まえがき
この記事は株式会社ビットキー 情シス Advent Calendar 2023 の20日目の投稿です。
はじめまして。株式会社ビットキーのshiba_no_sukeです。
SaaSサービス利用がメインのビットキー情シスの世界に3か月前飛び込んできましたが、前職ではスクラッチで社内Webアプリなどを作る機会の方が多い情シス担当者でした。
今回、BigQueryについてお話ししますが、アプリ屋さんだった筆者の前提スキルをお伝えしておきます。
- BigQuery、触ったことありません
- SQL Serverは利用していたので、クエリは一応書けます
- Javascriptは、まあまあ書けます
こんなレベル感の人間でも、何とかなります、という視点でご覧いただければ幸いです。
前提・課題
2023年12月現在、ビットキーでは受注・契約・請求などのデータを、Googleドライブで保管している、Googleスプレッドシート(GSS)で入力・管理しています。
これらのデータをGSS上で計算・加工して、管理会計の分析に利活用しています。
しかし、当然のことながら、元となるデータは日に日に増えていくため、GSSの計算処理は徐々に遅くなりつつあります。
また、GSSに埋め込まれた計算ロジックが、正しい範囲に適用されているよね…?この数字の計算って合ってるよね…?と、分析結果の確からしさに疑問が生まれることも出てきました。
そこで、速く・正確に、管理会計の分析をするために
- GSSはデータ入力のインターフェイスとして専念させて、
- BigQueryに複雑な計算処理をがんばってもらい、
- Looker Studioで自由に見たい形の管理会計レポートを表現しよう!
と、Googleが提供する各種サービスを活用して改善しよう、いうことになりました。
この記事で、改善活動のすべてをお伝えすると、長ーったらしくなってしまうので、今回はBigQuery環境構築編と題して、BigQueryにGSSのデータをインポートするまで、をお伝えしようと思います。
概要
絵心がなさすぎですが、GSSデータをBigQueryに連携する、今回の簡単な構成イメージです。

- Googleドライブ上のGSSデータを、BigQueryの外部テーブル(一時テーブル)を経由して、BigQueryの標準テーブルに連携するのが、本記事のゴールです。
- 一時テーブルを使用して、Googleドライブのデータにクエリを実行する方法はいくつかありますが、Google Apps Script(GAS)でGoogle BigQuery APIを利用できるため、筆者は「BigQuery APIでjobs.insertを呼び出す」という方法を選択しました。
- 参考にしたGoogle公式ドキュメントをいくつか載せておきます
ハンズオン
GSSデータを準備する
この記事では、GSSの2つのシートにあるデータを、BigQuery上の2つのテーブルに連携する、というシチュエーションでお伝えします。
-
GSSデータ
- sheet1

- sheet2

BigQuery標準テーブルを作成する
標準テーブルの作成方法はたくさんあるので、公式ドキュメントを参照しながら、お好きな方法で作成してください。
(ここはさほど難しくないので、詳細な手順は割愛します。)
作成後の標準テーブルは、以下のイメージです。
- table_A(sheet1の連携先テーブル)

- table_B(sheet2の連携先テーブル)

GSS上にGAS開発環境を作成し、BigQuery APIを呼べるようにする
次に、BigQuery APIを呼び出すためのGAS環境を作成します。
①GSSのメニュー:拡張機能 > Apps Scriptを選択して、新規のGASプロジェクトを作成します。
②サービスの追加を選択して、BigQuery APIを追加します。

