はじめに
昨今、AIの進化によりOCR(光学文字認識)技術が飛躍的に向上しています。特にディープラーニング/LLMを活用したモデルは、画像からの情報抽出能力を大幅に高めています。
本記事では、スーパーのチラシ画像を対象に、商品名と価格のペアを取得する試験を行い、さまざまなライブラリやモデルの性能を大雑把に比較検証していきます。
実装コードをトグル配下に載せているので、よかったら参考にしてください。
本記事の注意点は以下です。
- 環境構築方法は記載していないです。
- プロンプトはシンプルであり、チューニングは実施していません。
- 今回の試験結果はチラシ1枚に対してであり、すべてのチラシデータに対して同様の結果は保証されていません。
サマリ
今回実施したチラシの読み取り試験の結果は以下です。(正答の定義、詳しい手法は以下を参照してください。)
| 手法(ライブラリ、モデル) | Precision | Recall |
|---|---|---|
| Docling | - | - |
| PyMupPDF4LLM | - | - |
| Llama 3.2 90B | 0.050 | 0.050 |
| Gemini 1.5 Flash(N=1) | 0.42 | 0.46 |
| Gemini 1.5 Flash(多数決, N=3) | 0.55 | 0.44 |
| Gemini 1.5 Pro(N=1) | 0.42 | 0.60 |
| Gemini 1.5 Pro(多数決, N=3) | 1.0 | 0.55 |
Gemini 1.5 Pro(多数決、N=3)が最も高いPrecisionを示し、情報の信頼性が高いことが確認できました。
しかし、Recallの値が示すように、まだ情報の抜け漏れが存在し、チラシ読み取りの課題が残っています。
データ
今回対象とするのはスーパーのチラシの画像とします。
チラシの画像は公開データですが、念の為ぼかしを入れています。

ちなみにチラシデータは以下のサイトにまとまっているものから取得しました。
また正解データを作成するのが少し面倒なので、検証に使ったチラシ画像は1枚としました。
問題設定と評価観点
チラシの読み取りタスクにおいて、商品名と値段のペアが正しく取得できた場合を正答とします。
商品名の揺れについて完全に筆者の匙加減ですが、ある程度は許容することにしました。例えばマヨネーズとキューピーマヨネーズはどちらも同一商品としてみなしました。
モデルの精度指標は回答の正確性を測るPrecisionと回答の抜け漏れを測るRecallを採用します。
今回筆者は抜け漏れよりも情報の信憑性の方が気になっているので、Presionを重視しています。というのもチラシの読み取りを実際にやってみると分かるのですが、ハルシネーションが激しく、Recallが高かったとしても、どのデータを信用すれば良いのかわからないからです。
手法
チラシ読み取りでは筆者の興味から以下のライブラリ、モデルを選定しました。
- Docling
- PyMupPDF4LLM
- Llama 3.2 90B
- Gemini 1.5 Flash
- Gemini 1.5 Flashの多数決(過半数以上採用)
- Gemini 1.5 Pro
- Gemini 1.5 Proの多数決(過半数以上採用)
DoclingとPyMupPDF4LLMは2024年11月初旬で個人的にホットなライブラリ(表の読み取りなどで優れていて評判が良いように見える)なので採用しました。
Llama 3.2 90BはVisionモデルがGPT-4o miniを超えており(Metaの記事より)、精度に期待ができるので採用しました。
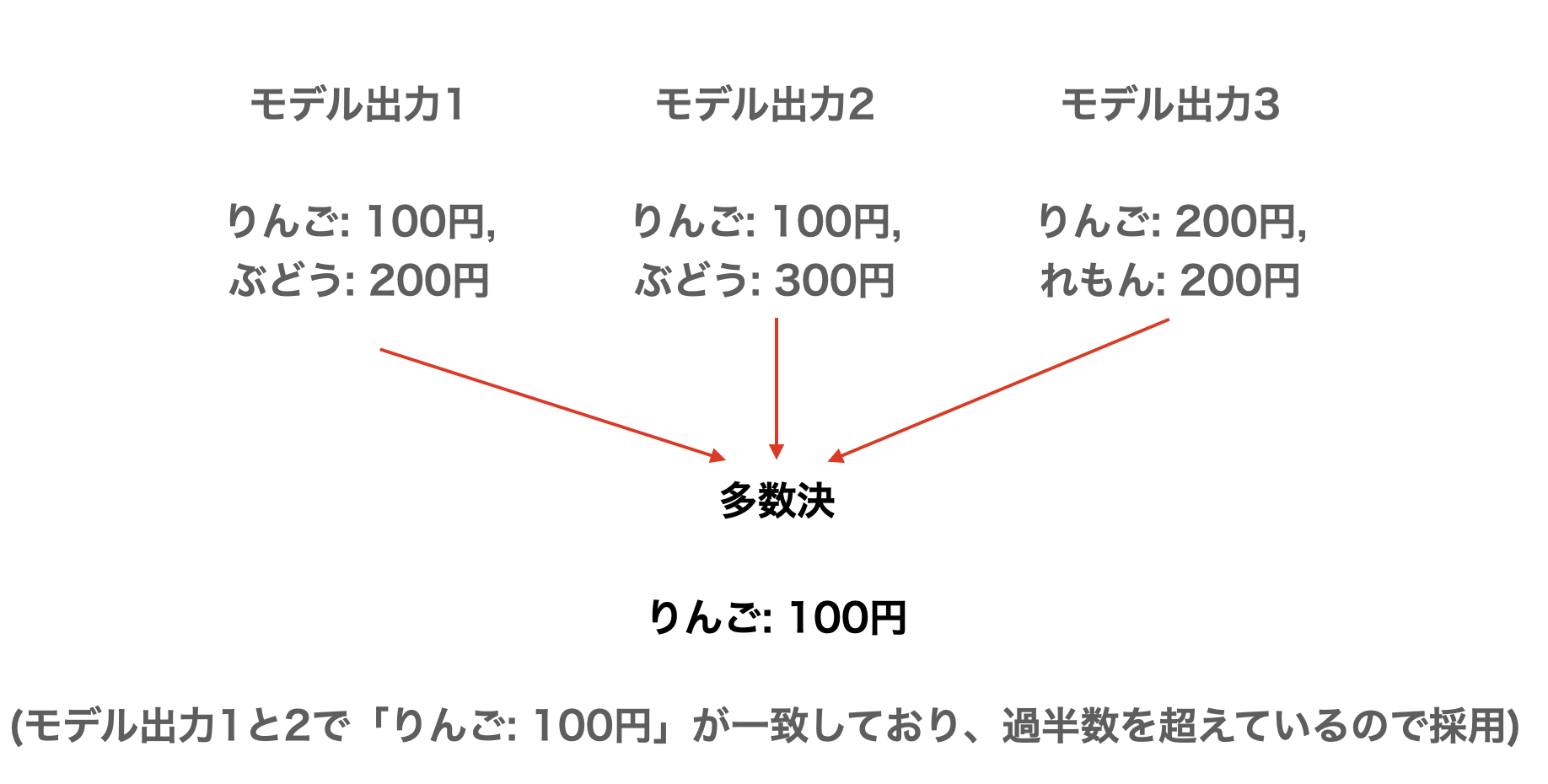
先述しましたが画像読み取り系のタスクはハルシネーションが多いので、ハルシネーションを抑えるためにアンサンブルチックな多数決の手法を採用しました。
具体的には同一モデルでN回推論を実行し、M(N>M)回結果が同じだった商品と値段のペアを採用しました。今回はN=3, M=2としました。(以下図参照)
プログラム
それぞれの実装を以下にまとめます。
1. Docling, PyMupPDF4LLM
Doclingのコード
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import (
PdfPipelineOptions,
TesseractOcrOptions,
EasyOcrOptions,
)
from docling.document_converter import DocumentConverter, PdfFormatOption
source = "img/image.pdf"
#OCRモデルは適宜変更する
#ocr_options = EasyOcrOptions(lang=["ja"])
ocr_options = TesseractOcrOptions(lang=["ja"])
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
