はじめに
はじめまして、データサイエンティストのshakeです。
最近ChatGPTなどの生成AIがすごい話題になってますね。まるで本物の人間が書いたような文を書き起こしてくれるため、私が初めてChatGPTを使った時は、ものすごく興奮したのを覚えています。
そんな生成AIですが、生活がより便利になる期待だけではなく、犯罪などに悪用されるリスクが指摘されています。
そこで今回、自学も兼ねてBERTモデルを使用したフェイクニュース(テキスト)判別モデルを作成し、ChatGPTに作らせたフェイクニュースがどれだけ精巧なのか検証してみました。
なお、NLP分野ではまだまだ素人ですので、記事の内容に誤りがあればご指摘いただけると幸いです。
導入
BERTとは
BERT(Bidirectional Encoder Representations from Transformers)とは、2018年10月にGoogleのJacob Devlinらより発表された自然言語処理モデルです。学習済みモデルは公開されており、誰でも利用することができます。学習済みモデルに対してファインチューニングを行うことで、翻訳、感情分析(ポジネガ分類)、文書のカテゴライズなど、様々な自然言語処理モデルを簡単に作成することができるという優れモノです。
今回は理論やモデル構造などの解説については省略します。詳しくは原著論文をご参照ください。日本語の解説記事などと合わせて読むと理解しやすいと思います。
参考になった解説記事:自然言語処理の王様「BERT」の論文を徹底解説
原著論文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
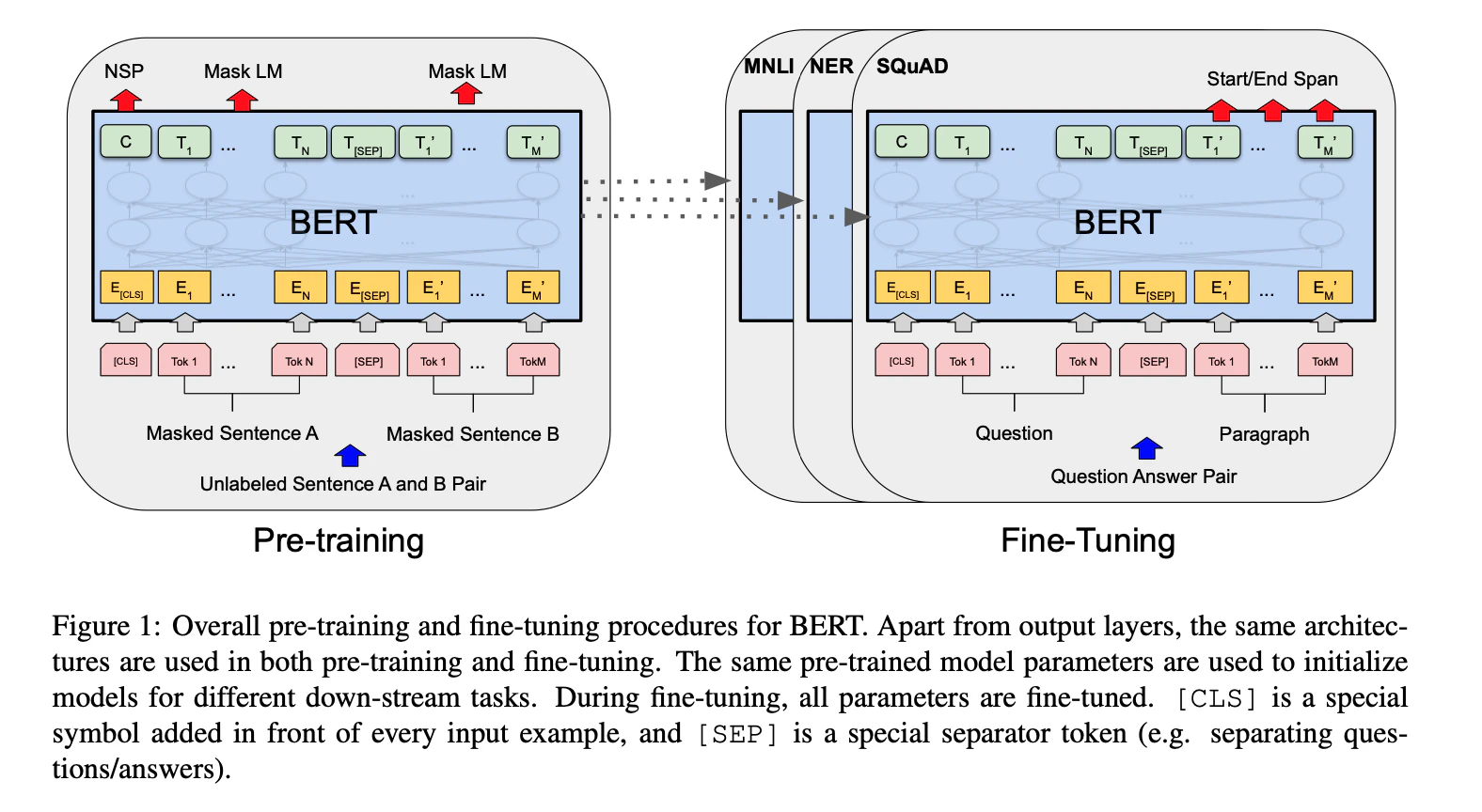
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
ちなみにGoogleが最近公開したBardはPaLM2という大規模言語モデル(LLM)を使用しており、BERTとは関係ないので注意しましょう。
学習データ
kaggleのFake and real news datasetからFake.csv(フェイクニュースデータ)とTrue.csv(本物のニュースデータ)をダウンロードし、学習・検証・テストデータに分けて使用しました。それぞれ17903個と20826個の記事データが格納されています。
追加テストデータ
今回の本命です。ChatGPTに生成させたフェイクニュース記事と、信頼できるニュースサイトの記事(BCCなど)、人の手によって書かれたフェイクニュースのデータを判別モデルに入力して結果を確認します。
環境
- Google Colab
