このシルバーウィークは、Elixirを勉強している。
Qiitaでも次のような投稿をした。
Elixirを試してみた。HirofumiTamori さんのElixirチュートリアルをやってみる
ElixirはerlangVM上で動くRubyっぽい文法の言語だ。このサイトの紹介が詳しい。 Elixir : Erlang VM 上で動作する Ruby 風味の関数型言語
実際どのくらい実用に堪えるのか確認するため、昔作ったニコニコ動画で似た動画を推薦するレコメンドエンジン部分を作ってみた。
ソースコードはこちらに公開している。
中心になるソースコードは、lib/relation_view.exである。
ニコニコ動画データセットを使ったリコメンドエンジン
類似動画の集計結果
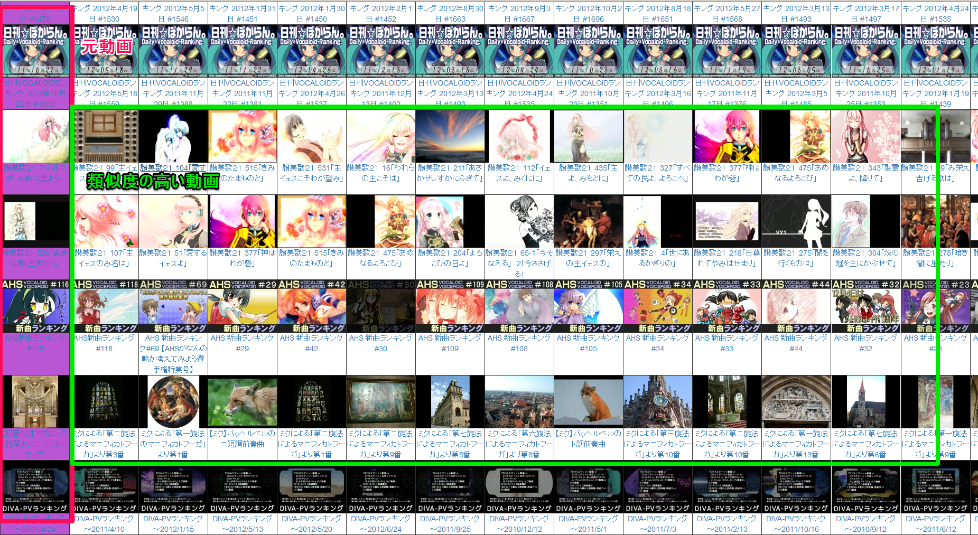
まず最初に今回作成したレコメンドエンジンの集計結果を示す。
左の紫色の背景の、動画が元となる動画、右の白の背景の動画は、その動画と類似度の高い順に並べた動画だ。
今回作成したレコメンドエンジンで、集計した。動画についているタグで、類似度を計算しているため、日刊ランキングなどはほぼ同じタグになるため、類似動画として多くリストアップされる。
集計した所、比較的似た動画がリストアップされているようだ。
概要
ニコニコ動画データセット言う物がある。2007-2012までのニコニコ動画の動画情報、タグ情報、コメント情報が配布されている。
今回は、その中でも、動画情報とタグ情報を使って、リコメンドエンジンを作る。
使用するのは動画情報、上記のデータセットの動画情報を用意する。
0000.dat.gz 0002.dat.gz 0004.dat.gz
という形式で配っている。
内容は次のようになっている。
{u'comment_counter': 337,
u'length': 384,
u'movie_type': u'flv',
u'mylist_counter': 101,
u'size_high': 15860960,
u'size_low': 15622973,
u'tags': [{u'tag': u'k-pop'},
{u'tag': u'\u2192sm1014'},
{u'lock': 1, u'tag': u'\u30dd\u30f3\u30c1\u30e3\u30c3\u30af'},
{u'lock': 1, u'tag': u'\u674e\u535a\u58eb'},
{u'tag': u'\u771f\u306e\u97d3\u6d41\u30b9\u30bf\u30fc'},
{u'tag': u'\u97d3\u56fd'}],
u'thread_id': 1173132609,
u'thumbnail_url': u'http://tn-skr2.smilevideo.jp/smile?i=1001',
u'title': u'\u674e\u535a\u58eb\u3000\u30dd\u30f3\u30c1\u30e3\u30c3\u30af\u30c7\u30a3\u30b9\u30b3',
u'upload_time': u'2007-03-06T07:10:10+09:00',
u'video_id': u'sm1001',
u'view_counter': 10246}
この中で、video_idとtagsの中のタグ情報を利用する。
