はじめに
最近Blenderをいじってたんですよ、でも若干飽きたからプログラムを作ることにしたよ。
前々から家計簿作りたいなーって思ってた、けどやる気起こらんかったんよ。
んで前述のBlenderに飽きた話があるんだけど、そこで燃料がたまったっぽいので火が付いた。
いやなんの話しとるんや。この項目いる???いらんけど書いとこ
モチベーション
いつどこで買うと何が安い っていう情報をLLMにレコメンドしてほしいから作った。
ほら、「どこそこの店(スーパー)は、いつ(春|夏|秋|冬)、どんな商品(肉|魚|野菜)が安い」っていうのあるじゃない、
でもあれ覚えるの結構めんどくさくて季節ごとに変わるからしんどいんだよね。
旬のものは量が取れるので安くなる傾向にあるし、地域差もある。
(近年季節だけで言うならそうでもなくなってきている感覚もありつつ)
一応、底値とベース、季節・地域による価格変動の傾向が分かれば、比較検討もしやすいじゃないすか
ってことでLLMにそういうの丸投げしたら楽だよねー って思ったから作った。
あとこれを応用して、CSVからデータ整理すれば在庫管理もできると思っていて
「今冷蔵庫に何があるからその材料で主菜と副菜レシピ考えてやー」 とかもできる。
この記事書いてからやりたいこと思い出したわ
実行環境
LLM・クライアントアプリ実行環境
HW: EVO-X2 128GB 2T(Unified Memory 128GBモデル)
OS: Windows 11 Pro
LLM Runner: LM Studio
Dify実行環境
OS: Windows 11 Pro(WSL)
LLM: ホストOS上のLMStudioを使用する
使用するモデル
LLM: GLM 4.5 Air(のGGUF量子化版)
選定理由
GPT-OSS120bよりもデフォでしっかり考えてくれる。手を抜けるからw
VLM: japanese-receipt-vl-3b-json
選定理由:日本のレシートを読み取ってくれる賢い子っぽいので
難所
- プロンプトとOCR精度
- LLMとVLMの役割分担
これをざっくりいうと
OCR用のVLMに「XXのフォーマットで出力せぇ」っていうと
VLM「わかった!(うーん)読み取ったよ!(なんか忘れたような気がするけどいいかぁ)」
ってなって、情報がうまく載らない状況に陥りました。
なので、出力フォーマットのプロンプトはお蔵入りになりました。
OCRは頭使わず読み取ったものを全部後の処理にぶん投げてくれ~!という風にしており
何も考えられずに構造を持たないただのOCRテキストの構造化や意味解析は、頭のいいLLM(今回はGLM 4.5-Air)を使い情報を整理するという方向性で実装しています。
レシート読み込みまでの使い方
レシートを読み込む
Android(Google Pixel 9a)を使っているのでGoogle Driveまたはカメラアプリをレシートにかざすと「ドキュメントをスキャン」というような奴が出てくるのでそれでスキャンする
そのあとPDF化する
システムとのレシートファイル共有
Syncthingを使い、レシートの写真を撮ったら、システム側に自動的に転送される設定をしておく
NATトラバーサル無効にすることでSTUN・TURNサーバを使わなくできるのでここはお好きに。ローカル転送のみにもできるのでよき
送信だけできればいいので、送信モードにしておく
送受信モードだと、アプリを実行した瞬間に転送したファイルがスマホから消えるので、意図しない動作になりそう
プログラムの実行
あとはポチるだけ。PDFから画像の取り出しとワークフローが走りいい感じにcsvが出来上がる。9割くらい正解するので残り1割は手修正するだけでOK
システムの設計と実装
雑に設計した設計資料です。ご査収ください。
コンポーネントの配置
利用シーケンス
クライアントのフローチャート
OCRのシステムプロンプト(全情報読み取りx2)
あなたはレシートを読み取るAIです
すべての項目を読み取ってください
OCRのシステムプロンプト(時刻情報読み取り)
あなたはレシートを読み取るAIです
時刻情報のみ読み取ってください
JSON正規化システムプロンプト
ユーザから渡されたOCRされた結果を構造化項目に投入することがあなたの役割です。
複数のVLMにOCRを任せており、特に店舗の情報や時刻の情報を注力して取らせています。
表記が異なるけれども、意味的には重複する情報もあります。
以下を検討し、投入してください。
- 値の適切性
- 項目の適切性
- 重複項目の排除
クライアントアプリ
必要なライブラリ
requests
python-dotenv
PyMuPDF
Pillow
環境セットアップ
uv venv
uv pip -r requirements.txt
ソース
import requests
from dotenv import load_dotenv
import os
import csv
from datetime import datetime
import fitz # PyMuPDF
from pathlib import Path
import json
load_dotenv()
api_key = os.getenv("DIFY_RECEIPT_READER_API")
url_base = "http://localhost:3000/v1/"
data = {
"user": "receipt2csv"
}
def list_receipt_pdfs(receipt_dir: str) -> list[str]:
"""指定されたディレクトリ内のpdfファイルをリストアップする
Args:
receipt_dir: pdfファイルが保存されているディレクトリのパス
Returns:
pdfファイルのパスのリスト
"""
supported_extensions = {'.pdf'}
pdf_files = []
for entry in os.scandir(receipt_dir):