- PyTorch:2.0.1+cu118
- transformers:4.29.2
データ前処理(Preprocessing Data)
データの前処理はこちらの記事を参考に進めました。
まず、記事データをダウンロードし、それぞれdf_fakeとdf_trueに格納します。そして、真偽のラベル付けを行いデータを1つに統合します。
import numpy as np
import pandas as pd
df_fake = pd.read_csv("Fake.csvのパス")
df_true = pd.read_csv("True.csvのパス")
df_true['category'] = "Real" #カテゴリーを追加
df_fake['category'] = "Fake" #カテゴリーを追加
df = pd.concat([df_true, df_fake]).reset_index(drop = True) #2つのデータセットを統合
ここで、データの中身を見てみます。
df.head()
記事のタイトルや、公開日などが入っていますが、今回は使いません。
'text'と'category'のコラム以外はいらないので削っちゃいます。
df = df[['category','text']]
特殊文字列を整形する関数
次に、記事に絵文字やURLが含まれると学習精度が落ちるので、それらを取り除いたり変形する関数を定義します。
import re
import string
def remove_URL(text):
url = re.compile('https?://\S+')
return url.sub(' httpsmark ', text)
def remove_html(text):
html = re.compile('<.*?>')
return html.sub('', text)
def remove_atsymbol(text):
name = re.compile(r'@\S+')
return name.sub(r' atsymbol ', text)
def remove_hashtag(text):
hashtag = re.compile(r'#')
return hashtag.sub(r' hashtag ', text)
def remove_exclamation(text):
exclamation = re.compile(r'!')
return exclamation.sub(r' exclamation ', text)
def remove_question(text):
question = re.compile(r'?')
