富士通の非公式Advent Calendar 2018 9日目 の記事です。記事の内容は個人の見解であり、所属する組織を代表するものではありません。
はじめに
Linux kernel の比較的新しい機能である eBPF について簡単に調べてみたので、その概要と使い方を紹介します。
eBPF は extended Berkeley Packet Filter の略で、ざっくり言うと、ユーザ空間で作成したプログラムをカーネルに送り込んで、独自の命令セット を持つカーネル内部の仮想マシン(以下VM)上で実行できる機能です。名前の通り、eBPF は BPF(Berkeley Packet Filter)と呼ばれる古くからあるパケットフィルタの技術を拡張したもので、パケットフィルタに限らず OS 用途一般に使えるようになっています。
システムに危険を及ぼす可能性のあるコードは、事前のチェックで検出され実行できないようになっています。例えば、ループ処理を含むコードを実行できない等の制約があります。
eBPF のバイトコードを人が直接記述するのは大変なので、C言語やその他言語で簡単に eBPF を扱えるように、BCC(BPF Compiler Collection)と呼ばれるツール群が提供されています。
本記事で使用する環境
eBPF が取り込まれたのは Linux kernel 3.15 からですが、BCC を使用するためには Linux kernel 4.1 以降で、INSTALL.md に記載されているパラメータでカーネルがコンパイルされている必要があります。
新しい機能 も利用できるよう、本記事では、執筆時点での Fedora の最新版である、Fedora 29 Server (Linux kernel 4.18)を使用します。
eBPF および BCC を使用するために以下のパッケージをインストールします。
- bcc-tools
- kernel-headers
- kernel-devel
kernel-* パッケージの版数は、uname -r の結果と一致している必要がありますのでご注意ください。
代表的な機能と使い方
本記事用に作成した簡単なサンプルプログラムを使って、eBPF および BCC の代表的な機能の使用例を紹介します。フロントエンドとして python を使用しています。
1. bpf_trace_printk
まずは Hello, World です。iovisor/bcc/examples/hello_world.py を参考にしています。
# !/usr/bin/python3
from bcc import BPF
bpf_text = """
int trace_sys_clone(struct pt_regs *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""
b = BPF(text=bpf_text)
b.attach_kprobe(event="__x64_sys_clone", fn_name="trace_sys_clone")
b.trace_print()
このコードは python で書かれていますが、その一部(bpf_text 変数に格納した文字列) に C言語のコードを含んでおり、それが実行時に eBPF のバイナリにコンパイルされカーネル内部の VM 上で実行されます。
上のコードの中の、
b.attach_kprobe(event="__x64_sys_clone", fn_name="trace_sys_clone")
の部分は、以下のことを指定しています。
- カーネル内部で
__x64_sys_clone関数が呼ばれたときに、 - 自分で定義した
trace_sys_clone関数を呼び出す
__x64_sys_clone はシステム上でプロセスを生成するときに呼ばれる関数です。
bpf_trace_printk はカーネル空間で動く eBPF のプログラムからユーザ空間にメッセージ(文字列)を渡すための関数です。ユーザ空間からは /sys/kernel/debug/tracing/trace_pipe を通じてそのメッセージを受け取ることができます。この例では、BCC が提供する BPF.trace_print を呼び出して、trace_pipe からのメッセージの受け取りとコンソールへの出力の両方を実行しています。
動作のイメージは以下の図の通りです。

カーネル内部では、通常 ①→④ で処理が流れますが、例のように eBPF を attach している場合には __x64_sys_clone 処理に到達した時点で eBPF コードに寄り道して、①→②→③→④ の順で処理されることになります。
以下は実行例です。システム上でプロセス生成が実行される(たとえば bash の上で何かコマンドをたたく) たびに、カーネル空間からユーザ空間に "Hello, World!" メッセージを送って、ユーザ空間でそれを出力しています。trace_pipe は ftrace の出力先でもあるので、その形式に合わせて (親)プロセスの情報、CPU番号、時刻も一緒に出力されています。
# ./hello_world.py
b' bash-9709 [001] .... 1814.873593: 0: Hello, World!'
b' bash-9709 [001] .... 1817.561363: 0: Hello, World!'
b' bash-9709 [001] .... 1819.697275: 0: Hello, World!'
