まえがき
今更ですが、友人の影響でウマ娘を遊んでみたところ、結構面白くて、そこから本物の競馬にも興味が湧きました。普通にレースを見るだけでも楽しいのですが、せっかくなのでエンジニアらしい楽しみ方をしたいと思い、AIを使ってレースの結果を予想してみることにしました。
AIを作成した環境は以下のとおりです。
・開発環境: JupyterLab
・機械学習フレームワーク: LightGBM
・パッケージ管理: Anaconda
・学習データ:JRDB (※ 有料の会員登録が必要です)
・OS:Mac Intel Core i5 (※ Windowsの方は適宜読み替えてください)
とりあえず動けばいいや、の精神で書いたため、人に見せられるような代物ではないんですが、一応Githubにソースコードも載せています。興味ある方はご参照ください
https://github.com/sf-12/uma-ai-jrdb
※ お断り
この記事を参照することで生じた損害・損失に対して、一切の責任を負いかねます。
馬券の購入などについて、あくまで自己責任でお願いします。
競馬の馬券やオッズについてのすごい適当な説明
記事を読みやすいように、前提知識をすごいざっくり説明します。
知ってるよ!って方は読み飛ばしてください。
勝馬投票券(馬券)
競馬は、ただ単にレースの結果を予想するだけでも楽しいですが、馬券を購入するという楽しみ方もあります。勝ちそうな馬を予想して馬券を購入し、その予測が正しかった場合には賞金を獲得することができます。馬券の種類には、単勝(1着になる馬を当てる)、複勝(指定した馬が3着以内に入る)、馬連(1着と2着を正確に当てる)などがあります。
3着以内を当てる馬券:「複勝」
この記事では特に、「複勝」馬券に焦点を当てます。複勝は、選んだ馬がレースで3着以内に入ると当たりとなる馬券です。3着以内に入る馬を当てればいいので、1着を当てる単勝に比べると比較的当てやすいとされています。しかし、レースの結果は、馬のコンディション、騎手の技術、天候、馬場状態など、多くの要素によって左右されるため、簡単に当てられるかというと、そういうわけにもいかないです。
オッズとは?
オッズは、特定の馬が勝つと予測される確率を示し、この数値に基づいて配当金が計算されます。オッズが高い馬ほど勝つ可能性が低く見られ、その馬が勝った場合には高いリターンを得られます。逆に、オッズが低い馬は勝つ可能性が高いと見られ、配当金は比較的低くなります。
機械学習の用語やプロセスについてのすごい適当な説明
記事を読みやすいように、前提知識をすごいざっくり説明します。
知ってるで!って方は読み飛ばしてください。
よく使う用語
機械学習でよく出てくる用語です。この記事内でも使用している可能性があります。
機械学習モデル
単にモデルともいいます。データからパターンを学習し、予測や分類を行います。
つまり今回、競馬予想AIを作るというのは具体的に何をするのかというと、モデルに競馬のレースのデータを読み込ませて学習させ、そのモデルを使って未知のレースの結果を予測させる、ということをやろうとしています。
モデルにも色々種類があリますが、今回はLightGBMというフレームワークを使用したいと思います。
これは決定木というアルゴリズムをベースにしたものになります。
特徴量
特徴量は、データの各要素のことを指します。今回の場合は、レースに出る馬の年齢や体重、性別、過去の成績などが特徴量にあたります。
説明変数・目的変数
説明変数は、予想のために使用する入力値となる変数です。例えば今回であれば、馬の過去の成績やレースの距離、騎乗する騎手、前走からのインターバルなど、レースの着順を予想するためにモデルに入力する値が説明変数となります。
目的変数は、予測したい出力値となる変数です。今回は、レースの着順が目的変数になります。
説明変数と目的変数は用途は違いますがどちらもデータの特徴を表すため、「特徴量」である、という点では同じです。
機械学習のプロセスについて
実際に競馬予想AIを作る前に、おおよそのプロセスについて紹介させていただきます。
大体こんな感じです。今回もこの流れに沿って実施していきます。
環境構築
機械学習を実施するための環境を構築します。プログラミング言語はPythonがよく使用されます。
学習するデータの量にもよりますが、モデルの学習にはそれなりのPCスペックが必要となります。そのため、クラウドに学習用の環境を用意するケースもあります。環境構築はつまずくことも多く、私も苦手なのですが頑張って構築します。
データ収集
まず、予想したい内容に応じて、機械学習に使用するデータを集めます。データは基本的には多い方がいいです。なので頑張って集めます。
前処理
収集したデータを整形し、モデルが処理できる形式に変換します。