if entry.is_file() and os.path.splitext(entry.name)[1].lower() in supported_extensions:
pdf_files.append(entry.path)
return pdf_files
def list_receipt_images(receipt_dir: str) -> list[str]:
"""指定されたディレクトリ内の画像ファイルをリストアップする
Args:
receipt_dir: 画像ファイルが保存されているディレクトリのパス
Returns:
画像ファイルのパスのリスト
"""
supported_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.webp', '.svg'}
image_files = []
for entry in os.scandir(receipt_dir):
if entry.is_file() and os.path.splitext(entry.name)[1].lower() in supported_extensions:
image_files.append(entry.path)
return image_files
def receipt_json_to_csv_rows(receipt_json: dict) -> list[list[str]]:
"""
レシートJSONをCSV用の複数行データに変換する
(products の数だけ行ができる)
CSV項目:
store_name, store_address, store_phone,
date, time,
product_code, product_name, quantity, price,
subtotal, tax_percent, final_total
Args:
receipt_json: レシートJSONデータ
Returns:
CSV用の行データリスト(各products要素ごとに1行)
"""
rows = []
# store情報を抽出
store_info = receipt_json.get("store_information", {})
store_name = store_info.get("name", "")
store_address = store_info.get("address", "")
store_phone = store_info.get("phone_number", "")
# date_and_time情報を抽出
date_time = receipt_json.get("date_and_time", {})
date = date_time.get("date", "")
time = date_time.get("time", "")
# total_summary情報を抽出
total_summary = receipt_json.get("total_summary", {})
subtotal = total_summary.get("subtotal", "")
tax_percent = total_summary.get("tax_percent", "")
final_total = total_summary.get("final_total", "")
# products配列から各商品情報を抽出
products = receipt_json.get("products", [])
for product in products:
product_code = product.get("product_code", "")
product_name = product.get("product_name", "")
quantity = str(product.get("quantity", ""))
price = str(product.get("price", ""))
# 1行分のデータを作成
row = [
store_name, # store_name
store_address, # store_address
store_phone, # store_phone
date, # date
time, # time
product_code, # product_code
product_name, # product_name
quantity, # quantity
price, # price
subtotal, # subtotal
tax_percent, # tax_percent
final_total # final_total
]
rows.append(row)
return rows
def judge_mime(image_name):
ext = os.path.splitext(image_name)[1].lower()
if ext == ".jpg" or ext == ".jpeg":
return "image/jpeg"
elif ext == ".png":
return "image/png"
elif ext == ".gif":
return "image/gif"
elif ext == ".webp":
return "image/webp"
elif ext == ".svg":
return "image/svg+xml"
else:
return "application/octet-stream" # 不明な場合のデフォルトMIMEタイプ
def upload_file(file_path, user):
upload_url = url_base+"files/upload"
headers = {
"Authorization": f"Bearer {api_key}"
}
try:
print("ファイルをアップロードしています...")
