(20/11/14 追記)
Tensorflowv2以降だと動作しなかったので、v2で動作するように修正しました。
https://github.com/sey323/tf-gan
概要
前回の記事ではGANを使った顔生成のプログラムを作成した.GANでは入力されたノイズに応じてランダムに画像を生成するため,例えばAさんの顔に似た画像を生成したいという時に,Aさんに似た画像を生成できるかは確率的になってしまう,という欠点がある.
そこで今回は,GANに教師ラベルを付与することで生成する画像の対象を制限(Condition)するGAN,ConditionalGAN(cGAN)を作成し実験する.
前回の記事はこちら
ソースコードの全体像は以下のリンクから
GitHub - sey323/tf-gan: tensorflowでGAN
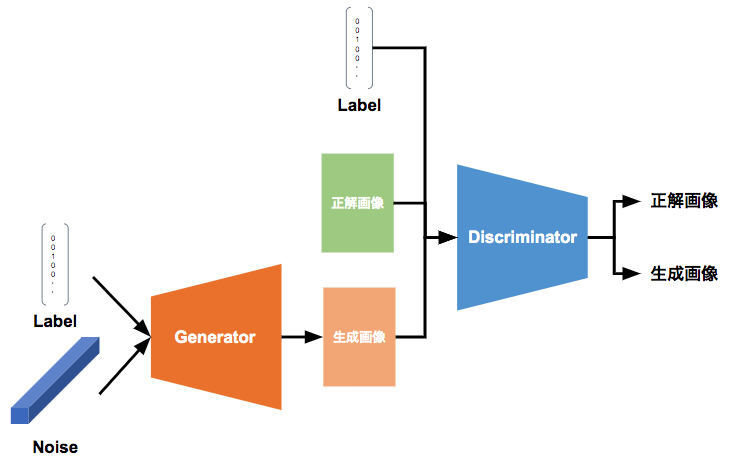
ConditionalGANの作成
全体的な構造は前回作成した前回作成したものと変化は少ない.
今回のCGANの作成では,それに加えてGeneratorとDiscriminatorに画像のクラスラベルの情報を入力する部分を追加する.
__init__では前回作成したGANのモデルを継承し,cGANで用いるラベル情報をlabel_numとして定義する。
class cGAN( GAN ):
'''
ConditionalGANの基本クラス
'''
def __init__(self ,
input_size,
label_num, #CGAN追加分
channel= 3,
layers = [ 64 , 128 , 256],
filter_size = [ 5 , 5 ],
drop_prob = 0.5,
zdim = 100,
batch_num = 64,
learn_rate = 2e-4,
max_epoch = 100,
gpu_config = tf.GPUOptions(per_process_gpu_memory_fraction=1.0) ,
save_folder = 'results/GAN' ):
Generatorの構築
CGANのGeneratorでは、生成したい対象のクラスラベルをノイズに加算してGeneratorのネットワークに入力する.ラベルとノイズの結合にはtf.concat()の関数を用いる.
それ以外はGANのネットワーク構造と変化はない.
def ConditionalGenerator(
self,
input,
label,
layers,
output_shape,
channel=3,
filter_size=[3, 3],
reuse=False,
):
'''
Generator
'''
print('[NETWORK]\tNoise Conditional Generator')
# ノイズにラベルを加算
concat_input = tf.concat([input, label], axis=1, name="concat_z")
with tf.compat.v1.variable_scope("Generator", reuse=reuse) as scope:
if reuse:
scope.reuse_variables()
# 逆FC
with tf.compat.v1.variable_scope("Fc{0}".format("")) as scope:
dim_h, dim_w = imutil.calcImageSize(
self.input_size[0],
self.input_size[1],
stride=2,
num=len(self.layers),
)
# 1層目
defc_1 = layer.defc(
input,
output_shape=[
dim_h,
dim_w,
],
output_dim=self.layers[-1],
name="defc",
)
before_output = defc_1
# Deconv層
for i, input_shape in enumerate(reversed(self.layers)):
# 初期情報
layer_no = len(self.layers) - i
output_dim = self.layers[layer_no - 1]
output_h, output_w = imutil.calcImageSize(
self.input_size[0], self.input_size[1], stride=2, num=layer_no
)
logging.debug(
"[OUTPUT]\t(batch_size, output_height:{0}, output_width:{1}, output_dim:{2})".format(
output_h, output_w, output_dim
)
)
# deconv
with tf.compat.v1.variable_scope(
"deconv_layer{0}".format(layer_no)
) as scope:
deconv = layer.deconv2d(
before_output,
stride=2,
filter_size=[self.filter_size[0], self.filter_size[1]],
output_shape=[output_h, output_w],
output_dim=output_dim,
batch_norm=True,
name="Deconv_{}".format(layer_no),
)
before_output = layer.ReLU(deconv)
# Outputで画像に復元
output = self.output_layer(before_output, channel=channel)
return output
Discriminatorの構築
cGANのDiscriminatorでは,生成されたor正解画像に対してクラスラベルを付与したものをネットワークに入力し,その画像が生成された画像か正解画像かを識別する.結合の際には,one-hot形式のクラスラベルを入力画像の縦横のサイズに合わせて$H \times W \times 1$の形式に行列変換し,それを入力画像に結合する.
それ以外はGANのネットワークと変更はない.