③サービスの下にBigQueryが表示されていればOKです。

外部テーブル(一時テーブル)用のjsonスキーマ 兼 BigQueryのジョブ定義を作成する
次に、GSSとBigQueryの標準テーブルをつなぐ、外部テーブルの定義を構成するjsonスキーマでもあり、BigQueryのジョブ定義でもある、スクリプトファイルを作成します。
①GAS開発環境のメニュー:ファイルを追加 > スクリプトを選択します。
②以下のスクリプトを記入します。
(テーブル定義やBigQueryの環境変数は、適宜変更してください。)
const tableA_job = {
"configuration": {
"query": {
//一時テーブルtemp_Aのデータを、BigQuery標準テーブルtable_Aに全件INSERTするというクエリ
"query": "INSERT INTO dataset.table_A SELECT * FROM temp_A",
"tableDefinitions": {
"temp_A": { //一時テーブルの名前をtemp_Aとしておく
"autodetect": false,
"sourceFormat": "GOOGLE_SHEETS",
"sourceUris": [
//データ連携対象のGSSのURLのSpreadsheetIDまでをセットする
"https://docs.google.com/spreadsheets/d/***************************************"
],
"googleSheetsOptions": {
"range": "sheet1!A:E", //GSSの連携対象のシートと範囲を指定する
"skipLeadingRows": 1 //シートの連携対象からスキップしたい行数を指定する
},
"schema": {
"fields": [
{
"name": "a",
"type": "STRING"
},
{
"name": "b",
"type": "STRING"
},
{
"name": "c",
"type": "INTEGER"
},
{
"name": "d",
"type": "DATE"
},
{
"name": "e",
"type": "STRING"
}
]
}
}
},
"useLegacySql": false
},
//ジョブのタイムアウト設定(ミリ秒)
"jobTimeoutMs": 300000,
//大量データの連携を検証するときは、dryRunをtrueにするようにしましょう!
"dryRun":false
},
"jobReference": {
//ロケーションを明示的に指定する
"location": "your-location"
}
};
Sheet2のデータをtable_Bに連携するためのスクリプトも、同様に作成しています。
テーブルのカラム数が多い場合は、BigQueryのテーブルスキーマをJSON形式で取得すると便利です。
以下のサイトが大変参考になりました。
BigQueryのテーブルスキーマをJSON形式で取得する方法
BigQueryにデータをインポートするジョブを作成する実行文をGASで書く
最後に、Apps Scriptの公式ドキュメントに掲載されているサンプルをもとに、実行文を書いてみます。
①GAS開発環境のメニュー:ファイルを追加 > スクリプトを選択します。
②以下のスクリプトを記入します。
(BigQueryのプロジェクトIDなどは、別のスクリプトファイルで定数として定義しています。)
function insertJobs() {
//スプレッドシートが置かれているGoogle DriveのフォルダのIDを指定する
//フォルダID=ブラウザ上でドライブを開き、対象のフォルダにアクセスしたときのURLから確認できる
//「https://drive.google.com/drive/folders/〇〇〇〇」の〇〇〇〇部分
const folderId = GDRIVE_FOLDER_ID;
DriveApp.getFolderById(folderId);
//BigQueryのプロジェクトIDを指定する
const projectId = BIGQUERY_PROJECT_ID;
//BigQueryのロケーションを指定する
const location = BIGQUERY_DATASET_LOCATION;
//ジョブの定義
const a_job = tableA_job;
const b_job = tableB_job;
try {
//2テーブル分同時にジョブを仕込む
const tableAJobInsert = BigQuery.Jobs.insert(a_job, projectId);
const tableBJobInsert = BigQuery.Jobs.insert(b_job, projectId);
//2つのジョブが完了するまでの間、5秒待ってジョブの結果を取りに行く、を繰り返す
while (
BigQuery.Jobs.get(projectId, tableAJobInsert.jobReference.jobId, { "location": location }).status.state != "DONE"
|| BigQuery.Jobs.get(projectId, tableBJobInsert.jobReference.jobId, { "location": location }).status.state != "DONE"
) Utilities.sleep(5000);
//各ジョブの結果を取得する
const tableAJobResult = BigQuery.Jobs.get(projectId, tableAJobInsert.jobReference.jobId, { "location": location });
//table_AのデータINSERTに失敗したら、ジョブのエラー結果をキャッチする
if (tableAJobResult.status.errorResult != null) {
console.log('table_A:Job insertion failed.');
console.log('error code:' + tableAJobResult.status.errorResult.reason);
console.log('error message:' + tableAJobResult.status.errorResult.message);
} else {
//ジョブが成功したとき
console.log('table_A:Job insertion succeeded!');
}
const tableBJobResult = BigQuery.Jobs.get(projectId, tableBJobInsert.jobReference.jobId, { "location": location });
//table_BのデータINSERTに失敗したら、ジョブのエラー結果をキャッチする
if (tableBJobResult.status.errorResult != null) {
console.log('table_B:Job insertion failed.');
console.log('error code:' + tableBJobResult.status.errorResult.reason);
console.log('error message:' + tableBJobResult.status.errorResult.message);
} else {
//ジョブが成功したとき
console.log('table_B:Job insertion succeeded!');
}
//スクリプトの中でエラーが発生したら、エラー結果をキャッチする
} catch (err) {
console.log('An error occurred in executing the script.');
console.log(err);
}
}
実行してみよう!
試しに、GAS開発環境で実行してみます。

