OSS の開発に興味があり、先日 Optuna V3 開発スプリント に参加させていただきました。Optuna 自体はそれほど触ったことがなかったのですが、Optuna 初心者でも開発ができるようにコミッタの方々が色々と手助けをしてくださったおかげで開発をうまく進めることができ、とても良い経験になりました。
そこで Optuna を実際に使ってみる方にも興味が出てきたので、趣味のパズルプログラミングに応用してみることにしました。
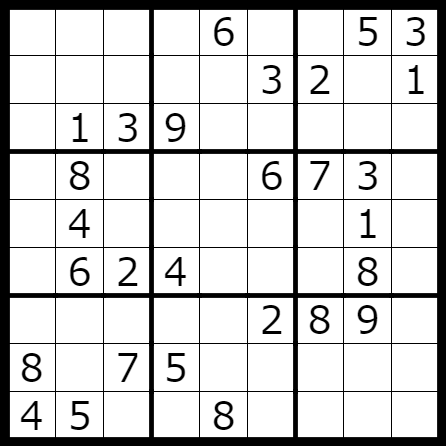
ナンバープレイス(数独)について
ご存知の方も多いと思いますが、ナンバープレイスとは次のようなルールのパズルです。
- 各空白マスに 1~9 の数字を入れる。
- 各行、各列、各ブロックには 1~9 の数字がそれぞれちょうど 1 個ずつ含まれるようにする。
ナンバープレイスを解く方法
全探索による方法、人間が解くときのようにルールベースで解く方法、Knuth's Algorithm X を使う方法 など色々ありますが、今回は SMT ソルバー z3 を利用します。
解を 1 つ求めるだけであれば、SMT で条件を書き下せばよく、次のようなコードで解くことができます。
import z3
def solve_sudoku(problem):
solver = z3.Solver()
vars = []
for i in range(9):
row = []
for j in range(9):
v = z3.Int(f"ans_{i}_{j}")
if problem[i][j] == 0:
solver.add(1 <= v, v <= 9)
else:
solver.add(v == problem[i][j])
row.append(v)
vars.append(row)
blocks = []
for i in range(9):
blocks.append([(i, j) for j in range(9)])
blocks.append([(j, i) for j in range(9)])
blocks.append([(i // 3 * 3 + j // 3, i % 3 * 3 + j % 3) for j in range(9)])
for block in blocks:
solver.add(z3.Distinct([vars[i][j] for i, j in block]))
if solver.check() == z3.unsat:
return None
model = solver.model()
ans = [[model[vars[i][j]].as_long() for j in range(9)] for i in range(9)]
return ans
これを利用して、上の例題を解かせてみましょう。
def main():
problem = [
[0, 0, 0, 0, 6, 0, 0, 5, 3],
[0, 0, 0, 0, 0, 3, 2, 0, 1],
[0, 1, 3, 9, 0, 0, 0, 0, 0],
[0, 8, 0, 0, 0, 6, 7, 3, 0],
[0, 4, 0, 0, 0, 0, 0, 1, 0],
[0, 6, 2, 4, 0, 0, 0, 8, 0],
[0, 0, 0, 0, 0, 2, 8, 9, 0],
[8, 0, 7, 5, 0, 0, 0, 0, 0],
[4, 5, 0, 0, 8, 0, 0, 0, 0],
]
print(solve_sudoku(problem))
$ python solver.py
[[2, 7, 8, 1, 6, 4, 9, 5, 3], [5, 9, 4, 8, 7, 3, 2, 6, 1], [6, 1, 3, 9, 2, 5, 4, 7, 8], [9, 8, 1, 2, 5, 6, 7, 3, 4], [7, 4, 5, 3, 9, 8, 6, 1, 2], [3, 6, 2, 4, 1, 7, 5, 8, 9], [1, 3, 6, 7, 4, 2, 8, 9, 5], [8, 2, 7, 5, 3, 9, 1, 4, 6], [4, 5, 9, 6, 8, 1, 3, 2, 7]]
このように、正しく解けていることが確かめられます。
自動生成に使えるソルバー
以前自動生成について説明する記事を書きました。ここにある通り、自動生成に使うソルバーでは「決定できるマスの個数が何個か」がわかる、ということが重要になります。ところが、先程書いたソルバーでは単に解を 1 個求めるだけで、複数解がある場合に「絶対に決められるのはどこか」というのを知ることはできません。
さて、このように「決まるところを全部知りたい」という場合には、先日の記事に書いたように、解を 1 個求める操作を複数回行うのが有効です。これを実装してみると、先程の solver.py の return ans の行が次のようになります。
while True:
extra_conds = []
for i in range(9):
for j in range(9):
if ans[i][j] is not None:
extra_conds.append(vars[i][j] != ans[i][j])
solver.add(z3.Or(extra_conds))
if solver.check() == z3.unsat:
return ans
model = solver.model()
for i in range(9):
for j in range(9):