return question.sub(r' question ', text)
def remove_punc(text):
return text.translate(str.maketrans('','',string.punctuation))
def remove_number(text):
number = re.compile(r'\d+')
return number.sub(r' number ', text)
def remove_emoji(string):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002500-\U00002BEF" # chinese char
u"\U00002702-\U000027B0"
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
u"\U0001f926-\U0001f937"
u"\U00010000-\U0010ffff"
u"\u2640-\u2642"
u"\u2600-\u2B55"
u"\u200d"
u"\u23cf"
u"\u23e9"
u"\u231a"
u"\ufe0f" # dingbats
u"\u3030"
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r' emoji ', string)
データに変形を適用します。
df['text'] = df['text'].str.lower() #すべて小文字にする
df['text'] = df['text'].apply(lambda text: remove_URL(text))
df['text'] = df['text'].apply(lambda text: remove_html(text))
df['text'] = df['text'].apply(lambda text: remove_atsymbol(text))
df['text'] = df['text'].apply(lambda text: remove_hashtag(text))
df['text'] = df['text'].apply(lambda text: remove_exclamation(text))
df['text'] = df['text'].apply(lambda text: remove_punc(text))
df['text'] = df['text'].apply(lambda text: remove_number(text))
df['text'] = df['text'].apply(lambda text: remove_emoji(text))
BERTによる分類モデルの実装
それではいよいよBERTによる分類モデルを実装していきます。実装方法は、Text Classification with BERT in PyTorchという記事がとても参考になりました。
イメージとしては、以下の図のように、学習済みBERTモデルの後ろに分類器classifier のNN(ニューラルネットワーク)をくっつけてあげて、ファインチューニングを行う流れになります。図は5種類のカテゴリ分類タスクですが、今回は Real or Fake の2値分類なので、図中のclassifier の先がRealとFakeの2種類のみになるということです。
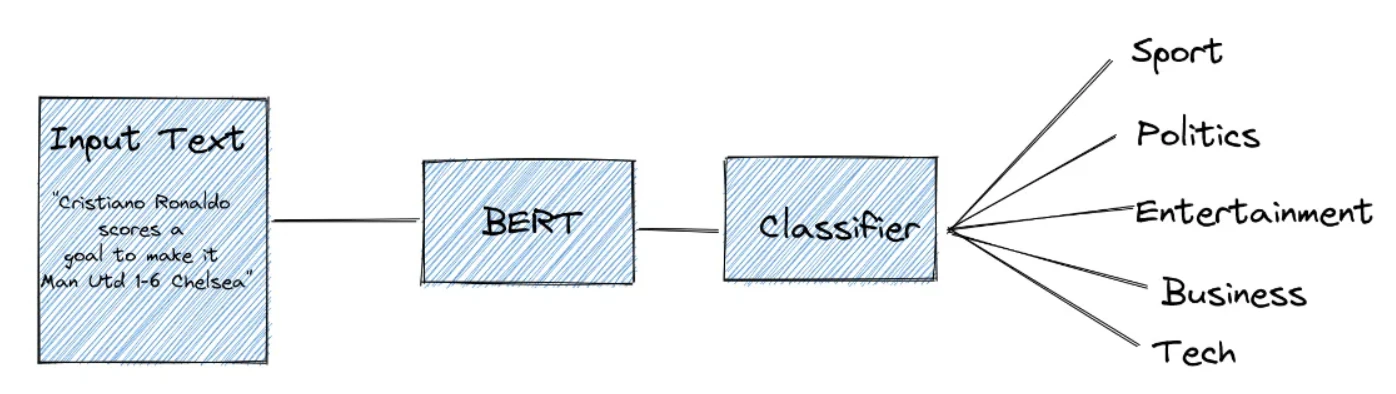
Text Classification with BERT in PyTorch, Ruben Winastwan, Nov 10, 2021
学習済みBERTモデルですが、公式のやつはTensorFlowしか対応してません。PyTorchで実装したかったので、今回はHuggingfaceのライブラリtransformersを使用します。
※ transformersのインストールは必ず仮想環境で行ってください。かなり多くのパッケージに依存しているみたいなので、実環境でインストールするとトラブルの元になるかも・・・
!pip install transformers #仮想環境でインストールすること!