特徴量に欠損や誤りがある場合にそれを補完・修正したり、不要な特徴量を削除したりします。また、特徴量同士を組み合わせて新しい特徴量を作成してみたり、色々やってみてモデルの精度が上がるようにします。モデルの性能を左右する大事なプロセスなので頑張ります。
モデルを学習する
前処理したデータを使用して、モデルにパターンを学習させます。この過程で、モデルはデータの構造を理解し、未知のデータに対する予測を行えるようになっていきます。「機械学習」というだけあって、この学習させる部分がメインの部分なので頑張ります。
モデルを評価する
モデルの性能を評価し、過学習(学習しすぎて学習データに特化したモデルになり、未知のデータに対する性能が低い)や未学習(学習が足りなくて性能が低い)がないかを確認します。その結果に応じて、モデルを学習させるときのパラメータを調整したり、追加でデータを集めたりすることもあります。根気よく検証し、試行錯誤をする必要があるので頑張ります。
予測
最終的に、訓練されたモデルを使用して未知のデータに対する予測を実施します。これが本来の目的ともいえる部分なので頑張りどころになります。
↓↓↓↓↓
前置きは以上になります。
では、競馬予想AIを作成していきます。
↓↓↓↓↓
環境構築
まずは、機械学習を行うための環境を用意する必要があります。
今回はPythonでの開発に必要なものをセットにしてあるAnacondaを使用しました。
Anaondaをインストール
公式サイトからダウンロードしてインストールします。
https://www.anaconda.com/download
Anacondaには環境という概念があります。これを使って、他のプロジェクトとの依存関係の衝突を避けます。
あらかじめ環境を作成しておきます。
env_uma_aiのところは好きな名前で大丈夫です。
$ conda create -n env_uma_ai
作成した環境をアクティベートします
$ conda activate env_uma_ai
Jupyter Lab をインストール
Jupyter Labはブラウザ上で開くことのできるツールです。コードをセルというブロックに区切って記入していきます。セル単位でコードを実行でき、結果をすぐ確認できるので、試行錯誤しながら処理を書き進めることができます。
インストールします。
$ conda install jupyterlab
↓こんな警告が出たので、指示に従って
==> WARNING: A newer version of conda exists. <==
current version: 23.7.4
latest version: 23.11.0
Please update conda by running
$ conda update -n base -c defaults conda
Or to minimize the number of packages updated during conda update use
conda install conda=23.11.0
こちらも実行しました。
$ conda update -n base -c defaults conda
Jupyter Notebookを使ってみる
実行用に適当な場所にフォルダを作成します
$ mkdir uma-ai
フォルダに移動します。
cd uma-ai
Jupyter Labを起動します。
$ jupyter lab
これでブラウザでJupyterLabが起動します。

Notebookと書いてある欄にある「python3(ipykernel)]をクリックすると、
新しいファイルが開きます。
ここにソースコードやテキストを書いていきます。
試しにセルの中にprint("Hello World!")と書いて、▶︎ボタンを押して実行してみます。
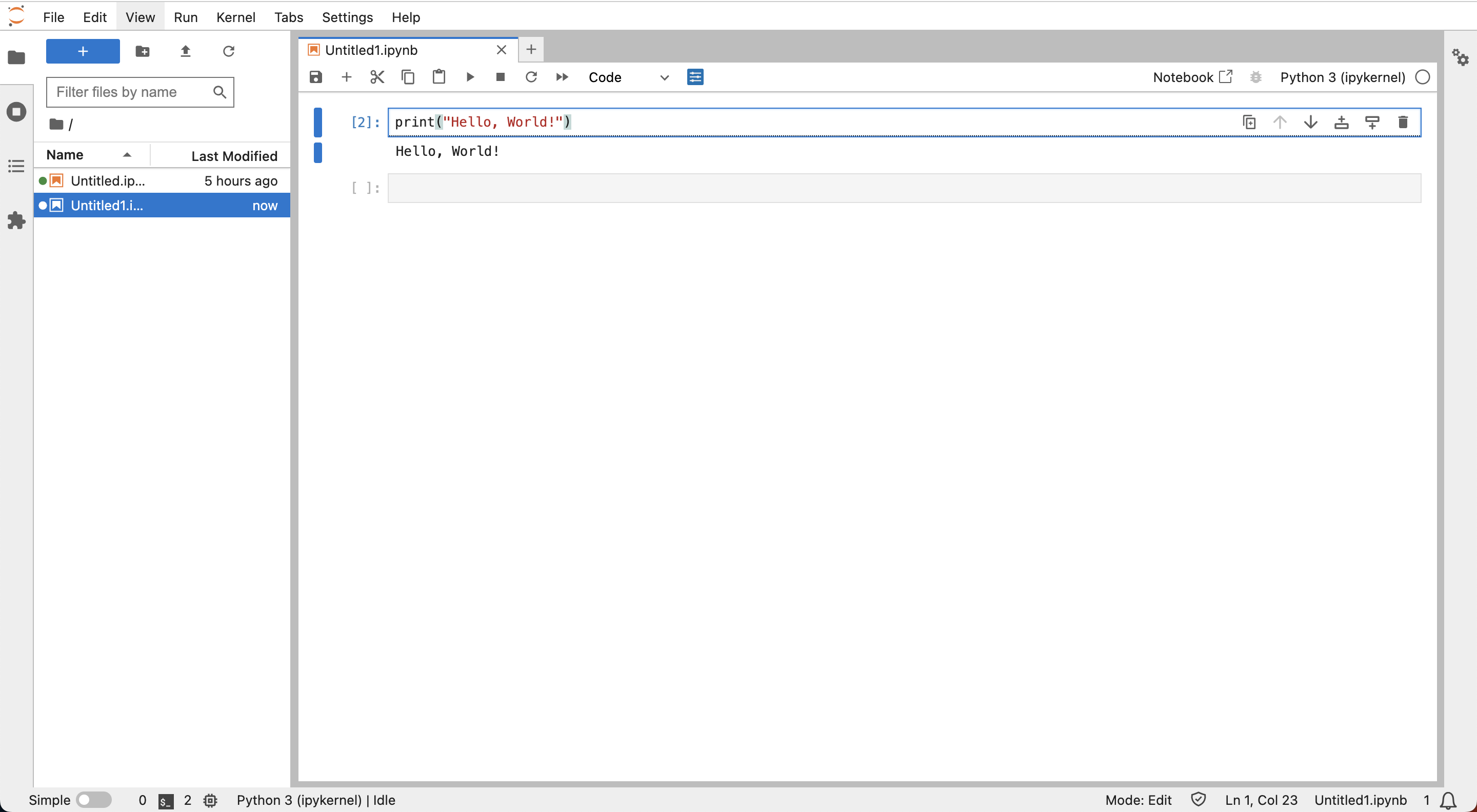
すると、このようにPythonのコードが実行され、「Hello World!」が出力されます。
ちなみに、実行したいコードが書いてあるセルをクリックしてフォーカスが当たった状態で「Shift」+「return」キーを押すことでも実行可能です。
その他にもいろいろ便利なショートカットがあるので気になる方はググってみてください。
Jupyter Labを終了したいときは、ターミナルで「Control」+「c」キーで終了できます。
そのほかに必要なパッケージをインストールしておく
以降の処理で必要になるパッケージをあらかじめインストールしておきます。
condaコマンドを使ってインストールしていきます。
$ conda install tqdm numpy pandas matplotlib seaborn scikit-learn
$ conda install -c conda-forge lightgbm
ただ、グラフを日本語で表示するパッケージがcondaでインストールできなかったため、pipを用いてインストールしました。