if ans[i][j] is not None and ans[i][j] != model[vars[i][j]].as_long():
ans[i][j] = None
これで先程の例題を解かせてみても、やはりすべてのマスが決定できること、すなわち先程の問題は唯一解であったことが確かめられます(適当にヒント数字を 0 に置き換えてみると、決まらないマスが出てくることも確かめられます)。
最適化問題として見た自動生成
以前の記事に書いたように、パズルの自動生成は、入力をヒント数字の配列として、決定できるマスの個数を最適化する問題とみなすことができます。ただし、パズルに解がない場合は問題外なのでスコアを実質的に負の無限大とすることにします。
Optuna での自動生成
このようにすると、Optuna を使って次のように自動生成器を簡単に書くことができます:
import optuna
from solver import solve_sudoku
def objective(trial):
board = [
[max(0, trial.suggest_int(f"clue_{i}_{j}", 0, 9)) for j in range(9)] for i in range(9)
]
answer = solve_sudoku(board)
if answer is not None:
score = 0
for i in range(9):
for j in range(9):
if answer[i][j] is not None:
score += 1
if score == 81:
for y in range(9):
for x in range(9):
print(board[y][x], end=" ")
print()
raise Exception("complete problem found")
return score
else:
return -100
def main():
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=10000)
if __name__ == "__main__":
main()
score == 81 のときに例外を出しているのは、最適化を objective の中から無理矢理止めるためです。
ところが、これはいくら動かしても best score が -100 から動かない、すなわち解がある問題を見つけることすらできていないことがわかります。Optuna の出すログを見ると、
[I 2021-12-19 23:27:58,539] Trial 610 finished with value: -100.0 and parameters: {'clue_0_0': 7, 'clue_0_1': 8, 'clue_0_2': 6, 'clue_0_3': 4, 'clue_0_4': 1, 'clue_0_5': 0, 'clue_0_6': 3, 'clue_0_7': 0, 'clue_0_8': 9, 'clue_1_0': 5, 'clue_1_1': 9, 'clue_1_2': 0, 'clue_1_3': 1, 'clue_1_4': 1, 'clue_1_5': 7, 'clue_1_6': 0, 'clue_1_7': 4, 'clue_1_8': 3, 'clue_2_0': 3, 'clue_2_1': 9, 'clue_2_2': 8, 'clue_2_3': 9, 'clue_2_4': 0, 'clue_2_5': 4, 'clue_2_6': 7, 'clue_2_7': 6, 'clue_2_8': 1, 'clue_3_0': 0, 'clue_3_1': 7, 'clue_3_2': 9, 'clue_3_3': 7, 'clue_3_4': 4, 'clue_3_5': 3, 'clue_3_6': 1, 'clue_3_7': 0, 'clue_3_8': 4, 'clue_4_0': 7, 'clue_4_1': 7, 'clue_4_2': 8, 'clue_4_3': 6, 'clue_4_4': 2, 'clue_4_5': 0, 'clue_4_6': 1, 'clue_4_7': 9, 'clue_4_8': 9, 'clue_5_0': 9, 'clue_5_1': 2, 'clue_5_2': 8, 'clue_5_3': 9, 'clue_5_4': 1, 'clue_5_5': 1, 'clue_5_6': 6, 'clue_5_7': 7, 'clue_5_8': 4, 'clue_6_0': 5, 'clue_6_1': 5, 'clue_6_2': 0, 'clue_6_3': 0, 'clue_6_4': 4, 'clue_6_5': 0, 'clue_6_6': 0, 'clue_6_7': 4, 'clue_6_8': 5, 'clue_7_0': 8, 'clue_7_1': 7, 'clue_7_2': 9, 'clue_7_3': 9, 'clue_7_4': 6, 'clue_7_5': 0, 'clue_7_6': 8, 'clue_7_7': 7, 'clue_7_8': 7, 'clue_8_0': 4, 'clue_8_1': 6, 'clue_8_2': 8, 'clue_8_3': 5, 'clue_8_4': 9, 'clue_8_5': 0, 'clue_8_6': 8, 'clue_8_7': 6, 'clue_8_8': 2}. Best is trial 0 with value: -100.0.
