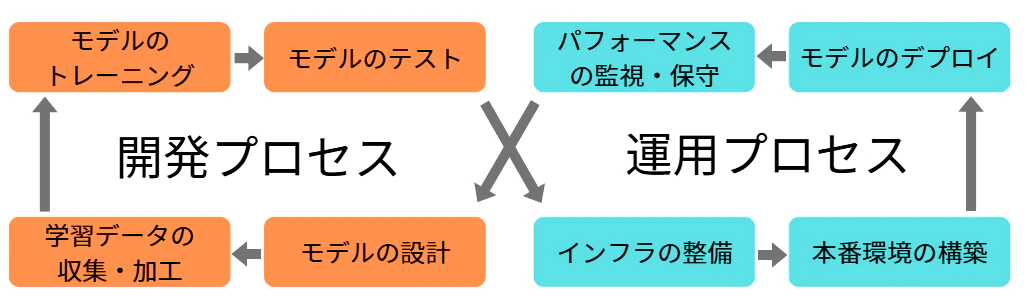
MLOpsってなんやねん。
MLOpsの概要記事は巷にたくさんあるのですがどれもプロダクションレベルの印象がありました。
今回私はMLOpsの一連の流れや雰囲気を掴みたいだけだったので、とても小さな規模であえてコードからやってみました。そのため、完全な運用プロセスまでは行っていません。MLOpsと呼んでいいのかわからない、MLぉ...くらいです。ご了承ください(_ _)
ちなみに「MLOpsとは〜?」系の記事はこちらがおすすめ
事前準備
MLOpsを構築する前に必要な準備やサービスを整理します。
使用したデータ
ビッグデータが欲しかったので以前参加したSIGNATE機械学習Beginnersコンペのデータで試してみます。テーマは「国勢調査のデータから対象データの年収を分類予測する」というよくある内容です。
使用した機械学習モデル
本投稿の内容には直接関係ないため簡単にしか記載しませんが、機械学習モデルには LightGBM モデル を使用しました。
MLOpsの状態がわかりやすくなるよう、LightGBMモデルのパラメータや訓練のコーディングだけ簡単に記載しておきます。(環境設定・データの前処理・特徴量の追加などは省略)
import lightgbm as lgb
# データ準備
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
# LightGBMを使用
train_data = lgb.Dataset(X_train, label=y_train)
val_data = lgb.Dataset(X_val, label=y_val, reference=train_data)
# パラメータ
params = {
'objective': 'binary', # 二値分類
'metric': 'binary_error', # 評価指標
'boosting_type': 'gbdt', # 勾配ブースティング
'num_leaves': 31, # 木の葉の数