$ pip install japanize-matplotlib
Anacondaとpipの両方でパッケージを管理すると依存関係の衝突など起こりそうなので、インストールは自己責任でお願いします。インストールしなくてもグラフが文字化けするだけで、モデルの生成は可能です。
データを用意する
環境が構築できたら、学習に使うデータを用意します。
調べてみたところ、競馬のデータを提供しているサイトがいくつかありました。
例えば次のようなサイトです。
-
netkeiba.com
競馬のデータサイトとして知名度がある。スクレイピングして無料でデータ取得できるらしい。 -
JRDB
オリジナルの指標がたくさんあり、その点を評価する声が多い。データ取得には有料会員になる必要あり。 -
JRA-VAN
競馬の実施団体であるJRA公式が100%出資している会社が提供。そのためデータに信頼性あり。
などなど
今回はJRDBさんを利用させていただくことにしました。
理由は、JRDBさんのデータはダウンロードした後に整形して使用する必要があり、やりがいがあって楽しそうだと思ったためです。
あと、データの種類が豊富なのもいいなと思いました。
データテーブルの分析
まず、JRDBのデータについて確認します。
データの一覧がこちらにまとまっています。
http://www.jrdb.com/program/jrdb_data_doc.txt
もうちょっとわかりやすく整形すると多分こんな感じだと思います。
(間違ってたらすみません)
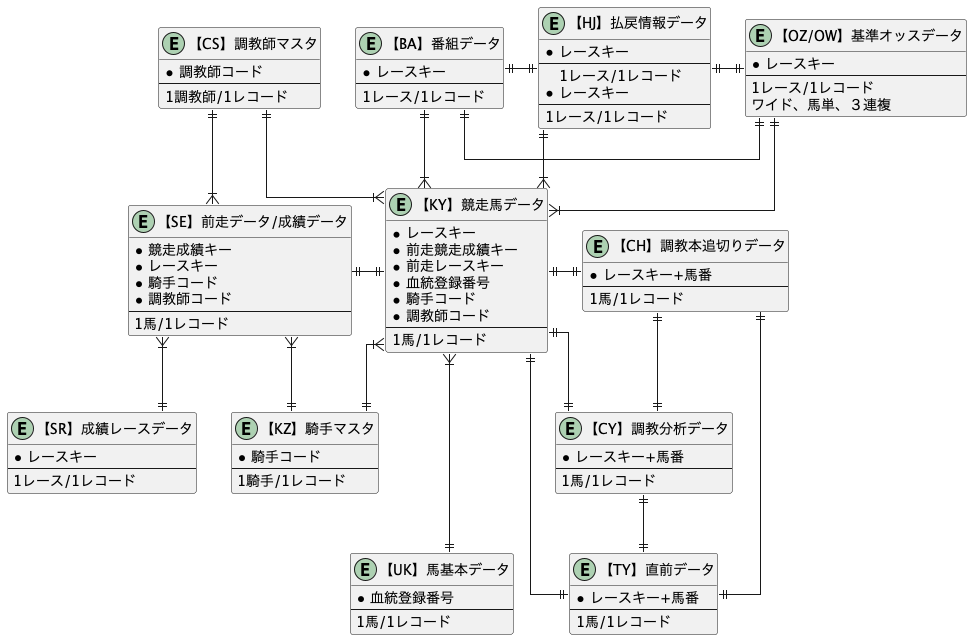
色々テーブルがあってどれを使ったらいいのか迷っちゃうんですが、以下の3つのテーブルを使うことにしました。
【KY】競走馬データ
ある馬がレースに出走するときの前情報的なデータです。その馬の名前や騎乗する騎手の名前、調教師の名前、体重、これまでの獲得賞金などのデータが入っています。これをベースにして、着順を予想すれば良さそうです。なので、説明変数として使えそうです。
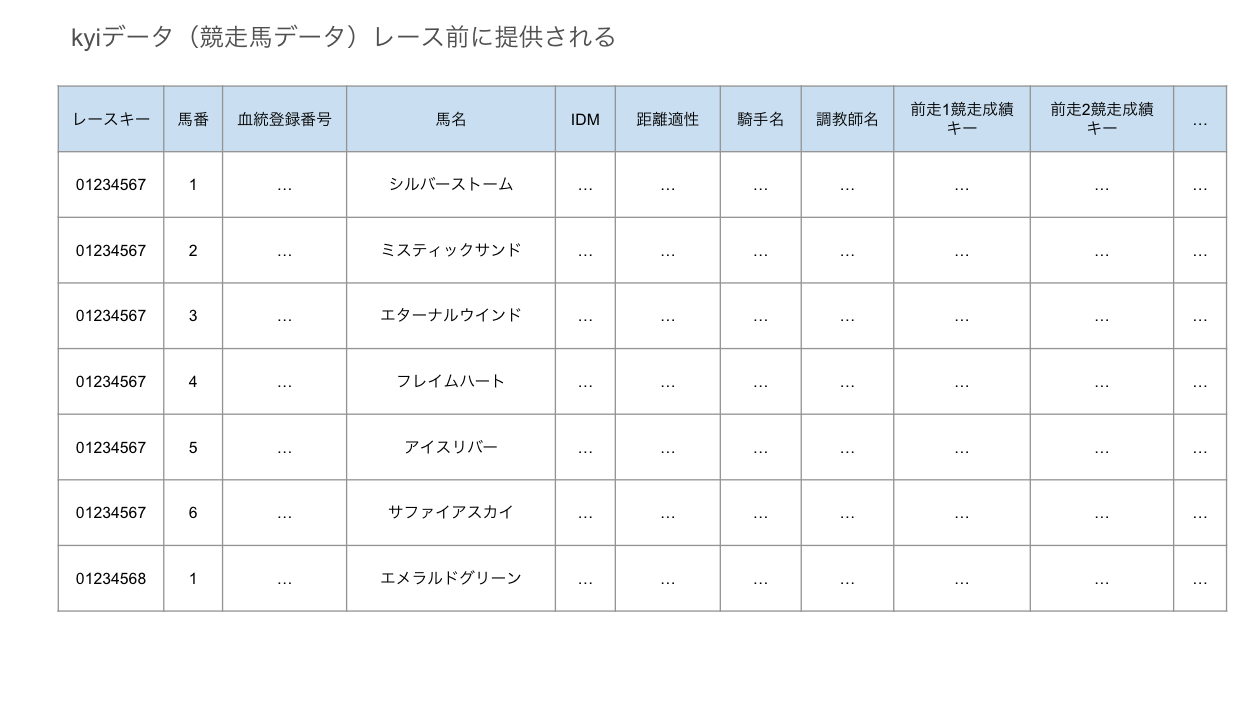
出走する馬ごとにレコードが登録されています。
【SE】前走データ/成績データ
レースに出走した馬の成績が記載されています。
「【KY】競走馬データ」の「レースキー」・「馬番」と照らし合わせて、そのレースでの馬の「着順」を確認することができます。これを今回の目的変数として使う想定です。
また、「【KY】競走馬データ」データの「前走1競走成績キー」〜「前走5競走成績キー」と照らし合わせると、過去のレースの着順などがわかります。これは今回のレースの予想に使えそうなので、説明変数としても活用できそうです。ちょっとややこしいので詳細は後段で各データを結合するときに紹介します。
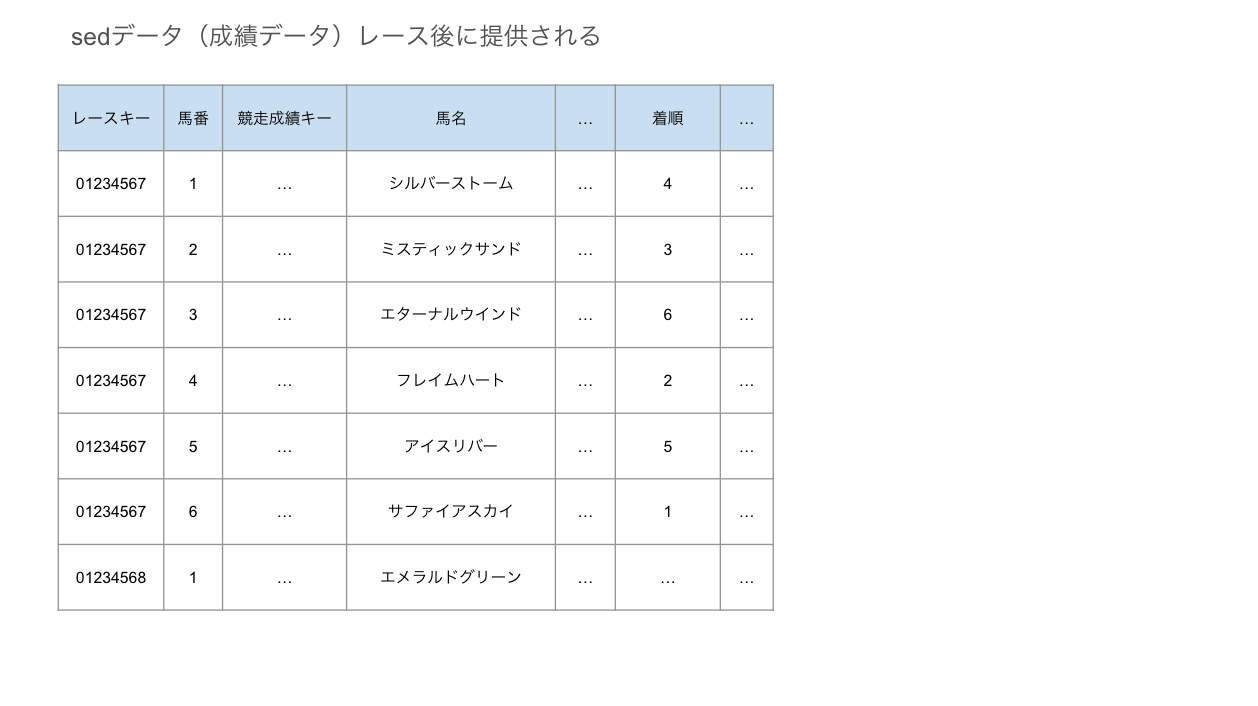
出走した馬ごとにレコードが登録されています。
【HJ】払い戻し情報データ
これはレースごとにいくら払い戻しがあったか書いてあります。
今回の目的変数でも説明変数でもないんですが、モデルで予測したあと、実際にお金をかけていたらいくらになるのか?を確認するのに使えそうです。
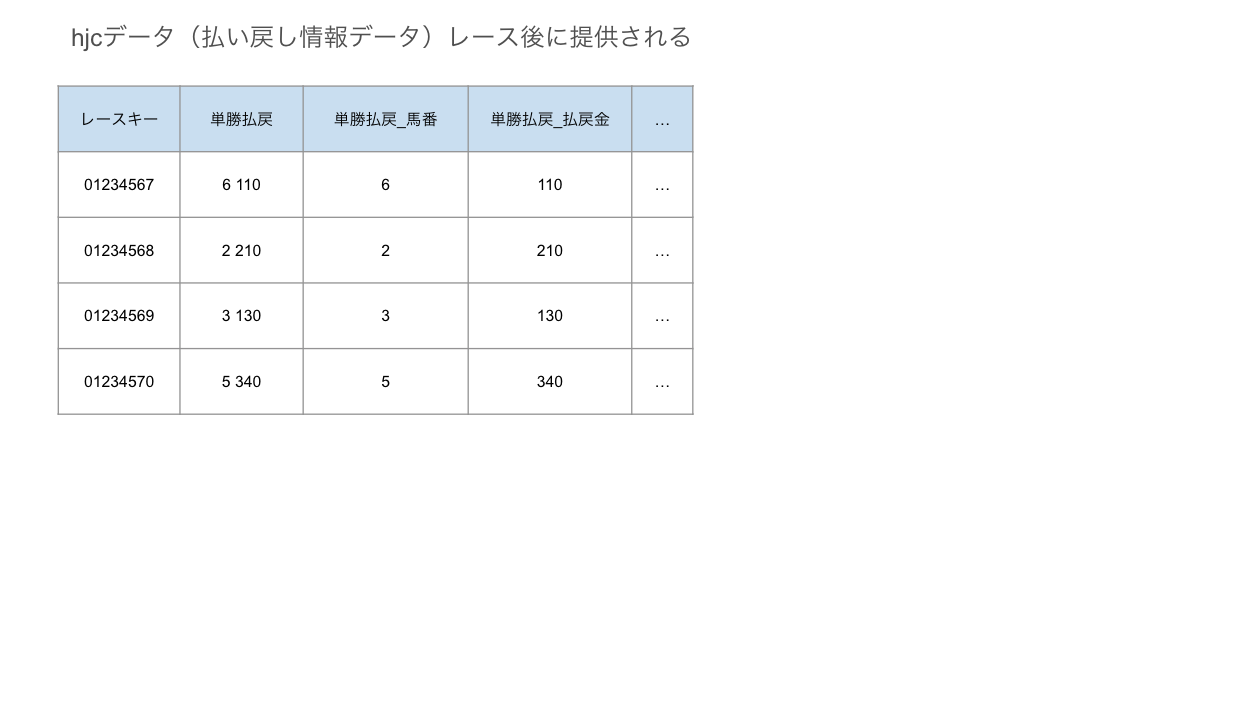
馬ごとではなく、レースごとにレコードが登録されています。
データのダウンロード
目星をつけた3つのデータについて、サイトからダウンロードします。
KYIデータ
http://www.jrdb.com/member/datazip/Kyi/index.html
「年度パックコーナー」に年単位でまとまっているものを一通りダウンロードします。
ファイル名:KYI_2022.zip〜KYI_1999.zip
※JRDB有料会員でないとダウンロードできません
↓このようにzipファイルが並んでいるので、クリックしてダウンロードします。

SEDデータ
http://www.jrdb.com/member/datazip/Sed/index.html
これも「年度パックコーナー」のデータをダウンロードします。
ファイル名:SED_2022.zip〜SED_1999.zip
※JRDB有料会員でないとダウンロードできません
HJCデータ
http://www.jrdb.com/member/datazip/Hjc/index.html
これも同様に、「年度パックコーナー」のデータをダウンロードします。
ファイル名:HJC_2022.zip〜HJC_1999.zip
※JRDB有料会員でないとダウンロードできません
データを格納
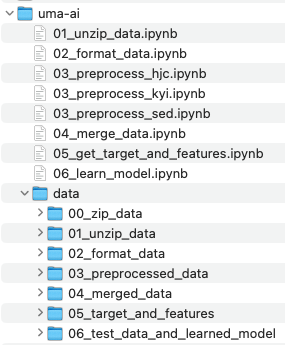
ダウンロードしたファイルは、uma-aiフォルダ内にこのように格納しました。
uma-aiフォルダ内にdataというフォルダを新しく作成して、
