「この SQL、結局なにしてるの?」を自然言語で説明するツールを作った。LLM に投げれば一発だが、それだとオフラインで動かないし、何よりパーサを書くのが面白い。SELECT 文専用の tokenizer + 再帰下降パーサを自前で書いて、AST を日本語/英語の解説に変換する。実装の hinge は 2 つ: (1)
ANDがORより強く結合する演算子優先順位を再帰下降でどう表現するか、(2) 解説を「書かれた順」ではなく「論理実行順」(FROM→WHERE→GROUP BY→SELECT) で並べること。後者が分かると「なぜ WHERE で SELECT のエイリアスが使えないのか」が腑に落ちる。
🌐 デモ: https://sen.ltd/portfolio/sql-explainer/
📦 GitHub: https://github.com/sen-ltd/sql-explainer
なぜ自前パーサか
「SQL を説明する」だけなら ChatGPT に貼れば終わる。でもそれだと:
- オフラインで動かない
- クエリを外部に送る (機密スキーマだと困る)
- 毎回ぶれる (同じ入力で違う説明)
決定的に動く小さなパーサを書けば、全部解決する。SELECT のサブセットに限れば、パーサは 200 行程度で書ける。
3 層構成
tokenizer.js → parser.js → explainer.js
- tokenizer: 文字列 → トークン列 (キーワード・識別子・文字列・数値・演算子)
- parser: トークン列 → AST (再帰下降)
- explainer: AST → 自然言語のステップ列
各層が DOM 非依存なので、35 個の Node テストが全部走る。
tokenizer: SQL の字句解析
キーワードは大文字化してタグ付け、識別子は元の大小を保持:
export const KEYWORDS = new Set([
"SELECT", "FROM", "WHERE", "GROUP", "BY", "HAVING", "JOIN", "ON",
"AND", "OR", "NOT", "IN", "LIKE", "BETWEEN", "IS", "NULL", "DISTINCT",
"COUNT", "SUM", "AVG", "MIN", "MAX", /* ... */
]);
// 識別子/キーワードの判定
const word = sql.slice(i, j);
if (KEYWORDS.has(word.toUpperCase())) {
tokens.push({ type: "kw", value: word.toUpperCase() });
} else {
tokens.push({ type: "ident", value: word }); // 元の大小を保持
}
SQL 特有のハマりどころ:
-
文字列内のクォートエスケープ
'O''Brien'→O'Brien(2 連続シングルクォート) -
クォート識別子
"select"や`from`は予約語でも識別子として扱う -
コメント
--行コメントと/* */ブロックコメント
// 文字列リテラル: '' は 1 つの ' にエスケープ
if (sql[j] === "'" && sql[j + 1] === "'") { val += "'"; j += 2; continue; }
parser: 演算子優先順位を文法構造で表す
再帰下降パーサの肝は演算子優先順位を関数の呼び出し階層で表現すること。AND は OR より強く結合するので、OR を外側、AND を内側にする:
parseCondition() { return this.parseOr(); }
parseOr() {
let left = this.parseAnd();
while (this.isKw("OR")) {
this.next();
const right = this.parseAnd();
left = { type: "or", left, right };
}
return left;
}
parseAnd() {
let left = this.parseNot();
while (this.isKw("AND")) {
this.next();
const right = this.parseNot();
left = { type: "and", left, right };
}
return left;
}
parseNot() {
if (this.isKw("NOT")) { this.next(); return { type: "not", operand: this.parseNot() }; }
