この記事は「IDOM Engineer Advent Calendar 2017」の22日目の記事として加筆編集しました。
0. 正規表現の学習の前に
はっきり言って、正規表現は一度や二度じゃないぐらい学習しているつもりでいるが、ちょっと間があくと忘れてしまう。
つまり、必要な時に必要なことがわかればいいと考えているからすぐに忘れてしまうんだろう。
しかし、それでは困る事がある。他人が記述した正規表現や自分が以前書いた正規表現が読めないのだ。
これでは、即時にプログラムを読むことができない。
前置きが長くなったが正規表現をもう一度整理しよう。
また先に正規表現について先にまとめてブログにうpしてくれた先達者様に感謝
Java好き 正規表現
JavaDrive Java正規表現の使い方
正規表現を使う - Javaちょこっとリファレンス
Java正規表現によくあるマッチ パターン
正規表現によるマッチング
hishidama Javaの正規表現
Javaちょこっとリファレンス
1. 正規表現の基本について
文字
| 構文 | Matches |
|---|---|
| x | 文字 x |
| \\ | バックスラッシュ文字 |
| \0n | 8 進値 0n を持つ文字 (0 <= n <= 7) |
| \0nn | 8 進値 0nn を持つ文字 (0 <= n <= 7) |
| \0mnn | 8 進値 0mnn を持つ文字 (0 <= m <= 3、0 <= n <= 7) |
| \xhh | 16 進値 0xhh を持つ文字 |
| \uhhhh | 16 進値 0xhhhh を持つ文字 |
| \t | タブ文字 ('\u0009') |
| \n | 改行文字 ('\u000A') |
| \r | キャリッジリターン文字 ('\u000D') |
| \f | 用紙送り文字 ('\u000C') |
| \a | 警告 (ベル) 文字 ('\u0007') |
| \e | エスケープ文字 ('\u001B') |
| \cx | x に対応する制御文字 |
最長一致数量子
| 構文 | Matches |
|---|---|
| X? | X、1 または 0 回 |
| X* | X、0 回以上 |
| X+ | X、1 回以上 |
| X{n} | X、n 回 |
| X{n,} | X、n 回以上 |
| X{n,m} | X、n 回以上、m 回以下 |
最短一致数量子
| 構文 | Matches |
|---|---|
| X?? | X、1 または 0 回 |
| X*? | X、0 回以上 |
| X+? | X、1 回以上 |
| X{n}? | X、n 回 |
| X{n,}? | X、n 回以上 |
| X{n,m}? | X、n 回以上、m 回以下 |
強欲な数量子
| 構文 | Matches |
|---|---|
| X?+ | X、1 または 0 回 |
| X*+ | X、0 回以上 |
| X++ | X、1 回以上 |
| X{n}+ | X、n 回 |
| X{n,}+ | X、n 回以上 |
| X{n,m}+ | X、n 回以上、m 回以下 |
論理演算子
| 構文 | Matches |
|---|---|
| XY | X の直後に Y |
| X|Y | X または Y |
| (X) | X、前方参照を行う正規表現グループ |
文字クラス
| 構文 | Matches |
|---|---|
| [abc] | a、b、または c (単純クラス) |
| [^abc] | a、b、c 以外の文字 (否定) |
| [a-zA-Z] | a 〜 z または A 〜 Z (範囲) |
| [a-d[m-p]] | a 〜 d、または m 〜 p:[a-dm-p] 結合
|
| [a-z&&[def]] | d、e、f 交差
|
| [a-z&&[^bc]] | b と c を除く a 〜 z:[ad-z] 減算
|
| [a-z&&[^m-p]] | m 〜 p を除く a 〜 z:[a-lq-z] 減算
|
定義済みの文字クラス
| 構文 | Matches |
|---|---|
| . | 任意の文字 (行末記号とマッチする場合もある) |
| \d | 数字: [0-9] |
| \D | 数字以外: [^0-9] |
| \s | 空白文字:[ \t\n\x0B\f\r] |
| \S | 非空白文字:[^\s] |
| \w | 単語構成文字:[a-zA-Z_0-9] |
| \W | 非単語文字:[^\w] |
境界正規表現エンジン
| 構文 | Matches |
|---|---|
| ^ | 行の先頭 |
| $ | 行の末尾 |
| \b | 単語境界 |
| \B | 非単語境界 |
| \A | 入力の先頭 |
| \G | 前回のマッチの末尾 |
| \Z | 最後の行末記号がある場合は、それを除く入力の末尾 |
| \z | 入力の末尾 |
まぁ、基本的な正規表現でみんなが利用するのはこの辺かな。