'learning_rate': 0.05, # 学習率
'feature_fraction': 0.9 # 特徴量のサンプル
}
# モデルの訓練
evals_result = {} # 訓練結果
gbm = lgb.train(
params,
train_data,
valid_sets=[train_data, val_data], # 訓練データと検証データ
valid_names=['train', 'val'],
num_boost_round=500, # 最大反復回数
callbacks=[
lgb.early_stopping(stopping_rounds=50), # early_stoppingを使用
lgb.record_evaluation(evals_result)
]
)
使用サービス
Google Colab / Jupyter Notebook(環境)
機械学習の処理があるためGPUをさくっと使用したく、今回はGoogle Colabで試しました。
MLflow(フレームワーク)
MLflowは Databricks社が開発した機械学習モデルのライフサイクルを管理するために設計されたオープンソースのフレームワーク です。
MLflowを使うことで、機械学習モデルのトラッキング、バージョン管理が簡単にできます。
今回は、機械学習モデルのパラメータを記録して比較できるように使用します。
ngrok(トンネリングツール)
ローカル環境では以下を実行するだけで、MLflowのWeb UIにアクセスできます。
!mlflow ui
ただし、Google Colabのようなクラウド環境では内部でサーバーを起動してもポートが閉じられているため、そのままでは外部のブラウザからアクセスすることができません。
そこで使用するのが ngrok です。
これは、ローカル環境で立ち上げたWebサーバーを、インターネット経由でアクセス可能にするトンネリング/リバースプロキシツールです。
後ほどngrokのトークンが必要になるので、あらかじめ会員登録を済ませておきます。