基本的なアルゴリズムは、昔々天下一カウボーイ大会で利用したrelational_viewerの仕組みを利用する。
基本的には、同じタグを共有しているかを計算するが、一工夫して、希少度が高いタグを共有していれば、似た動画と判断している。
例えば次のような感じである。

上の画像は2つの似ている動画のタグを比較したものだ。
VOCALOIODというタグと、冷凍麦茶というタグを共有している。VOCALOIDというタグは、2つの動画に共通しているが、一般的なタグのため、小さなポイントしか与えられない。一方、冷凍麦茶はこの2つの動画以外に、10件しかついておらず希少なタグなので大きなポイントが付いている、そのため単にタグを共通で持っているだけでなく希少なタグを、共有しているので似ていると判定する。
VInfoTagsの:normalizeのセクションで、各タグの希少度(重み)を計算している。
その希少度を元に、動画毎にタグを比較して、共起したタグの値を計算して、動画の類似度を判定している。
SimilaritySearchのresearchで計算している。
実行
Elixirは簡単にマルチコアでのプログラムが書けるそうなので、EC2で、16コアのマシンを借りて、テストしてみた。
借りたマシンは、m4.4xlargeで、CPUは16core、メモリは64GBある。
ボーカロイド(VOCALOID)タグを持つ動画同士の、類似度を測定した。
12万件あり、全ての類似度を測るのに140億位の調査をした。よく考えたらもっと効果的なアルゴリズムがあるかもしれないが、思いつかなかった。12万件x12万件の調査に、6時間位かかった。昔、作った時には、2週間位演算にかかっていた気がしたんで、それでもだいぶ早くなっている。
実行時のTOP画像
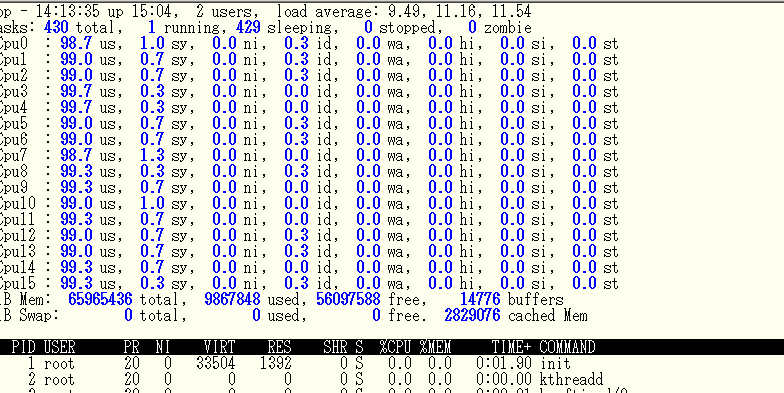
マルチコアのCPUは効率的に使えているようだ。
実行結果実行結果は、
元となる動画、比較動画、類似度で、ソートして上位40件をファイルに書きだした。
sm17605241,sm18236361,2.5116585747968436
sm17605241,sm17670858,2.5116585747968436
sm17605241,sm15063598,2.5116585747968436
sm17605241,sm16562741,2.5116585747968436
sm17605241,sm17316656,2.5116585747968436
sm17605241,sm17019694,2.5116585747968436
sm17605241,sm17143747,2.313397715093444
sm17605241,sm18251938,2.274968701506397
sm17605241,sm17202294,2.274968701506397
sm17605241,sm18600435,1.9881636276721941
の様な型式になる。
その他の話
プロダクションビルド
プロダクションビルドは次のようにする
MIX_ENV=prod mix escript.build
プロダクションのほうが心持ちCPUを効率的に使えているようだ。
メモリ消費を少なくする方法
tagmapにタグ情報を保存したが、タグ自体を、keyにすると、メモリ量が膨大になるので、
cpt = :crypto.hash(:md5,a["tag"])
一旦md5へのハッシュ化してから格納した(重複は無視した)