def ConditionalDiscriminator(self,y,label,channel=3,reuse=False):
'''
Discriminator
'''
print('[NETWORK]\tNoise Conditional Discriminator')
label_num = label.get_shape()[-1]
# クラスラベルを入力画像に加算する処理
with tf.compat.v1.variable_scope("Noise_Concat", reuse=reuse) as scope:
if reuse:
scope.reuse_variables()
label = tf.reshape(label, [-1, 1, 1, label_num])
output_shape = tf.stack(
[
tf.shape(input)[0],
tf.shape(input)[1],
tf.shape(input)[2],
label_num,
],
)
k = tf.ones(output_shape) * label
concat_input = tf.concat([input, k], axis=3)
with tf.compat.v1.variable_scope("Discriminator" + name, reuse=reuse) as scope:
if reuse:
scope.reuse_variables()
for i, output_shape in enumerate(self.layers, 1):
if i == 1: # 1層目の時だけ
before_output = input
# conv
with tf.compat.v1.variable_scope("conv_layer{0}".format(i)) as scope:
conv = layer.conv2d(
input=before_output,
stride=2,
filter_size=[self.filter_size[0], self.filter_size[1]],
output_dim=output_shape,
batch_norm=True,
name="Conv_{}".format(i),
)
conv = layer.leakyReLU(conv)
before_output = conv
return before_output
損失関数,最適化関数
損失関数,最適化関数はGANのものと変更は無し.
"""損失関数の定義"""
logging.info("[BUILDING]\tLoss Function")
self.g_loss = loss_function.cross_entropy(
x=self.d_fake,
labels=tf.ones_like(self.d_fake),
name="g_loss_fake",
)
self.d_loss_real = loss_function.cross_entropy(
x=self.d_real,
labels=tf.ones_like(self.d_real),
name="d_loss_real",
)
self.d_loss_fake = loss_function.cross_entropy(
x=self.d_fake,
labels=tf.zeros_like(self.d_fake),
name="d_loss_fake",
)
self.d_loss = self.d_loss_real + self.d_loss_fake
"""最適化関数の定義"""
logging.info("[BUILDING]\tOptimizer")
self.g_optimizer = optimizer.adam(self.g_loss, self.learn_rate, "Generator")
self.d_optimizer = optimizer.adam(self.d_loss, self.learn_rate, "Discriminator")
学習
学習では,正解画像とその画像の人物を示すクラスラベルであるbatch_labelsを学習の入力に与えている.batch_labelsは学習データの各顔画像のラベルのone-hot表現が格納されている.
テスト用の画像を生成する際のラベルは6行目以降で作成している.バッチ枚数分,0から順番に1,2,3・・・とone-hot表現のベクトルを作成する.
# 画像を生成するラベルの作成.
self.test_code = []
for i in range(self.batch_num):
tmp = np.zeros( self.label_num )
tmp.put(i%self.label_num, 1)
self.test_code.append(tmp)
全体像は以下の通り.
def train(self, batch_o ):
self.build_model()
initOP = tf.global_variables_initializer()
self.sess.run(initOP)
# 画像を生成するラベルの作成.
self.test_code = []
for i in range(self.batch_num):
tmp = np.zeros( self.label_num )
tmp.put(i%self.label_num, 1)
self.test_code.append(tmp)
step = -1
time_history=[]
start = time.time()
while batch_o.getEpoch()<self.max_epoch:
step += 1
batch_images,batch_labels = batch_o.getBatch(self.batch_num)
batch_z = np.random.uniform(-1.,+1.,[self.batch_num,self.zdim]).astype(np.float32)
# update generator
_,d_loss,y_fake,y_real,summary = self.sess.run([self.d_optimizer,self.d_loss,self.y_fake,self.y_real,self.summary],feed_dict={self.z:batch_z, self.label:batch_labels, self.y_real:batch_images})
