを分けるのかと言うと、tweetのままでもBigQueryは検索できるのですが、ネストが深いと直感的なデータの把握がしづらく、クエリーも複雑なものになりがちなので、tweet,retweet,引用tweet,Userでテーブルを分けました。本当に使う際には、メディアツイート、位置ツイート、hashタグなども分離します(その方がテーブル構造がシンプルになるので)。
twitterのSampled streamをflunetdで受けて、pubsubに格納するまで
用意するもの
- twitterの開発者アカウント
- Google PubSubのTopic
twitterの開発者アカウント
twitterのSampled streamを取得する場合は、twitterの開発者アカウントが必要になります。開発者アカウントはtwitterの開発者サイトで作成してください。英語で用途などを入力する必要があるかもしれません。
詳しくはこちらのサイトが参考になるかもしれません(2019年8月時点の情報です)。
GCPのpubsub TOPIC
PUBSUBについての概要はこちら。
pubsubは、事前にご自身のプロジェクトで、トピックの作成をお願いします。
fluentdの準備
fluentdはこちらで、イントールをお願いします。
必要なプラグインの準備
twitterからpubshubへのデータ保存には、flunetdに対して、いくつかプラグインを追加する必要があります。
- fluent-plugin-twitter twitterのプラグインhttps://github.com/y-ken/fluent-plugin-twitter
- fluent-plugin-gcloud-pubsub-custom pubsubへのプラグインになります。https://github.com/mia-0032/fluent-plugin-gcloud-pubsub-custom pubsubプラグインは、こちら もありますが、pubsub-customの方が新しいようです。
twitter-pluginで日本語の判定をする。
twitter-pluginでは、日本語がうまく判定できないかもしれません。その際はこちらのPRを参考にtwitter-pluginの修正が必要になります。 https://github.com/y-ken/fluent-plugin-twitter/pull/45/files
flunetdのconfファイルの準備
fluentdのconfファイルは次のようになります。
github上はこちら
consumer_key,consumer_secret,access_token, access_token_secret は、twitterの開発者サイトで取得できます。lang jaは上記にあるように、twitter-pluginの修正が必要かもしれません。
twitterからデータ取得
<source>
@type twitter
consumer_key xxxxxxxxxxxxxx
consumer_secret xxxxxxxxxxxxxxxxxxxxxxx
access_token xxxxxxxxxxxxxxxxxxxxx
access_token_secret xxxxxxxxxxxxxxxxxxx
tag input.twitter.sampling
timeline sampling
lang ja
output_format nest
</source>
pubsubへの格納
これは、メモリへbufferをためて一秒ごとに送信するというもの
<match input.twitter.sampling>
@type gcloud_pubsub
project xxxxxxxxxxxxxxxxx
key xxxxxxxx.json
topic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
autocreate_topic false
max_messages 1000
max_total_size 9800000
max_message_size 4000000
compression zip
<buffer>
@type memory
flush_interval 1s
</buffer>
<format>
@type json
</format>
</match>
pubsubからBigQueryへデータをロードする
pubsubへデータを格納した後、dataflowを利用して、BigQueryへデータを送る。これは、pythonで行う。
githubはこちら。
python-apache-beamの準備
pythonでdataflowを使う場合は apache-beam ライブラリを使う。
pip install apache-beam
こうすれば apache-beamがインストールされる。
コードの解説
with beam.Pipeline(options=pipeline_options) as p:
# Read from PubSub into a PCollection.
if known_args.input_subscription:
messages = (
p
| beam.io.ReadFromPubSub(subscription=known_args.input_subscription).\
with_output_types(bytes)) #<- pubsubのsubscriptionからデータをread
lines = messages | 'decode' >> beam.Map(lambda x: x.decode('utf-8')) #バイナリなので、utf-8に変更する。
devide_dict = (
lines
| 'devide_dict' >> (beam.ParDo(DevideDict())) #DevideDictでJSONをパースして、中身を取り出す。
| "to BQ" >> WriteToBigQuery(table_fn,schema=schema_fn,project="xxxxxxxxx") #table_fn,schema_fnで `table_name` を見て対象テーブル振り分け
#| "print" >> (beam.Map(print))
)
DevideDict
elementはjsonなので、loadでdictにしたあと、変更する。
table_fn
table_nameによってテーブル振り分けする。
schema_fn
同様に、schemaも振り分ける。
一旦BigQueryにロードすることで他の分析ができるようになる。
sampleingのデータは、日本語tweetで一日50万件程度だ。一年で大体1億から2億ぐらいになる。mysqlで分析するのは困難になる。bigqueryに入れることでデータの分析がしやすくなる。こちらの記事にあるように、形態素解析もできるようになる。
データ分析のためにはデータの取得が必要になる。そのための一助になれば幸いだ。