その中に「00_zip_data」「01_unzip_data」というフォルダを用意しました。
ダウンロードしたデータは、「00_zip_data」フォルダ内に個別に「hjc」「kyi」「sed」フォルダを作成して格納しています。
例えば、hjcフォルダの中はこんな感じで、ダウンロードしてきたファイルが入っています。kyiフォルダ、sedフォルダ内も同様にダウンロードしたファイルが入っています。
これらのデータを解凍して、「01_unzip_data」に格納しようと思います。
01. データを解凍する
ここから、ソースコードを書いて処理を実行していきます。
このセクションは「01_unzip_data.ipynb」に対応しています。
zipファイルを1つずつクリックして解凍してもいいのですが、ちょっとめんどくさいのでコードを書いて自動化しました。
「01_unzip_data.ipynb」を実行すると、「01_unzip_data」内に「hjc」「kyi」「sed」フォルダが作成され、それぞれの中に解凍したデータが格納されます。
02. データをフォーマットする
このセクションは「02_format_data.ipynb」に対応しています。
ダウンロードしたデータの確認
ダウンロードしたデータはこんな感じになっています。

このままだと何が何だかさっぱりなので、JRDBサイトに記載されているデータのフォーマットに従って、わかりやすい形式に整えます。
フォーマット
HJCデータ:http://www.jrdb.com/program/Hjc/hjcdata_doc.txt
KYIデータ:http://www.jrdb.com/program/Kyi/kyi_doc.txt
SEDデータ:http://www.jrdb.com/program/Sed/sed_doc.txt
例えばSEDデータの場合、先頭から8バイト目までが「レースキー」、その次の2バイトが「馬番」、その次の○バイトが〜といった具合に分割していけばいいみたいです。
改行があると次のレコードに移動して、またそのレコードの先頭から8バイト目までが「レースキー」、その次の2バイトが「馬番」、その次の○バイトが〜と続きます。
これを手動でやるのは不可能なので、コードを書いて自動化します。
フォーマットしたデータを格納するためのフォルダを用意します。
名前は「02_format_data」としました。
そして、新しいノートブックも作成します。
名前は「02_format_data.ipynb」としました。

データをフォーマットするためには、上に貼ったHJC,KYI,SEDそれぞれのフォーマットのルールを、ソースコード上で読み取れるような状態にしておく必要があります。
なので、あらかじめJson形式のファイルにフォーマットルールをまとめました。
「02_format_data」フォルダ内に「format_info」というフォルダを作成し、そこに格納しておきましょう。
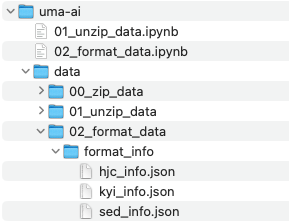
※この段階で、必要なさそうな特徴量については、それ以降のデータの容量や処理時間の縮小のためにフォーマットしないでデータから除外するようにしました。もし、全部のデータをフォーマットして処理を行いたい場合は、Githubに格納してある「~_full.json」という名前のJsonファイルを使用してください。ただ、これ以降の処理はfullじゃないJsonファイルでフォーマットした前提で書かれているため、処理を適宜追加する必要があります。
Jsonファイルも格納したら、「02_format_data.ipynb」を実行します。
「02_format_data」フォルダ内にフォーマットされたデータが出力されます。

03. 前処理を行う
このセクションは
「03_preprocess_hjc.ipynb」「03_preprocess_kyi.ipynb」「03_preprocess_sed.ipynb」
に対応しています。
データの中身を確認し、必要に応じて型を変換したり、欠損値を補完したりします。
前処理を行ったデータを保存するために、「03_preprocessed_data」フォルダを作成しておきます。
hjcデータの前処理
「03_preprocess_hjc.ipynb」ファイルを作成し、hjcデータの前処理を行います。

やっている処理としては、データの中身の確認と、型の変換です。
最初は全てのカラムがObject型になっているため、整数についてはint型に変換しています。
また、欠損値についても0に変換する処理を行っています。
各項目の意味についてはJRDBの仕様書を参照ください。
払戻情報データ仕様 第4版:http://www.jrdb.com/program/Hjc/hjcdata_doc.txt
「03_preprocess_hjc.ipynb」を実行すると、