BERTにはbaseとlargeという大きさに応じた2つのモデルがありますが、今回は小さいほうのbaseモデルを使用します。
BERTモデルに長文テキストをそのまま入力することはできません、そのため、テキストデータに前処理を行い変形(tokenize)する必要があります。具体的には、下図のように変形します。
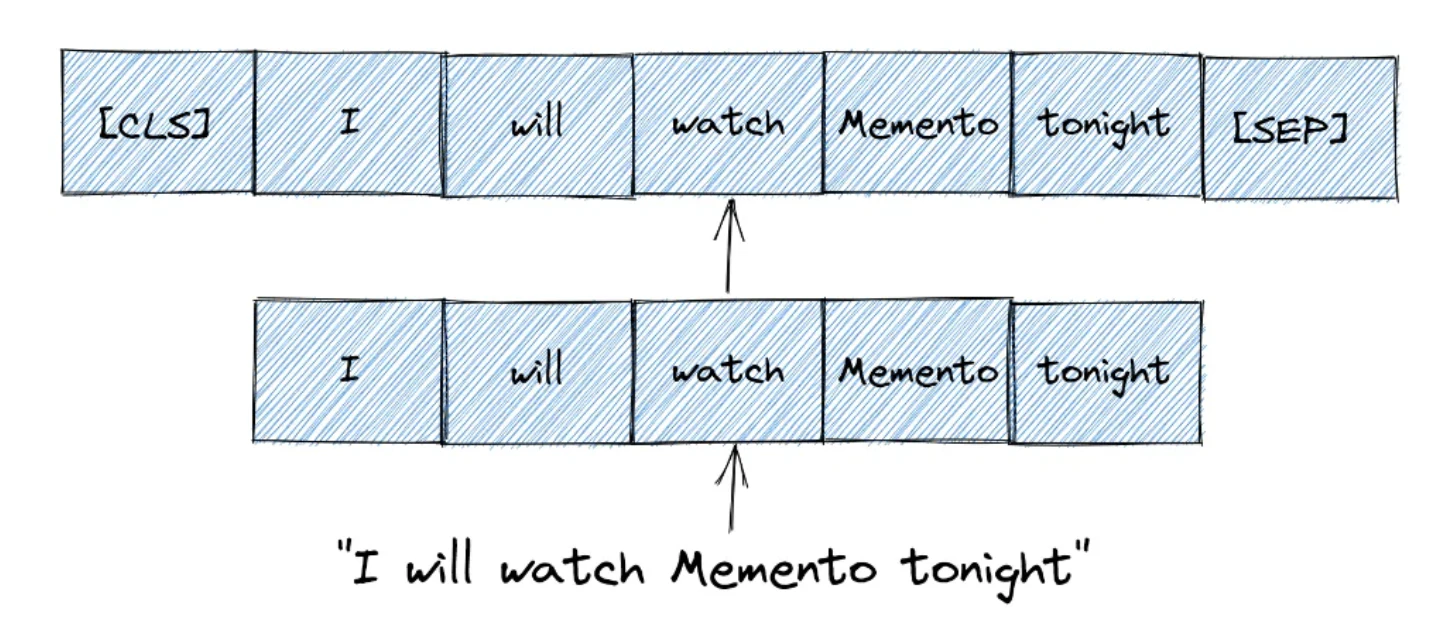
Text Classification with BERT in PyTorch, Ruben Winastwan, Nov 10, 2021
ここで、[CLS]は、文の開始を意味する分類トークンです。一方[SEP]は、文の末尾や分かれ目を表すトークンを表しています。このように、文章を単語ごとに分割し、文の開始点と終了点を示すトークンをそれぞれ挿入することで、BERTにデータを入力することができるようになります。
では、この前処理を行う関数を定義します。
import torch
import numpy as np
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
labels = {'Fake':0,
'Real':1,
}
class Dataset(torch.utils.data.Dataset):
def __init__(self, df):
self.labels = [labels[label] for label in df['category']]
self.texts = [tokenizer(text,
padding='max_length', max_length = 512, truncation=True,
return_tensors="pt") for text in df['text']]
def classes(self):
return self.labels
def __len__(self):
return len(self.labels)
def get_batch_labels(self, idx):
# Fetch a batch of labels
return np.array(self.labels[idx])
def get_batch_texts(self, idx):
# Fetch a batch of inputs
return self.texts[idx]
def __getitem__(self, idx):
batch_texts = self.get_batch_texts(idx)
batch_y = self.get_batch_labels(idx)
return batch_texts, batch_y
次に、データを学習・検証・テスト用に分割します。比率は 80:10:10 です。
df_train, df_val, df_test = np.split(df.sample(frac=1, random_state=42),
[int(.8*len(df)), int(.9*len(df))])
モデル定義
from torch import nn
from transformers import BertModel
class BertClassifier(nn.Module):
def __init__(self, dropout=0.5):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-cased')
self.dropout = nn.Dropout(dropout)
self.linear = nn.Linear(768, len(labels)) # label数に応じて出力先のノード数を変える
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids= input_id, attention_mask=mask,return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer
上記のコードからわかるように、BERT モデルは2つの変数を出力します:
- 最初の変数は、上記のコードで _ と名付けたもので、文章内の全トークンの埋め込みベクトルが格納されています。
- pooled_outputと名付けた2番目の変数は、[CLS]トークンの埋め込みベクトルを含んでいます。テキスト分類のタスクでは、この埋め込みベクトルを分類器(NN)の入力として使用すれば十分です。
次に、pooled_outputを活性化関数ReLUを持つ線形層に渡します。線形層の出力には、サイズ2のベクトルがあり、それが入力データの分類結果(Real or Fake)に対応します。これが先程の図でいうclassifierになるということです。
学習
PyTorchではよく見る形ですね。
最適化関数にはAdam、損失関数にはCrrossEntropyを使用します。
from torch.optim import Adam
from tqdm import tqdm