GoogleアカウントかGitHubアカウントで無料ですぐに作成できます。
下記Authtokenから自分のトークンを取得できます。

私自身今回初めてngrokを使いましたが、使い方に関する解説記事はQiitaやZennにも多くありますので、随時参照してください。
MLOpsの構築
ここから本題のMLOps構築について、書いていきます。
1. 必要なライブラリのインポート
まずは、Google Colab上でMLflowとngrokを使う準備です。
必要なライブラリをインストールします。
# MLflow
!pip install mlflow
# ngrok
!pip install pyngrok
次に、インストールしたライブラリをインポートします。
# MLflow本体とLightGBM用モジュール
import mlflow
import mlflow.lightgbm
# ngrokの制御用
from pyngrok import ngrok
# サーバー起動用にsubprocessも使用
import subprocess
2. MLflow UIを使えるようColab上での設定
事前準備で取得しておいたngrokのトークンを使用し、MLflow UIを外部からアクセスできるようにします。
# ngrokの認証トークンを設定
ngrok.set_auth_token('ここに取得したトークンをペースト')
# MLflow UIをバックグラウンドで実行
subprocess.Popen(["mlflow", "ui", "--host", "0.0.0.0", "--port", "5000"])
# ngrokで5000ポートにトンネルを作成
public_url = ngrok.connect(5000)
print(f"MLflow UI is available at: {public_url}")
これにより、MLflow UI のローカルサーバー(Colab内部で動いている)を ngrok を使ってインターネットに公開できます。