return this.parsePredicate();
}
parseOr が parseAnd を呼び、parseAnd が parseNot を呼ぶ。この呼び出しの深さがそのまま結合の強さになる。a=1 OR b=2 AND c=3 をパースすると:
test("AND binds tighter than OR", () => {
const ast = parse("SELECT * FROM t WHERE a=1 OR b=2 AND c=3");
// a=1 OR (b=2 AND c=3) になる
assert.equal(ast.where.type, "or");
assert.equal(ast.where.right.type, "and");
});
OR ノードが最上位で、その右側に AND が入る。括弧 () は parsePredicate で明示的な group ノードになり、優先順位を上書きする。
predicate は比較演算子だけでなく SQL 特有の述語も処理:
parseComparison() {
const left = this.parseExpr();
if (this.isKw("IS")) { /* IS [NOT] NULL */ }
let negated = this.isKw("NOT") ? (this.next(), true) : false;
if (this.isKw("IN")) { /* IN (...) */ }
if (this.isKw("LIKE")) { /* LIKE pattern */ }
if (this.isKw("BETWEEN")) { /* BETWEEN a AND b */ }
// 通常の比較 = < > <= >= <> !=
}
NOT IN / NOT LIKE / NOT BETWEEN の NOT を先読みして各述語に渡しているのがポイント。IS NOT NULL だけは IS の後に NOT が来るので別処理。
explainer: 論理実行順という切り口
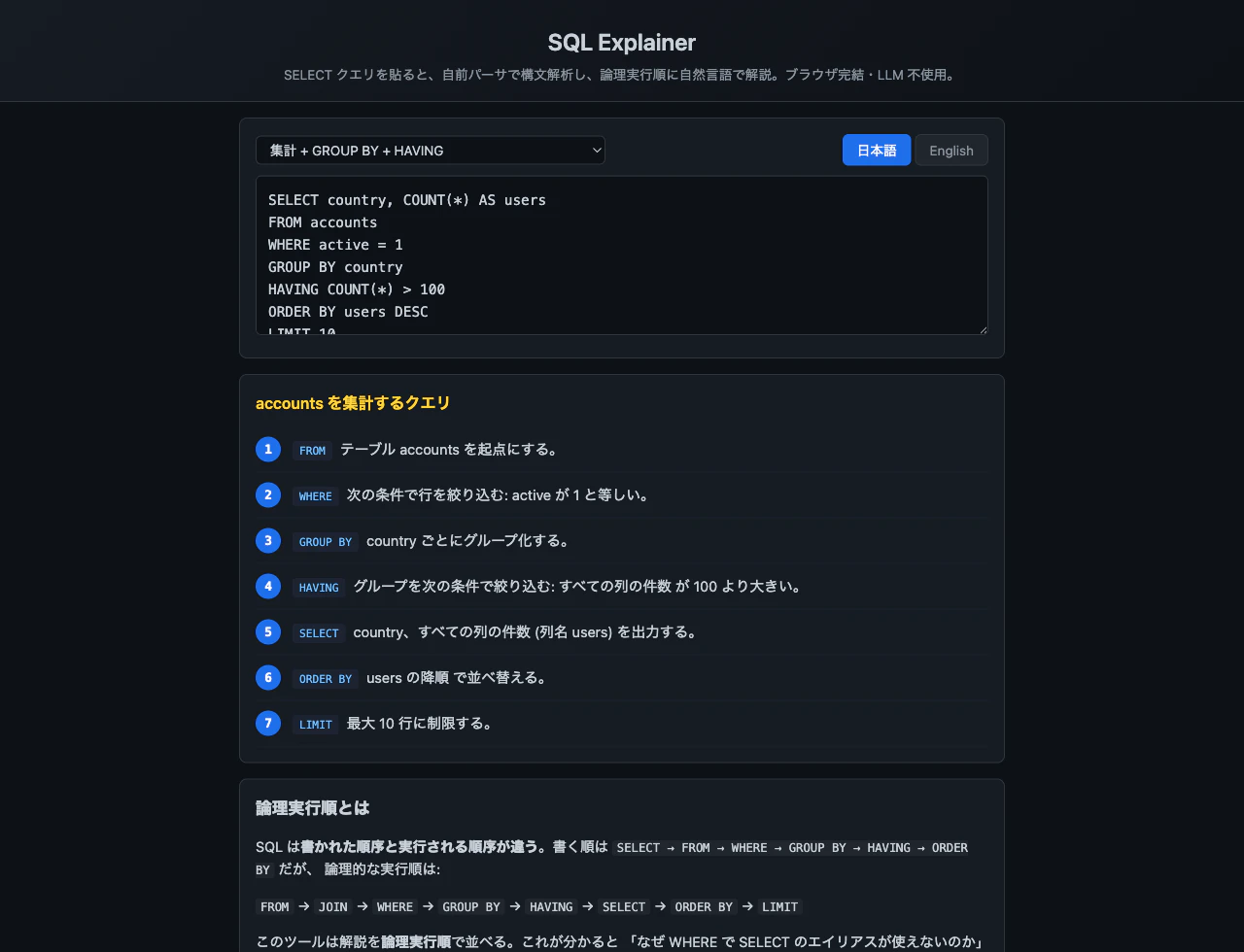
ここが一番の見せ場。SQL は書く順序と実行される順序が違う:
書く順: SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY → LIMIT
実行順: FROM → JOIN → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
SELECT が後ろから 3 番目に実行されるのが鍵。explainer はこの論理実行順でステップを並べる:
export function explain(ast, lang = "ja") {
const steps = [];
// 1. FROM — 起点テーブル
// 2. JOIN — 結合
// 3. WHERE — 行のフィルタ
// 4. GROUP BY — グループ化
// 5. HAVING — グループのフィルタ
// 6. SELECT — 列の出力 (ここで初めて列が確定)
// 7. ORDER BY — 並べ替え
// 8. LIMIT — 行数制限
return steps;
}
順序はテストで保証:
test("full query yields all clauses in logical order", () => {
const ast = parse(`SELECT country, COUNT(*) FROM users
JOIN accounts ON users.id = accounts.user_id
WHERE active = 1 GROUP BY country HAVING COUNT(*) > 10
ORDER BY country LIMIT 5`);
assert.deepEqual(explain(ast, "en").map((s) => s.clause),
["FROM", "JOIN", "WHERE", "GROUP BY", "HAVING", "SELECT", "ORDER BY", "LIMIT"]);
});
なぜこれが教育的か: 論理実行順が分かると、SQL の「謎ルール」が全部腑に落ちる:
- WHERE で SELECT のエイリアスが使えない → WHERE (3) は SELECT (6) より先に実行されるから、エイリアスはまだ存在しない
- 集計列の絞り込みは HAVING で WHERE ではない → WHERE (3) はグループ化 (4) の前。集計値はまだ計算されていない