この例で扱った bpf_trace_printk や trace_print は、イベント発生時にユーザ空間へメッセージ(文字列)を渡す手段であり、デバッグ用途で使うものです。次に紹介するように、メッセージに限らず、イベント発生ごとに任意の構造のデータをユーザ空間に受け渡すこともできます。
2. BPF_PERF_OUTPUT/perf_submit
前の例では、イベント発生ごとにメッセージ(文字列)をユーザ空間へ送っていましたが、BPF_PERF_OUTPUT および perf_submit を使うと、文字列に限らず任意の構造のデータを受け渡すことができます。
例として、メモリ上の dirty なページをディスクへ書き出す要求があったときに、そのタイミングで、どのファイルに対して要求があったかを出力することを考えます。
以下がプログラムの例です。
# !/usr/bin/python3
from bcc import BPF
import ctypes as ct
import time
bpf_text = """
# include <linux/fs.h>
struct data_t {
unsigned long ino;
};
BPF_PERF_OUTPUT(events);
int trace_do_writepages(struct pt_regs *ctx, struct address_space *mapping) {
struct data_t data;
struct inode *host = mapping->host;
if (host && host->i_ino) {
data.ino = host->i_ino;
events.perf_submit(ctx, &data, sizeof(data));
}
return 0;
};
"""
b = BPF(text=bpf_text)
b.attach_kprobe(event="do_writepages",
fn_name="trace_do_writepages")
class Data(ct.Structure):
_fields_ = [
("i_ino", ct.c_ulong)
]
def print_event(cpu, data, size):
event = ct.cast(data, ct.POINTER(Data)).contents
print("{} {}".format(time.strftime("%H:%M:%S"), event.i_ino))
b["events"].open_perf_buffer(print_event)
print("TIME INODE")
while True:
b.perf_buffer_poll()
カーネル空間からユーザ空間に渡す、ファイルを(ファイルシステム内で)一意に特定する情報として、 inode 番号を渡すことにして、それをメンバ ino として含む data_t という名前の構造体を新たに定義しています。dirty なページをディスクに書き出す際に呼ばれる do_writepages に attach して、その呼び出し時の引数を見て inode 番号を取得し、data_t 構造体に変換して perf_submit でユーザ空間に渡しています。
データの受け渡しに使うバッファ(ring buffer)を BPF_PERF_OUTPUT および open_perf_buffer で確保しています。
ユーザ空間では perf_buffer_poll によりそのバッファを監視し、バッファにカーネルからのデータが入るとただちにそれを受け取って、callback 関数として指定した print_event を呼び出し、内容を表示します。この例では、受け取った inode 番号をタイムスタンプと共に出力します。
以下のようなイメージです。

前の例と同様、通常の流れは ①→④ で、do_writepages に attach した本例の処理の流れは ①→②→③→④ となります。
以下は実行例です。
まず、書き換え対象の適当なファイル(test.txtとします)の inode番号を ls -i で調べます。inode 番号は 20093401 です。
# ls -i test.txt
20093401 test.txt
別のコンソールで上記サンプルプログラムを流しておきます。
# ./writepages.py
先ほど用意したファイルを更新(テキストを追記)します。
# echo message >> test.txt && date +"%H:%M:%S"
21:20:22
この時点(21:20:22)では、何も起きません。ファイルに対応するメモリ上のデータ(page) が書き換えられ、dirty なページが増えたただけです。しばらく待てばディスクへの書き出し処理が走るはずですが、sync コマンドで強制的に書き出してみます。
