はじめに
ハングルを構成要素に分解して処理するためのPythonライブラリについてまとめます。
日本語だとjaconvやkakasiやjamorasepなどのようなものでしょうか。
hanja
漢字語の処理のライブラリっぽいですが、ハングルの処理にも使えます。
$ pip install hanja
一文字ずつ入力します。
from hanja import hangul
hangul.separate('가')
#=> (0, 0, 0)
タプルの一つ目の要素が子音(初声)、2つ目が母音(中声)、3つ目がパッチム(下につく子音:終声)です。
それぞれの数字の割り振りは以下の順序のようです。
# 子音
['ㄱ',
'ㄲ',
'ㄴ',
'ㄷ',
'ㄸ',
'ㄹ',
'ㅁ',
'ㅂ',
'ㅃ',
'ㅅ',
'ㅆ',
'ㅇ',
'ㅈ',
'ㅉ',
'ㅊ',
'ㅋ',
'ㅌ',
'ㅍ',
'ㅎ']
# 母音
['ㅏ',
'ㅐ',
'ㅑ',
'ㅒ',
'ㅓ',
'ㅔ',
'ㅕ',
'ㅖ',
'ㅗ',
'ㅘ',
'ㅙ',
'ㅚ',
'ㅛ',
'ㅜ',
'ㅝ',
'ㅞ',
'ㅟ',
'ㅠ',
'ㅡ',
'ㅢ',
'ㅣ']
# パッチム
['', # 0番目はパッチム無し
'ㄱ',
'ㄲ',
'ㄳ',
'ㄴ',
'ㄵ',
'ㄶ',
'ㄷ',
'ㄹ',
'ㄺ',
'ㄻ',
'ㄼ',
'ㄽ',
'ㄾ',
'ㄿ',
'ㅀ',
'ㅁ',
'ㅂ',
'ㅄ',
'ㅅ',
'ㅆ',
'ㅇ',
'ㅈ',
'ㅊ',
'ㅋ',
'ㅌ',
'ㅍ',
'ㅎ',
'ㅐ',
'ㄱ',
'ㄲ',
'ㄳ',
'ㄴ',
'ㄵ',
'ㄶ',
'ㄷ',
'ㄹ',
'ㄺ',
'ㄻ',
'ㄼ',
'ㄽ',
'ㄾ',
'ㄿ',
'ㅀ',
'ㅁ',
'ㅂ',
'ㅄ',
'ㅅ',
'ㅆ',
'ㅇ',
'ㅈ',
'ㅊ',
'ㅋ',
'ㅌ',
'ㅍ',
'ㅎ']
jamo
$ pip install jamo
ハングルの構成要素にばらけさせます。複数文字も同時に入力できます。
from jamo import h2j, j2hcj
j2hcj(h2j("한글자모분리"))
#=> 'ㅎㅏㄴㄱㅡㄹㅈㅏㅁㅗㅂㅜㄴㄹㅣ'
最初のh2jメソッドは型変換的なものっぽい。
一文字ずつ先に分けておかないとパッチムでややこしくなりそう。
hgtk
jamoより便利そう?
$ pip install hgtk
jamoのj2hcjと同じことができます。
import hgtk
hgtk.letter.decompose('감')
#=> ('ㄱ', 'ㅏ', 'ㅁ')
compose_codeを区切りにして文字ごとに区切ってくれます。
hgtk.text.decompose('학교종이 땡땡땡! hello world 1234567890 ㅋㅋ!', compose_code='/')
#=> 'ㅎㅏㄱ/ㄱㅛ/ㅈㅗㅇ/ㅇㅣ/ㄸㅐㅇ/ㄸㅐㅇ/ㄸㅐㅇ/! hello world 1234567890 ㅋ/ㅋ/!'
助詞を良い感じにつけてくれる
hgtk.josa.attach('하늘', hgtk.josa.I_GA)
#=> '하늘이'
hgtk.josa.attach('바다', hgtk.josa.I_GA)
#=> '바다가'
(番外編)BTS
ライブラリではありませんが、2022年に発表された以下の論文の実装になります。(名前はなんか狙いすぎですが...)