出力された public_url にアクセスすれば、ブラウザから MLflow のUIに接続できます。
3. 新しいMLflowのRunを実行
以下は、LightGBM モデルの訓練とその記録処理です。mlflow.start_run() を使うことで、学習中のパラメータやメトリクスを記録し、モデルも一緒に保存できます。
#トラッキングサーバーのURIを設定(Colab内のlocalhost)
mlflow.set_tracking_uri("http://localhost:5000")
# ログ記録
with mlflow.start_run():
# LightGBMの訓練
gbm = lgb.train(
params,
train_data,
valid_sets=[train_data, val_data],
valid_names=['train', 'val'],
num_boost_round=500,
callbacks=[
lgb.early_stopping(stopping_rounds=50),
lgb.record_evaluation(evals_result)
]
)
# モデルの入力例を指定(※X_trainから1行を抽出)
input_example = pd.DataFrame(X_train.iloc[0]).T
# モデルをMLflowに保存
mlflow.lightgbm.log_model(gbm, "lightgbm_model", input_example=input_example)
# パラメータを記録
for param, value in params.items():
mlflow.log_param(param, value)
# メトリクスを記録
mlflow.log_metric("best_iteration", gbm.best_iteration)
mlflow.log_metric("train_error", evals_result['train']['binary_error'][gbm.best_iteration])