このように大量のヒントを置いていて、そもそも最初のヒントの時点で明らかにルールに違反している問題ばかりが出てきていると推測されます。そこで、解がない場合は実質負の無限大の -100 に加えて、さらにヒントの個数に応じたペナルティを課すようにして、ヒントを減らす方向の圧力をかけてみましょう。
...
return score
else:
penalty = 0
for i in range(9):
for j in range(9):
if board[i][j] != 0:
penalty += 1
return -100 - penalty
こうしてみても、スコアが増える速度は遅く、一向に問題ができそうにありません。せっかくなので別の sampler も試してみましょう。ここでは、遺伝的アルゴリズムに基づく NSGAIISampler を使ってみることにします。
def main():
sampler = optuna.samplers.NSGAIISampler()
study = optuna.create_study(direction="maximize", sampler=sampler)
study.optimize(objective, n_trials=10000)
こうすると、さっきよりだいぶ速く trial が進み、順調にスコアを上げていきます(デフォルトの sampler よりも NSGAIISampler のほうが速いようです)。そして、ついに問題を生成することができました!
[I 2021-12-19 23:39:58,005] Trial 5071 finished with value: -126.0 and parameters: {'clue_0_0': 2, 'clue_0_1': 0, 'clue_0_2': 0, 'clue_0_3': 8, 'clue_0_4': 0, 'clue_0_5': 6, 'clue_0_6': 1, 'clue_0_7': 9, 'clue_0_8': 0, 'clue_1_0': 0, 'clue_1_1': 0, 'clue_1_2': 0, 'clue_1_3': 0, 'clue_1_4': 0, 'clue_1_5': 0, 'clue_1_6': 0, 'clue_1_7': 3, 'clue_1_8': 4, 'clue_2_0': 0, 'clue_2_1': 0, 'clue_2_2': 0, 'clue_2_3': 1, 'clue_2_4': 2, 'clue_2_5': 0, 'clue_2_6': 0, 'clue_2_7': 0, 'clue_2_8': 0, 'clue_3_0': 0, 'clue_3_1': 3, 'clue_3_2': 0, 'clue_3_3': 7, 'clue_3_4': 0, 'clue_3_5': 1, 'clue_3_6': 0, 'clue_3_7': 0, 'clue_3_8': 2, 'clue_4_0': 0, 'clue_4_1': 8, 'clue_4_2': 6, 'clue_4_3': 0, 'clue_4_4': 0, 'clue_4_5': 3, 'clue_4_6': 0, 'clue_4_7': 0, 'clue_4_8': 7, 'clue_5_0': 0, 'clue_5_1': 0, 'clue_5_2': 4, 'clue_5_3': 0, 'clue_5_4': 6, 'clue_5_5': 0, 'clue_5_6': 0, 'clue_5_7': 0, 'clue_5_8': 9, 'clue_6_0': 0, 'clue_6_1': 0, 'clue_6_2': 0, 'clue_6_3': 0, 'clue_6_4': 0, 'clue_6_5': 0, 'clue_6_6': 0, 'clue_6_7': 0, 'clue_6_8': 0, 'clue_7_0': 0, 'clue_7_1': 0, 'clue_7_2': 2, 'clue_7_3': 0, 'clue_7_4': 7, 'clue_7_5': 0, 'clue_7_6': 0, 'clue_7_7': 0, 'clue_7_8': 1, 'clue_8_0': 5, 'clue_8_1': 0, 'clue_8_2': 0, 'clue_8_3': 0, 'clue_8_4': 0, 'clue_8_5': 8, 'clue_8_6': 4, 'clue_8_7': 0, 'clue_8_8': 0}. Best is trial 4950 with value: 74.0.