# sync && date +"%H:%M:%S"
21:20:32
sync コマンドを実行したタイミング(21:20:32)で、もう一方のコンソールでは、上記ファイル(inode番号:20093401) に対して書き出しの処理があったことを示すメッセージが出力されます。
# ./writepages.py
TIME INODE
<略>
21:20:32 20093401
3. Maps
これまでの例ではイベント発生のたびにユーザ空間へデータの受け渡しが発生していました。そうではなく、カーネル内部でデータを処理・保存しておいて、それをユーザ空間から任意のタイミングで取り出せる方が、好ましい場合もあります。
このような場合にデータ格納域として使えるのが Maps です。Maps はカーネル内部に存在する領域として、カーネル内から参照/更新でき、ユーザ空間からも任意のタイミングで(イベントとは非同期に) 参照/更新できます。
データ構造として、配列(BPF_ARRAY)や連想配列(BPF_HASH)、ヒストグラム(BPF_HISTOGRAM) などが用意されています。詳細は bcc Reference Guide に記載があります。
例として、プロセス間通信の通信量を計測する場合を考えます。特に、プロセスの内部通信でよく使われている UDS (Unix Domain Socket) を対象として、ソケットタイプにSOCK_STREAM を指定した場合の送信データ量を測定することにします。 unix_stream_sendmsg 関数の戻り値がこのデータ量に相当します。
以下が、実現のコードの例です。
# !/usr/bin/python3
from bcc import BPF
from time import sleep, strftime
bpf_text = """
# include <net/af_unix.h>
BPF_HASH(send_bytes, u64, u64);
int trace_ret_unix_stream_sendmsg(struct pt_regs *ctx) {
int ret = PT_REGS_RC(ctx);
u64 pid = bpf_get_current_pid_tgid() >> 32;
u64 *prev, bytes = 0;
if (ret > 0) {
prev = send_bytes.lookup_or_init(&pid, &bytes);
bytes = *prev + ret;
send_bytes.update(&pid, &bytes);
}
return 0;
}
"""
b = BPF(text=bpf_text)
b.attach_kretprobe(event="unix_stream_sendmsg", fn_name="trace_ret_unix_stream_sendmsg")
send_bytes_table = b.get_table("send_bytes")
while True:
sleep(5)
print("%-8s" % strftime("%H:%M:%S"))
print("{:>10s} {:>18s}".format("PID", "UDS(stream)_txB"))
for k, v in send_bytes_table.items():
print("{:10d} {:18d}".format(k.value, v.value))
以下の行で Maps を定義しています。
BPF_HASH(send_bytes, u64, u64);
key, value の型がそれぞれ u64 の、send_bytes という名前の連想配列です。この例では、PID (key)毎に送信バイト数(value)を保存しておくために使用します。 key/value の型として構造体を指定することも可能です。
BPF.attach_kretprobe で unix_stream_sendmsg 関数の 返却時 に attach し、カーネル内部で以下を実行しています。
-
PT_REGS_RCでunix_stream_sendmsgの戻り値を得る(送信バイト数に相当) -
bpf_get_current_pid_tgidで PID を得る - Maps に対する
lookup_or_initやupdateの操作で PID ごとの送信バイト数(累計)を保存
ユーザ空間では、BPF.get_table で取得したオブジェクトを通じて、 5秒おきに Maps を参照し、key, value のペアを、PID、送信バイト数として表示しています。
動作は以下の図のようなイメージです。

以下は実行例です。
# ./uds_send.py
14:21:19
PID UDS(stream)_txB