2. Javaで正規表現について
javaで、正規表現をプログラミングに取り入れる場合はjava.util.regexを利用する事になる。JavaDocのURLはこれ。javadoc SE6
java.util.regex.Patternクラスには、正規表現についての詳細の説明が記述されている。Javaを利用して正規表現を極めたいと思ったら一度は読むべき。
ちなみに、java.util.regex.Pattenクラスの概要はこんな記述がされている。
つまり、Javadocをしっかり読めば正規表現を理解する近道になる。
コンパイル済みの正規表現です。
正規表現は、文字列として指定し、このクラスのインスタンスにコンパイルする必要があります。結果として得られるパターンは、Matcher オブジェクトを作成するために使用されます。 このオブジェクトは、任意の 文字シーケンス とこの正規表現をマッチできます。マッチを実行したときの状態はすべて正規表現エンジンに格納されます。 このため、複数の正規表現エンジンが同じパターンを共有できます。
標準的な呼び出しシーケンスは、次のようになります。
Pattern p = Pattern.compile("a*b");
Matcher m = p.matcher("aaaaab");
boolean b = m.matches();
このクラスに定義した matches メソッドを使用すれば、正規表現は一度使用するだけで済みます。このメソッドを 1 回呼び出すだけで、表現がコンパイルされ、入力シーケンスとのマッチが行われます。次の文は、前述の 3 つの文と等価です。
boolean b = Pattern.matches("a*b", "aaaaab");
ただし、マッチを繰り返す場合は、コンパイル済みのパターンを再利用できないため、効率が低下します。
このクラスのインスタンスは不変であるため、複数のスレッドで並行して使用できます。Matcher クラスのインスタンスは、複数スレッドでの並行使用に対応していません。
正規表現の記述にて、この辺を利用している正規表現はあまりみないなー。
みんな毎回ググって誰からのサンプルを加工しているんでしょうね。
POSIX 文字クラス (US-ASCII のみ)
| 構文 | Matches |
|---|---|
| \p{Lower} | 小文字の英字:[a-z] |
| \p{Upper} | 大文字の英字: [A-Z] |
| \p{ASCII} | すべての ASCII 文字: [\x00-\x7F] |
| \p{Alpha} | 英字: [\p{Lower}\p{Upper}] |
| \p{Digit} | 10 進数字: [0-9] |
| \p{Alnum} | 英数字: [\p{Alpha}\p{Digit}] |
| \p{Punct} | 句読文字:!"#$%&'()*+,-./:;<=>?@[]^_`{ |
| \p{Graph} | 表示できる文字:[\p{Alnum}\p{Punct}] |
| \p{Print} | プリント可能文字:[\p{Graph}\x20] |
| \p{Blank} | 空白またはタブ:[ \t] |
| \p{Cntrl} | 制御文字:[\x00-\x1F\x7F] |
| \p{XDigit} | 16 進数字:[0-9a-fA-F] |
| \p{Space} | 空白文字:[ \t\n\x0B\f\r] |
java.lang.Character クラス (単純な java 文字タイプ)
| 構文 | Matches |
|---|---|
| \p{javaLowerCase} | java.lang.Character.isLowerCase() と等価 |
| \p{javaUpperCase} | java.lang.Character.isUpperCase() と等価 |
| \p{javaWhitespace} | java.lang.Character.isWhitespace() と等価 |
| \p{javaMirrored} | java.lang.Character.isMirrored() と等価 |
Unicode ブロックとカテゴリのクラス
| 構文 | Matches |
|---|---|
| \p{InGreek} | ギリシャ語ブロックの文字 (単純ブロック) |
| \p{Lu} | 大文字(単純カテゴリ) |
| \p{Sc} | 通貨記号 |
| \P{InGreek} | ギリシャ語ブロック以外の文字 (否定) |
| [\p{L}&&[^\p{Lu}]] | 大文字以外の文字 (減算) |
3. Javaプログラミング
実際のプログラミングの中で利用する正規表現の記述例
public static void main(String args[]) {
//判定する文字列
String str = "123A5";
//判定するパターンを生成