mlflow.log_metric("val_error", evals_result['val']['binary_error'][gbm.best_iteration])
with を使っているため、ブロックが終了すると mlflow.end_run() が自動で呼ばれます。
3の補足:input_example を指定する理由
以下のコードは、MLflow にモデルを保存する際に、入力データの構造を自動推測させるためのものです。
input_example = pd.DataFrame(X_train.iloc[0]).T
この行のコードを書いていなかった際、以下の警告が起きていました。
mlflow.models.model: Model logged without a signature and input examplez
これは、MLflowがモデルにどんな形式の入力が必要かを正しく認識できなかったことを意味しているそうです。
動作に直接影響はしませんが、モデルを再利用・配布する場合などには input_example を指定しておくことをおすすめします。
4. MLflow UIを確認する。
あとは3で取得したURLで、MLflow UIを確認できます。
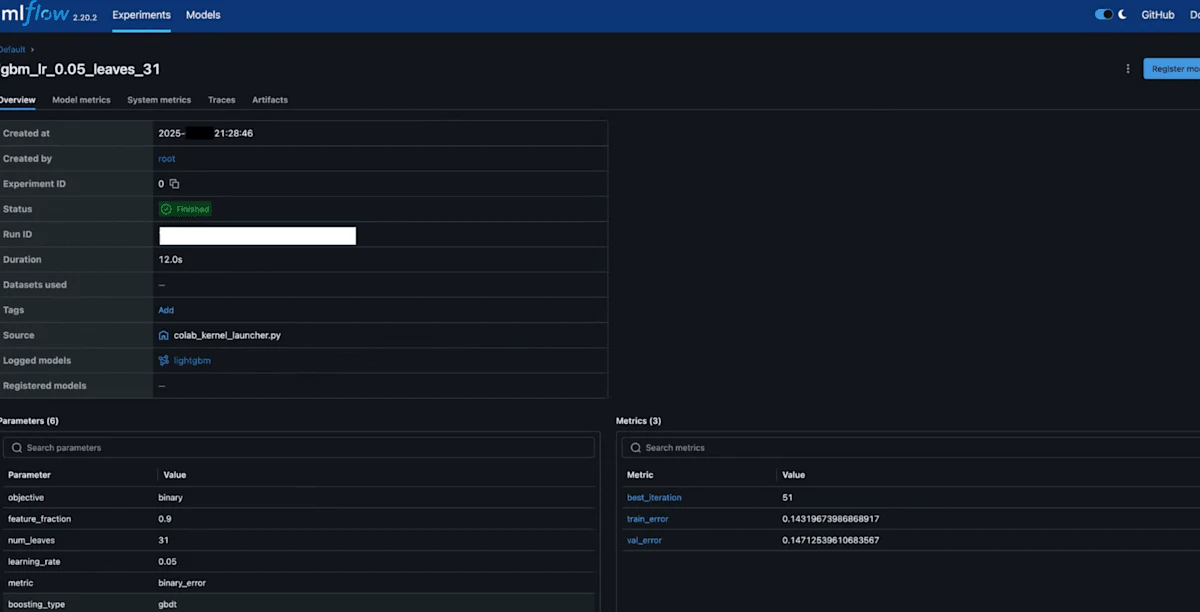
こちらはMLflowのOverView画面。かっこよい。
今回のMLOps(MLFlow)からわかること
それではMLflowのModel metricsの画面を見ていきます。
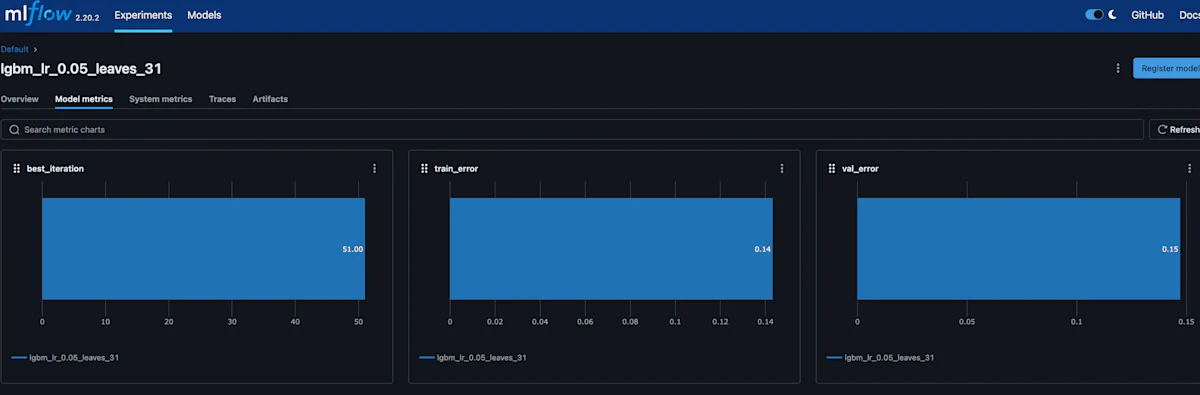
重みが更新された回数(best_iteration)
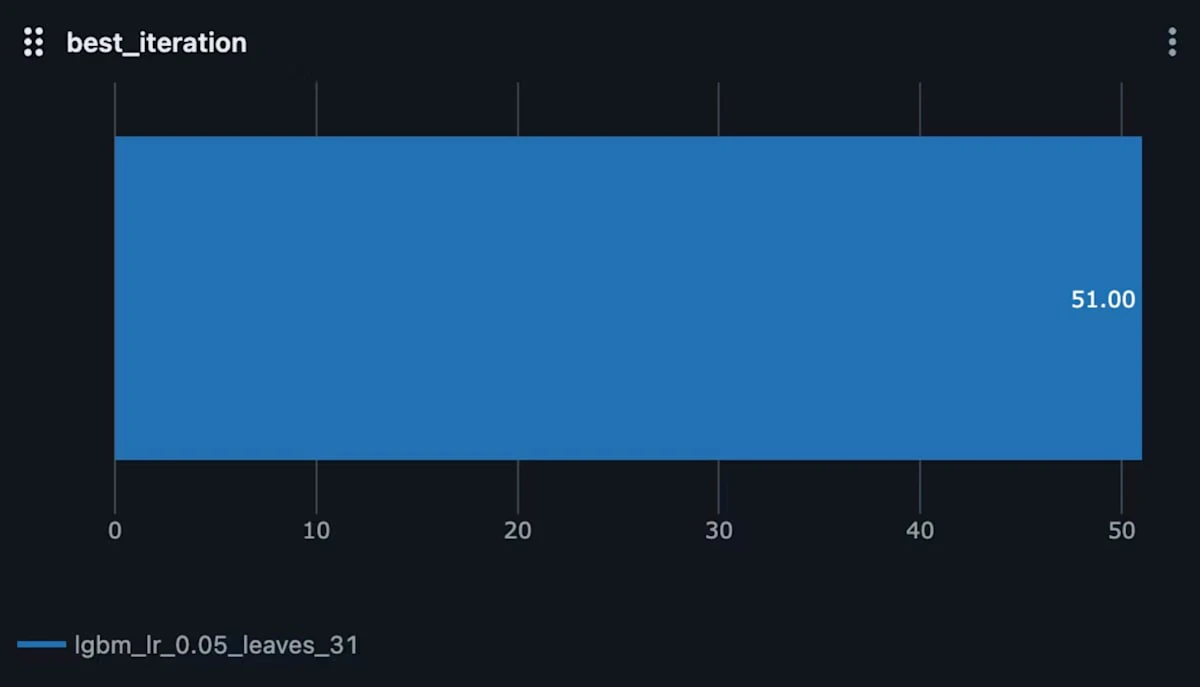
こちらは最も良いパフォーマンスを発揮した 訓練の重みが更新された回数(イテレーション) です。
この場合、51が表示されているので、訓練の途中で早期停止(early stopping)が適用され、最もパフォーマンスが良かったのは51回目のイテレーションであったことを示しています。