843 380
969 317
14:21:24
PID UDS(stream)_txB
843 760
806 12312
969 637
1109 10260
13968 4652
1105 119704
5秒おきに、PID ごとに送信バイト数が表示されます。
4. XDP
今までの例は、カーネル内部の情報を参照して結果を出力するものでした。XDP は eXpress Data Path の略で、カーネル内のデータを参照するだけでなく、ネットワークの処理の動作を変えられる機能です。
XDP の attach 先はネットワークドライバです。そのため、XDP の使用可否は、ドライバ側の対応状況 に依存します。
ここでは、bcc/examples/networking/xdp/xdp_drop_count.py を参考に、eth ヘッダを解析して、IPパケットのうち、プロトコル番号 が 1 のパケット(ICMPパケット) のみ DROP するサンプルを考えます。
# !/usr/bin/python3
from bcc import BPF
import sys
import time
bpf_text = """
# include <uapi/linux/bpf.h>
# include <linux/ip.h>
BPF_HASH(dropcnt, u32, u32);
int xdp_drop_icmp(struct xdp_md *ctx) {
void* data_end = (void*)(long)ctx->data_end;
void* data = (void*)(long)ctx->data;
struct ethhdr *eth = data;
u32 value = 0, *vp;
u32 protocol;
u64 nh_off = sizeof(*eth);
if (data + nh_off > data_end)
return XDP_PASS;
if (eth->h_proto == htons(ETH_P_IP)) {
struct iphdr *iph = data + nh_off;
if ((void*)&iph[1] > data_end)
return XDP_PASS;
protocol = iph->protocol;
if (protocol == 1) {
vp = dropcnt.lookup_or_init(&protocol, &value);
*vp += 1;
return XDP_DROP;
}
}
return XDP_PASS;
}
"""
b = BPF(text=bpf_text)
fn = b.load_func("xdp_drop_icmp", BPF.XDP)
device = sys.argv[1]
b.attach_xdp(device, fn)
dropcnt = b.get_table("dropcnt")
while True:
try:
dropcnt.clear()
time.sleep(1)
for k, v in dropcnt.items():
print("{} {}: {} pkt/s".format(time.strftime("%H:%M:%S"), k.value, v.value))
except KeyboardInterrupt:
break
b.remove_xdp(device)
attach_xdp でドライバ層に attach します。パケット到着ごとに、自分で定義した関数 xdp_drop_icmp が呼ばれます。この関数の戻り値が XDP_PASS であれば、そのパケットは通常どおり処理され(ドライバ層からネットワークの上位層へのデータの受け渡し)、戻り値がXDP_DROP であればそのパケットを DROP します。
DROP のついでに、その数を Maps を使って記録し、毎秒その数を表示しています。
以下は動作のイメージです。
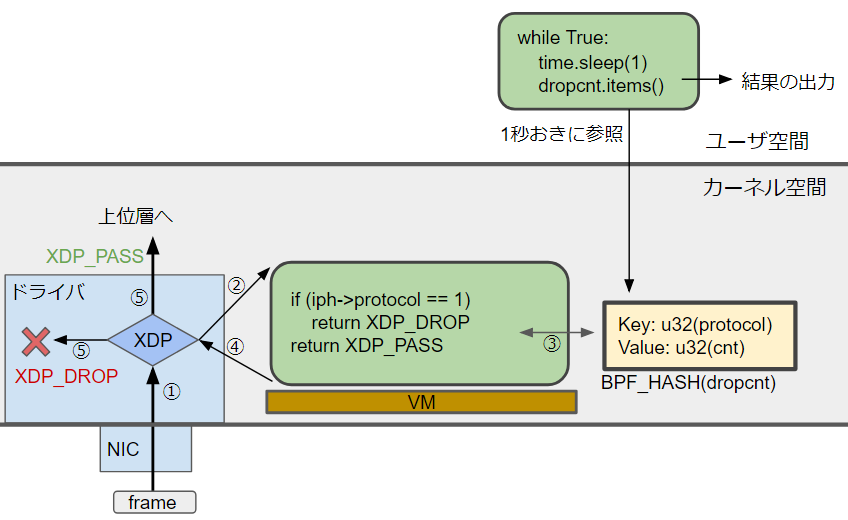
通常は ①→⑤→上位層 の流れですが、例のように XDP を使うと、①→②→③→④ のように eBPF のコードの処理された後に、その結果に応じて、引き続き上位層で処理するか、パケットを DROP するかが変わります。
以下は実行例です。自宅の環境で XDP が使えるインターフェースとして、KVM ゲストの e1000 ドライバのインターフェースで試しました。
# ethtool -i ens11 | grep driver
driver: e1000
以下は、指定の NIC (ens11) に対して外部から ping を使って秒間5個の ICMP パケットを送っている状態で、本サンプルプログラムを動作させた結果です。プロトコル番号1 のパケット(ICMPパケット)を毎秒5個、DROP していることを表しています。