Pattern p = Pattern.compile("^[0-9]*$");
Matcher m = p.matcher(str);
//画面表示
System.out.println(m.find());
}
正規表現サンプル集
| 構文 | Matches |
|---|---|
| 半角数値10桁にマッチ | ^\d{10}$ |
| 半角数値8桁以上10桁以下にマッチ | ^\d{8,10}$ |
| 1桁以上の半角英数(0~9、a~z、A~Z)にマッチ | ^[0-9a-zA-Z]+$ |
| 郵便番号(半角数値3桁 半角ハイフン 半角数値4桁)にマッチ | ^\d{3}-\d{4}$ |
5. さらにjava プログラム & テストコード
さすがに全部の正規表現のテストコードを記述するのはめんどくさいので数字のみ
/**
* Copyright 2014 by openbooks, All rights reserved.
*/
package com.openbooks.sample.marches;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* このクラスは、正規表現を確認するために用意したクラスです。
*
* @author openbooks
* @version 0.0.1, 2014/11/16
* @since 0.0.1
*/
public class ExampleMatches {
/**
* 正規表現のパターン郡列挙オブジェクト
*/
public enum PatternEnum {
/** 英数字のみ: ^[a-zA-Z0-9]+$ */
ALNUM("^[a-zA-Z0-9]+$"),
/** 英字のみ: ^[a-zA-Z]+$ */
ALPHA("^[a-zA-Z]+$"),
/** すべての ASCII 文字: [\x00-\x7F] */
ASCII("[\\x00-\\x7F]"),
/** 10 進数字のみ: ^[0-9]+$ */
DIGIT("^[0-9]+$"),
/** 小文字の英字のみ:[a-z] */
LOWER("^[a-z]+$"),
/** 郵便番号(半角数値3桁 半角ハイフン 半角数値4桁): ^\\d{3}-\\d{4}$*/
POSTALCODE("^\\d{3}-\\d{4}"),
/** 句読文字:!"#$%&'()*+,-./:;<=>?@[]^_`{ */
PUNCT("!\"#$%&'()*+,-./:;<=>?@[]^_`{]+$"),
/** 空白文字:[ \t\n\x0B\f\r] */
SPACE(" \\t\\n\\x0B\\f\\r"),
/** 大文字の英字のみ:^[A-Z]+$ */
UPPER("^[A-Z]+$"),
/** 16 進数字のみ:[0-9a-fA-F] */
XDIGIT("^[0-9a-fA-F]+$");
/** 正規表現 */
private final String regex;
private PatternEnum(final String regex) {
this.regex = regex;
}
/** 正規表現を保持する{@code Pattern}オブジェクトを返却する */
@SuppressWarnings("unqualified-field-access")
public Pattern toPattern() {
return Pattern.compile(regex);
}
}
/**
* このメソッドは、patternオブジェクトに指定された正規表現に属している場合はtrueを返却し属していない場合はfalseを返却する。<br>
* @param pattern 正規表現を保持するオブジェクト
* @param input 正規表現を利用して確認したい対象オブジェクト
* @return {@link Matcher#find()}の結果を返却する
*/
public static boolean findMatches(Pattern pattern, CharSequence input) {
final Matcher m = pattern.matcher(input);
return m.find();
}
/**
* このメソッドは、内部で{@code ExampleMatches#findMatches(Pattern, CharSequence)}を呼び出しています。
* @param patternEnum 正規表現を保持するオブジェクト
* @param input 正規表現を利用して確認したい対象オブジェクト
* @return {@link ExampleMatches#findMatches(Pattern, CharSequence)}のjavadocを参照
*/
public static boolean findMatches(PatternEnum patternEnum, CharSequence input) {
