できたもの

はじめに
単語や文章の意味を分散表現のベクトルとして扱うアプローチが一般的になっていますが、単語の意味において色はどういう関係にあるのだろうと思い立ち、試しにモデルを学習させてみました。色にも色空間(RGBやHSVなど)があるので、単語の分散表現空間と色のRGB空間との転写を学習するというアプローチを試してみることにしました
具体的には、単語→意味分散表現→RGB空間→色という流れで今回は単語から色を生成してみます
色の名前とRGB値をセットで取得
こちらのサイトからHTMLカラーと呼ばれる140種類ぐらいの名前のついた色を集めさせていただきました
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.w3schools.com/colors/colors_names.asp'
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
color_names_and_codes = {}
for name, code in zip(soup.select('.colornamespan'), soup.select('.colorhexspan')):
name = re.sub('(.)([A-Z])', r'\1 \2', name.text).lower() # eg: AliceBlue -> alice blue
color_names_and_codes[name] = code.text
このcolor_names_and_codesには次のようにHTMLカラー名とRGBの組み合わせが入っています
{'alice blue': '#F0F8FF',
'antique white': '#FAEBD7',
'aqua': '#00FFFF',
'aquamarine': '#7FFFD4',
'azure': '#F0FFFF',
'beige': '#F5F5DC',
'bisque': '#FFE4C4',
'black': '#000000',
'blanched almond': '#FFEBCD',
...
BERTの分散表現学習(huggingface transformers)
モデルと分散表現
使用したバージョン:transformers==4.5.0
huggingfaceのtransformersが簡単にモデルを取得し学習・評価できたのでこちらを用います。
事前学習済みの英語のbertのトークナイザーとモデルをまずロードします
import torch
from transformers.tokenization_bert import BertTokenizer
from transformers import BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-cased') # casedは大文字小文字区別なし
model = BertModel.from_pretrained('bert-base-cased')
とりあえず現状の分散表現空間(768次元)での各単語の分布を見てみたいので、全単語の出力を取得します
def encode_texts(texts):
encoding = tokenizer.batch_encode_plus(texts, return_tensors='pt', pad_to_max_length=True)
return encoding['input_ids'], encoding['attention_mask']
texts = list(color_names_and_codes.keys())
ids, attention_mask = encode_texts(texts)
outputs = model(ids)
vecs = outputs[0][:, 0, :].tolist()
このベクトルを次元圧縮(t-SNE)して見てみます。プロット点の色がその単語の色と対応しています
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
def plot_tsne(x, y, color):
plt.figure(figsize=(8, 6))
plt.clf()
tsne = TSNE(n_components=2, random_state=0, perplexity=10)
x_embedded = tsne.fit_transform(x)
plt.scatter(x_embedded[:, 0], x_embedded[:, 1], c=color)
plt.show()
plot_tsne(vecs, texts, color_names_and_codes.values())
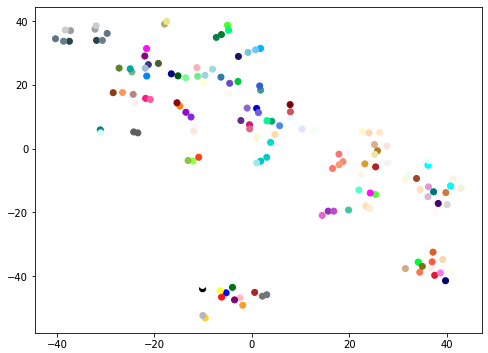
時々似ている色が隣り合っていたり集まっている箇所はあるようです
学習
このモデルの最終層をRGBに対応した3次元のものに取り替えます。RGBの3次元の回帰問題として学習します
# すべてのパラメータを固定
for param in model.parameters():
param.requires_grad = False
n_in_features = model.pooler.dense.in_features