converter = (
DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=pipeline_options,
),
}
)
)
result = converter.convert(source)
print(result.document.export_to_markdown())
PyMupPDF4LLMのコード
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("img/img.pdf")
print(md_text)
2. Llama 3.2 90B
Llama 3.2 90Bのコード
Groqを使ってLlama 3.2 90Bを動かしています。 (また瑣末な点ですがQiitaに執筆する関係上、プロンプト内の`という文字を削除しています。)またGroqでVisionモデルを使う場合はLangChainが活用できないので、groqライブラリを用いています。
https://python.langchain.com/docs/integrations/chat/groq/
import base64
from groq import Groq
import json
import re
model_name = 'llama-3.2-90b-vision-preview'
image_path = 'img/image.jpg'
pattern = r'```json.*?```'
with open(image_path, 'rb') as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
prompt = """
この画像について商品と値段についてJSON形式でまとめてください。出力例は以下です。
json <- ここの文頭に```がつきます
{
"りんご": 160,
"ぶどう": 130
}
<- ここに```がつきます
"""
client = Groq()
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_string}",
},
},
],
}
],
model=model_name,
)
try:
output = chat_completion.choices[0].message.content
output = re.findall(pattern, output, re.DOTALL)[0]
output = output.replace('```json', '').replace('```', '')
json_data = json.loads(output)
with open(f'output/products_{model_name}.json', 'w', encoding='utf-8') as f:
json.dump(json_data, f, ensure_ascii=False, indent=2)
except Exception as e:
print(f"Error: {e}")
3. Geminiの実装
Geminiのコード
GeminiはLangChainを用いてコーディングしています。from collections import defaultdict, Counter
def extract_majority_key_values(json_list, majority=2):
"""
各キーについて、過半数以上のJSONで同一の値を持つものを抽出します。
:param json_list: JSONオブジェクトのリスト
:param majority: 過半数を定義する数値(デフォルトは2)
:return: 過半数以上で一致するキーと値の辞書
"""
key_values = defaultdict(list)
# 各JSONからキーと値を収集
for json_data in json_list:
for key, value in json_data.items():
key_values[key].append(value)
common_data = {}
for key, values in key_values.items():
# 値の出現回数をカウント
value_counts = Counter(values)
# 最も多く出現した値とその回数を取得
most_common_value, count = value_counts.most_common(1)[0]
if count >= majority:
common_data[key] = most_common_value
return common_data
from langchain_google_genai import ChatGoogleGenerativeAI
import base64
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import JsonOutputParser
