はじめに
エンジニアのコミュニティEasy Easyでお世話になっている @unsoluble_sugar 師匠から完全に理解したTalk Advent Calendar 2020へのお誘いをいただき、全文検索の仕組みについて投稿することにしました。
読み終わる頃には、みなさんも全文検索が完全に理解できている1はずです。
1.「全文検索」とは?
「ぜんぶんけんさく」と読みます。
「全文」は「文章の始めから終わりまで」という意味なので、「全文検索」は「文章の始めから終わりまでを検索すること」です。「フルテキスト検索」とか「full-text search」とか呼ばれたりもします。
全文検索は当たり前の機能
全文検索はごく当たり前の、どこにでもある機能です。
皆さんがお使いのテキスト エディター、Microsoft Office、統合開発環境などには検索機能があるかと思いますが、それを使えば文章やソースコード全体に対して好きな言葉で検索ができますよね。それが全文検索です。
他にも
- コマンドならLinuxの
grepやWindowsのfindなど - プログラミング言語なら
str.indexOf()やstr.Contains()やstrstr()など - データベースならたとえば
WHERE bio LIKE '%G検定%';
といった感じで全文検索できます。
全文検索の課題
全文検索は当たり前の機能なのですが、対象の全文データが大容量だと、処理が遅くなるという課題があります。
- PCの中やファイル サーバーのファイルを検索しても、結果がなかなか返ってこない
- 社内で使っている業務システムの検索が遅い
- 巨大なログ ファイルを検索したいけど、検索以前にログの読み込みが遅すぎる
- SQLのLikeで中間一致検索すると、インデックスを作っていても遅い
似たようなお悩みをお持ちの方は、意外に多いのではないかと思います。

でも世の中には、大容量のデータでも高速に全文検索できるサービスがたくさんあります。
- Bing、Google、Yahoo!などのインターネット検索
- QiitaやTwitterなどの投稿内容の検索
- Box、Dropbox、Evernoteなどの登録文書の検索
他にもたくさんあるかと思います。これらのサービスが高速なのは、全文検索専用の仕組みが動いているためです。この記事では、この仕組みについて解説していきます。

全文検索エンジン
IT業界では、専用の仕組みを実装したプログラムを「エンジン」と呼ぶので、高速な全文検索を実現するプログラムのことを「全文検索エンジン」と呼んだりします。この記事でも、以降は「全文検索エンジン」と呼びます。
全文検索エンジンのタイプ
全文検索エンジンには、大きく2つのタイプがあります。溜まったデータを検索するものと、流れてくるデータを検索するものです。
a. 溜まったデータ用
こちらは、事前に蓄積されている大容量のデータに対して、高速に全文検索するための仕組みです。
例えばインターネット検索はこちらのタイプです。事前にインターネットのサイトの情報を集めて蓄積し、その蓄積されたデータに対して全文検索します。

(溜まった寿司の中から好きなネタを高速に検索)
b. 流れてくるデータ用
こちらは、どんどん流れてくるデータに対して、大量の条件で高速に全文検索するための仕組みです。
例えばニュース配信サービスの中には、自分が事前に設定しておいた言葉が含まれるニュースが入るとリアルタイム配信してくれるものがあります。これは今まさに流れてきたニュースに対して、全利用者の登録している大量の条件で検索する必要があるので、こちらのタイプのエンジンが適しています。2

