laravelの事を聴いたら大体の事を答えてくれる
larvel先生のAiを作りたくなったので、
強化学習用のデータセットを作る為にqiitaを利用させて貰う。
こちらの記事を参考にさせていただきました。
ありがとうございます。
Apiのアクセストークンを作る
アクセストークンの発行ページに移動する
記事一覧を取得したいだけなので、
- アクセストークンの説明
- スコープをread_qiita
にして、
「発行する」ボタンをクリックする

APIが発行できた。

赤く囲んでる部分がアクセストークンになる。
次にpythonでApiを叩く
pythonのrequestsライブラリを利用するので、インストールする
インストールが完了したので、以下のようなコードでとりあえず1ページで100件のデータを取得する。
queryへの検索条件の入れ方はここで見た。
pip install requests
import requests
url = "https://qiita.com/api/v2/items"
params = {'query': 'tag:laravel', 'page': '1','per_page':'100'}
headers = {'Authorization': 'Bearer アクセストークン'}
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
print(data)
# データを加工するなどの処理を行う
else:
print("Error: ", response.status_code)
実行すると、こんな感じでばさ~と記事が取れた!

これだと意味が解らないので
sqliteにでも入れようか・・・
たぶん正しくはpandasとかでCSVに吐き出すのが正解だけど、
今後データ加工とかをする事になるので、sqliteの方が使いやすい気がする。
mysqlでも良いけど、気軽に使えるのがsqliteジャン?
Sqliteを利用する。
WindowsでsqlliteのDBを作成する
で下の画像のヤツをダウンロードしてインストールした。

ダウンロードしたsqlite-tools-win-x64-3440000.zipは解凍しておく

shiftを押しながら右クリックでパスをコピーをクリックして
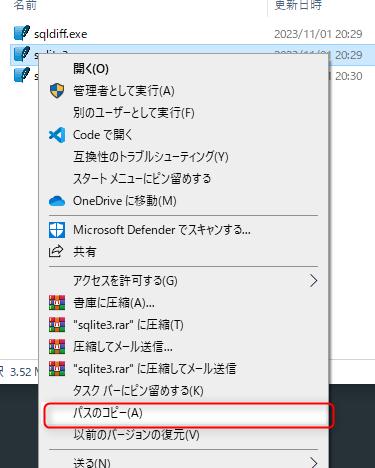
PowerShellに張り付け
前後に"が入っちゃうから消してEnterで実行

PowerShellが起動した。
今回はE:\git\getQiitaPostにlaravelposts.dbを作りたいので、

出来た。

DBeaverでテーブルを作る
DBeaverでさっき作ったlaravelposts.dbに接続する
接続方法はここが解りやすかった。
Dbeaverのテーブルから、「あたらしく作る 表」をクリックする


こんな感じに表示されるのでカラムを作って行く。
ちなみにDB構造はこんな感じで考えている。
| カラム名 | 型 | 制約 |
|---|---|---|
| id | int | PRIMARY KEY AUTOINCREMENT |
| title | text | NOT NULL |
| content | text | NOT NULL |
| url | text | NOT NULL |
テーブル名を入れる
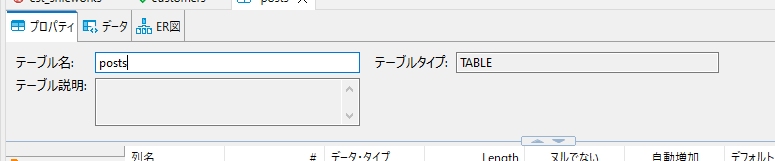
カラムの作り方は下の図の当たりを右クリックから、
「新しくつくる カラム」をクリックすると、カラム作成画面が表示される


こんな感じ

画面右下の「Save」ボタンをクリックで保存
SQLプレビューが表示されるので、「持続する」をクリック

出来た

Pythonで記事をDBに保存
後はpythonで取得した記事情報をこのDBにぶち込めばOK
pythonのコードはこんな感じにした。
import requests
import sqlite3
con = sqlite3.connect('./laravelposts.db')
cur = con.cursor()
url = "https://qiita.com/api/v2/items"
params = {'query': 'tag:laravel', 'page': '1','per_page':'100'}
headers = {'Authorization': 'Bearer アクセストークン'}
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
for post in data:
body = post["rendered_body"].replace("'", "''").replace('"', '""')
body = body.replace('\n', '').replace('\r', '').replace('\t', '')
body = body.replace('\b', '').replace('\f', '')
body = body.replace('(', "'<").replace(')', "'>")
title = post["title"].replace("'", "''").replace('"', '""')
title = title.replace('\n', '').replace('\r', '').replace('\t', '')
title = title.replace('\b', '').replace('\f', '')
title = title.replace('(', "'(").replace(')', "')")
sql = F' ("{title}", "{body}","{post["url"]}") '
print(sql)
cur.execute(F'INSERT INTO posts (title,content,url) values {sql}')
else:
print("Error: ", response.status_code)
con.commit()
print('処理が完了しました。')
OK保存できた