# 拡張子からMIMEタイプを推測する
basename = os.path.basename(file_path)
mimetype = judge_mime(basename)
with open(file_path, 'rb') as file:
files = {
'file': (basename, file, mimetype) # ファイルが適切な MIME タイプでアップロードされていることを確認してください
}
data = {
"user": user,
"type": "image" # ファイルタイプをTXTに設定します
}
response = requests.post(upload_url, headers=headers, files=files, data=data)
if response.status_code == 201: # 201 は作成が成功したことを意味します
print("ファイルが正常にアップロードされました")
return response.json().get("id") # アップロードされたファイルIDを取得する
else:
print("file_path:",file_path)
print("アップロードレスポンス:",response.text)
print(f"ファイルのアップロードに失敗しました。ステータス コード: {response.status_code}")
return None
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
return None
def run_workflow(file_id, user, response_mode="blocking"):
workflow_url = url_base+"workflows/run"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"inputs": {
"receipt": {
"transfer_method": "local_file",
"upload_file_id": file_id,
"type": "image"
}
},
"response_mode": response_mode,
"user": user
}
try:
print("ワークフローを実行...")
response = requests.post(workflow_url, headers=headers, json=data)
if response.status_code == 200:
print("ワークフローが正常に実行されました")
return response.json()
else:
print("アップロードレスポンス:",response.text)
print(f"ワークフローの実行がステータス コードで失敗しました: {response.status_code}")
return {"status": "error", "message": f"Failed to execute workflow, status code: {response.status_code}"}
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
return {"status": "error", "message": str(e)}
def upload_receipt_and_get_json(image_path: str) -> dict:
"""
レシート画像をアップロードし、解析済みJSONを返す
"""
id = upload_file(image_path, "receipt2csv")
result = run_workflow(id,"receipt2csv")
return result
def ensure_csv_exists(csv_path: str, header: list[str]) -> None:
"""
CSVが存在しなければヘッダ付きで作成する
"""
if not os.path.exists(csv_path):
with open(csv_path, "w", encoding="utf-8") as f:
f.write(",".join(header) + "\n")
def move_receipt_to_done(image_path: str, done_dir: str) -> None:
"""
処理済み画像を done フォルダへ移動
"""
if not os.path.exists(done_dir):
os.makedirs(done_dir)
base_name = os.path.basename(image_path)
done_path = os.path.join(done_dir, base_name)