def train(model, train_data, val_data, learning_rate, epochs):
train, val = Dataset(train_data), Dataset(val_data)
train_dataloader = torch.utils.data.DataLoader(train, batch_size=2, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr= learning_rate)
if use_cuda:
model = model.cuda()
criterion = criterion.cuda()
for epoch_num in range(epochs):
total_acc_train = 0
total_loss_train = 0
for train_input, train_label in tqdm(train_dataloader):
train_label = train_label.to(device)
mask = train_input['attention_mask'].to(device)
input_id = train_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, train_label.long())
total_loss_train += batch_loss.item()
acc = (output.argmax(dim=1) == train_label).sum().item()
total_acc_train += acc
model.zero_grad()
batch_loss.backward()
optimizer.step()
total_acc_val = 0
total_loss_val = 0
with torch.no_grad():
for val_input, val_label in val_dataloader:
val_label = val_label.to(device)
mask = val_input['attention_mask'].to(device)
input_id = val_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, val_label.long())
total_loss_val += batch_loss.item()
acc = (output.argmax(dim=1) == val_label).sum().item()
total_acc_val += acc
print(
f'Epochs: {epoch_num + 1} | Train Loss: {total_loss_train / len(train_data): .3f} \
| Train Accuracy: {total_acc_train / len(train_data): .3f} \
| Val Loss: {total_loss_val / len(val_data): .3f} \
| Val Accuracy: {total_acc_val / len(val_data): .3f}')
実際に学習させてみます。ColabのGPU(Tesla T4)で1エポックあたり1時間かかりました。
EPOCHS = 4
model = BertClassifier()
LR = 1e-6
train(model, df_train, df_val, LR, EPOCHS)
モデル評価
テストデータを学習済みモデルに入力し、判別の正答率を求める関数を作成します。
def evaluate(model, test_data):
test = Dataset(test_data)
test_dataloader = torch.utils.data.DataLoader(test, batch_size=2)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
if use_cuda:
model = model.cuda()
total_acc_test = 0
with torch.no_grad():
for test_input, test_label in test_dataloader:
test_label = test_label.to(device)
mask = test_input['attention_mask'].to(device)
input_id = test_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
total_acc_test += acc
print(f'Test Accuracy: {total_acc_test / len(test_data): .3f}')
実行してみます。
evaluate(model, df_test)