n_out_features = 3
model.pooler.dense = torch.nn.Linear(n_in_features, n_out_features)
model.pooler.activation = torch.nn.ReLU()
カラーコードを0から1の値を持つRGBベクトルに変換し、正解データを作ります。
import numpy as np
import torch
from sklearn.model_selection import train_test_split
def hex_to_rgb(color_code):
r = int(color_code[1:3], 16) / 255
g = int(color_code[3:5], 16) / 255
b = int(color_code[5:7], 16) / 255
return [r, g, b]
y = np.array([hex_to_rgb(code) for code in color_names_and_codes.values()])
y_tensor = torch.from_numpy(y).float()
i_train, i_val = train_test_split(range(len(ids)), test_size=0.25)
print(y_tensor[i_train].shape)
print(ids[i_val].shape)
# =>
torch.Size([111, 3])
torch.Size([37, 8])
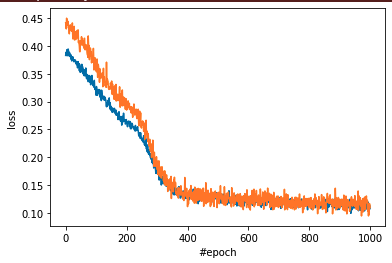
損失関数を平均二乗誤差に設定し、モデルの学習を行います
optimizer = transformers.AdamW(model.pooler.parameters(), lr=0.00001)
criterion = torch.nn.MSELoss()
model.train()
n_epochs = 1000
train_losses, val_losses = [], []
x_train, x_val, y_train, y_val = ids[i_train], ids[i_val], y_tensor[i_train], y_tensor[i_val]
attention_mask_train, attention_mask_val = attention_mask[i_train], attention_mask[i_val]
for epoch in tqdm(range(n_epochs)):
y_train_pred = model(x_train, attention_mask_train)
loss = criterion(y_train_pred.pooler_output, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(loss.data.numpy().tolist())
y_val_pred = model(x_val, attention_mask_val)
val_loss = criterion(y_val_pred.pooler_output, y_val)
val_losses.append(val_loss.data.numpy().tolist())
一応それなりにロスは落ちたみたいなので、
データ内の色をどのように生成したかプロットしてみます(以下のページですべて確認可能です)
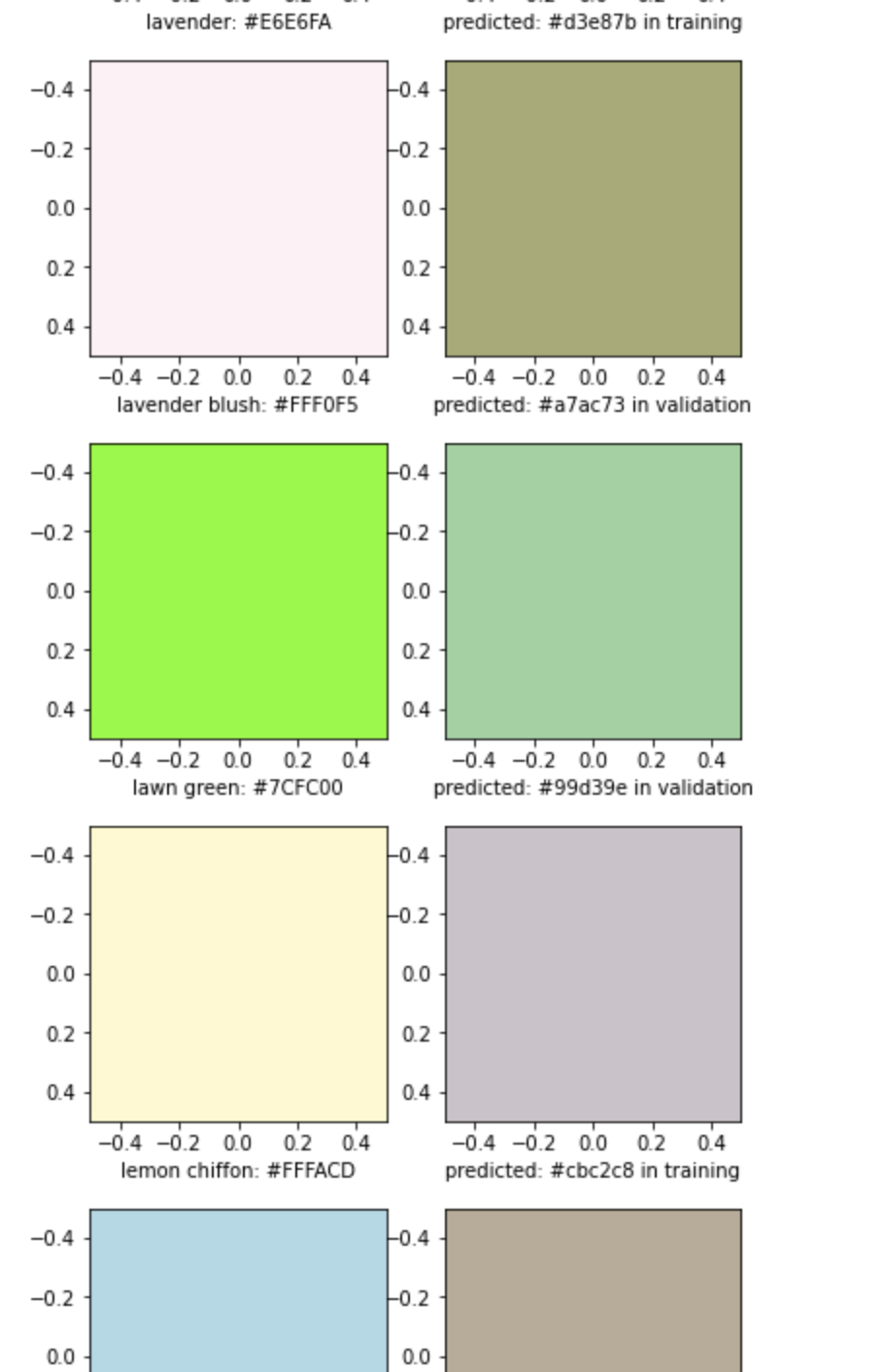
元のデータの分布からなのか、なんか地味めな青とか緑系の色が多くなりました。あまり上手くいってなさげですが、そもそも単語の意味分散表現から色の生成がどの程度難しいのかよく分からないので、とりあえずこのモデルを使用することにしました
herokuへデプロイ
単語に色がついているのが見てみたかったので、どんな単語でもインタラクティブに色の確認ができるように、streamlitを用いてwebアプリ化してみました
おわりに
文字に色があるタイプの共感覚を疑似体験することはできた感じがしますが、理想的には「晴れた夏の青空」とか入力すると鮮やかな青色のRGB値を出力するようなものができれば、何かしらに使えるかもしれないですが今回はそこまでは難しかったみたいです
ちなみにHSV空間でも試したところ、青か緑しか出さないモデルができて上手くいかなかったのですが、明度や彩度を無視して色相(H)だけを予測するとかでも良かったのかもしれないです
参考
- https://qiita.com/ichiroex/items/6e305a5d5bed7d715c2f
- https://qiita.com/xkumiyu/items/1cc0223486c560062e00#%E5%B1%9E%E6%80%A7%E3%83%99%E3%82%AF%E3%83%88%E3%83%AB%E3%81%AE%E6%8A%BD%E5%87%BA
- https://tksmml.hatenablog.com/entry/2019/10/22/215000
- https://aidiary.hatenablog.com/entry/20180217/1518833659
追記
こちらの研究室でまさに研究されているようです!