Thoughtworks Technology Radar Vol 34 (April 2026) の Trial 枠に Semantic layer が戻ってきている。BI / LLM / ダッシュボードが 同じ metric 定義 を共有するためのレイヤ。Snowflake が "Semantic Views"、Databricks が "Metric Views" を出して、もはや BI プラグインではなくデータプラットフォームの一級市民になった。500 行 vanilla JS で JSON で metric を定義 → 次元 + filter で query → SQL を生成 する educational playground を作って、何が嬉しいかを構造で見せた。Tech Radar 試してみた シリーズはこれで 6 件達成、最終回。
🌐 Demo: https://sen.ltd/portfolio/semantic-layer/
📦 GitHub: https://github.com/sen-ltd/semantic-layer
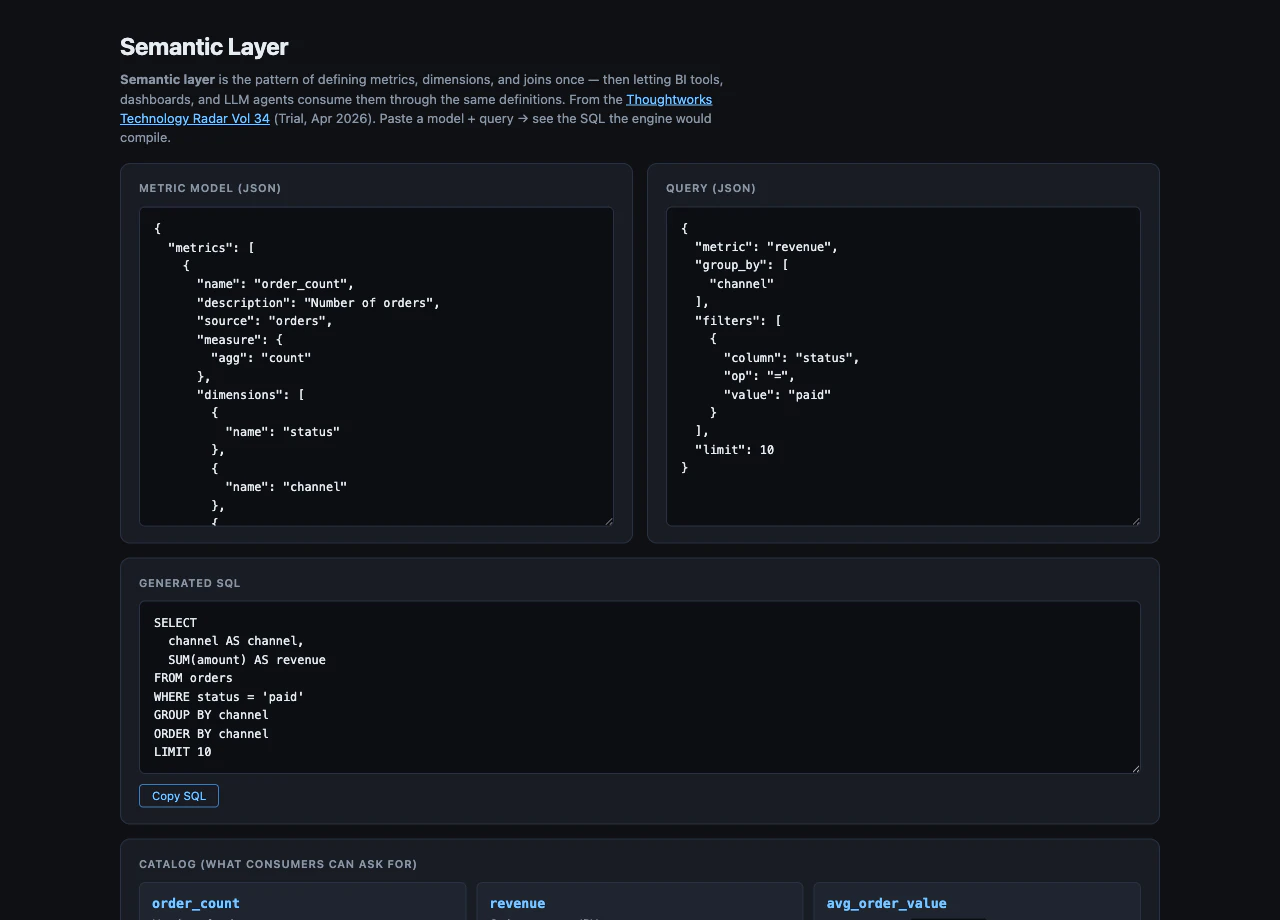
なぜ semantic layer か
「先月の売上いくら?」を 3 つのチームがそれぞれ書く:
- 経営ダッシュボード:
SELECT SUM(amount) FROM orders WHERE month = ... - BI チーム:
SELECT SUM(amount) FROM orders WHERE status = 'paid' AND month = ... - LLM agent:
SELECT SUM(amount) FROM orders(status フィルタを忘れる)
3 つの数字が 微妙に違う。誰の数字が正しいか議論が始まる。これが semantic layer のない世界の典型的失敗。
semantic layer は metric の定義を 1 箇所に集める:
{
"name": "revenue",
"source": "orders",
"measure": { "agg": "sum", "column": "amount" },
"dimensions": [{ "name": "channel" }, { "name": "country" }, { "name": "month" }]
}
これに「業務ルール (refund を除外、status='paid' のみ、月境界は会計月)」をビューや WHERE 句で隠蔽 → 全消費者が同じ数字を見る。LLM が text-to-SQL を生成するときも 生のスキーマではなく semantic layer を読ませる、というのが Radar の主張。
query の形
query 側は「どの metric を、どの次元で割って、どう絞るか」だけを書く:
{
"metric": "revenue",
"group_by": ["channel"],
"filters": [{ "column": "status", "op": "=", "value": "paid" }],
"limit": 10
}
これを compile.js が SQL に変換する:
SELECT
channel AS channel,
SUM(amount) AS revenue
FROM orders
WHERE status = 'paid'
GROUP BY channel
ORDER BY channel
LIMIT 10
定義済みの metric revenue は変えていない。同じ metric を別の query が別の角度から呼ぶ: country で割る、月で割る、両方で割る、フィルタなしで合計。消費者ごとに metric の意味がブレない のがこのパターンの本質。
バリデーション — 「定義済み次元しか聞けない」
semantic layer の真価は 「次元の禁止」 にある。消費者は宣言された次元しか group_by できない。
export function validateQuery(model, query) {
const issues = [];
const metric = (model.metrics || []).find((m) => m.name === query.metric);
if (!metric) {
issues.push({ path: "$.metric", message: `unknown metric: ${query.metric}` });
return issues;
}
const allowed = new Set((metric.dimensions || []).map((d) => d.name || d));
for (let i = 0; i < (query.group_by || []).length; i++) {
const g = query.group_by[i];