_,g_loss = self.sess.run([ self.g_optimizer , self.g_loss ] , feed_dict={ self.z:batch_z , self.label:batch_labels })
if step>0 and step%10==0:
self.writer.add_summary( summary , step )
if step%100==0:
train_time = time.time()-start
time_history.append({"step":step , "time":train_time})
print("%6d: loss(D)=%.4e, loss(G)=%.4e; time/step = %.2f sec"%(step,d_loss,g_loss,train_time))
z1 = np.random.uniform(-1,+1,[ self.batch_num , self.zdim ])
z2 = np.random.uniform(-1,+1,[ self.zdim ])
z2 = np.expand_dims( z2 , axis = 0 )
z2 = np.repeat( z2 , repeats = self.batch_num , axis = 0 )
g_image1 = self.sess.run(self.y_sample,feed_dict={self.z:z1,self.label:self.test_code})
g_image2 = self.sess.run(self.y_sample,feed_dict={self.z:z2,self.label:self.test_code})
cv2.imwrite(os.path.join(self.save_folder,"images","img_%d_real.png"%step),imutil.tileImage( y_real , size = self.label_num) * 255.+128.)
cv2.imwrite(os.path.join(self.save_folder,"images","img_%d_fake1.png"%step),imutil.tileImage( g_image1 , size = self.label_num) * 255.+128.)
cv2.imwrite(os.path.join(self.save_folder,"images","img_%d_fake2.png"%step),imutil.tileImage( g_image2 , size = self.label_num) * 255.+128.)
self.saver.save(self.sess,os.path.join(self.save_folder,"model.ckpt"),step)
start = time.time()
実験
学習の実行
データセットは前回と同様にfacescrubのハリウッド俳優の画像データセットを使う.
$ python train.py --type=cgan --folder=face --batch_size=25
[LOADING] model parameters loding
[LOADING] Label0 Name:Alan_Alda Pictures exit. Unit On 111
[LOADING] Label1 Name:Alan_Rickman Pictures exit. Unit On 119
[LOADING] Label2 Name:Adam_McKay Pictures exit. Unit On 45
libpng warning: iCCP: known incorrect sRGB profile
[LOADING] Label3 Name:Al_Pacino Pictures exit. Unit On 102
[LOADING] Label4 Name:Adrien_Brody Pictures exit. Unit On 113
[LOADING] Label5 Name:Adam_Sandler Pictures exit. Unit On 95
[LOADING] Label6 Name:Alec_Baldwin Pictures exit. Unit On 125
[LOADING] Label7 Name:Aaron_Eckhart Pictures exit. Unit On 117
[LOADING] Label8 Name:Alan_Arkin Pictures exit. Unit On 94
[LOADING] Label9 Name:Adam_Brody Pictures exit. Unit On 107
[LOADING] Conditional GAN
[BUILDING] Generator
[NETWORK]
Noise Conditional Generator
[NETWORK]
Noise Conditional Generator
[BUILDING] Discriminator
・
・
・
結果
実験結果を以下に示す.
学習回数100回

学習回数1000回

学習回数2000回

学習回数3000回

学習回数5000回

画像の縦の列は同じラベルを表すベクトルを入力し,ラベル以外はランダムなノイズを入力している.理想は,縦列に同じ人の様々なアングルや表情の顔画像が生成されれば成功となる.
3000回目の画像を見ると,左から5番目の列の人はヒゲが生えているなど,人を区別して生成はできているがGANのものより解像度は落ちている.
5000回目の画像を見ると,ラベルによる人の顔を区別可能な画像を生成できているが,異なるノイズで同じ顔の画像を生成してしまっている.学習データが1人あたり100枚前後しかないので過学習してしまったようだ.
やっぱり学習画像の枚数って大事.
終わりに
GANの学習に制限付きラベルを加えることで生成する人物を指定して顔画像を生成することが可能になった.
因みにこのノイズのコントロールによりGANで生成する対象を制限する考え方は,今後のPIX2PIXやCycleGANにも影響を与えているよう.
気力があれば次はPIX2PIXあたりを作りたいですね.