「03_preprocessed_data」フォルダに前処理を実施したファイル「df_hjc.pkl」が生成されます。
kyiデータの前処理
hjcデータと同様にkyiデータも前処理を行っていきます。
「03_preprocess_kyi.ipynb」ファイルを作成します。
同じようにデータの中身を確認し、型の変換をしたり、欠損値を補完したりします。
各項目の意味についてはJRDBの仕様書を参照ください。
競走馬データ仕様 第11版:http://www.jrdb.com/program/Kyi/kyi_doc.txt
競走馬データ仕様書内容の説明:http://www.jrdb.com/program/Kyi/ky_siyo_doc.txt
JRDBデータコード表:http://www.jrdb.com/program/jrdb_code.txt
「03_preprocess_kyi.ipynb」を実行すると、
「03_preprocessed_data」フォルダに前処理を実施したファイル「df_kyi.pkl」が生成されます。
sedデータの前処理
sedデータも同様に前処理を行います。
「03_preprocess_sed.ipynb」ファイルを作成します。
同じようにデータの中身を確認し、型の変換をしたり、欠損値を補完したりします。
各項目の意味についてはJRDBの仕様書を参照ください。
競走馬データ仕様 第11版:http://www.jrdb.com/program/Kyi/kyi_doc.txt
競走馬データ仕様書内容の説明:http://www.jrdb.com/program/Kyi/ky_siyo_doc.txt
JRDBデータコード表:http://www.jrdb.com/program/jrdb_code.txt
「03_preprocess_sed.ipynb」を実行すると、
「03_preprocessed_data」フォルダに前処理を実施したファイル「df_sed.pkl」が生成されます。

04. データを結合する
このセクションは「04_merge_data.ipynb」に対応しています。
機械学習に使用するため、前処理を実施したデータを結合し、1つのデータにまとめます。
hjcデータは機械学習には使わないので、kyiデータとsedデータを結合していきます。
「04_merge_data.ipynb」ファイルを新しく作成します。
また、結合後のデータを保管する場所として「04_merged_data」フォルダを作成しておきます。

方針としては、kyiデータをベースに、そこにsedデータを結合していくようにしようと思います。
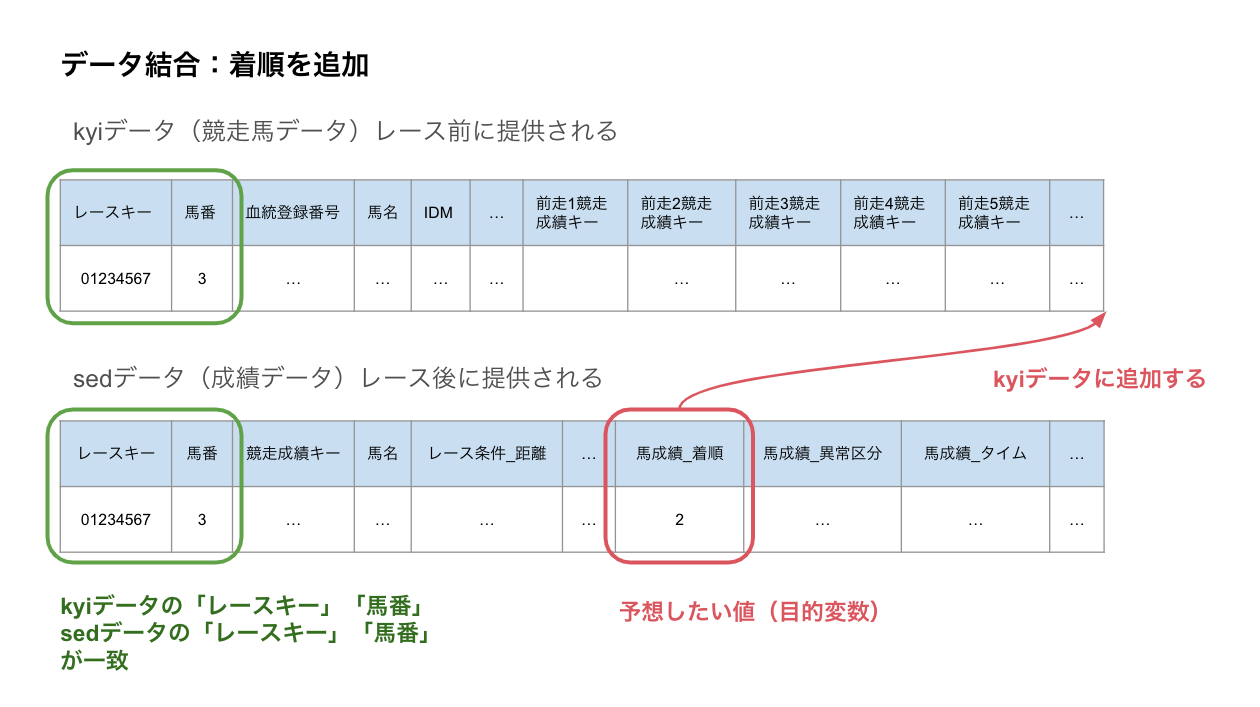
kyiデータに着順を追加
まずはkyiデータの各レコードに、その馬の着順のデータを追加していきます。
kyiデータの「レースキー」「馬番」に対して一致する sedデータの「レースキー」「馬番」を探します。
そのsedデータが、kyiデータ記載の馬のそのレースにおける成績になります。
図にするとこんなイメージです。
kyiデータに過去の成績データを追加
kyiデータには「前走1競走成績キー」〜「前走5競走成績キー」というカラムがあります。これもsedデータと対応しており、その馬の過去の成績になります。
例えばkyiデータ記載の馬の前走の成績は、kyiデータの「前走1競走成績キー」と一致する「競走成績キー」を持つsedデータの値になります。
図にするとこんなイメージです。
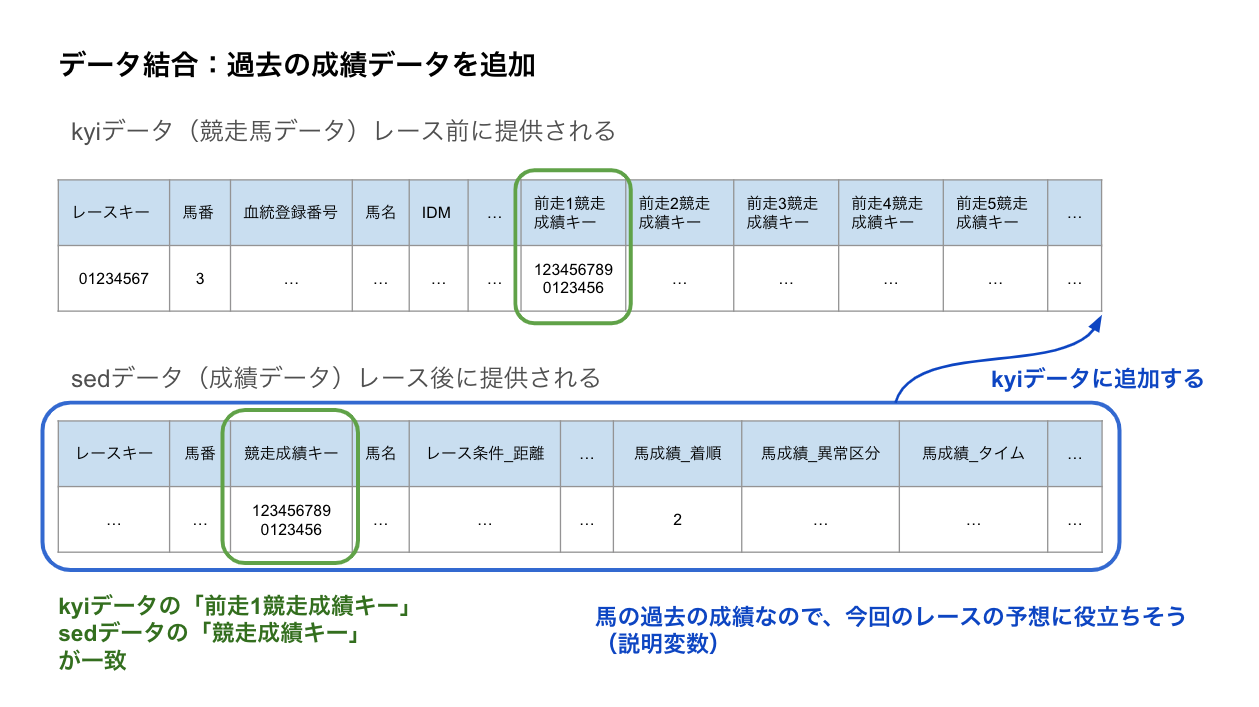
「前走2競走成績キー」〜「前走5競走成績キー」についても同様にsedデータと紐付けて結合していくと、最終的にはこんなデータを得ることができます。
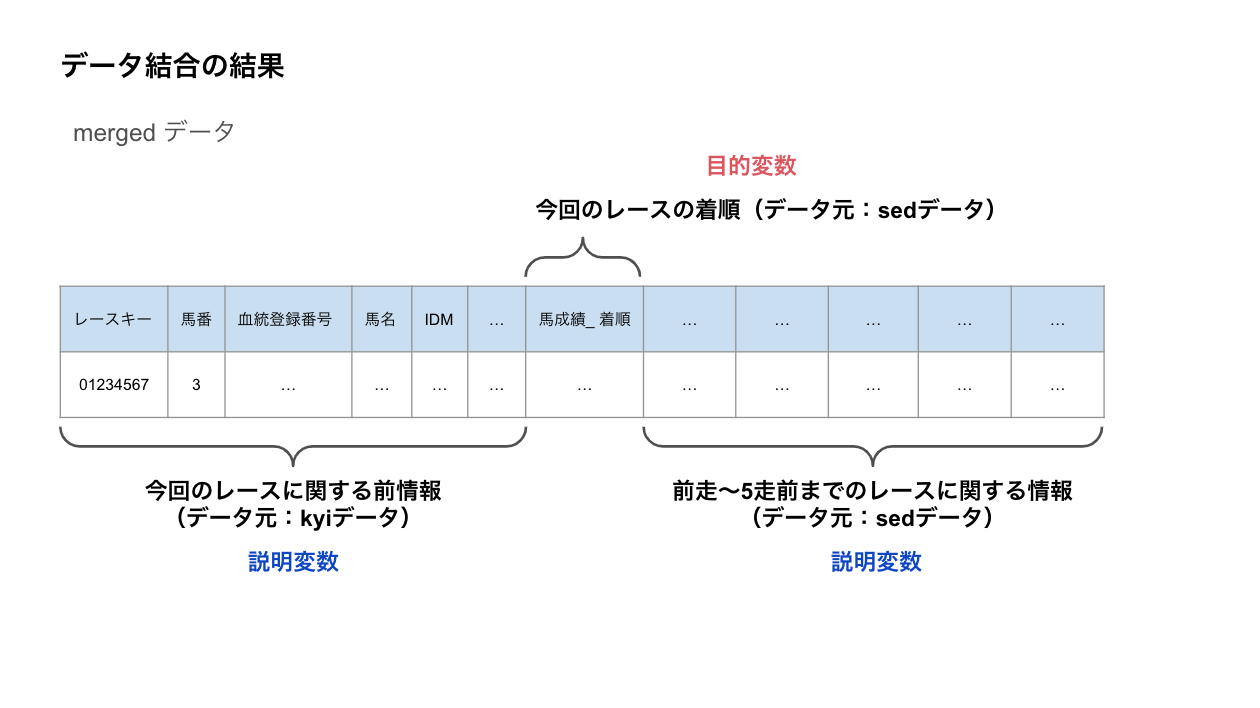
このデータには、以下の情報が含まれます。
・出走する馬の前情報(出典はkyiデータ)
・出走する馬の着順(出典はsedデータ)
・出走する馬の過去の成績(出典はsedデータ)
今回の機械学習モデルでは
着順 を予想したいので、これが目的変数になります。
前情報と過去の成績 は着順の予想に使えそうなので、これが説明変数になります。
より正確には、
着順カラムを参照して3着以内に入ったor入らなかったのバイナリ情報を表すカラムを作成し、それを目的変数として使用します。
また、前情報と過去の成績についてのカラム群の中から機械学習モデルに入力するカラムたちを選択し、それらを説明変数として使用します。
「04_merge_data.ipynb」を実行すると、「04_merged_data」フォルダに「df_merged.pkl」ファイルが生成されます。

05. 目的変数と説明変数を抽出する