子音と母音の分解を以下のように、ハングルの成立過程なども踏まえて行っているようです。
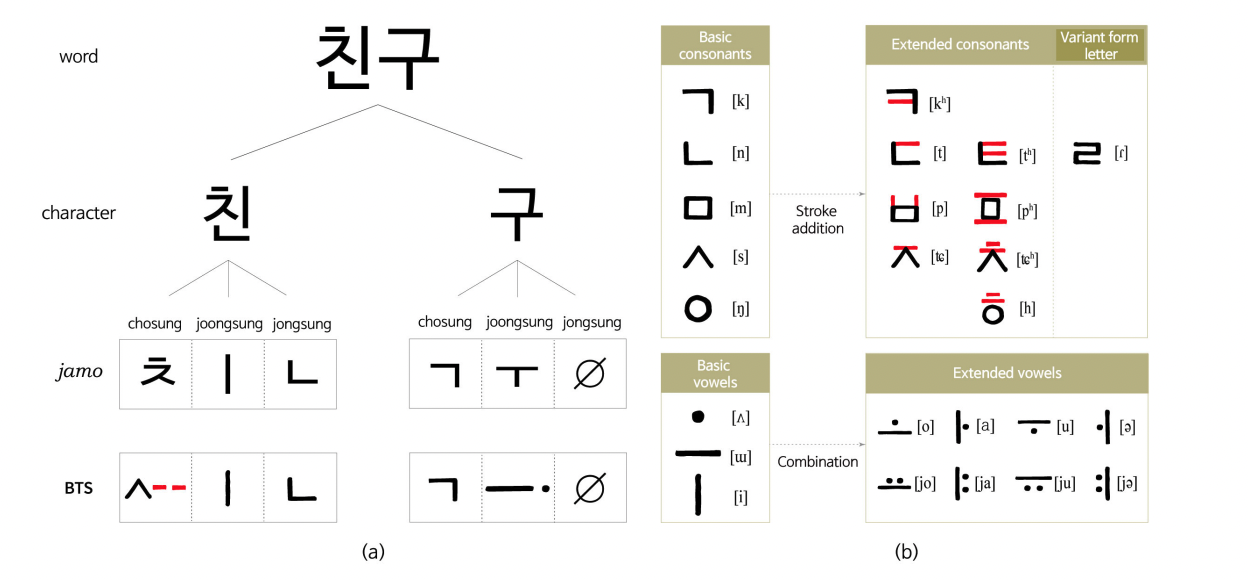
これにより、異なる子音の間でも共通の要素を取り出すことができるような手法です。ㅋがㄱと-に分解されるのとかは分かるんですが、ㄷがㄴと-に分解されるのとかは結構不思議な感じがします。
$ pip install hgtk jamotools
$ git clone https://github.com/irishev/BTS.git
して
import sys
sys.path.append("BTS")
しておきます。
必要な関数(jamo_split)だけ取り出して使うと良さそうです。
from BTS.decompose_letters import jamo_split
sentence = "이라크"
jamo_split(sentence, split_stroke=True, split_cji=True)
#=> 'ㅇ^ㅣ^^/ㄹ^ㅣㆍ^^/ㄱ-^ㅡ^^/'
文字の区切りが/、文字内の要素の区切りが^になっています。
split_strokeとsplit_cjiの設定により、以下のように区切り方が変化します。
# 子音がまとまる(ㅋ)
jamo_split(sentence, split_stroke=False, split_cji=True)
#=> 'ㅇ^ㅣ^^/ㄹ^ㅣㆍ^^/ㅋ^ㅡ^^/'
# 母音がまとまる(ㅏ)
jamo_split(sentence, split_stroke=True, split_cji=False)
#=> 'ㅇ^ㅣ^^/ㄹ^ㅏ^^/ㄱ-^ㅡ^^/'
# 子音と母音の両方がまとまる
jamo_split(sentence, split_stroke=False, split_cji=False)
#=> 'ㅇ^ㅣ^^/ㄹ^ㅏ^^/ㅋ^ㅡ^^/'
おわりに
ハングル自体がとてもシステマチックでシンプルなので、これだけあれば問題なさそうでしょうかね