はじめに
前回の記事の続きになります。
https://qiita.com/shallowdf20/items/eb35a9cf3c24403debb1
今回はDataLinerのうちEncoding系の処理について紹介したいと思います。
インストール
! pip install -U dataliner
データ準備
前回同様Titanicのデータを準備します。
import pandas as pd
import dataliner as dl
df = pd.read_csv('train.csv')
target_col = 'Survived'
X = df.drop(target_col, axis=1)
y = df[target_col]

SexやNameなどのカテゴリ変数を何らかの方法でEncodingしてあげることで、そのままでは扱えない文字列を数式やモデルで扱うことができるようになります。
それでは早速見ていきましょう。
OneHotEncoding
もっとも一般的なエンコーディング手法です。カテゴリー変数を0と1のダミー変数で置き換えます。
まずは見てみましょう。
trans = dl.OneHotEncoding()
trans.fit_transform(X)
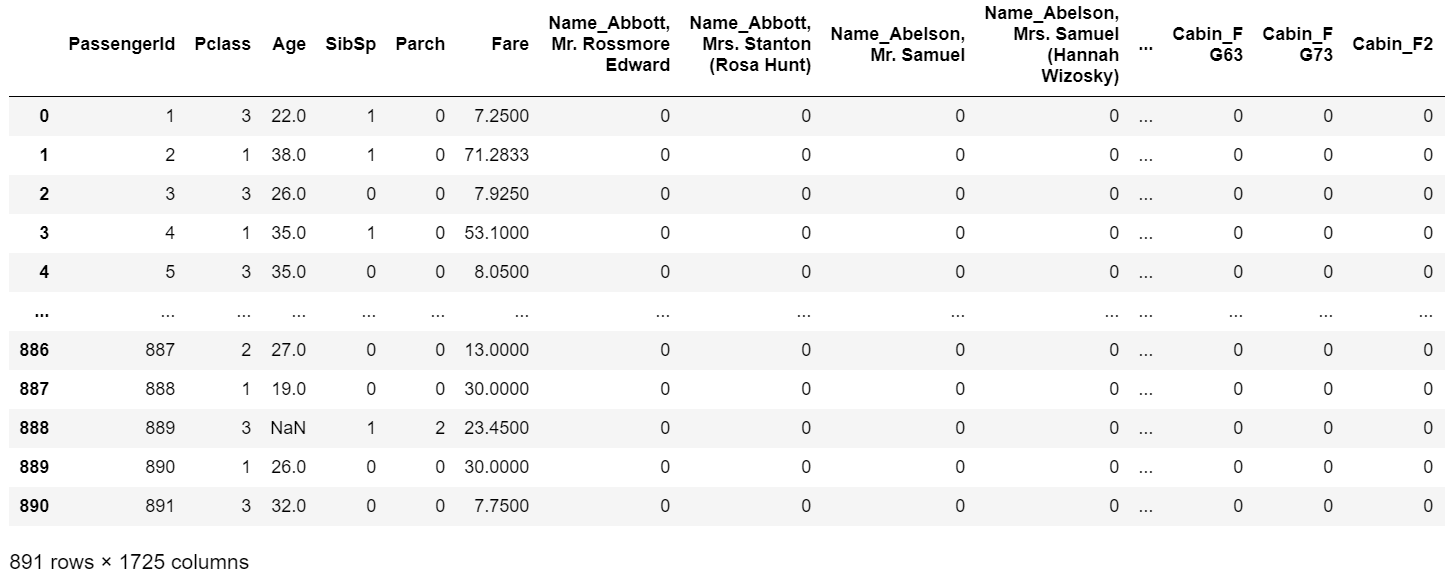
列数が一気に増えました。例えば名前はデータ数=891名分の種類があるので、一気に891列も増えてしまいます。
この後にDropLowAUCなどで変数を落としても良いですが、事前にGroupRareCategoryやDropHighCardinalityをかけておく方がよいでしょう。
試しにパイプラインでDropHighCardinalityをかけてからエンコーディングしてみます。
from sklearn.pipeline import make_pipeline
process = make_pipeline(
dl.DropHighCardinality(),
dl.OneHotEncoding(),
)
process.fit_transform(X)

常識的な特徴量数に収まりました。
尚、例えばTitanicの性別のように男女しか存在しない変数をダミー変数化する場合は共線性をさけるためにどちらか片方の列を落とすのが一般的です。
DataLinerではdrop_firstという引数を準備しており、デフォルトでTrue=自動で落とす実装となっています。
CountEncoding
これはカテゴリ変数を、カテゴリーの出現回数で置き換えるエンコーディングです。まずは、Titanicで性別毎の乗客数を見てみましょう。
df['Sex'].value_counts()
male 577
female 314
Name: Sex, dtype: int64
男性は577名、女性は314名ですね。
では、CountEncodingを行ってみます。
trans = dl.CountEncoding()
trans.fit_transform(X)