table_Aもtable_Bも、成功という結果が返ってきました!!
本当に成功したのか、BigQueryのジョブの結果も見てみましょう。

同じ時間にtable_Aとtable_Bへのデータ連携ジョブが作成され、どちらも成功しています!
では、最後にテーブルの結果も見てみましょう。
- table_A

- table_B

どちらのテーブルにも、GSSに準備したデータが全件登録されていることが確認できました!
大量レコードを処理してみよう!
上記の方法を使って、同じGSS内で、以下の大量レコードを持つ2シート分のデータを処理してみます。
-
table_C
- 列:A~Z(26カラム)✕ 30,000レコード
- A列はINTEGER型で行番号を振り、B列はSTRING型の列に、C列以降は適当に計算させたINTEGER型の列になっています。

-
table_D
- 列:A~Z(26カラム)✕ 50,000レコード
- table_Cと同じ構成で、20,000レコード増やしました。
データとプログラムを準備して、GASを実行してみました。

なんと、30秒で成功という結果が返ってきました!
ホントかよ…と、ちょっと疑いたくなるぐらいですね…
ということで、ジョブとテーブルの結果も確認してみましょう。

- table_C


- table_D

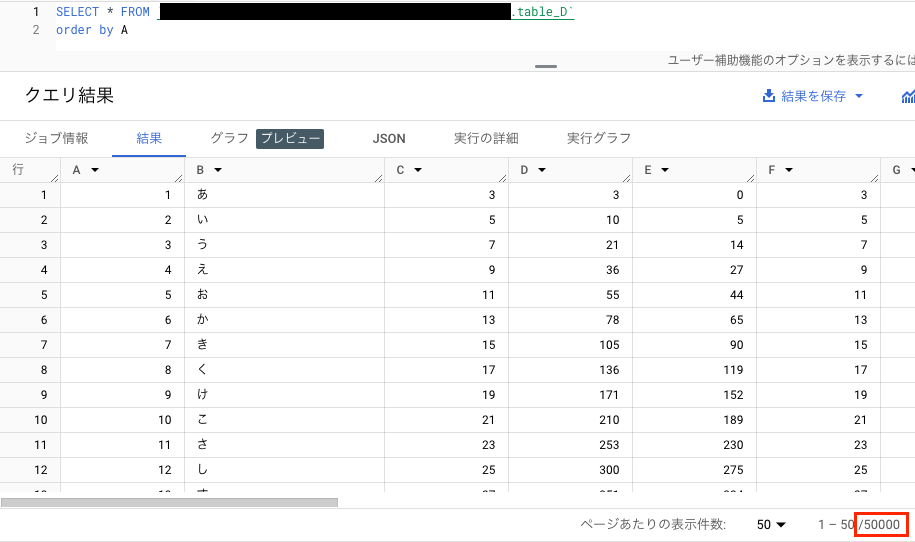
30,000レコードのtable_Cは17秒で、50,000レコードのtable_Dは26秒で、データが連携されていることが確認できました!
BigQuery上なら、大量データの計算も加工も、とても速く実行することができます。
例えば、「table_Cとtable_DをA列をキーにINNER JOINし、(簡単な計算式ではあるけれど…)各列を計算させて30,000レコードSELECTする」といった以下のクエリの実行速度は、たったの1秒です!
SELECT
c.A AS rowNo,
c.B AS title,
c.C + d.C AS C,
c.D - d.C AS D,
SAFE_MULTIPLY(c.E, d.E) AS E,
c.F / d.F AS F,
MOD(c.G, d.G) AS G,
SAFE_MULTIPLY(c.H, d.H) AS H,
c.I + d.I AS I,
c.J - d.J AS J,
SAFE_MULTIPLY(c.K, d.K) AS K,
c.L / d.L AS L,
MOD(c.M, d.M) AS M,
SAFE_MULTIPLY(c.N, d.N) AS N,
c.O + d.O AS O,
c.P - d.P AS P,
SAFE_MULTIPLY(c.Q, d.Q) AS Q,
c.R / d.R AS R,
MOD(c.S, d.S) AS S,
SAFE_MULTIPLY(c.T, d.T) AS T,
c.U + d.U AS U,
c.V - d.V AS V,
SAFE_MULTIPLY(c.W, d.W) AS W,
c.X / d.X AS X,
MOD(c.Y, d.Y) AS Y,
SAFE_MULTIPLY(c.Z, d.Z) AS Z
FROM
`dataset.table_C` AS c
INNER JOIN
`dataset.table_D` AS d
ON
c.A = d.A
ORDER BY
rowNo

