はじめに
2023年4月5日にMeta社がSAM(Segment Anything Model)というセグメンテーションモデルを発表しました。SAMはファインチューニングなし(ゼロショット)であらゆる物体のセグメンテーションを精度高く行うことができます。
以下はMeta社のSAMのWebページから持ってきたセグメンテーション後の画像ですが、物体多めの画像でも正しくセグメンテーションできています。

SAMは上述のようにゼロショットで高い精度でセグメンテーションができますが、計算資源が限られてた環境(ex.エッジデバイス)では使用が困難であるという問題があります。
その問題の解決策の一つとして、セグメンテーションの精度を維持しつつ、SAMを軽量化したモデルであるTinySAMが提案されました。
本記事ではTinySAMについて紹介していきます。
手法
TinySAMはSAMに対して、(1)知識蒸留と(2)量子化を行うことで、サイズを2%まで圧縮しています。
さらに(3)階層型セグメンテーションを行うことで、推論時間を約1/2倍に短縮しています。
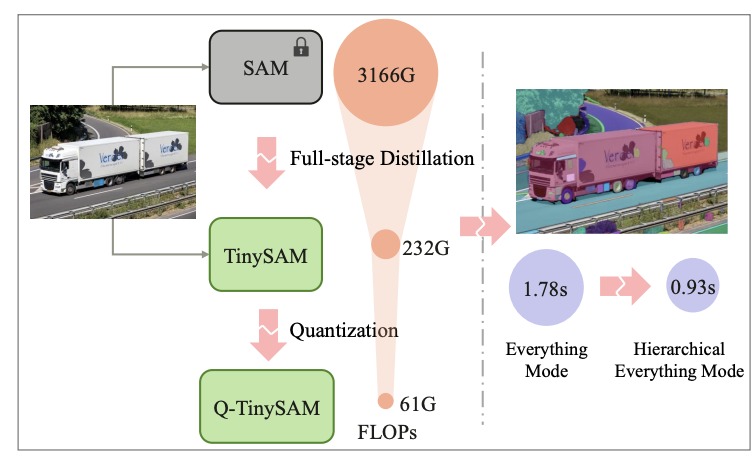
以下では(1)知識蒸留(2)量子化(3)階層型セグメンテーションについて簡単に解説します。
知識蒸留
SAMは画像エンコーダー、プロンプトエンコーダー、マスクデコーダーの3つのサブネットワークから構成されています。(下の図はSAMの原著の図)

SAMの特筆した特徴は、画像とプロンプトを組み合わせて出力のセグメンテーションを生成する部分です。ここでいうプロンプトとは、画像内の何をセグメンテーションするかを指定するものです。
詳しくはSAMの原著をご覧ください。
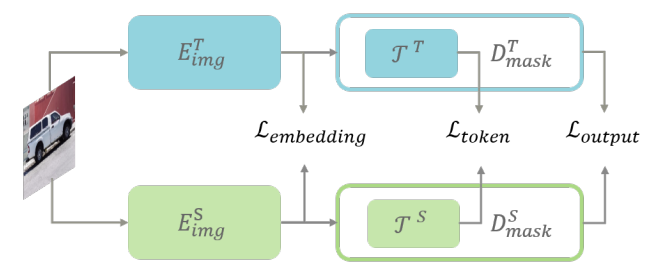
SAMの問題点は、画像エンコーダがViTで構成されているため、計算コストが大きいことです。そこでTinySAMでは知識蒸留によってエンコーダー部分の軽量化を行いました。知識蒸留では、画像エンコーダーの埋め込みの損失(Embedding Loss)、プロンプトのトークンの損失(Token Loss)、マスクデコーダーによるSAMの出力の損失(Output Loss)の3つの損失を組み合わせることで蒸留時の損失関数を設定しました。
SAMの出力の損失だけでなく、画像エンコーダーの埋め込みの損失やプロンプトのトークンの損失を使っている点が工夫点です。
また知識蒸留時の手法としてハードプロンプトサンプリングという手法が採用されており、サンプリングによってプロンプトの難易度に大きな差が出ないようにしています。
ここでいうハードプロンプトについて、筆者は静的なプロンプト•プロンプトのテンプレートのようなニュアンスで使われていると理解しています。(よく理解できませんでした。)
量子化
量子化でモデルの重みを低ビットに変換しています。
またガウス分布の特性を維持するためにスケーリングファクターの調整を行っています。
階層型セグメンテーション
SAMでは画像を格子状の点としてサンプリングしてセグメンテーションを行うが、高密度の点は、セグメンテーションの結果を細かくしすぎ、また膨大なコンピューティングリソースを占有し、計算時間が増加してしまいます。
この時間コストを削減するための手法として、 階層型セグメンテーションが提案されました。
階層型セグメンテーションは4ステップで構成させています。
- step1:SAMと比べて1/16の点をサンプリングしてエンコーダとマスクデコーダにより推論します。(画像(c)の下の矢印の画像)
- step2:信頼度が閾値を超えるいくつかのマスクをフィルタリングして信頼できる領域とします。
- step3:信頼度が閾値を超えなかった領域について再度点のサンプリングを行い、再度推論します。(画像(c)->(d)の矢印に対応する)
- step4:これら2つの推論結果をマージし、後処理して最終的なマスクを獲得します。