if (!allowed.has(g)) {
issues.push({ path: `$.group_by[${i}]`, message: `dimension '${g}' not defined for metric '${metric.name}'` });
}
}
return issues;
}
active_users メトリックに channel 次元が宣言されていなければ、group_by: ["channel"] は 拒否される。「とりあえず join できそうな column 適当に使ってみるか」が物理的に不可能になる。これが「ガードレール」の正体。
LLM が text-to-SQL を生成する場面ではこの効果が直接効く: モデルに見せる次元を絞る ことで、誤 join / 誤 group_by を構造的に防ぐ。
SQL コンパイラ
compile 自体はストレートに「SELECT 句 + FROM + WHERE + GROUP BY + ORDER BY + LIMIT」を組み立てる:
export function compile(model, query) {
const metric = model.metrics.find((m) => m.name === query.metric);
const groupBy = query.group_by || [];
const filters = query.filters || [];
const dimCols = groupBy.map((g) => dimColumn(metric, g));
const selectParts = [];
for (let i = 0; i < groupBy.length; i++) {
selectParts.push(` ${dimCols[i]} AS ${groupBy[i]}`);
}
selectParts.push(` ${aggExpression(metric.measure)} AS ${metric.name}`);
const lines = [
"SELECT",
selectParts.join(",\n"),
`FROM ${metric.source}`,
];
if (filters.length > 0) {
lines.push("WHERE " + filters.map(renderFilter).join("\n AND "));
}
if (groupBy.length > 0) {
lines.push("GROUP BY " + dimCols.join(", "));
lines.push("ORDER BY " + dimCols.join(", "));
}
if (query.limit !== undefined) lines.push(`LIMIT ${query.limit}`);
return lines.join("\n");
}
肝は dimColumn — 単純な column 名なら channel をそのまま出すが、式付き次元 なら式を埋め込む:
{ "name": "month", "expr": "DATE_TRUNC('month', created_at)" }
これがあると group_by: ["month"] で GROUP BY DATE_TRUNC('month', created_at) が出る。「月集計」の式を全消費者が同じ書き方で使える — 会計月の定義変更が 1 箇所で済む。
値リテラルの整形
filter の value 型ごとに引用符を変える地味だが重要な部分:
function formatValue(v) {
if (typeof v === "number") return String(v);
if (typeof v === "boolean") return v ? "TRUE" : "FALSE";
if (v === null) return "NULL";
return `'${String(v).replaceAll("'", "''")}'`;
}
- 文字列 →
'で囲み + シングルクォートエスケープ (SQL インジェクション対策) - 数値 → そのまま (
1000を'1000'にすると比較で罠) - bool → SQL 標準の
TRUE/FALSE - null →
NULL
test("numeric values render unquoted", () => {
const sql = compile(sampleModel, {
metric: "revenue",
filters: [{ column: "amount", op: ">", value: 1000 }],
});
assert.match(sql, /amount > 1000/);
assert.doesNotMatch(sql, /amount > '1000'/);
});
「数値が文字列リテラル化されて DB が文字列比較する」事故は実コードでも起きる。テストで境界を切る。