# ./xdp_drop.py ens11
19:15:24 1: 5 pkt/s
19:15:25 1: 5 pkt/s
19:15:26 1: 5 pkt/s
19:15:27 1: 5 pkt/s
19:15:28 1: 5 pkt/s
上記を実行中は、ping は通りませんが、他のプロトコル(TCP など)は使えます。以下は外部からアクセスしたときの実行例です。192.168.122.41 が上記インターフェース(ens11) に対応するIPアドレスです。
$ ping -c 1 -w 1 192.168.122.41 # ping(ICMP)は通らない
PING 192.168.122.41 (192.168.122.41) 56(84) bytes of data.
--- 192.168.122.41 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 999ms
$ ssh root@192.168.122.41 "echo test" # ssh(TCP)は使える
root@192.168.122.41's password:
test
サンプルプログラムの実行を止めた後は、ping が通ります。
$ ping -c 1 -w 1 192.168.122.41 # pingが通る
PING 192.168.122.41 (192.168.122.41) 56(84) bytes of data.
64 bytes from 192.168.122.41: icmp_seq=1 ttl=64 time=0.388 ms
--- 192.168.122.41 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.388/0.388/0.388/0.000 ms
eBPF を使ったツール
主に性能測定用途のものですが、iovisor/bcc/tools には eBPF を使ったツールが公開されています。
各ツールのカーネル内での位置付けについて、iovisor/bccに説明があります。

この中の一つである、biolatency を試しに使ってみます(上の図の Block Device Interface の部分に相当)。
# python3 biolatency.py
Tracing block device I/O... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 1 |* |
128 -> 255 : 23 |****************************************|
256 -> 511 : 16 |*************************** |
512 -> 1023 : 7 |************ |
ブロック層で計測した IO のレイテンシがヒストグラムで表示されます。
bpftool
bpftool を使用すると、動作中の eBPF の情報を確認できます。利用には別途 bpftool パッケージのインストールが必要です。
以下は、Hello, World のサンプルの実行中に実行した結果です。trace_sys_clone に attach していることがわかります。
# bpftool prog
<略>
30: kprobe name trace_sys_clone tag c514db71faba4034 gpl
loaded_at 2018-12-05T21:39:00+0900 uid 0
xlated 120B jited 115B memlock 4096B
動作中の eBPF のコードは、以下のように確認できます。
# bpftool prog dump xlated id 30
0: (b7) r1 = 2593
1: (6b) *(u16 *)(r10 -4) = r1
2: (b7) r1 = 1684828783
3: (63) *(u32 *)(r10 -8) = r1
4: (18) r1 = 0x57202c6f6c6c6548
6: (7b) *(u64 *)(r10 -16) = r1
7: (b7) r1 = 0
8: (73) *(u8 *)(r10 -2) = r1
9: (bf) r1 = r10
10: (07) r1 += -16
11: (b7) r2 = 15
12: (85) call bpf_trace_printk#-44656
13: (b7) r0 = 0
14: (95) exit
おわりに
自分が使う範囲に限れば eBPF でなく Systemtap でも十分かと思いましたが、Cilium などの応用もあり、今後も応用範囲が広がる可能性があるので、引き続き動向を追えればと思います。