Sexの列を見ると、確かにカウント数で置き換えられていることがわかります。自動的にカテゴリ列を認識するので、他のカテゴリ列であるNameやEmbarkedなども数字に置き換わっています。
RankedCountEncoding
CountEncodingはシンプルながら強力な手法ですが、例えば1種類のカテゴリが異常に多いなどの外れ値に弱い欠点があります。また、出現回数が同じカテゴリーがあると、それらは同一の数字で置き換えられてしまうため区別がつかなくなる性質もあります。(もちろん、本質的に区別すべきでない場合はそれで正しいのですが)
そこで、出現回数に置き換えたうえで出現回数の多い順にランキングを作成し、その順位でカテゴリ変数を置き換えるというのがこのエンコーダーです。先ほどの例でいえば、男性が577名なのでSex内では1位、女性は314名なのでSex内で2位の出現回数です。
trans = dl.RankedCountEncoding()
trans.fit_transform(X)

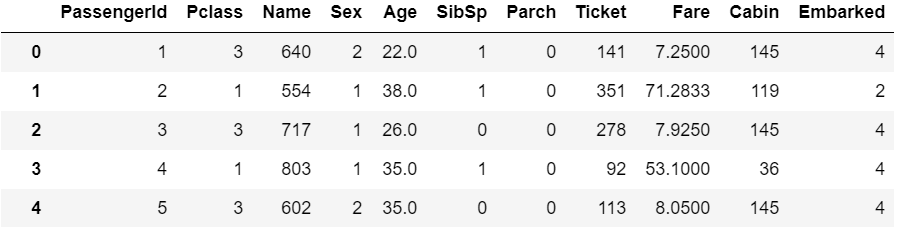
男性と女性がそれぞれ1と2で置き換わっています。また、Nameを確認すると出現回数はどれも1回ですが異なる数字でEncodingされていることがわかります。
これは同一の出現回数の場合でも、ランキング化した後のインデックスを使ってエンコードしているのでカテゴリが違う場合は必ず別の数字で置き換えることができます。
FrequencyEncoding
CountEncodingでは出現回数でエンコードしましたが、FrequencyEncodingでは出現頻度でエンコードします。
結果が自動的に0から1の間に収まる点で扱いやすいです。
例えばSexであれば、男性は577 / (577 + 314)で0.647...、女性は 314 / (577 + 314)で0.352...でエンコードされます。
trans = dl.FrequencyEncoding()
trans.fit_transform(X)

CountEncoding同様同じ出現回数のカテゴリーが区別できないという性質は残りますが、外れ値に弱いという点は改善されています。
尚、RankedFrequencyEncodingはRankedCountEncodingと同じ結果になるため用意していません。
TargetMeanEncoding
Kaggleなどで名前が有名になった手法ですが、考え方自体はデータ分析では基礎の基礎です。
具体的にはカテゴリ変数を、カテゴリー毎の目的変数の平均値で置き換えるものです。
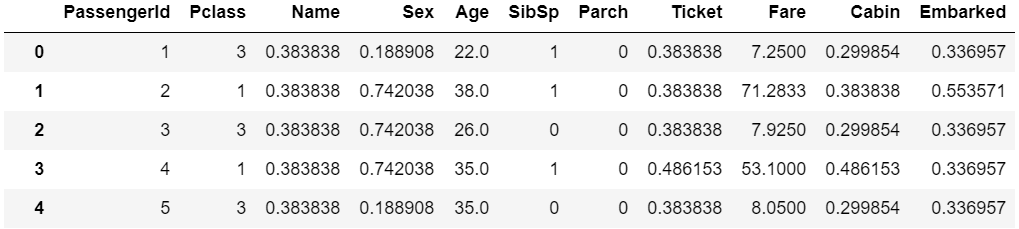
目的変数が乗客の生死なので、例えばSexなら男女別の生存率で置き換えるといった具合になります。
ただし、目的変数の平均という本来であれば予測する対象の情報を用いるため、データ数が少ない場合はエンコードした値と目的変数が対応してしまい容易にリークを起こします。
DataLinerの実装ではベイズのように目的変数全体の平均を各カテゴリーの事前確率として採用し、データ数で重みをつけて変換するようになっています。
trans = dl.TargetMeanEncoding()
trans.fit_transform(X, y)
RankedTargetMeanEncoding
TargetMeanEncodingの結果をランキング付けして、その順位で置き換えるものです。
例えば生存率1位が女性、2位が男性であれば女性は1、男性は2で置き換えるといった具合です。
事前確率を採用するTargetMeanEncodingではあるカテゴリの数がデータ全体の数に対して少ないとき、違うカテゴリにも関わらずほとんど似たような(=事前確率に近い)数字でエンコードされてしまいます。
RankedTargetMeanEncodingであれば、それらを明確に違うものとしてエンコードしてくれます。
trans = dl.RankedTargetMeanEncoding()
trans.fit_transform(X, y)
おわりに
ということで今回はDataLinerのEncoding系の項目を紹介しました。
次は変換系を紹介したいと思います。
Datalinerリリース記事: https://qiita.com/shallowdf20/items/36727c9a18f5be365b37
GitHub: https://github.com/shallowdf20/dataliner
PyPI: https://pypi.org/project/dataliner/