os.rename(image_path, done_path)
def flatten_json(obj: dict, parent_key="", sep="_") -> dict:
"""
ネストした JSON をフラットな dict に変換する
list は index 付きで展開する
"""
items = {}
for k, v in obj.items():
new_key = f"{parent_key}{sep}{k}" if parent_key else k
if isinstance(v, dict):
items.update(flatten_json(v, new_key, sep))
elif isinstance(v, list):
for i, item in enumerate(v):
if isinstance(item, dict):
items.update(flatten_json(item, f"{new_key}_{i}", sep))
else:
items[f"{new_key}_{i}"] = item
else:
items[new_key] = v
return items
def extract_csv_header(flat_json: dict) -> list[str]:
"""
フラット化された JSON から CSV ヘッダを生成
"""
return list(flat_json.keys())
def append_dict_to_csv(csv_path: str, row_dict: dict, header: list[str]) -> None:
"""
dict を CSV に 1行追記する(ヘッダ順で)
"""
row = [str(row_dict.get(col, "")) for col in header]
print(row)
with open(csv_path, "a", encoding="utf-8") as f:
f.write(",".join(row) + "\n")
def flatten_base_fields(receipt_json: dict) -> dict:
"""
配列を除いた共通情報をフラットな dict にする
"""
base = {}
def _flatten(obj, prefix=""):
for k, v in obj.items():
key = f"{prefix}{k}" if prefix == "" else f"{prefix}_{k}"
if isinstance(v, dict):
_flatten(v, key)
elif isinstance(v, list):
# list はここでは無視(別処理)
continue
else:
base[key] = v
_flatten(receipt_json)
return base
def expand_list_to_rows(
receipt_json: dict,
list_key: str
) -> list[dict]:
"""
指定した配列キーを、複数CSV行に展開する
"""
base = flatten_base_fields(receipt_json)
rows = []
items = receipt_json.get(list_key, [])
# 配列が無い or 空なら base だけで 1行
if not items:
rows.append(base)
return rows
for item in items:
row = base.copy()
if isinstance(item, dict):
for k, v in item.items():
row[f"{list_key}_{k}"] = v
else:
row[list_key] = item
rows.append(row)
return rows
def build_csv_header(rows: list[dict]) -> list[str]:
header = set()
for row in rows:
header.update(row.keys())
return sorted(header)
def append_rows_to_csv(csv_path: str, rows: list[dict]):
header = build_csv_header(rows)
# CSVがなければヘッダ付きで作成
ensure_csv_exists(csv_path, header)
with open(csv_path, "a", encoding="utf-8") as f:
for row in rows:
line = [str(row.get(col, "")) for col in header]