このセクションは「05_get_target_and_features.ipynb」に対応しています。
結合したデータから、目的変数と説明変数を抽出します。
抽出後の目的変数データと説明変数データを格納するために「05_target_and_features」フォルダを作成しておきます。
また、処理を実行するための新しいノート「05_get_target_and_features.ipynb」を作ります。
データ抽出用のJsonファイルを生成する
データの中から、目的変数に使用するカラム および 説明変数に使用するカラム を抽出したいです。
しかし、いちいち全部のカラム対してどれが目的変数に使用するカラムで、どれが説明変数に使用するカラムで、どれが使用しないカラムで、と手作業で指定するのは結構大変です。
そのため、ある程度自動で指定するようにしました。
まず、データに含まれるカラムの一覧を作成し、Json形式で出力します。
その時に各カラムに対して以下のように”usage”という値を持たせます。
"usage"の値の意味:
- "target":目的変数として使用
- "feature":説明変数として使用
- "key":学習に使用しないが残しておきたいカラム
- null:学習に使用しない
この"usage"の値を参照して抽出処理を実行します。
"usage"の値はJsonファイル生成時に暫定値が自動で入るようになっています。なので、全部の値を手動で設定する必要はありません。
抽出処理を実行する前に、Jsonファイルを眺めて、"usage"の値を修正したいカラムがあったらそこだけ書き換えればOKです。
↓生成されるJsonファイルの先頭部分
{
"KYI_レースキー": {
"dtype": "object",
"nunique": 82829,
"usage": "key"
},
"KYI_馬番": {
"dtype": "int64",
"nunique": 18,
"usage": "feature"
},
"KYI_血統登録番号": {
"dtype": "object",
"nunique": 114141,
"usage": null
},
"KYI_馬名": {
"dtype": "object",
"nunique": 112067,
"usage": null
},
"KYI_IDM": {
"dtype": "float64",
"nunique": 777,
"usage": "feature"
},
"KYI_騎手指数": {
"dtype": "float64",
"nunique": 42,
"usage": "feature"
},
"KYI_情報指数": {
"dtype": "float64",
"nunique": 84,
"usage": "feature"
},
"KYI_予備1": {
"dtype": "object",
"nunique": 1,
"usage": null
},
ちなみに、"usage"の値の自動生成のルールは以下のとおりです。
"usage"の値の自動生成ルール:
- 引数 target_columns で指定したカラムは"target"が入ります
- 引数 key_columns で指定したカラムは"key"が入ります
- 型がobjectのカラムはnullが入ります
- 型がそれ以外のカラムは"feature"が入ります
※ "key"の意味について
"key"は学習に使用しないが残しておきたいカラムに対して設定します。
"KYI_レースキー"カラムを残しておきたかったので作りました。
残したい理由は、このカラムを使用してhjcデータを参照したいからです。
hjcデータには払戻金のデータが入っています。機械学習モデルでデータを予測した後の話になるのですが、もし予測が的中していた時、実際にどれくらいの利益になるのか、を計算するのに使用するため、ここで破棄せずに残しておきたいという意図があります。
目的変数と説明変数を抽出する
Jsonファイルに定義した情報に従って、目的変数と説明変数を抽出します。
なお、目的変数について、
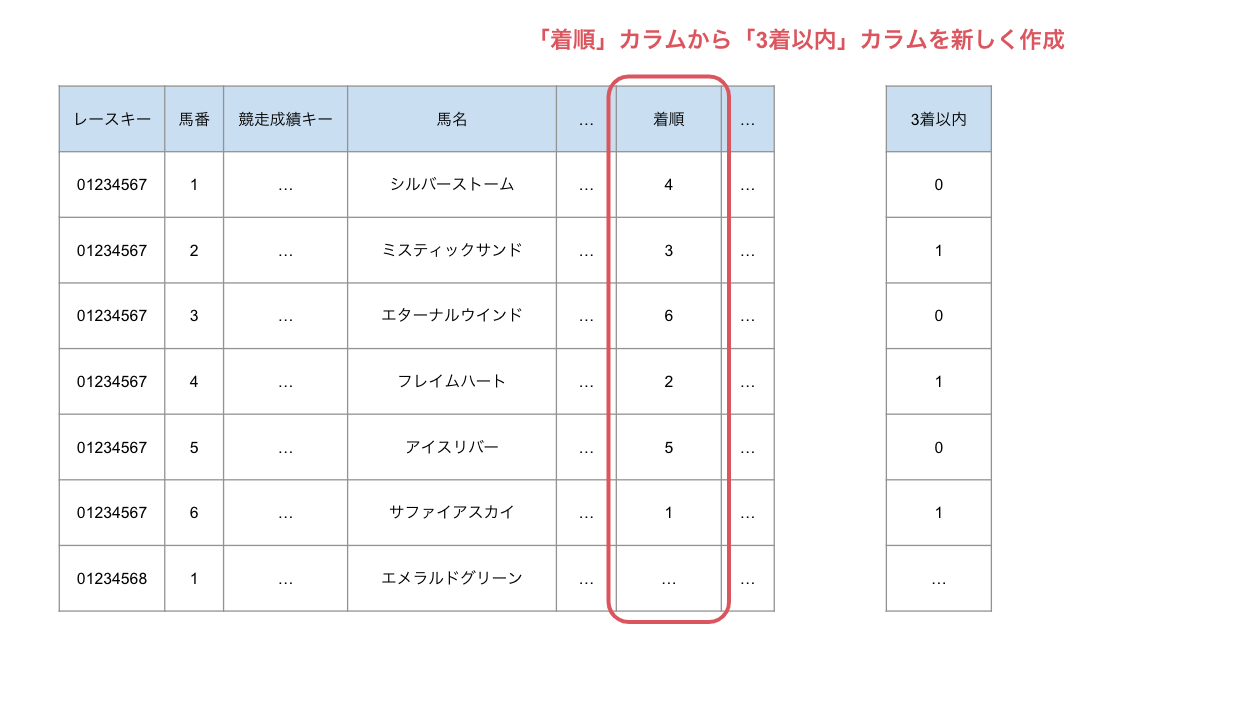
今回の機械学習では、馬が3着以内に入るか、入らないか、といういわゆる2値分類の問題を解こうとしています。
そのため、「着順」カラムを参照し、3着以内であれば1, それ以外であれば0の値を取るカラム「3着以内」を新しく作成しています。これを目的変数とします。
「05_get_target_and_features.ipynb」を実行すると、「05_target_and_features」フォルダに「columns_info.json」「df_features.pkl」「df_target.pkl」が生成されます。
06. モデルを学習する
このセクションは「06_learned_model.ipynb」に対応しています。