Test Accuracy: 1.000
テストデータをすべて正しく判別することができたみたいです!ちなみに、テストデータの内訳はFakeが2349個、Realが2141個となります。
追加テストデータで検証
Fake and real news dataset だけではなく、オリジナルのテストデータでも検証してみます。
今回は、以下の3種類のデータを用意しました。
-
Real:大手ニュースサイトの記事:BBC, CNN, FoxNews -
Fake:ChatGPTに生成させたフェイクニュース記事 -
Fake:人の手によって書かれたフェイクニュース
3.の「人の手によって書かれたフェイクニュース」はWikipediaの List of fake news websites で報告されているフェイクニュースサイトから、記事がそれなりに長いものを収集しました。また、学習に利用したデータセットはpolitics(政治)の記事が多いため、テストデータでも政治系の記事を多めに収集しています。
※スクレイピングはせず、ちまちま1つずつ記事を集めたので46個しかデータないです
original_path = "エクセルデータのパス"
df_original = pd.read_excel(original_path, index_col=None)
一部のデータを見てみます。
df_original.head() #はじめの5個

df_original.tail() #最後の5個

df_original_test = df_original[['category','text']]
オリジナルのテストデータは数が少ないので、結果を1つずつ可視化できるように評価関数を改造します。
# 結果を可視化するための評価関数
def evaluate_visualize(model, test_data):
test = Dataset(test_data)
test_dataloader = torch.utils.data.DataLoader(test, batch_size=1)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
if use_cuda:
model = model.cuda()
total_acc_test = 0
with torch.no_grad():
cnt = 0
for test_input, test_label in test_dataloader:
test_label = test_label.to(device)
mask = test_input['attention_mask'].to(device)
input_id = test_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
# print("Label:{} Result:{}".format((test_label == acc)[0].item(), acc))
print("Source:{} Label:{} Prediction:{}".format(df_original['source'][cnt],test_label[0].item(), output.argmax(dim=1)[0].item()))
total_acc_test += acc
cnt += 1
print(f'Test Accuracy: {total_acc_test / len(test_data): .3f}')
結果を出力します。1はReal、0はFakeを表しています。
evaluate_visualize(model, df_original_test)
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:BBC Label:1 Prediction:1
Source:CNN Label:1 Prediction:1
Source:CNN Label:1 Prediction:1
Source:CNN Label:1 Prediction:1
Source:CNN Label:1 Prediction:1
Source:CNN Label:1 Prediction:1
Source:CNN Label:1 Prediction:1
Source:FoxNews Label:1 Prediction:1
Source:FoxNews Label:1 Prediction:1
Source:FoxNews Label:1 Prediction:0
Source:FoxNews Label:1 Prediction:1
Source:FoxNews Label:1 Prediction:1
Source:FoxNews Label:1 Prediction:1
Source:ChatGPT Label:0 Prediction:0
Source:ChatGPT Label:0 Prediction:1
Source:ChatGPT Label:0 Prediction:1