1つしか値を得てないグラフに意味はあるのか?とかはさておき、このモデル使用時に工夫していた点の1つだったため、それが可視化できたのは嬉しいですね。
訓練データに対するエラー率(train_error)
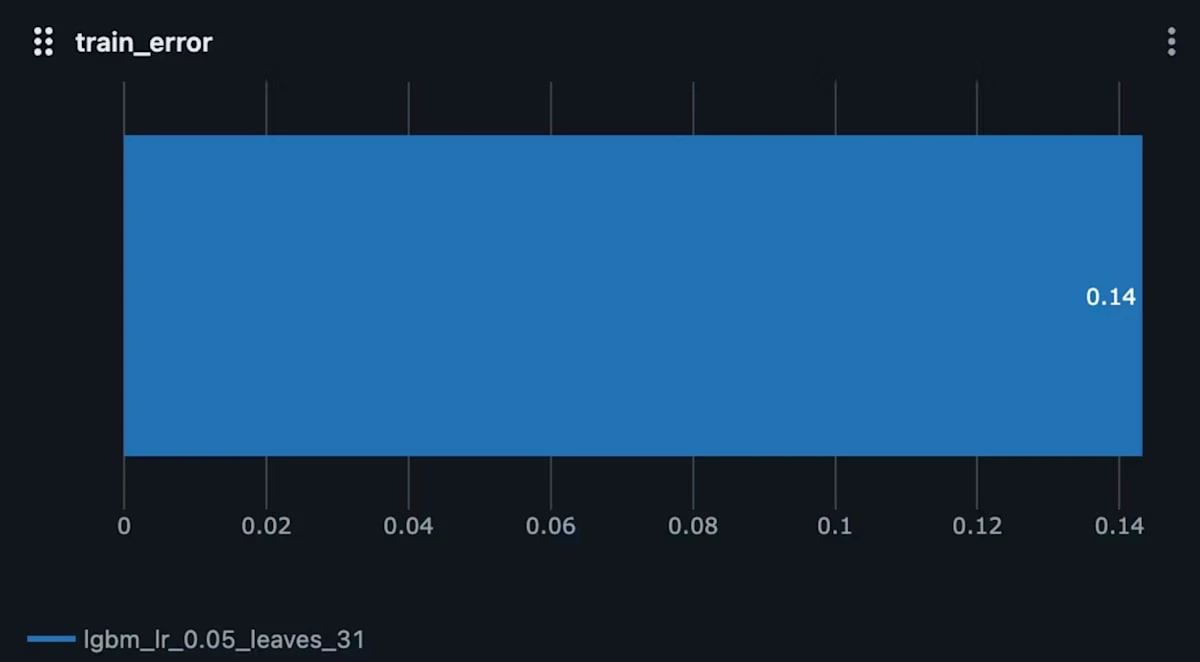
次は 訓練データに対するエラー率(binary_error) です。
ここでは train_error = 0.14 となっており、訓練データに対する予測の誤りが約14%であることを示しています。
訓練データに対してモデルが約86%の精度ということで、訓練誤差は比較的低くモデルは訓練データにうまく適合していると解釈できます。
検証データに対するエラー率(val_error)
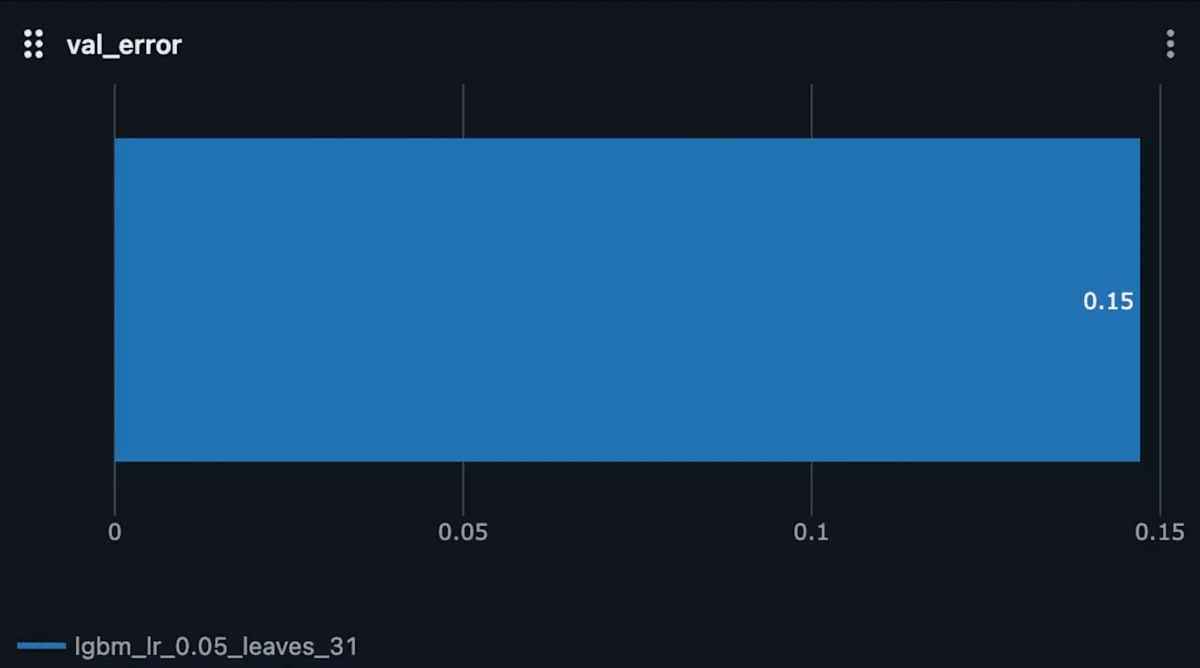
最後に 検証データに対するエラー率(binary_error) です。
ここでは val_error = 0.15 となっており、検証データに対する予測の誤りが約15%であることを示しています。
検証データに対してもモデルは約85%の精度で予測しているということですが、訓練データに対する誤差と比較すると若干誤差が増えているため、モデルが多少過学習している可能性もありそうです。
MLOpsを組み込むメリット
ここまではかっこいい感じですが、正直MLOpsを使用せずとも確認できる範囲です。
では、今回MLOpsを機械学習モデルに導入すると何がいいのか?というと、
「モデルのパラメータ・メトリクスの変化による比較ができること」 です。
例えば、lightGBMの以下2つのハイパーパラメータを組み合わせる9種類を出力してみます。
learning_rates = [0.01, 0.05, 0.1]
num_leaves_values = [31, 50, 100]
実行すると、先ほど公開したサーバに9つのrunが反映されました。
選択して比較してみます。
この9つの実行をそれぞれテーブルとグラフによって比較してくれています。