いよいよ、モデルを学習していきます。
学習したモデルや、テストデータを格納するために「06_testdata_and_learned_model」フォルダを作成しておきます。
また、処理を実行するための新しいノート「06_learned_model.ipynb」を作ります。
学習データとテストデータに分ける
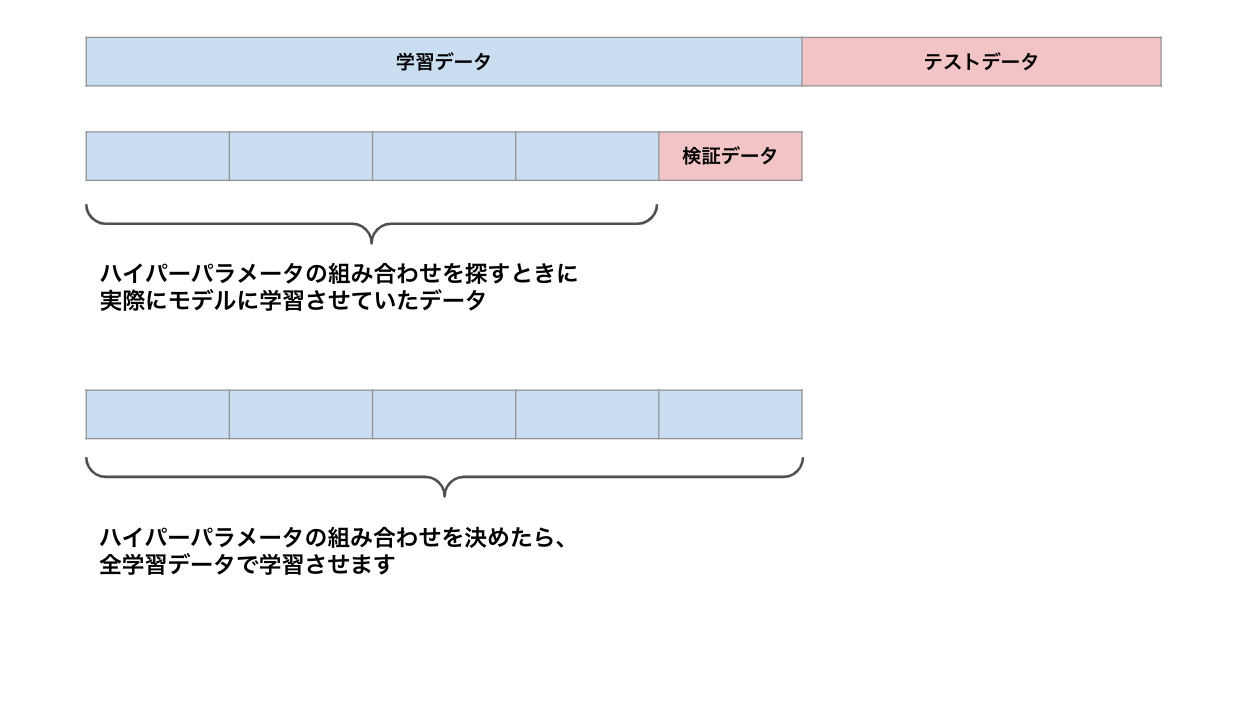
データを学習データとテストデータに分けます。
テストデータはモデルの最終的な性能の確認に使用するため、モデルの学習には使用しないようにします。
モデルの性能確認は次のノートで実施するため、テストデータはファイルに保存しておきます。

ハイパーパラメータのチューニング
機械学習モデルには、学習過程を制御する設定値があります。
いわゆるハイパーパラメータと呼ばれているものです。
LightGBMであれば、ソースコードに記載されているような、これらの値がハイパーパラメータです。
'num_leaves'
'learning_rate'
'n_estimators'
'verbosity'
LightGBMのハイパーパラメータは他にもたくさんあります。
詳細は公式ドキュメントを参照ください。
これらハイパーパラメータを適切な値に設定することが、モデルの性能の向上につながります。
そのため、値を色々変更してモデルを学習させ、それを評価してまた設定を変更して学習させ、、という試行錯誤が必要となります。
この作業のことをハイパーパラメータチューニングと呼びます。
今回のソースコードではどんな感じでハイパーパラメータのチューニングを実施しているか
グリッドサーチと交差検証の2つに焦点を当ててざっくり説明させていただきます。
グリッドサーチについて
今回はグリッドサーチという手法を用いています。
ソースコードのここの部分で設定しています。
grid = GridSearchCV(model, param_grid, cv=5, scoring='accuracy', verbose=3)
グリッドサーチとは、あらかじめハイパーパラメータの組み合わせを羅列しておき、その組み合わせでの中で一番性能の良い組み合わせを探す手法です。
図にするとこのようなイメージになります。
この図では、'num_leaves'というハイパーパラメータの候補として[30, 50, 100]を用意し、
'learning_rate'というハイパーパラメータの候補として[0.1, 0.05, 0.01]を用意しています。
そして、それらの組み合わせでモデルを学習させ、一番性能の良い組み合わせを探します。
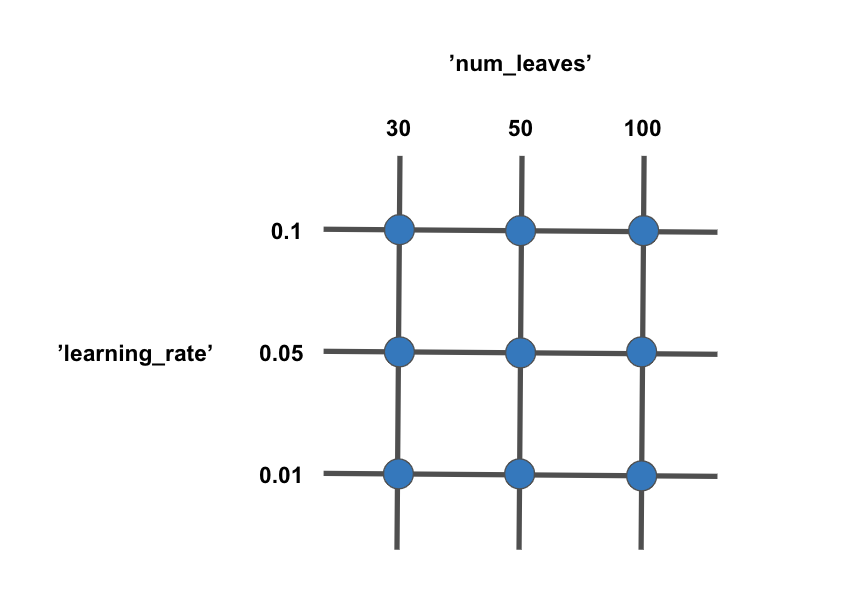
各ハイパーパラメータの候補値から形成される格子点(グリッド)の組み合わせを全部試す手法なので、グリッドサーチと呼ばれています。
今回のソースコードではこのような設定でグリッドサーチをしようとしています。
param_grid = {
'num_leaves': [30, 50, 100],
'learning_rate': [0.1, 0.05, 0.01],
'n_estimators': [100, 200, 500],
'verbosity': [-1] # 不要なログを抑制
}
verbosityについては不要なログを出さないようにするパラメータであり、1通りしか値を定義していないので無視するとして、'num_leaves', 'learning_rate', 'n_estimators'についてはそれぞれ3つの候補値を設定しています。
そのため、3 x 3 x 3 で、合わせて27通りの設定を試すことになります。
あえて図をイメージするとすれば、格子状の立方体の格子点の値を全部試す、という感じでしょうか。
いずれにせよ、あらかじめ設定した候補値の組み合わせを全部試して一番いい組み合わせを採用する、ということです。
交差検証について
グリッドサーチの設定の引数でcv=5というのがあります。
これは交差検証(Cross Validation)の分割数を設定しています。
この設定がどういう意味なのか、ざっくり説明させていただきます。
↓再掲:グリッドサーチの設定
grid = GridSearchCV(model, param_grid, cv=5, scoring='accuracy', verbose=3)
交差検証とは、モデルの性能をより正確に評価するための手法です。
例えば今回は、cv=5なので、学習データを5つのフィールドに分割し、そのうち4つのフィールでモデルを学習し、残りの1つのフィールドで評価を実施します。
4つで学習、残りの1つで評価、というプロセスを全てのパターンで実施します。
そうすると、5つのモデルが学習され、それぞれに対して評価をするので5つの評価(score)が出せます。