import json
from util import extract_majority_key_values
model_name = 'gemini-1.5-pro'
image_path = 'img/image.jpg'
N = 3
llm = ChatGoogleGenerativeAI(model=model_name)
chain = llm | JsonOutputParser()
prompt = """
この画像について商品と値段についてJSON形式でまとめてください。出力例は以下です。
{
"りんご": 160,
"ぶどう": 130
}
"""
with open(image_path, 'rb') as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
message = HumanMessage(
content=[
{
'type': 'text',
'text': prompt,
},
{
'type': 'image_url',
'image_url': f'data:image/jpg;base64,${encoded_string}',
},
]
)
json_list = []
for i in range(N):
print(f"\n--- 呼び出し {i+1} ---")
try:
output = chain.invoke([message])
print(output)
json_list.append(output)
except Exception as e:
print(f"Error: {e}")
json_data = extract_majority_key_values(json_list, majority=2)
with open(f'output/products_{model_name}_sample.json', 'w', encoding='utf-8') as f:
json.dump(output, f, ensure_ascii=False, indent=2)
with open(f'output/products_{model_name}.json', 'w', encoding='utf-8') as f:
json.dump(json_data, f, ensure_ascii=False, indent=2)
結果
1. Docling、PyMupPDF4LLM
どちらもチラシの読み取り以前に文字起こしがうまくいきませんでした。
設定方法やパラメータが悪い可能性はあるのですが、パラメータを少しいじっても読み取りが難しかったので、深追いはしていないです。
筆者の使用感的にDocling、PyMupPDF4LLMはある程度構造化されているデータに強い印象があり、今回のような非構造化データは得意でないかもしれません。
2. Llama 3.2 90B
ほぼうまくできませんでした。
特にハルシネーションが激しく、チラシにない情報ばかりを出力してしまいました。(プロンプトである程度制御はできるかもしれませんが)
| 手法(ライブラリ、モデル) | Precision | Recall |
|---|---|---|
| Llama 3.2 90B | 0.050 | 0.050 |
Metaが出しているLlama系のモデルは日本語能力がそこまで高くないというのもあり、英語表記のチラシを読み取らせるなどで追加検証するのも面白いかもしれません。
3. Gemini
モデル単体で実施した方がRecallは高く、多数決を導入した方がPrecisionは高くなりました。
また精度面ではGemini 1.5 FlashよりもGemini 1.5 Proの方が優れており、特にPrecisionが非常に高くなりました。
ただRecallはどれも0.4~0.6台であり、Geminiにとってはスーパーのチラシ自体の読み取りが難しいタスクと言えるかもしれません。
| 手法(ライブラリ、モデル) | Precision | Recall |
|---|---|---|
| Gemini 1.5 Flash(N=1) | 0.42 | 0.46 |
| Gemini 1.5 Flash(多数決, N=3) | 0.55 | 0.44 |
| Gemini 1.5 Pro(N=1) | 0.42 | 0.60 |
| Gemini 1.5 Pro(多数決, N=3) | 1.0 | 0.55 |
gpt-4oやgpt-4o-miniでも同様の検証をしてみたり、ハルシネーションを抑えるプロンプトを入れてみると面白いかもしれません。
おわりに
本試験を通じて、Gemini 1.5 Pro(多数決、N=3)が最も高いPrecisionを示し、情報の信頼性が高いことが確認できました。
しかし、Recallの値が示すように、まだ情報の抜け漏れが存在し、チラシ読み取りの課題が残っています。
ハルシネーションを抑えるプロンプトの工夫や、他のモデルとの比較検討を進め、より精度の高いチラシ読み取りをしてみるのも面白いかもしれません。