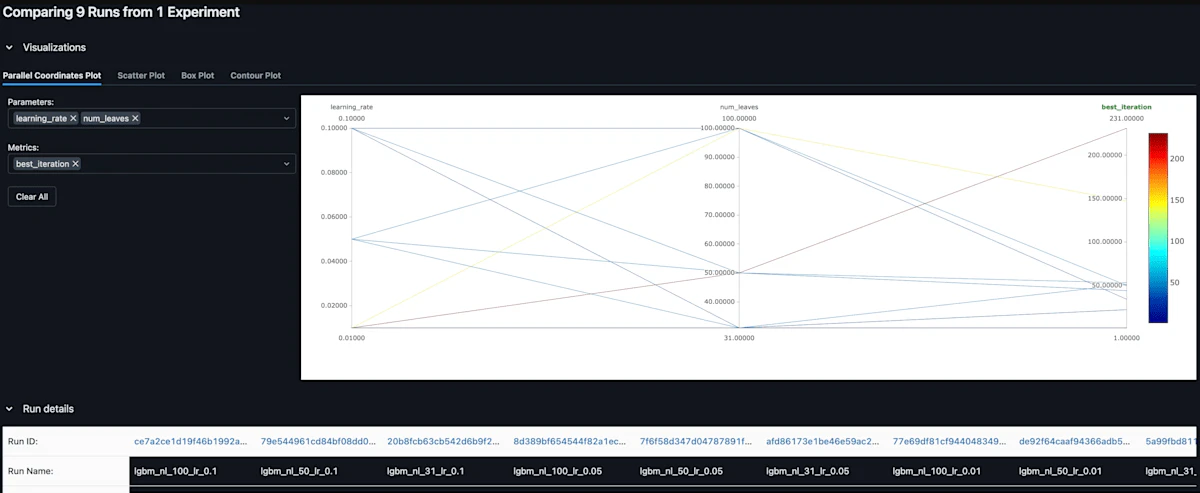

パラメータでも比較することができます。
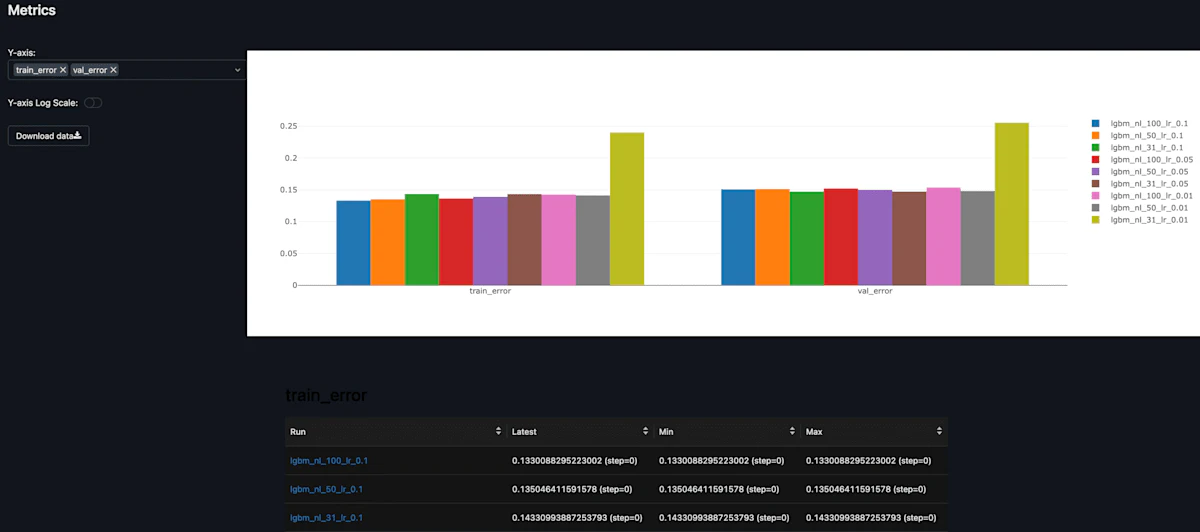
lgbm_nl_50_lr_0.01 は train_error が低めで val_error も他のモデルに比べて適度に低いです。訓練と検証の誤差のバランスが良いため、このなかでは最も良いモデルであると考えられそうです。
モデルのパラメータや条件を簡単に比較し、 どのモデルを使用するのが適切かを一目で直感的に判断できます。 これは確かにモデルの設計やトレーニングを効率的に実施できることに繋がりそうです。
実際には運用していく中でもこれらを監視できるという要素でメリットが大きいかと思います。
まとめ
今回はGoogle ColabでMLflowとngrokを使い、ミニ機械学習モデルにミニミニMLOpsの要素を組み込んでみました。
MLOpsと聞くと「保守・運用」「自動化されたパイプライン」など、DevOps寄りのイメージが先行し、どこか 「企業向けの大がかりな仕組み」 という印象を持っている方も多いかもしれません。実際私も高嶺の花子さんだと思っていました。高嶺のMLOps…そう、オプ子です。
しかし、今回Colab上で手を動かしてみたことで、
- MLOpsの基本的な構成要素(実験管理・モデル記録など)は、意外と簡単に触れられること
- たとえ個人開発でも、MLOps的な仕組みを取り入れることで、モデル開発の効率や再現性が格段に向上すること
を実感できました。
もちろん、実際のビジネス現場ではAzure MLやDatabricksなどのマネージドサービスが主流です。セキュリティ、スケーラビリティ、チーム運用、CI/CDとの統合など、手書きでは対応が難しい課題が多いためです。
ただMLOpsを体感するという意味では、今回のような手作りのMLOps体験は有効かと思います。特にMLflowはAzureやDatabricksでもコア技術として使われているので、今後のステップにもつながるといいなと思います。