2 0 0 8 0 6 1 9 0
0 0 0 0 0 0 0 3 4
0 0 0 1 2 0 0 0 0
0 3 0 7 0 5 0 0 2
0 8 6 0 0 3 0 0 7
0 0 0 0 6 0 0 0 9
1 4 0 5 0 0 0 0 0
0 0 2 0 0 0 0 0 1
5 0 0 0 0 8 0 0 0
[W 2021-12-19 23:39:58,063] Trial 5072 failed because of the following error: Exception('complete problem found')
高速化
NSGAIISampler は遺伝的アルゴリズムに基づく手法なので、解が存在する問題が最初から個体集合の中に入っていると、最初解が存在するようになるまで探索を繰り返すところを速くできそうです。そこで、enqueue_trial を使って、1 回目の探索時の問題を指定してみましょう。ここでは、自明な問題ではありますがヒントが一切ない問題を指定してみます。
def main():
sampler = optuna.samplers.NSGAIISampler()
study = optuna.create_study(direction="maximize", sampler=sampler)
initial_trial = dict()
for i in range(9):
for j in range(9):
initial_trial[f"clue_{i}_{j}"] = 0
study.enqueue_trial(initial_trial)
study.optimize(objective, n_trials=10000)
この場合、最初の 1 回目の trial にやたらと時間がかかりますが(z3 の探索アルゴリズムの問題?)より少ない trial で問題を生成することができました。
[I 2021-12-19 23:58:05,094] Trial 2225 finished with value: 35.0 and parameters: {'clue_0_0': 0, 'clue_0_1': 0, 'clue_0_2': 8, 'clue_0_3': 0, 'clue_0_4': 0, 'clue_0_5': 0, 'clue_0_6': 0, 'clue_0_7': 0, 'clue_0_8': 0, 'clue_1_0': 0, 'clue_1_1': 0, 'clue_1_2': 0, 'clue_1_3': 0, 'clue_1_4': 1, 'clue_1_5': 0, 'clue_1_6': 5, 'clue_1_7': 0, 'clue_1_8': 0, 'clue_2_0': 3, 'clue_2_1': 5, 'clue_2_2': 4, 'clue_2_3': 0, 'clue_2_4': 0, 'clue_2_5': 0, 'clue_2_6': 7, 'clue_2_7': 0, 'clue_2_8': 0, 'clue_3_0': 0, 'clue_3_1': 1, 'clue_3_2': 0, 'clue_3_3': 0, 'clue_3_4': 6, 'clue_3_5': 4, 'clue_3_6': 0, 'clue_3_7': 0, 'clue_3_8': 0, 'clue_4_0': 0, 'clue_4_1': 0, 'clue_4_2': 0, 'clue_4_3': 5, 'clue_4_4': 7, 'clue_4_5': 0, 'clue_4_6': 0, 'clue_4_7': 0, 'clue_4_8': 0, 'clue_5_0': 5, 'clue_5_1': 8, 'clue_5_2': 0, 'clue_5_3': 0, 'clue_5_4': 0, 'clue_5_5': 0, 'clue_5_6': 0, 'clue_5_7': 7, 'clue_5_8': 9, 'clue_6_0': 7, 'clue_6_1': 0, 'clue_6_2': 0, 'clue_6_3': 0, 'clue_6_4': 0, 'clue_6_5': 0, 'clue_6_6': 0, 'clue_6_7': 9, 'clue_6_8': 4, 'clue_7_0': 0, 'clue_7_1': 0, 'clue_7_2': 2, 'clue_7_3': 0, 'clue_7_4': 0, 'clue_7_5': 6, 'clue_7_6': 0, 'clue_7_7': 0, 'clue_7_8': 0, 'clue_8_0': 0, 'clue_8_1': 0, 'clue_8_2': 0, 'clue_8_3': 7, 'clue_8_4': 2, 'clue_8_5': 0, 'clue_8_6': 0, 'clue_8_7': 0, 'clue_8_8': 0}. Best is trial 1671 with value: 77.0.
0 0 8 0 0 0 0 0 0
0 0 0 0 1 0 5 0 0
3 0 4 8 0 0 7 0 0
0 1 0 0 6 4 0 0 0
0 9 0 5 7 0 0 0 0
5 8 0 0 0 0 0 7 9
7 0 0 0 0 0 0 9 4
0 0 2 0 0 6 0 0 0
0 0 0 7 2 0 0 0 1
[W 2021-12-19 23:58:05,150] Trial 2226 failed because of the following error: Exception('complete problem found')
まとめ
Optuna はハイパーパラメータ探索などによく用いられると思いますが、それとは傾向が違うと考えられるパズルの自動生成にも適用できることがわかりました。
注意
ナンバープレイスを解く場合は z3 よりも CSP ソルバー(Sugar など)を使うほうが速いようです。
また途中でも触れましたが、パズルの生成ではヒントが多すぎて明らかな矛盾を起こしているような場合をあまり踏まないようにしたほうが良いようで、何もヒントが置かれていない状態から始めて焼きなまし法を行うなどしたほうが効率が良いようです。