上記のクエリと同じ結果が得られるよう、GSS上で計算させてみたところ、30,000レコード分の全体の計算結果が返ってくるまで、約7秒かかりました。
(以下のような感じで、各列に計算式を入れています。)

もちろん、結果を単純比較することはできませんが、BigQueryが"分析用データベース"というだけのことはあるようです。
余談
GSSの同一ワークブック内のデータ量の限界は、1,000万セルとなっています。(2023/12時点)
26カラムの場合、理論上だと384,615レコード登録できる計算です。
この章の検証をするにあたって、限界までデータを登録するとGSSの挙動が不安定になるだろうと、半分の19万強レコードで検証しようと考えていました。
が、しかし、実際に19万レコードのデータをGSSに準備してみると、計算式を入れている関係もあるのか、GUIが固まってしまいました…(きっと、あるあるですよね!)
GSSの限界セル数は、段階を経て徐々に増えていますが、ゴリゴリ計算が必要なビッグデータを扱うのは難しい部分もあるようです。
改善計画の動機に戻ってしまいますが、データの分析や表示については、やはり、餅は餅屋ということで、BigQueryやLooker Studioに任せた方がよさそうだと感じました。
メリット/何が嬉しいのか
今回、上記の方法を選択したのには、いくつか理由がありました。
①データ連携のトリガーを自動化したい
・・・GASでBigQueryのジョブを作成する、という手段は、データ連携を一定のタイミングで自動的に実行する上で、比較的容易に実装することができると考えたからでした。
また、ジョブの作成を並行して実行できるため、複数のテーブルデータを連携するときに、データの静止点を作ることもできます。
②データ連携がエラーになったとき、外部でエラー内容をキャッチできるようにしたい
・・・GASでジョブの結果を取得することで、SlackやGmailでエラー結果を通知する、GSSにエラーログを転記する、など、様々な方法でエラー内容をキャッチすることができます。
継続課題(2023/12/20現在)
本記事を書いている時点では、GSS・BigQuery・Googleドライブの各環境に必要な権限が何か、という点を検証している段階であるため、詳細をお伝えすることができませんでした。
検証結果をまとめられたら、改善活動の続きとともに、新たな記事にできたらよいなと思っています。
最後に
はじめにお伝えした通り、「BigQuery?触ったことない!」という筆者でしたが、いろいろ調査・検証した結果、こんな方法もありますよー、という1つを、まとめることができたと思っています。
ですが、本記事の方法がベストだ!というわけではありません。
もっとよい方法があるよ、こんな方法もあるよ、という方がいらっしゃいましたら、ぜひ、共有していただけると幸いです!