基本事項
インストール
私の環境はMacOS Monterey なので、以下からダウンロードし、インストールしました。
https://cran.r-project.org/bin/macosx/
ちなみにRstudio は利用しておりません。
ライブラリを利用
RはR本体と多彩なライブラリで構成されています。
ライブラリはCRANと呼ばれるリポジトリで管理されています。
実はR本体でできることは限られていますが、CRANに膨大な数のライブラリが存在するため、それらを取り込むことでできることの幅が飛躍的に大きくなります。
ライブラリをインストールするには以下のようにします。
たとえば、tidyverse というライブラリをインストールするには
install.packages('tidyverse')
と入力します。
ところが、インストールしただけでは使うことができません。
インストールしたライブラリを使用するには
library(tidyverse)
と入力して、宣言する必要があります。
インストールの作業は初回のみですが、宣言はRを立ち上げるたびに行う必要があります。
データ型
以下のようなデータ型があります。
- integer(numeric) 整数型
- double(numeric) 実数型
- complex 複素数型
- character 文字型
- logical 論理型
また、それとは別に以下のようなデータ構造があります。
- vector (ベクトル)
- matrix (行列)
- array (配列)
- data.frame (データフレーム)
- list (リスト)
- table (テーブル)
データ型とデータ構造は独立した概念なので、たとえば
「double型のvector」や「integer型のmatrix」などを作ることができます。
たとえば、以下のようなvectorを定義してみます。
typeof()でデータ型を調べることができます。
> a <- c(1, 2)
> typeof(a)
[1] "double"
aはデータ型としてはdoubleです。
もし、integer型のvectorを定義したければ、以下のように数値の後ろに"L"をつけます。
> a <- c(1L, 2L)
> a
[1] 1 2
> typeof(a)
[1] "integer"
参照 https://uc-r.github.io/integer_double/
is系の関数を使えば、引数のデータが当該のデータ型かどうかを調べることができます。
> is.double(a)
[1] TRUE
is系の関数は、他にもis.complex()、is.character() など上に挙げた各データ型に対応したものがあります。
対して、データ型を変換するにはas系の関数を使います。
> typeof(a)
[1] "double"
> b <- as.integer(a)
> b
[1] 1 2
> typeof(b)
[1] "integer"
データ構造についても同様に種々のis系関数、as系関数があります。
> is.vector(a)
[1] TRUE
matrixとdata.frame
これはちょっと紛らわしいかもしれません。
どちらも縦横2次元にデータが並んでいるからです。
> MA
[,1] [,2]
[1,] 1 2
[2,] 3 4
> DB
V1 V2
1 5 6
2 7 8
> class(MA)
[1] "matrix" "array"
> class(DB)
[1] "data.frame"
このようにMAはmatrix、DBはdata.frameです。
相互変換ができる
matrixとdata.frameは相互変換ができます。
> DA <- as.data.frame(MA)
> DA
V1 V2
1 1 2
2 3 4
> is.data.frame(DA)
[1] TRUE
> MB <- as.matrix(DB)
> MB
V1 V2
[1,] 5 6
[2,] 7 8
> is.matrix(MB)
[1] TRUE
matrix は行列演算が可能
matrixであるMAとMBの積(いわゆる行列の積)を求めてみると
> MA %*% MB
V1 V2
[1,] 19 22
[2,] 43 50
MBの代わりにDB(data.frame)を用いるとエラーになる
> MA %*% DB
MA %*% DB でエラー: 数値/複素数/行列またはベクトルが要求されます
matrix には統計関数(mean()やsd()など)が適用可能
matrix MAの第1行の平均を求めると
> mean(MA[1,])
[1] 1.5
同じことはdata.frame DBではできません。
> mean(DB[1,])
[1] NA
警告メッセージ:
mean.default(DB[1, ]) で:
引数は数値でも論理値でもありません。NA 値を返します
ちなみに統計関数はvectorにも適用できます。
> v
[1] 1 2 3
> is.vector(v)
[1] TRUE
> mean(v)
[1] 2
もう少し突っ込んでいうと、matrix MAの1行目を取り出したMA[1,]はvectorです。
一方、data.frame DBの1行目を取り出したDB[1,]はvectorではありません。
> is.vector(MA[1,])
[1] TRUE
> is.vector(DB[1,])
[1] FALSE
ということで、上記の例はvectorにmean()を適用した、ということですね。
matrixそのものにmean()を適用することもできます。
> mean(MA)
[1] 2.5
これは全要素の平均です。
data.frameの列を取り出して表示
以下のようなdata.frame D を考えます。
> D
V1 V2
1 1 4
2 2 5
3 3 6
このdata.frame のV1列を取り出して表示するには
> D$V1
[1] 1 2 3
ちなみに取り出された列のデータ構造はvector です。
> v1 <- D$V1
> is.vector(v1)
[1] TRUE
前項の内容と合わせると、D$V1ならvector なので、mean()を適用することができます。
> mean(D$V1)
[1] 2
入出力
作業ディレクトリ
ファイルからの入出力を行うには、作業ディレクトリを指定しておく必要があります。
現在設定されている作業ディレクトリを調べるには
> getwd()
[1] "/Users/***/statistics/R/"
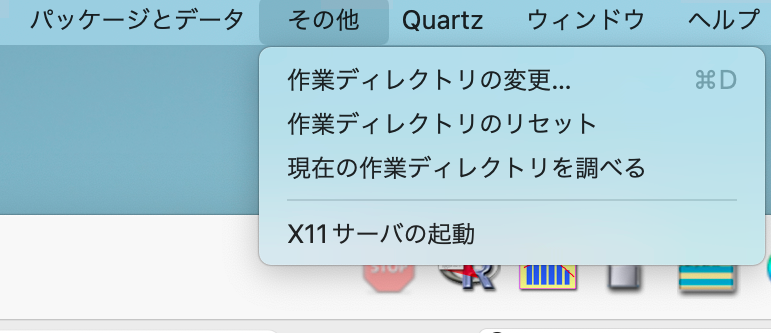
とします。作業ディレクトリを変更するには、メニューバーの
「その他-作業ディレクトリの変更」から行います。
CSVファイルからの入力/出力
CSVファイルから入力するにはread.csv()を用いて
D <- read.csv("testdata.csv")
とします。これでtestdata.csv がdというオブジェクトに代入されます。
Dはdata.frameです。
> is.data.frame(D)
[1] TRUE
逆に、data.frame DをCSVファイルに出力するにはwrite.csv()を用いて
write.csv(x = D, file = "./sampledata1.csv")
とします。
参考文献
R 基本統計関数マニュアル(間瀬 茂)
Rのページ(逆瀬川 浩孝)
biostatistics
トップページはこちら