- ORDER BY では SELECT のエイリアスが使える → ORDER BY (7) は SELECT (6) の後だから
「SQL を説明する」というより「SQL の実行モデルを体感させる」ツールになっている。
AST → 文への変換
条件木を再帰的に文字列化する。日本語と英語で語順が違うので分岐:
function condText(c, lang) {
switch (c.type) {
case "and": return lang === "ja"
? `(${condText(c.left, lang)}) かつ (${condText(c.right, lang)})`
: `(${condText(c.left, lang)}) AND (${condText(c.right, lang)})`;
case "compare": return lang === "ja"
? `${exprText(c.left, lang)} が ${exprText(c.right, lang)} ${OP_JA[c.op]}`
: `${exprText(c.left, lang)} ${OP_EN[c.op]} ${exprText(c.right, lang)}`;
case "between": return lang === "ja"
? `${exprText(c.expr, lang)} が ${low} 〜 ${high} の範囲内`
: `${exprText(c.expr, lang)} is between ${low} and ${high}`;
// ...
}
}
集計関数も自然言語に: COUNT(*) → 「件数」、AVG(price) → 「price の平均」/「the average of price」。
エラーは silent partial parse しない
パースに失敗したら ParseError を投げる。中途半端に解釈して嘘の説明を出すより、エラーを出す方が誠実:
test("missing FROM throws", () => {
assert.throws(() => parse("SELECT *"), ParseError);
});
test("trailing junk throws", () => {
assert.throws(() => parse("SELECT * FROM t garbage extra"), ParseError);
});
test("non-select throws", () => {
assert.throws(() => parse("DELETE FROM t"), ParseError);
});
expectEnd() で「トークンを全部消費したか」を確認するのが効く。SELECT * FROM t garbage のような末尾ゴミを検出できる。
設計
tokenizer.js ← SQL 字句解析
parser.js ← 再帰下降 SELECT パーサ → AST (DOM-free)
explainer.js ← AST → 論理実行順のステップ列, ja/en (DOM-free)
app.js ← UI glue
テスト 35 個。tokenizer (エスケープ・コメント・クォート識別子) + parser (各句・優先順位・エラー) + explainer (論理順・文生成)。
試してみる
サンプルの「複数 JOIN + 複合条件」を選んで、日本語/英語を切り替えてみてほしい。(u.active = 1 OR u.role = 'admin') AND p.published IS NOT NULL のような入れ子条件が、括弧の優先順位を保ったまま自然言語になる。
まとめ
- SQL 解説に LLM は要らない。SELECT サブセットなら tokenizer + 再帰下降パーサを 200 行で書ける。
- 演算子優先順位は関数の呼び出し階層で表す。
parseOr → parseAnd → parseNotの深さ = 結合の強さ。 - 解説を論理実行順 (FROM→WHERE→GROUP BY→SELECT→ORDER BY) で並べると、SQL の「謎ルール」が全部腑に落ちる。
- パースエラーは silent partial parse せず投げる。
expectEnd()で末尾ゴミを検出。 - 3 層 (字句/構文/意味) を分離すると、各層が DOM-free で全部テストできる。
これは SEN 合同会社の OSS ポートフォリオ #263 です。https://sen.ltd/portfolio/