はじめに
この記事は「【pix2pix】AIの力で人に勝手にポーズを取らせてみた【OpenPose】」の続きです。
上記の記事では人に任意のポーズを取らせることが可能になりました。
この記事ではそこから更に発展させて動画を作成することを目指します。
前回の技術で動画作成
前回の記事でも静止画を大量に並べて動画も作っていました。(下記)

遠目で見るとそれなりに良い感じに見えるのですが、ちゃんと画像を確認すると下図のような腕や足が消えてしまったりしていました。

また、背景がコロコロ切り替わってしまうのも気になります。
諸問題への対処
仮説として人と背景を一緒に生成しようとするから学習の難易度が高くなってしまっているのではないかというのがあります。
その為、背景と人物を切り分けることを考えます。
人と背景の分離
人と背景を切り分けるためにEnd-to-end Recovery of Human Shape and PoseのHuman Mesh Recoveryを使用します。例を以下に示します。

これを用いると写真から3Dmeshを作成することができます。出力画像は作成した3Dmeshを重ねて描画しています。
作成した3Dmeshの位置に該当するピクセルだけを切り抜くと以下のようになります。
※顔部分はプライバシー保護の観点から黒塗り、3Dmeshはちょっと情報が多くなるようにいろいろつけてます
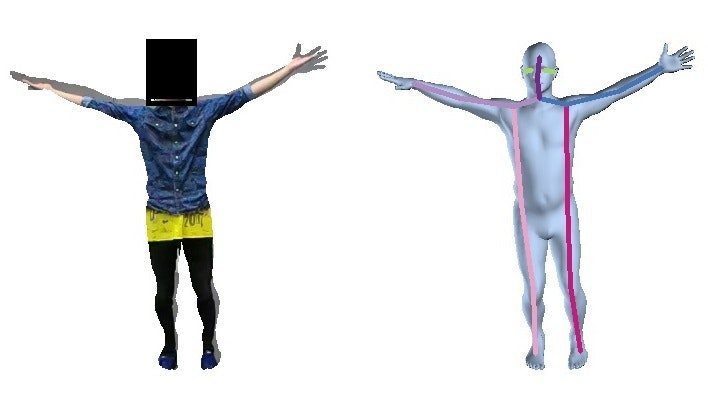
この手法は既にある3Dmeshを動かしているため、手足が無くなることはありません。
これをpix2pixで学習させることで白塗のところは描画せず、それ以外の所には何かしらが描画され、シルエット的には手足が消滅しているように見えないはずです。
更に、3Dmeshは正面、背後なども判断できるというメリットもあります。今回はそういったダンスを用意できなかったので見せられませんが…
処理の流れ
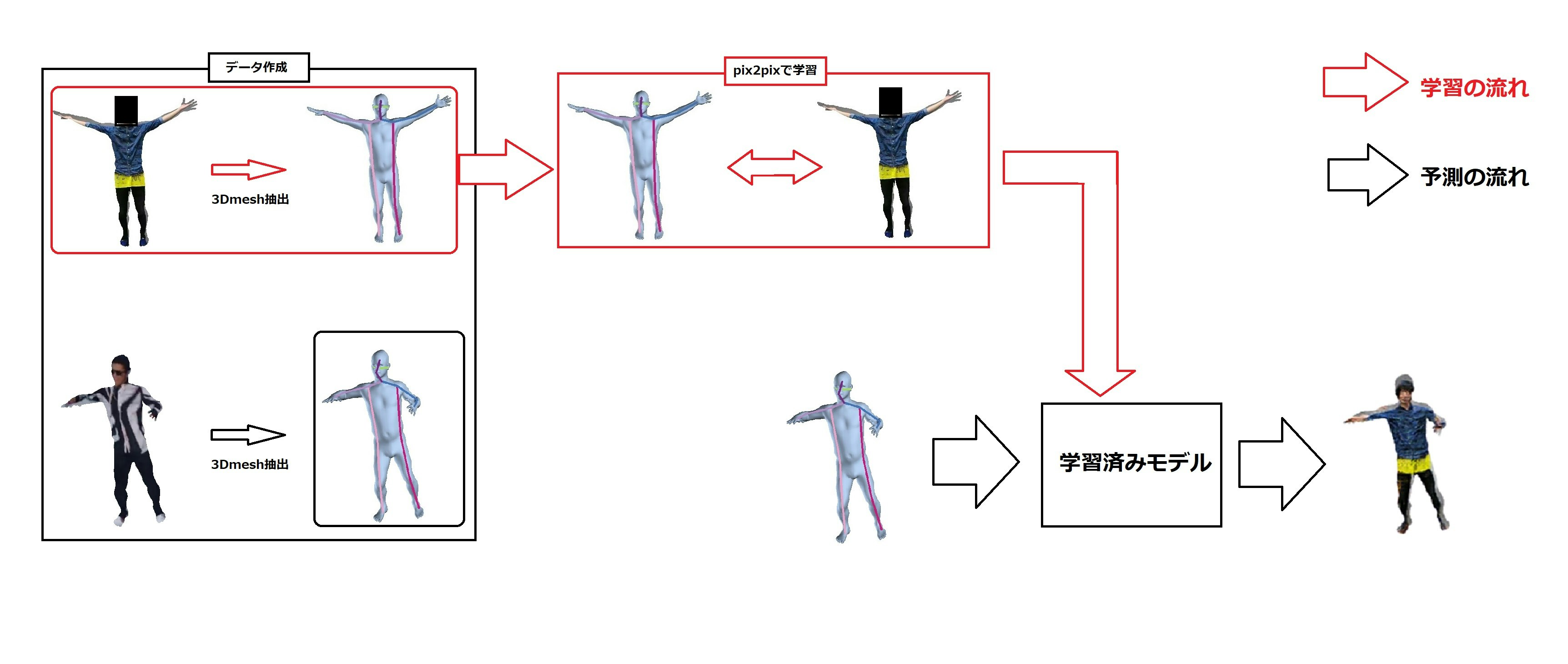
今回の方法で動画作成
人を踊らせる奴更新した pic.twitter.com/OzNeU3LjRe