f.write(",".join(line) + "\n")
def save_workflow_json_to_csv(csv_path: str, workflow_json: dict):
"""
Workflow の出力 JSON を解析し、CSV に保存する
"""
rows = expand_list_to_rows(workflow_json, "products")
append_rows_to_csv(csv_path, rows)
def extract_pdf_to_image(pdf_path, out_dir):
pdf_path = Path(pdf_path)
out_dir = Path(out_dir)
out_dir.mkdir(parents=True, exist_ok=True)
doc = fitz.open(pdf_path)
count = 0
for page_index in range(len(doc)):
page = doc[page_index]
for img in page.get_images(full=True):
xref = img[0]
base = doc.extract_image(xref)
image_bytes = base["image"]
ext = normalize_ext(base["ext"]) # jpg, png, jpx, etc.
out_path = out_dir / f"{pdf_path.stem}_{count}.{ext}"
with open(out_path, "wb") as f:
f.write(image_bytes)
count += 1
doc.close()
def normalize_ext(ext: str) -> str:
ext = ext.lower()
if ext == "jpeg":
return "jpg"
return ext
pdflist = list_receipt_pdfs("./receipt")
if pdflist != []:
pdfcnt=len(pdflist)
print(f"PDFファイルを{pdfcnt}件発見しました。画像抽出を開始します。")
processed = 0
for pdf in pdflist:
print(f"{pdfcnt}件中{pdfcnt-processed}件目の処理を実行します。")
extract_pdf_to_image(pdf, "./receipt")
move_receipt_to_done(pdf, "./done")
print(f"PDFファイル {pdf} の画像抽出が完了しました")
processed += 1
print("PDFファイルの画像抽出が完了しました。")
imglist = list_receipt_images("./receipt")
date = datetime.now().strftime("%Y%m%d")
for img in imglist:
response = upload_receipt_and_get_json(img)
save_workflow_json_to_csv(f"receipts-{date}.csv", json.loads(response['data']['outputs']['text']))
move_receipt_to_done(img, "./done")
出来上がったcsv
いろんなお店のやつをスキャンしてみたけど、ほぼ修正していない(3か所修正しただけ)
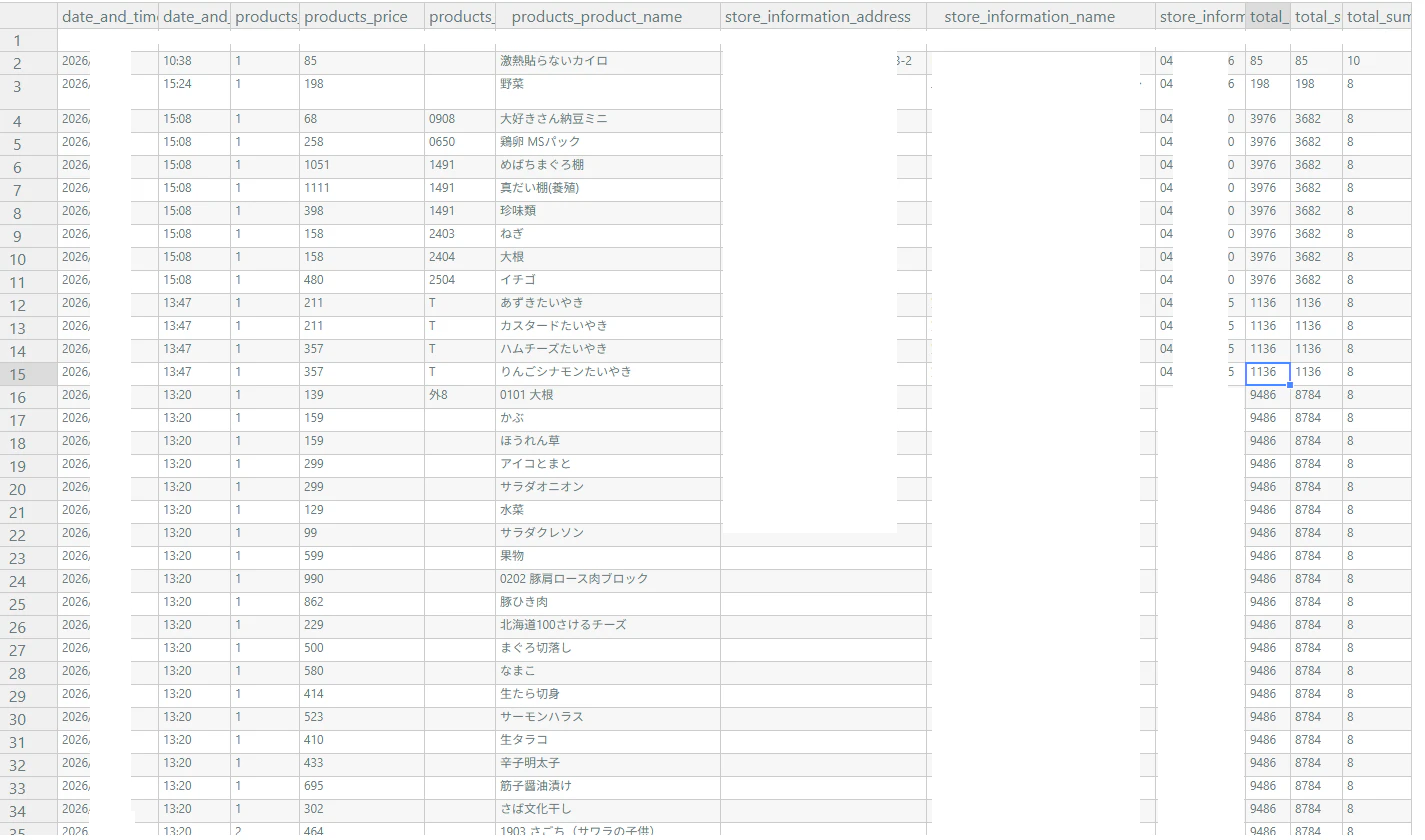
これがローカルだけ、オフラインで完結するのいい時代になりましたな。
まとめ
LLM/VLMを使って、完全ローカル・オフラインで動くレシートOCR家計簿システムを作ってみた。
ポイントは、
- OCR(VLM)には余計なことをさせない
- VLMには読み取った生テキストは全部吐かせて、構造化・意味解釈はLLMに丸投げする
という役割分担にしたことです。
最初は「OCRにJSONで出せ」とやって失敗しましたが、
「考えないOCR × 頭のいいLLM」に切り替えたことで精度と安定性が一気に改善しました。
スマホでスキャン → Syncthingで写真撮ったら自動転送 → Dify経由で解析 → CSV化、という流れで、
9割方そのまま使える家計簿CSVが自動生成されます。
残り1割だけ軽く手修正すればOKなので、実用性は十分かなと思います。
クラウドに投げず、APIもローカル、モデルもローカルです。
プライバシーを「気にする人も気にしない人も」安心できる構成になりました。
LLMが身近になった今、
「ちょっと不便だけど自動化できそう」くらいの個人用途には最高の時代ですね。
家計簿に限らず、OCR × LLMの分業構成は色々応用できそうです。
それじゃ。