「Date.now で十分」の 5 つの嘘
benchmark.js は事実上メンテされていない。hyperfine は CLI ツールには最高だが JavaScript の関数は扱えない。結局、みんな Date.now() のループをスクラッチファイルに貼り付ける。
const start = Date.now()
for (let i = 0; i < 1_000_000; i++) { myFunction() }
const elapsed = Date.now() - start
console.log(`${elapsed}ms total`)
このコードには 5 つの問題がある:
-
Date.now()はミリ秒精度。1 ミリ秒以下で終わる処理ではクロックの精度を測っている - ウォームアップがない。V8 のベースラインコンパイラで動く最初の数千回は定常状態を反映しない
- サンプルが 1 つ。「50ms」が「50ms ± 40」なのか区別できない
- 戻り値を消費していない。V8 がループ本体を丸ごと削除する可能性がある
- ベースラインがない。前回のコミットで遅くなったのか分からない
ts-bench はこれらすべてに対処する。
📦 GitHub: https://github.com/sen-ltd/ts-bench
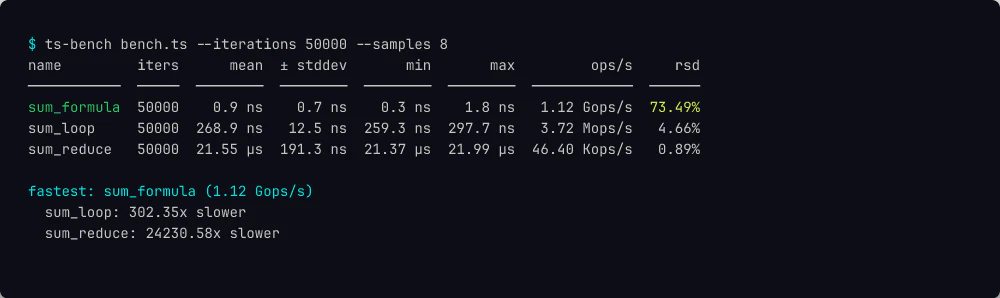
ナノ秒精度と dead-code 防止
export class Runner {
private sink: unknown = undefined
constructor(private readonly now: NowFn) {}
private runBucket(fn: BenchFn, iterations: number): number {
const start = this.now()
for (let i = 0; i < iterations; i++) {
this.sink = fn()
}
const end = this.now()
if (this.sink === Symbol.for('ts-bench/unreachable')) {
throw new Error('unreachable')
}
return Number(end - start)
}
}
2 つのポイント:
-
クロックを注入 — 本番では
process.hrtime.bigint()、テストでは事前にプログラムした bigint 列を返すフェイク -
sinkが dead-code 防止 — 戻り値をインスタンスフィールドに保存し、到達不可能なifで参照する。V8 はフィールドが未読だと証明できないのでループ本体を削除できない
フェイククロックによる決定論的テスト
ウォームアップが確実に捨てられることを証明するテスト:
it('discards warmup buckets so their timings do not influence stats', () => {
const clock = fakeClock([
0n, 10_000n, // warmup 1 (破棄)
10_000n, 20_000n, // warmup 2 (破棄)
20_000n, 20_100n, // sample 1: 100ns / 1 iter
20_100n, 20_200n, // sample 2: 100ns / 1 iter
])
const runner = new Runner(clock)
const result = runner.run('const', () => 0, {
...defaultRunOptions,
iterations: 1,
warmup: 2,
samples: 2,
autoCalibrate: false,
})
expect(result.stats.meanNs).toBe(100)
expect(result.stats.stddevNs).toBe(0)
})
ウォームアップバケットは 10,000ns(本番サンプルの 100 倍遅い)だが、報告される平均は 100ns。ウォームアップがサンプルプールに混入していればテストが大きく失敗する。
標準偏差はノイズへの最初の防壁
export function computeStats(samplesNs: readonly number[]): Stats {
const n = samplesNs.length
let sum = 0
let min = Number.POSITIVE_INFINITY
let max = Number.NEGATIVE_INFINITY
for (const s of samplesNs) {
sum += s
if (s < min) min = s
if (s > max) max = s
}
const mean = sum / n
let variance = 0
if (n > 1) {
let sqSum = 0
for (const s of samplesNs) {
const d = s - mean
sqSum += d * d
}
variance = sqSum / (n - 1) // ベッセルの補正
}
const stddev = Math.sqrt(variance)
const rsd = mean > 0 ? stddev / mean : 0
const opsPerSec = mean > 0 ? 1e9 / mean : 0
return { samples: n, meanNs: mean, minNs: min, maxNs: max,
stddevNs: stddev, rsd, opsPerSec }
}