— 2019年5月11日
終わりに
今回の方法で背景がコロコロ切り替わることがなく(削除したからね)、「シルエット上は」手足が消えなくなることもなくなりました。
生成された人物も鮮明になったことから背景も生成するよりは人物だけを生成したほうがよりよくなると言えそうです。
この方法はHuman Mesh Recoveryの人物の推定精度に依存しているのであまりスマートな解決策とは言えません。もっとスマートなやり方があったら教えてください(12Gメモリ以上のGPUを使わない方法に限る)
余談
最初はeverybody dance nowという論文の方法を使って踊らせてみよう!と始めました。実はこれ結構な茨の道で要求スペックが最低でもメモリ12G、もしくは24GのGPU。これに加えて学習データ14万枚でした。12Gはあくまでも最低ラインでありまともに動かそうとすると24Gは欲しいです。ほんと。。。
どれぐらいえげつないか説明しましょう。
ちなみに12ギガメモリのGPUですが買おうとすると18万円ほどします(https://www.amazon.co.jp/EVGA-%E3%82%B0%E3%83%A9%E3%83%95%E3%82%A3%E3%83%83%E3%82%AF%E3%82%AB%E3%83%BC%E3%83%89-Superclocked-GDDR5-768bit-%EF%BC%8812G-P4-3992-KR%EF%BC%89/dp/B00KLTHMH4)
awsで賄おうとするとp3.8xlargeです(1時間 $12.24)
私は18万もさすがに出せないので一度p3.8xlargeで試しに動かしてみました。この時に用いた学習データは256*256の画像を1018枚でした。
これで1エポック4分程でした。そして200エポックがデフォルトなので800分・・・学習データの数と1エポックの時間は比例するのでこれを14万枚やろうとすると地獄です。ちょっとお試しでやってみようとかできません。
今回の物は6GメモリのGPUで動かしているので上の物に比べればだいぶお得だと思います。
もっと安くもっときれいに作れるようになりたいなぁ。