はじめに
データ前処理を簡単に行えるライブラリDataLinerを、Kaggleでも有名なTitanicデータで色々試してみたいと思います。(データ:https://www.kaggle.com/c/titanic/data)
ちなみに、KaggleのTitanicデータではいくつか特徴量が削除されており、ここのデータを見ると他にもいくつか特徴量があるようです。(データ:https://www.openml.org/d/40945)
それでは、早速やっていきましょう。今回はDropXX系の紹介になります。最後にPipelineを使っての処理も紹介します。
インストール
! pip install -U dataliner
Titanicのデータ
まずはtrain.csvを読み込みます。
import pandas as pd
import dataliner as dl
df = pd.read_csv('train.csv')
target_col = 'Survived'
X = df.drop(target_col, axis=1)
y = df[target_col]
読み込んだtrainデータはこんな感じです。

DropColumns
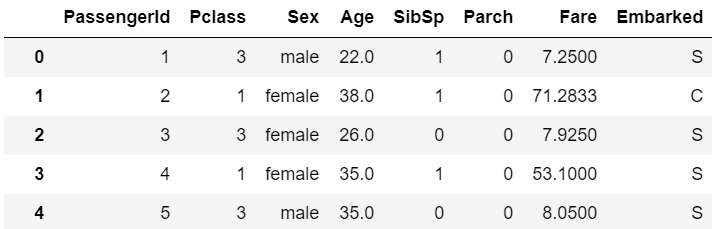
指定した列を単純に削除します。例えば乗客番号を表すPassengerIdはモデリングにおいてあまり役に立たないので削除してみます。
trans = dl.DropColumns('PassengerId')
trans.fit_transform(X)

PassengerIdが削除されました。リストを渡して複数を同時に削除することも可能です。
例えばtrainデータとtestデータをくっつけてdf.dropで普通に削除することもできますが、上記のやり方であればミスが起きにくく、何をしているかが明確となります。例えば、テストデータへは以下のように適用できます。
X_test = pd.read_csv('test.csv')
trans.transform(X_test)

また、後述しますがscikit-learnのパイプラインと組み合わせることでデータ前処理・特徴量エンジニアリングの流れを効率的かつ抽象的に組み立てることができるようになります。
DropNoVariance
分散がない、列の中で単一の値しか存在しない特徴量を削除します。Titanicデータにはそのような特徴量がないので、まず作ってみます。
X['Test_Feature'] = 1

では、DropNoVarianceをかけてみます。
trans = dl.DropNoVariance()
trans.fit_transform(X)

といった具合です。数値列、カテゴリ列どちらに対しても使用可能で、複数列ある場合はそのすべてを削除します。
DropHighCardinality
カテゴリ数が非常に多い列を削除します。カテゴリ数が多すぎると適切にEncodingするのが大変で何かと苦労するので、初動ではone-pass通すためにサクッと落としてしまうのも手です。(Kaggleなどではそこから情報を抽出してグループ化するなどしてカーディナリティを下げに行きます)
trans = dl.DropHighCardinality()
trans.fit_transform(X)
必要であれば、どの列が消されたかは以下のように確認することもできます。
trans.drop_columns
array(['Name', 'Ticket', 'Cabin'], dtype='<U6')
カテゴリ数が非常に多い特徴量が削除されていることがわかります。
DropLowAUC
単一の特徴量と目的変数とのロジスティック回帰を行い、その結果AUCが特定のしきい値を下回った特徴量を削除します。特徴量選択に使うことができます。
カテゴリ変数の場合は内部的にダミー変数化された上でロジスティック回帰を行います。
通常0.55程度を推奨しますが、今回はわかりやすさのために高めのしきい値を設定します。
trans = dl.DropLowAUC(threshold=0.65)
trans.fit_transform(X, y)

残ったのはPclass、Sex、FareとどれもTitanicデータでは目的変数との強い相関がわかっているものばかりとなりました。
OneHotEncodingなどを行い次元数が爆発した後に使うと効果的です。
DropHighCorrelation
ピアソンの相関係数をもとに、相関が高い特徴量同士を洗い出した上で、目的変数との相関がより高い特徴量のみを残して他を削除します。
内容が全く同じ特徴量が複数あった場合もこちらで同時に削除してくれます。
ブースティング木などではそこまで気にしなくても何とかなりますが、線形回帰などを行う場合は正則化していても削除しておくべきでしょう。
trans = dl.DropHighCorrelation(threshold=0.5)
trans.fit_transform(X, y)

Fareが消されていますね。
Pipelineで使う
ここからがこの方式で前処理を行う最大の利点です。今回紹介した5種類のDropをパイプラインで処理してみます。
from sklearn.pipeline import make_pipeline
process = make_pipeline(
dl.DropColumns('PassengerId'),
dl.DropNoVariance(),
dl.DropHighCardinality(),
dl.DropLowAUC(threshold=0.65),
dl.DropHighCorrelation(),
)
process.fit_transform(X, y)
上記で紹介した処理がすべて行われ、以下のような結果となりました。

これを、テストデータに対して適用してみます。
X_test = pd.read_csv('test.csv')
process.transform(X_test)
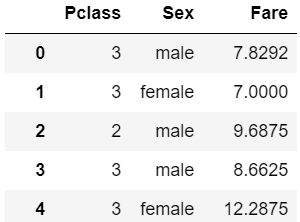
学習時と同様の処理をあっという間にテストデータにもかけることができました。
あとはPickleとしてでも保存しておけば、次使う時でもサービスのデプロイでもバッチリですね!
おわりに
ということで今回はDataLinerのDrop系の項目を紹介しました。
次はEncoding系を紹介したいと思います。
Datalinerリリース記事: https://qiita.com/shallowdf20/items/36727c9a18f5be365b37
GitHub: https://github.com/shallowdf20/dataliner
PyPI: https://pypi.org/project/dataliner/