(流れる寿司の中から狙っていたネタを高速に検索)
2.全文検索エンジンの仕組み
全文検索エンジンと言うと、一般的には溜まったデータ用のものを指すことが多いので、ここからは溜まったデータ用のエンジンについて、一般的な仕組みを解説します。
本の索引
全文検索エンジンの仕組みはとても単純で、本の索引のようになっています。
例えば体のことについて書かれた本の中で「足」について書かれているページを探したい場合、本を頭から読んで探していたら大変ですが、索引を見れば簡単です。例えば以下のような索引の場合、「足」については239ページと351ページに書いてあることがわかります。
| 言葉 | 掲載ページ |
|---|---|
| 【 あ 】 | |
| あご | 13, 208 |
| 足 | 239, 351 |
| 頭 | 192 |
| 【 い 】 | |
| 胃 | 28, 312 |
| 【 う 】 | |
| 腕 | 32, 122, 390, 523 |
| うなじ | 129 |
全文検索エンジンも、事前に検索対象のデータを調べてこのような索引を作っておくことで、高速な検索を実現しています。
インターネット検索の例
たとえばインターネット検索の場合、まず各サイトからデータを収集して、その中から索引に載せる単語を選んで索引を作ります。索引のデータは下の図の右側のような表になっています。各単語と、それがどのサイトのどこにあったのかを記録しておく形です。
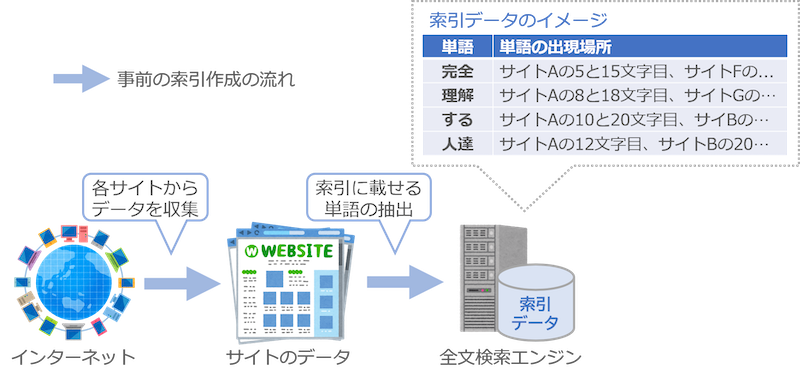
検索の時は、この索引データを調べます。例えば利用者が「理解」という言葉で検索したら、索引の「理解」のところを調べます。そうすると「サイトAの8文字目と18文字目、サイトGの……」と出現場所がわかるので、すぐに結果を返せます。
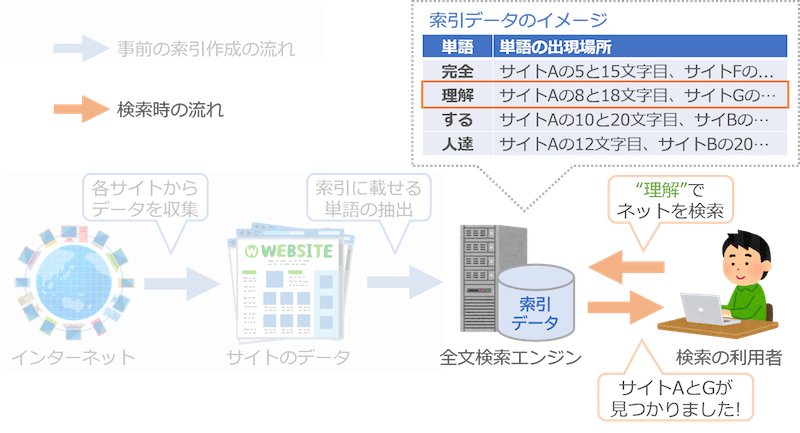
なお、この図では索引の単語の並び方が適当ですが、実際には本と同じように「あいうえお順」などに並べておいて、すぐに単語を見つけられるようにしてあります。
索引にない単語
この仕組みの場合、索引にある単語なら検索できますが、索引にないと検索できません。例えば下のような索引を作っていた場合、「理解」という単語は索引にあるので検索できますが、「寿司」は索引にないので検索できません。

