はじめに
様々なテキストファイル(様々な文字コード)やバイナリファイルを精査する時に使えるツールがほしいなー と思ったので作ってみた。
ライブラリはlibyaraを使用
要するに、C-FFIで表面だけ作ってみたってやつ
今回使うツールのリポジトリ
関連記事(Qiita) RustのFFI経由でlibyaraを使う。
(祝)マルチスレッドに対応しました
32スレッドくらいで流すと早い
-t 32とかやるといい。
デフォルトスレッド数(自動で決まるもの)は「CPUコア数x2倍~32スレッド」まで。
手動指定は制限なし(計算リソースの制限が上限)
使い方
バイナリをここからダウンロードするか
リポジトリのソースをビルドしてバイナリを得る。
yarust.exe --rule rule.yr --path ./
こうすると、rule.yrに従ってディレクトリまたはファイルをスキャンして、一致した箇所を出してくれる
日本語ヘルプ
yarust 1.0.1
segfo <k.segfo@gmail.com>
USAGE:
yarust.exe [OPTIONS] --rule <rule_file> --path <search_path>
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-r, --rule <rule_file> YARAルールのファイルパスを指定する
-w, --width <scope_width> 一致箇所から表示する前後任意のバイト数を指定(デフォルト20バイト)
-p, --path <search_path> 探索対象のファイルかディレクトリのパスを指定する
スキャン対象ファイル
ぶっちゃけなんでもいい。
この記事では以下のファイルを対象にする。
https://github.com/segfo/yarust/blob/ba544c8dc8cae940ec7ccf53100ce2e4c09e634a/src/main.rs
日本語入ってて文字コードも考慮しなきゃいけないしサンプルとしては良さそう。
スキャンルールの定義(Yaraルールの定義)
test.yr
rule ascii_string
{
meta:
author = "segfo"
date = "2018/05/15"
description = "sample"
strings:
$damn = "AAAAAAAAAAAABBBBBBBBBBBBCCCCCCCCC"
$abc = "abcdefghijk"
$main = "main" nocase
$crate = " crate" nocase
condition:
any of them
}
rule sjis
{
meta:
author = "segfo"
date = "2018/05/15"
description = "sample"
strings:
$scan = {83 58 83 4C 83 83 83 93}
condition:
any of them
}
rule utf8
{
meta:
author = "segfo"
date = "2018/05/15"
description = "sample"
strings:
$scan = {E3 82 B9 E3 82 AD E3 83 A3 E3 83 B3}
condition:
any of them
}
実行結果

日本語にもちゃんとマッチしてていい感じ。
じゃあ、UTF-8の部分バイトにマッチさせたらどうなるのかやってみよう
ルールの定義
test.yr
rule ascii_string
{
meta:
author = "segfo"
date = "2018/05/15"
description = "sample"
strings:
$damn = "AAAAAAAAAAAABBBBBBBBBBBBCCCCCCCCC"
$abc = "abcdefghijk"
$main = "main" nocase
$crate = " crate" nocase
condition:
any of them
}
rule sjis
{
meta:
author = "segfo"
date = "2018/05/15"
description = "sample"
strings:
$scan = {83 58 83 4C 83 83 83 93}
condition:
any of them
}
rule utf8
{
meta:
author = "segfo"
date = "2018/05/15"
description = "sample"
strings:
$scan = {E3 82 B9 E3}
condition:
any of them
}
実行結果
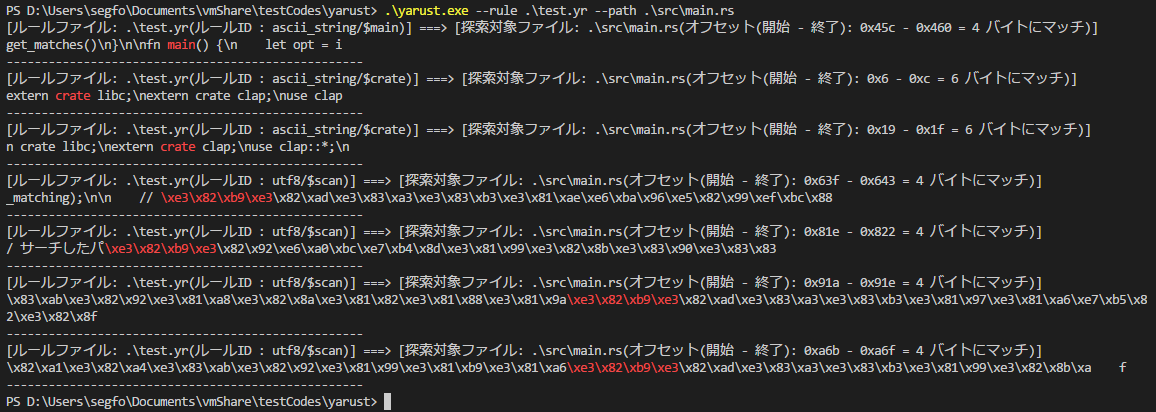
ちゃんと、部分バイトに一致してる!というわけで
なんかいろいろ文字コードが混在してるようなファイルたちから
特定の文字列やバイト列を検索して列挙したいよー という需要があれば使ってみてはいかがでしょうか。
おわりに
Rustはいいぞ