これを永遠ループで全部の記事をDBに保存しちゃえば良いんだね!
と思ったけど・・・
laravelのタグが付いている記事は13885件あるから、
1回100件取れるとして、13885/100=138.85なので、139回回せばいいなね。
でも、apiでpageパラメーターは100が最大値だから、39ページ3900件は保存できない。
作成日時の降順で取得できるから、あわせて、最後のレコードの日付を表示して、
それ以降で2回回さないといけないか・・・
単純にとれる最終の記事の公開日時を調べる
という事でとりあえず、100回目の最後の記事の日付を取得する処理を書く。
import requests
import sqlite3
con = sqlite3.connect('./laravelposts.db')
cur = con.cursor()
url = "https://qiita.com/api/v2/items"
params = {'query': 'tag:laravel', 'page': 100,'per_page':'100'}
headers = {'Authorization': 'Bearer アクセストークン'}
response = requests.get(url, params=params, headers=headers)
print(response.url)
if response.status_code == 200:
data = response.json()
for post in data:
print(post['created_at'])
else:
print("Error: ", response.status_code)
print('処理が完了しました。')
ダメダメな処理だけど、1回走らせるだけならこれで十分

これで単純に取得できる記事の一番古いのが「2019-06-12T16:55:39+09:00」である事が解ったので、
それ以前の記事も取得できるように変える。
ついでに、DBにも記事の作成日時を保存するカラムを追加する
CREATE TABLE posts (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
content TEXT,
url TEXT NOT NULL,
created TEXT
);
記事を取得する処理はこんな感じに書き換える。
参考にしないでください。マジで許してください。
穴があったら入りたいレベルのクソ汚いコードでごめんなさい。
import requests
import sqlite3
con = sqlite3.connect('./laravelposts.db')
cur = con.cursor()
url = "https://qiita.com/api/v2/items"
headers = {'Authorization': 'Bearer アクセストークン'}
params = {'query': 'tag:laravel created:>=2019-06-13', 'page': 0,'per_page':'100'}
#とりあえず100ページまで取得
for i in range(1, 100):
params['page'] = i
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
for post in data:
body = post["rendered_body"].replace("'", "''").replace('"', '""')
body = body.replace('\n', '').replace('\r', '').replace('\t', '')
body = body.replace('\b', '').replace('\f', '')
body = body.replace('(', "'<").replace(')', "'>")
title = post["title"].replace("'", "''").replace('"', '""')
title = title.replace('\n', '').replace('\r', '').replace('\t', '')
title = title.replace('\b', '').replace('\f', '')
title = title.replace('(', "'(").replace(')', "')")
sql = F' ("{title}", "{body}","{post["url"]}","{post["created_at"]}") '
# print(sql)
cur.execute(F'INSERT INTO posts (title,content,url,created) values {sql}')
else:
print("Error: ", response.status_code)
con.commit()
print(F'{i}/100')
# 100ページ以上は取得できないので、無理やり取得
params['query'] = 'tag:laravel created:<2019-06-13'
for i in range(1, 100):
params['page'] = i
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
for post in data:
body = post["rendered_body"].replace("'", "''").replace('"', '""')
body = body.replace('\n', '').replace('\r', '').replace('\t', '')
body = body.replace('\b', '').replace('\f', '')
body = body.replace('(', "'<").replace(')', "'>")
title = post["title"].replace("'", "''").replace('"', '""')
title = title.replace('\n', '').replace('\r', '').replace('\t', '')
title = title.replace('\b', '').replace('\f', '')
title = title.replace('(', "'(").replace(')', "')")
sql = F' ("{title}", "{body}","{post["url"]}","{post["created_at"]}") '
cur.execute(F'INSERT INTO posts (title,content,url,created) values {sql}')
else:
print("Error: ", response.status_code)
con.commit()
print(F'{i}/100')
print('処理が完了しました。')
超絶汚いソースだけど、許してくれ!
次回以降使う事があったら、リファクタリングはする。
ちなみにこの状態で「ソースレビューして」ってコミットされてたらブチぎれる自信がある!
という事で実行する
py index.py
後は放置!
こんな感じで10秒に1回ぐらいカウンターが進んでいく

取り合えず記事は13783レコード取得できた!
次回に続く