そのため、どんな単語でも探せるように索引を作っておく必要があるのですが、これがなかなか大変です。
3.索引に載せる単語の選び方
ここからは、索引に載せる単語の選び方についての解説です。
単語選びの2つの方法
単語選びにはいくつか方法がありますが、2つの代表的な方法をご紹介します。
a. 日本語を解析する方法
検索対象になる文章を解析してバラバラにし、その中から索引にのせる単語を選ぶ方法です。
まず用語辞書を使って文章をバラバラにします。用語辞書とは、国語辞典のような意味を調べるものではなく、単語の品詞(名詞、動詞、etc.)や原形(「し」→「する」)を調べるためのものです。
これを使ってバラバラにした後、検索に不要な助詞などを取り除き、変化しているものを原形に戻すことで索引に載せる言葉を決定します。たとえば「完全に理解した人達」から索引を作ると、下の図の左側のようになります。
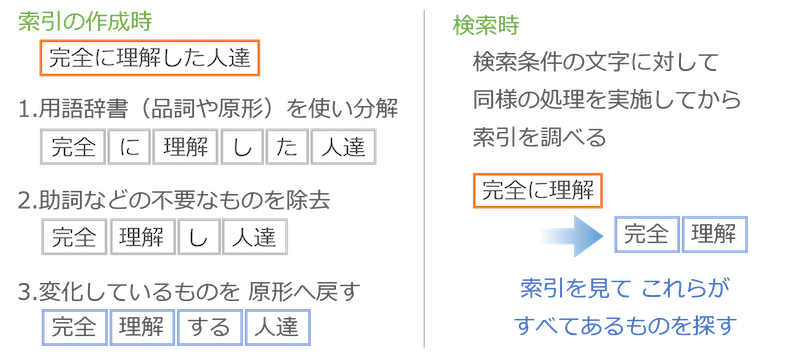
検索する時も、検索条件で指定された検索語に対して同じことを実施します。たとえば「完全に理解」という条件で検索された場合は、上の図の右側のように「完全」と「理解」の2つの言葉を取り出します。この言葉を索引で調べることで検索します。
b. 単純に切り刻む方法
もう1つの方法は、文章を適当に決めた文字数で単純に切り刻んでしまう方法です。下の図の左側です。
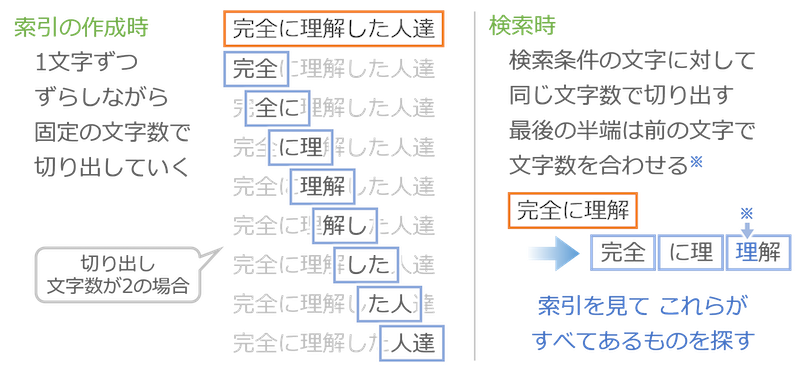
この図は2文字ずつ切り出した場合の例ですが、このように機械的に1文字ずつずらして2文字を切り出し、「完全」、「全に」、「に理」、……を索引に載せます。意味不明の言葉もできますが、気にしないでOKです。
検索する時も、検索条件で指定された検索語に対して、索引を作った時と同じ文字数で切り刻みます。ただし、検索時は1文字ずつずらす作業は不要です。上の図の右側のように「完全に理解」という条件で検索されたら「完全」「に理」「解」の3つに分解し、最後の「解」は1文字足りないので1つ前の文字を使って「理解」にします。そしてこれらの言葉で索引を調べれば検索できます。
単語選びの課題
索引に載せる単語選びの方法を2つご紹介しましたが、残念ながらどちらも万能ではありません。
a. 日本語を解析する方法の課題
日本語を解析する方法の場合、解析ミスがあると検索できなくなってしまいます。例えば「Honda Cards 東京都」という文章があった場合、一般的な解析では次のような結果になります。

一見、正しいように思えますが、実はこの![]() Honda Cards 東京都さんの「東京都」は「ひがしきょうと」で京都にあります。そのため「京都」で検索できないのは困りますし、「東京」で検索されてしまうのも困ります。
Honda Cards 東京都さんの「東京都」は「ひがしきょうと」で京都にあります。そのため「京都」で検索できないのは困りますし、「東京」で検索されてしまうのも困ります。
英語は単語の間に空白が入るので解析しやすいのですが、日本語や中国語、韓国語、タイ語などは空白が入らないので、解析ミスの問題が付きまといます。また、Twitterのつぶやきなどは、文法的に正しくない文章もたくさんあります。こういったものは用語辞書にない単語が出てきたりするので、解析もなかなか大変です。
b. 単純に切り刻む方法の課題
単純に切り刻む方法は、どんな言葉でも探せるように1文字ずつずらしていますが、それが原因で余計なものまで検索されてしまう問題がおきます。

この例のように、東京都の住所なのに「京都」で検索されてしまったりします。
日本語を解析する方法に比べると、こちらの方法ならTwitterのように文法的に正しくない文章でも探すことができますが、索引に意味不明な言葉が載ってしまうので、余計なものまで検索されてしまう傾向にあります。
どちらの方法が良いのか?
2つの方式には一長一短がありますので、実際に使う際には検索の要件に合わせて選択する必要があります。また商用の全文検索エンジンでは、これらの方法を独自に改良したり両方を組み合わせたり別の手法も使ったりして、検索の精度を向上させているものもあります。
同じ意味を指す言葉の扱い
索引に載せる単語の選び方として、もう1つ必要な工夫をご紹介します。それは、同じ意味の言葉や文字をまとめる作業です。