IN 演算子
function renderFilter(f) {
if (f.op === "in" || f.op === "not in") {
const list = Array.isArray(f.value) ? f.value : [f.value];
return `${f.column} ${f.op.toUpperCase()} (${list.map(formatValue).join(", ")})`;
}
return `${f.column} ${f.op} ${formatValue(f.value)}`;
}
{ column: "country", op: "in", value: ["JP", "US", "DE"] } → country IN ('JP', 'US', 'DE')。これも各値が formatValue を通るので、文字列なら quoted、数値なら unquoted で出る。
3 ドメインの presets
semantic layer は実例で初めて意味が見える。本ツールは 3 種類:
e-commerce orders:
-
order_count(COUNT(*)) -
revenue(SUM(amount)) -
avg_order_value(AVG(amount)) - 共通次元: channel, country, status, month
SaaS user activity:
-
active_users(COUNT(DISTINCT user_id)) -
events_logged(COUNT(*)) - 次元: plan, type, country, day
Support tickets:
-
ticket_count(COUNT(*)) -
avg_resolution_hours(AVG(resolution_hours)) - 次元: priority, team, month
それぞれ「同じ metric を別の次元で割る」「filter を変える」 → SQL がリアルタイムで再生成される、を体感できる。
教育ツールとしての限界
実 production engine がやっていて本ツールが省いていること:
-
複数 source の join —
ordersとcustomersを結合して「国別売上」を出すなど -
time grain expansion —
monthをquarter/yearに rollup する自動展開 - access control — 「マーケチームは収益データ見られない」 みたいなロール base
- materialization — 重い query を pre-aggregate してキャッシュ
- multi-cube join — 異なる metric を同じ次元で並べる
これらは production engine (dbt MetricFlow, Cube.dev, Snowflake Semantic Views, Databricks Metric Views) が担う領域。本ツールは 「定義 1 箇所、消費者多数」というアーキテクチャの骨格 を見せるためのおもちゃ。
まとめ
- semantic layer の本質は 「同じ metric 定義を全消費者が共有する」 こと
- 真価は 「定義済み次元しか問えない」というガードレール — text-to-SQL のような自由度の高い消費者を制約するのに特に効く
-
式付き次元 (
DATE_TRUNC('month', created_at)) で時系列の業務ルールを 1 箇所に閉じ込める - literal 整形 は地味だが重要 — 数値の quote ミスは比較バグの典型
- 実 production は dbt MetricFlow / Cube.dev / Snowflake / Databricks の各 engine で、本ツールは 「なぜそういう engine があるか」を理解する用 のおもちゃ
- Tech Radar 試してみた シリーズはこれで 6 件達成 (TOON / Markdown→Typst / Schema→LLM Prompt / Server-driven UI / Mutation testing / Semantic layer)
リポジトリ: https://github.com/sen-ltd/semantic-layer
このツールは弊社の OSS ポートフォリオ #252 として作成しました。Tech Radar 試してみた シリーズ最終回。前回までの 5 件: #247 TOON, #248 Markdown → Typst, #249 Schema → LLM Prompt, #250 Server-driven UI, #251 Mutation Testing。SEN 合同会社(東京)では小さくて切れ味のあるツール群を継続的に公開しています: https://sen.ltd/portfolio/