これにより推論コストと、オブジェクトの細かすぎるセグメンテーションの両方を回避することができます。
結果
TinySAMと比較対象のモデルのセグメンテーションの精度は以下です。
比較対象のモデルと比べて、精度を保ったまま、計算コストを小さくできていることがわかります。
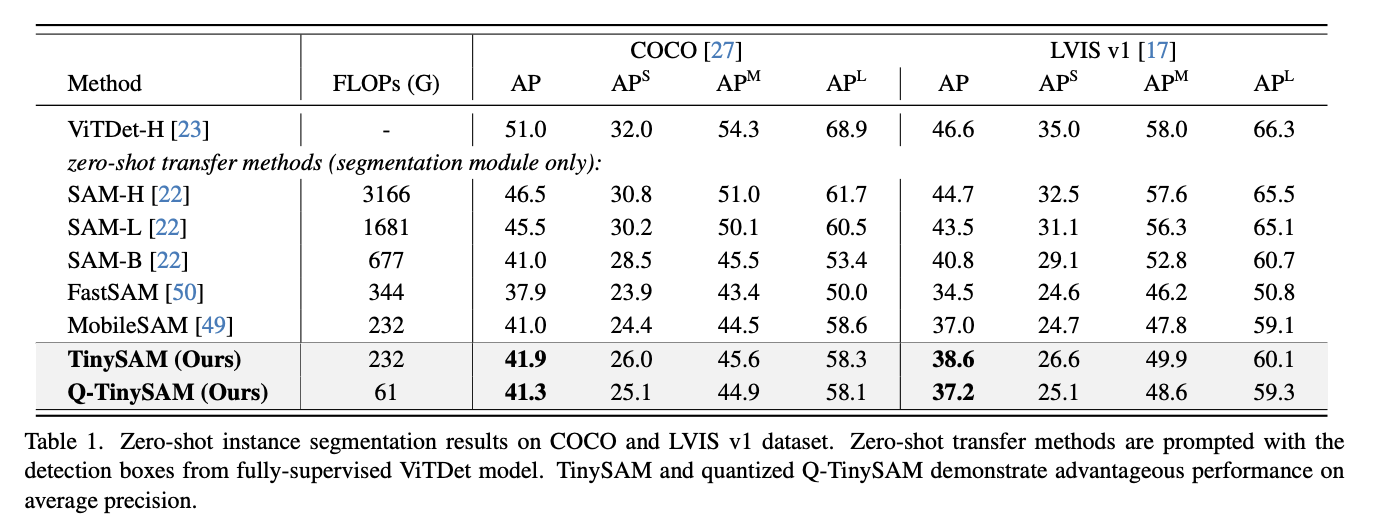
評価指標のAPとは、モデルが特定のクラスのオブジェクトを正確に識別し、その位置を正確に予測する能力を測定する指標であり、高いほど正確にセグメンテーションできていることを示します。APは、さまざまな閾値での精度と再現率の平均値を算出することによって計算されます。
次にセグメンテーションの定性的な結果は以下です。著者らは、以下の定性画像(COCOのセグメンテーション結果)からTinySAMが他のモデルより明確なセグメンテーションができていると言っていますが、私にはあまり違いがわかりませんでした。

以降での精度は、全てCOCOデータセットでの結果となります。
各手法の性能寄与

知識蒸留の損失関数の設定、ハードプロンプトサンプリングにより、モデルの性能は向上していることがわかります。また量子化によって性能はわずかに低下(APが0.6ポイント低下)していることがわかります。
知識蒸留における損失の性能寄与
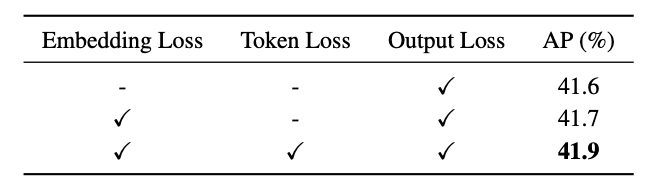
上図より、モデルの出力の損失だけでなく、画像エンコーダーの埋め込みの損失やプロンプトのトークンの損失が性能に寄与していることがわかります。
量子化における速度と性能について
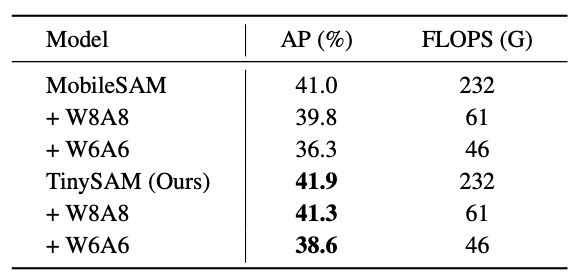
上図より、8bit量子化によって性能はわずかに低下(APが0.6ポイント低下)していることがわかります。また6bit量子化では、8bit量子化に比べて性能が低下(APが3.3ポイント低下)していることがわかります。
階層型セグメンテーションの有効性について
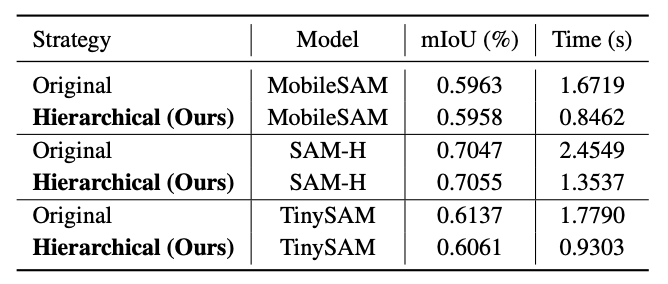
上図より、階層型セグメンテーションを使うことで、TinySAMや比較対象のモデルでも精度(mLoU)を保ったまま、計算時間を約1/2に短縮できています。
おわりに
いかがだったでしょうか。
モデルのパラメータ数が膨大である昨今、モデルの軽量化はとても重要なテーマの一つです。TinySAMの論文で紹介された手法は、他の手法ともアナロジーが取れる部分もあるので、参考になれば幸いです。