Source:ChatGPT Label:0 Prediction:1
Source:ChatGPT Label:0 Prediction:1
Source:ChatGPT Label:0 Prediction:0
Source:ChatGPT Label:0 Prediction:1
Source:ChatGPT Label:0 Prediction:1
Source:ChatGPT Label:0 Prediction:1
Source:ChatGPT Label:0 Prediction:0
Source:ChatGPT Label:0 Prediction:0
Source:LibertyWriters Label:0 Prediction:0
Source:LibertyWriters Label:0 Prediction:0
Source:LibertyWriters Label:0 Prediction:1
Source:BeforeItsNews Label:0 Prediction:0
Source:InfoWars Label:0 Prediction:1
Source:InfoWars Label:0 Prediction:0
Source:InfoWars Label:0 Prediction:0
Source:Palmer Report Label:0 Prediction:0
Source:WorldNetDaily Label:0 Prediction:0
Source:WorldNetDaily Label:0 Prediction:1
Source:WorldNetDaily Label:0 Prediction:0
Source:WorldNetDaily Label:0 Prediction:0
Test Accuracy: 0.761
混合行列で表すと以下のようになります。
==混合行列== Predicted
Negative Positive
Actual Negative | 13 | 10
Positive | 1 | 22
全体の判別精度は76.1%となりました。本物の記事はほぼ間違いなく判別できるのに対し、フェイク記事(特にChatGPTの記事)の判別精度が低く、全体精度の足を引っ張っていますね。以下、データセットごとの感想です。
-
Real:大手ニュースサイトの記事:BBC, CNN, FoxNews
BBCの記事はすべて真と判別されました。やはり、天下のBBCはAIにとって信頼できる記事を書くようです。データは少ないですが、左派のCNNや右派のFoxといった大手メディアも信頼できそうです。 -
Fake:ChatGPTに生成させたフェイクニュース記事
1/3ほどしか、Fakeと見抜くことができませんでした。実際に自分の目でも記事を見たが、文章は実にそれらしかったです。内容も明らかにおかしいと思う点は少なく、とても良くできた記事でした。しかし、なんとなくふわふわしており、中身が無いような印象を受けました。これは、具体的な数字が少ないことが原因だと思われます。
※ 後日、ChatGPTに対するプロンプト文に「根拠となる数値データを含めてください」という指示を追加してフェイクニュースを生成してもらいました。すると、文章に具体的な数値(もちろん偽データ)が含まれるようになりました!どうやら私のプロンプトエンジニア力が足りなかったみたいですね・・・ -
Fake:人の手によって書かれたフェイクニュース
ChatGPTの記事に比べると、正しくFakeと判別される確率が高いようです。いくつかフェイクニュースサイトを見ましたが、サイトを個人が運営していたり、運営会社の規模が小さかったりするためか、記事の質が低いものが多かったです。サイトによっては、動画やツイートの引用記事ばかりでテキストデータが少ないものも散見されました。
まとめ
本記事では、BERTモデルを使用したフェイクニュース(テキスト)判別モデルを作成し、ChatGPTに生成させた記事がどれだけ精巧なのか検証しました。
結果は、人の手より、ChatGPTのほうが精巧なフェイクニュースを作ることができる可能性が示唆されました。今回使用したChatGPTのバージョンはGPT3.5なので、GPT4だとさらに完成度の高いフェイクニュースを生成できるでしょう。
また、BERTの入力含めすべて英語で検証を行いましたが、日本語対応の学習済みBERTモデルも存在します。気になる人はそっちも試してみてください。判別の根拠の可視化とかもできるみたいなので、時間があれば試してみたいですね。
フェイクニュースは時に人々の判断を狂わせ、トラブルを招きます。
生成AIの進化に伴ってフェイクコンテンツ(画像、音声、テキストなど)は量・質共にどんどん増していくため、その危険性は私たち一般人も無視できません。私たちが、その事実を認識し、情報のソースを調べたり、複数の媒体から多角的に情報を得ることで、能動的に信頼できる情報を得る努力が重要です。日本としても、アメリカのようにファクトチェック団体の発展にもっと注力したほうがいいのではないかと思います。
以上、読んでいただきありがとうございました。