return findMatches(patternEnum.toPattern(), input);
}
}
package com.openbooks.sample.marches;
import static org.hamcrest.CoreMatchers.is;
import static org.hamcrest.MatcherAssert.assertThat;
import java.util.regex.Pattern;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Test;
import com.openbooks.sample.marches.ExampleMatches.PatternEnum;
public class ExampleMatchesTest {
@BeforeClass
public static void setUpBeforeClass() {
}
@Before
public void setUp() {
}
// PatternEnum.DIGITのテスト ここから
@SuppressWarnings("boxing")
@Test(timeout=100)
public void 正規表現で数字のみの場合に数字と数字以外を渡すとfalseが返却されること() {
final Pattern pattern = PatternEnum.DIGIT.toPattern(); // 数字のみ
final boolean result = ExampleMatches.findMatches(pattern, "0一2三4五6七8九");
assertThat(result, is(Boolean.FALSE));
}
@SuppressWarnings("boxing")
@Test(timeout=100)
public void 正規表現で数字のみの場合に数字を渡すとtrueが返却されること() {
final Pattern pattern = PatternEnum.DIGIT.toPattern(); // 数字のみ
final boolean result = ExampleMatches.findMatches(pattern, "0123456789");
assertThat(result, is(Boolean.TRUE));
}
@SuppressWarnings("boxing")
@Test(timeout=100)
public void 引数にPatternEnumを渡すパターン_正規表現で数字のみの場合に数字を渡すとtrueが返却されること() {
final boolean result = ExampleMatches.findMatches(PatternEnum.DIGIT, "0123456789");
assertThat(result, is(Boolean.TRUE));
}
@SuppressWarnings("boxing")
@Test(timeout=100)
public void 正規表現で数字のみの場合に数字以外を渡すとfalseが返却されること() {
final Pattern pattern = PatternEnum.DIGIT.toPattern(); // 数字のみ
final boolean result = ExampleMatches.findMatches(pattern, "一二三四五六七八九零");
assertThat(result, is(Boolean.FALSE));
}
@SuppressWarnings("boxing")
@Test(timeout=100)
public void 正規表現で数字のみの場合に全角の数字を渡すとfalseが返却されること() {
final Pattern pattern = PatternEnum.DIGIT.toPattern(); // 数字のみ
final boolean result = ExampleMatches.findMatches(pattern, "0123456789");
assertThat(result, is(Boolean.FALSE));
}
}
// PatternEnum.DIGITのテスト ここまで
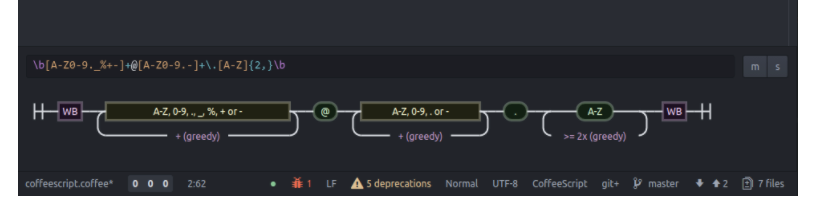
正規表現の可視化
regexperサイトを利用すると正規表現を可視化することができる。
また、可視化した情報をイメージとしてダウンロードすることも可能。以下は簡単なサンプル
英数字のみ: ^[a-zA-Z0-9]+$

英字のみ: ^[a-zA-Z]+$

すべての ASCII 文字: [\x00-\x7F]

atomプラグインの紹介
atomエディタを利用している人で正規表現を可視化したい場合はこのプラグインがいいかも。
cmd + R, Rでエディタの下にダイアグラムを生成するウィンドウが表示されるそこで正規表現を記述するといい感じ。