ベッセルの補正(n-1)を使う理由は、サンプルから母分散を推定しているため。サンプル数が少ないときに差が出る。
human フォーマッタは rsd > 10% のベンチを黄色で表示する:
sum_formula: 0.8 ns ± 0.6 ns, 1.18 Gops/s, 73.52%
RSD 73% は「V8 がベンチ本体を定数畳み込みで消した結果、空ループのスケジューラノイズを測定している」というシステムからのメッセージ。ランナーが問題を表面化するのが重要で、自信満々に「1.18 Gops/s」と報告して PR に貼らせるのは最悪。
自動キャリブレーション
export function estimateIterations(
probeIters: number,
probeNs: number,
targetNs: number
): number {
if (probeIters <= 0 || probeNs <= 0 || targetNs <= 0) return 1
const perIter = probeNs / probeIters
const est = Math.round(targetNs / perIter)
if (!Number.isFinite(est) || est < 1) return 1
if (est > 1_000_000_000) return 1_000_000_000
return est
}
--auto-calibrate では、まず 1,000 回のプローブを実行して 1 反復あたりのナノ秒を推定し、各バケットが約 100ms になるイテレーション数を自動選択する。速いベンチ → 大きなバケット、遅いベンチ → 小さなバケット、実行時間は同程度。
ベースライン比較: CI 向け
export function compareToBaseline(
current: readonly BenchResult[],
baseline: BaselineFile,
thresholdPct = 5
): ComparisonResult {
const baseByName = new Map(baseline.entries.map((e) => [e.name, e]))
const rows: ComparisonRow[] = []
const regressions: string[] = []
for (const r of current) {
const b = baseByName.get(r.name)
if (!b) {
rows.push({ name: r.name, status: 'new',
currentMeanNs: r.stats.meanNs, baselineMeanNs: null,
deltaPct: null })
continue
}
const delta = ((r.stats.meanNs - b.meanNs) / b.meanNs) * 100
let status: ComparisonStatus
if (delta > thresholdPct) {
status = 'slower'
regressions.push(r.name)
} else if (delta < -thresholdPct) {
status = 'faster'
} else {
status = 'same'
}
rows.push({ name: r.name, status,
currentMeanNs: r.stats.meanNs,
baselineMeanNs: b.meanNs, deltaPct: delta })
}
return { rows, regressions }
}
閾値はデフォルト 5%。ゼロ許容だと実行ごとの分散でほぼ毎回「リグレッション」になる。5% は健全なベンチのノイズフロア(rsd < 2%)より広く、実際のアルゴリズムのリグレッションは捕捉できる。
--fail-on-regression で exit 1。GitHub Actions の if: github.event_name == 'pull_request' に入れればパフォーマンスゲートになる。
このツールの限界
- JIT に勝てない — V8 の最適化判定はインライン化、型フィードバック、脱最適化の履歴に依存する。ウォームアップ、戻り値消費、rsd チェックが精一杯
- シングルプロセス — 先に走ったベンチのインラインキャッシュが後のベンチに影響しうる
-
マクロベンチマークではない — 「10k 同時リクエストでの HTTP サーバ性能」は
wrkやk6の領域 - 統計的検定はない — 平均が 1% 以内なら「same」と報告して人間に委ねる
63 アサーション: stats、runner、ベースラインラウンドトリップ、比較ロジック、3 フォーマッタ、引数パース。タイミングテストはフェイククロックでマイクロ秒単位で完了。
試してみる
cat > bench.ts << 'EOT'
export function bench_sum_loop() {
let s = 0
for (let i = 0; i < 1000; i++) s += i
return s
}
export function bench_sum_reduce() {
return Array.from({ length: 1000 }, (_, i) => i)
.reduce((a, b) => a + b, 0)
}
EOT
docker run --rm -v "$PWD":/work ts-bench /work/bench.ts --auto-calibrate
ソース・テスト・Dockerfile: https://github.com/sen-ltd/ts-bench
SEN 合同会社 の 100 超ポートフォリオシリーズ #166。