このscoreを平均したものを、そのハイパーパラメータで学習したモデルの性能の指標にします。
(繰り返しになるのですが、テストデータは学習には一切使用しないので、ここにおける検証データとは全く別物です。モデルの学習が終わるまで、テストデータはちぎってどこかにぶん投げておきましょう)

なんでこんな面倒なことをするかというと、次のようなメリットがあるとされているからです。
- 全てのデータが少なくとも1回はテスト用に使われるため、データの使用効率が良い
- データの偏りによる悪影響を軽減でき、モデルの一般化能力をより正確に評価できる
グリッドサーチと交差検証を組み合わせることで、
より性能の良いハイパーパラメータの組み合わせを探すような実装になっています。
ただ、デメリットとして、処理時間が多くなってしまうという点があります。
先に述べた通り、グリッドサーチで27パターンの組み合わせを試すのですが、そのそれぞれに対して交差検証で5つのモデルを学習させてその平均scoreを出しているので、27 x 5 = 135 回、モデルの学習を繰り返すことになります。
実際の出力ログを見てみるとこんな感じになっており、135回モデルを学習させていることがわかります。

もし学習が全然終わらない場合、グリッドサーチのパターン数を減らしたり、交差検証の分割数を少なくしたりする必要があるかもしれません。
全学習データでモデルを学習させる
ハイパーパラメータの組み合わせが決まったら、改めて全学習データでモデルを学習させます。
今まではハイパーパラメータの組み合わせを見つけるために、学習データから検証データを切り出していたため、
実際にモデルに学習させているデータは、検証データをのぞいたデータでした。
しかし、ハイパーパラメータを決めたら、もうscoreを算出するための検証データを切り出す必要はないので、全学習データを使ってモデルを学習させます。
(何度も繰り返しになりますが、ここでテストデータを含めた全データでモデルを学習させるのはNGです。テストデータに関しては最終的なモデルの性能評価に使うので、モデルの学習が終わるまで存在自体を忘れましょう。)
おまけとして、モデルの学習に寄与した特徴量を出力してみました。
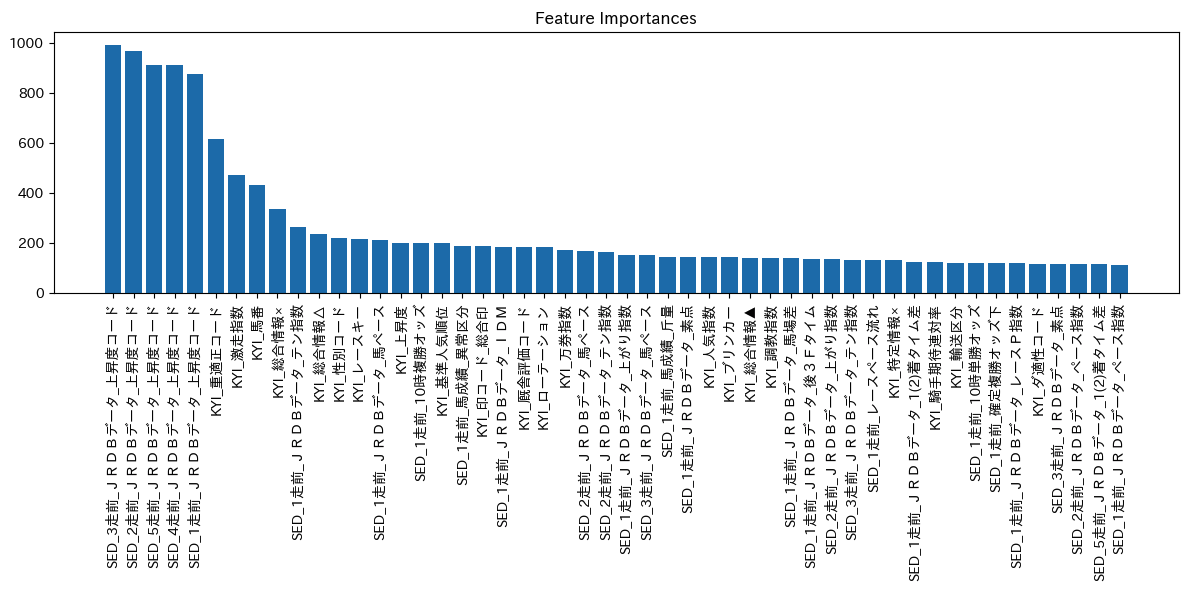
上昇度コードがかなり学習に寄与しているようです。
このグラフを眺めるだけでも色々発見がありそうですね。
「06_learned_model.ipynb」を全部実行し終えると、「06_target_and_features」フォルダに「best_lightgbm_model.pkl」「X_test.pkl」「y_test.pkl」が生成されているはずです。
07. モデルでテストデータの予想をする
このセクションは「07_predict_test_data.ipynb」に対応しています。
学習したモデルを使って、テストデータの予想をしてみます。
処理を実行するための新しいノート「07_predict_test_data.ipynb」を作ります。

テストデータの予想をしてみる
モデルでの予想の仕方は、ソースコードに書いてある通りです。
その結果は、精度0.81 でした。
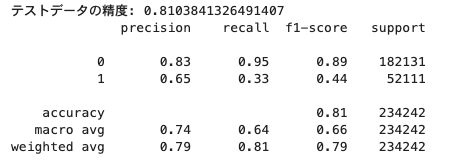
3着以内に入る、入らないについて、81%の確率で的中することができています。
私が想像してたよりも的中できてました。
馬券を買った場合の利益を調べる
では、実際に馬券を買ったらどれくらい儲かるの??というのが気になるところです。
機械学習モデルが3着以内に入ると予想した馬に対して、複勝100円を買う、というルールで運用してみましょう。
hjcデータを読み込むことで払戻金を調べます。そして利益を計算してグラフにしてみると、、
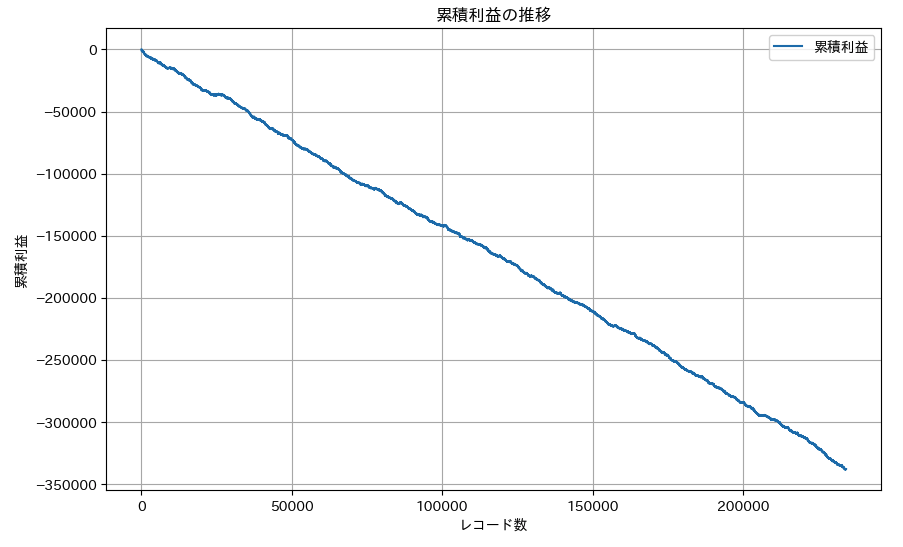
すごいマイナスでした笑
モデルの精度は80%を超えているので、そこそこ的中はするのですが、オッズが低く、当たったとしても100円が130円になって30円しか利益が出ない、ということがザラでした。
一方、馬券を外してしまうとマイナス100円なので、一発外した時のマイナスが大きく、的中した馬券でそれを取り返すことができていないようです。
あとがき
普段はWebエンジニアとして働いており、機械学習モデルを作成する機会はほぼないので実装が楽しかったです。
思っていたよりも的中できるモデルが生成できた点では満足でした。
ただ、利益を出そうとするとなかなかうまくはいかないみたいです。
モデルの改良の余地はまだまだたくさんあるので、色々試してみたいなと思いました。
- 騎手や調教師の情報も使って学習してみる
- LightGBM以外のモデルを使ってみる
- 特定のレース場のみ、芝コースのみ、など条件を絞って学習してみる
など
謝辞:ここまで読んでくださってありがとうございました!