上の表のように同じ言葉や文字を同一のものとして扱う仕組みがないと、思ったものが検索できません。この表の右側のような対応表や同義語の辞書などを用いるのが一般的です。
ちなみに同一のものとして扱う処理は、単純な文字の同一視ならWindowsにも搭載されていて、例えばメモ帳の検索でも内部でやってくれます。ただ「ー」で検索すると「々」まで検索されてしまったりする3ので、やりすぎると余計なお世話にもなってしまいます。要件に合わせた調整も必要です。
以上で、全文検索エンジンの仕組みの解説はおわりです。
4.全文検索と一緒に使われる仕組み
最後に少しだけ脱線して、周辺の仕組みについても軽くご紹介します。
全文検索は手段
ユーザーが全文検索をする目的は「検索すること」ではなく「必要な情報を得ること」です。そのため「ユーザーが必要とする情報」を推測して提示してあげる仕組みがセットでよく使われます。これらの機能が備わっている全文検索エンジンもあります。
以下、全文検索とセットでよく使われる仕組みを簡単にご紹介します。
a. 検索結果の並べ替え
インターネット検索では、数千や数万のサイトがヒットすることもよくありますが、ユーザーが必要だと思うサイトから順番に表示してくれるため、全ての結果を見なくても済むようになっています。このように、検索結果をユーザーが必要だと思う順番に並び替えて、検索結果が大量にあっても見つけやすくする仕組みがよく使われます。
並べ方は、ユーザーが何を必要としているかによって変わってきます。以下、いくつかの例です。
- 指定された検索条件がたくさん出現している結果を優先して並べる
- 新しい情報や人気の情報を優先して並べる
- そのユーザーと似たような傾向を持つ方がよく見るものを優先して並べる
- そのユーザーの特性(例えば年齢、性別、業務、今いる場所、etc.)に合わせて、それに関連しそうな情報を優先して並べる
- サービス提供側からそのユーザーへ伝えたいものを優先して並べる
このように、全文検索が終わった後の検索結果の並びを決める部分でも、いろいろな仕組みが使われています。
b. 検索結果の分類
検索結果を分類して提示する仕組みもよく使われます。
例えばECサイトでは、検索結果一覧の左側に商品のカテゴリやブランド、価格帯ごとの件数などが表示されていて、それを選ぶと検索結果がたくさんあっても商品を簡単に絞り込むことができます。
このように、大量の検索結果を分類して提示することで、絞り込みを支援する仕組みもよく使われます。

(ブランド名を選んだらすぐ見つかった!)
c. 関連する情報の提示
検索結果にはないものを提示する仕組みもよく使われます。
例えばECサイトで「掃除機」を検索すると、炊飯器や電子レンジも一緒にオススメしてきます。おそらく、一人暮らしを始めるのかも?という推測の元で関係する商品をオススメしてくるのでしょう。
このように、ユーザーが検索した時に、その条件には該当しないけど有用だと思われる情報を一緒に提示する仕組みもよく使われます。

(確かに金のオノや銀のオノでもいいかも!)
d. 検索条件の入力支援
検索条件の入力を支援する仕組みもよく使われます。何文字か入力すると候補の単語を提示してくれたり、多少のスペルミスでも訂正して検索してくれたりします。
また、「近くの美味しいラーメン屋」といった話し言葉で検索できたり、音声で検索できるものもあります。チャットで会話をしていると、そのやり取りから検索の条件を自動生成して検索してくれるようなシステムもあります。
検索の条件を考えたり入力したりするには慣れやコツも必要ですが、こういった入力支援の仕組みにより、誰でも必要な情報が探せるようになってきています。

(サンタクロースは本当にいるの?)
e. AIの活用
最後にAIです。ちょっと言葉が大きいので一言ではまとめにくいのですが、AIは全文検索と一緒に使われる仕組みというよりも、全文検索の仕組みを進化させるものになりそうです。
この記事で解説した索引を作る方法は、検索対象の文章を機械的に解析しているだけで、索引にはその文章の意味までは取り込んでいません。また、索引はあくまでも検索のためのものであり、他の用途には不向きです。
これに対して最近のAIの仕組みでは、検索に限らず何にでも使える「万能な索引」のようなものを作るのが主流になっています。この万能な索引には元の文章の意味も含まれていて、これを使えばユーザーが必要とする様々なことが実現できます。
例えば対話したり、翻訳したり、文書を生成したり、プログラムのコードを書いたりと、ひと昔前では考えられなかったことが実現され始めています。

(AIにブログ書かせたらランキング1位に!4)
おわりに
全文検索エンジンの仕組みの解説と、セットで使われることの多い周辺の仕組みについて簡単にご紹介しましたが、いかがでしたでしょうか。この記事が、全文検索に興味を持っていただけたり、全文検索が何かのお役に立つきっかけになりましたら幸いです。
なお、最後にちょっとだけ宣伝を。
私が以前所属していたジップインフォブリッジ株式会社は全文検索エンジンの老舗で、1986年に「SAVVY」(サビー)という名前でリリース以降、おかげさまで数千社のお客様にご採用いただいています。以下のサイトでご紹介しておりますので、もしご興味がありましたらご参照ください。
最後までお読みいただき、ありがとうございました。
専門用語一覧
この記事はなるべく専門用語を使わずにまとめましたが、より深く知りたい方は以下の専門用語で検索してみてください。
| この記事の説明 | 関係する専門用語 |
|---|---|
| 仕組み | アルゴリズム、モデル |
| 蓄積されたデータ | ストック データ |
| 流れてくるデータ | フロー データ、ストリーム データ |
| 事前に索引を作ること・その索引 | インデキシング・インデックス |
| 索引データ(言葉と出現位置の対応表) | 転置インデックス、転置ファイル |
| 索引作成のために 対象のデータを集めること | クローリング、クロールする |
| 日本語を解析して言葉を切り出すこと | 形態素解析、分かち書き |
| 検索で不要な 助詞などの言葉を 索引から除くこと | ストップワードの除去 |
| 文章を一定の文字数で単純に切り刻む方式 | n-gram(エヌ・グラム) |
| 文章の分割ミスなどにより 検索に該当しないこと | 検索もれ |
| 文章の分割ミスなどにより 間違って該当したデータ | 検索ノイズ |
| 表記ゆれを統一したり 辞書を使って対応する処理 | 単語の正規化、辞書展開 |
| 検索結果を並べ替えること | ソート、スコアリング、ランク付け、ランキング |
| 検索結果の分類 | カテゴライズ、クラスタリング |
| 関連する情報の提示 | レコメンド、リコメンド、サジェスト |
| 検索条件の入力支援 | 条件語のサジェスト |
| 最近のAIの仕組みにおける万能な索引のようなもの | 単語の埋め込み、分散表現、言語モデル |
| 記事全体と関連の深い技術分野 | 自然言語処理、NLP |
参考文献・Webサイト
- 全文検索 - フリー百科事典『ウィキペディア(Wikipedia)』(最終閲覧日:2020年12月14日)
https://ja.wikipedia.org/wiki/%E5%85%A8%E6%96%87%E6%A4%9C%E7%B4%A2 - 転置インデックス - フリー百科事典『ウィキペディア(Wikipedia)』(最終閲覧日:2020年12月14日)
https://ja.wikipedia.org/wiki/%E8%BB%A2%E7%BD%AE%E3%82%A4%E3%83%B3%E3%83%87%E3%83%83%E3%82%AF%E3%82%B9 - 自然言語処理 - フリー百科事典『ウィキペディア(Wikipedia)』(最終閲覧日:2020年12月14日)
https://ja.wikipedia.org/wiki/%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E5%87%A6%E7%90%86 - 言語処理100本ノック 2020 (Rev 1)(最終閲覧日:2020年12月14日)
https://nlp100.github.io/ja/ - 斎藤康毅『ゼロから作るDeepLearning❷ - 自然言語処理編』オライリー・ジャパン, 2018年
https://www.oreilly.co.jp/books/9784873118369/ - 株式会社NTTデータ『金融業界向け自然言語処理技術の検証開始』, 2020年7月10日(最終閲覧日:2020年12月18日)
https://www.nttdata.com/jp/ja/news/release/2020/071000/ - LINE株式会社『LINE、NAVERと共同で、世界初、日本語に特化した超巨大言語モデルを開発 新規開発不要で、対話や翻訳などさまざまな日本語AIの生成を可能に』, 2020年11月25日(最終閲覧日:2020年12月18日)
https://linecorp.com/ja/pr/news/ja/2020/3508 - かわいいフリー素材集『いらすとや』(最終閲覧日:2020年12月18日)
https://www.irasutoya.com/
-
エンジニアの言う「完全に理解した」については、モーリさんが
 IT技術の最高熟練度を表す「チョットデキル」に先行するプルシェンコの「スケートチョットデキル」を完全に理解したで歴史を紐解いています。 ↩
IT技術の最高熟練度を表す「チョットデキル」に先行するプルシェンコの「スケートチョットデキル」を完全に理解したで歴史を紐解いています。 ↩ -
データの流量が少なかったり、検索したい条件が少量だったり、リアルタイムの要件がそれほど高くない場合は、単位時間(例えば10分単位とか)のデータをストックして、溜まったデータ用の全文検索エンジンで実現することもあるかと思います。 ↩