- Ruby 4.0 の Ractor 使ってみた (1) 触ってみるまで
- Ruby 4.0 の Ractor 使ってみた (2) 題材
- Ruby 4.0 の Ractor 使ってみた (3) Ractor::Port に馴染む
- Ruby 4.0 の Ractor 使ってみた (4) Ractor に馴染む
- Ruby 4.0 の Ractor 使ってみた (5) 設計方針
- Ruby 4.0 の Ractor 使ってみた (6) 実装
- Ruby 4.0 の Ractor 使ってみた (7) ベンチマークテスト
はじめに
ついにベンチマークテストを行うときがやってきた。
並列処理の何たるかを知らん筆者が Ruby 4.0 で刷新された Ractor に挑戦したのは,「時間のかかる処理を早く終わらせたい」ことが(たまに)あるからだ。
しかし早くなるのかどうかは,ベンチマークテストをやって初めて分かる。
方針
数 MiB のテキストデータを何十個か用意し,それの処理にかかる時間を計測する。
きちんとしたベンチマークテストにはベンチマーク用ライブラリーを使うべきだが,ここでは開始時刻と終了時刻の差分を表示するという原始的な方法を取った。
データの規模を,処理時間全体が秒の位になるようにしてあるので,これでもまあ意味のある測定ができるはずだ1。
テキストデータとして,英文のプレインテキストを用意する。
英語版 Wikipedia の何かのページを開いて全選択してコピペしたファイルを用意した。
200 KiB 弱しかないので,これを 10 回繰り返したテキストを作る。2 MiB 弱になる。
テキストデータは 50 個用意する。
本来なら(長さの異なる)別々のテキストとするのがよいが,めんどうなので,dup して作る。
コード
並列化しないもの
まずは並列化しない場合。
require_relative "ractor_filter_processor"
text = File.read("sample.txt") * 10
texts = Array.new(50){ text.dup }
def char_histogram(text)
text.chars.tally.sort_by{ -_2 }.to_h
end
start_time = Time.now
result = texts.map{ |text| char_histogram(text) }
puts "%0.2f sec" % (Time.now - start_time)
Ractor 版
次に,RactorFilterProcessor を使った場合。
ワーカーの数をコマンドライン引数で与えることにしよう。つまり,
ruby bench-ractor.rb 4
のように起動する。
コードは以下の通り:
require_relative "ractor_filter_processor"
w_text = File.read("sample.txt") * 10
texts = Array.new(50){ w_text.dup }
def char_histogram(text)
text.chars.tally.sort_by{ -_2 }.to_h
end
worker_count = ARGV[0].to_i
start_time = Time.now
processor = RactorFilterProcessor.new(worker_count) do |text|
char_histogram(text)
end
result = processor.filter(texts)
puts "%0.2f sec" % (Time.now - start_time)
「Ractor でワーカーを作ってそいつらにゴニョゴニョ」というあたりをクラスにまとめておいたので,使う側のコードの行数は非並列版に比べて少ししか増えていない。
ractor_filter_processor.rb のコードは シリーズ (6) に掲載してある。
結果
並列化しない場合
5 回実行した結果は次のとおりであった。
| 回 | 時間(sec) |
|---|---|
| 1 | 7.91 |
| 2 | 7.70 |
| 3 | 7.72 |
| 4 | 7.69 |
| 5 | 7.81 |
平均 7.77,標準偏差 0.08
(ええと,統計に疎いので,5 個程度の値で標準偏差に意味があるのかよく分からないけど,振れ幅の目安として)
Ractor 版(1 ワーカー)
Ractor 版では,あえてワーカーを 1 個でまずやってみる。
これだと並列化にならない。
むしろ何らかのオーバーヘッドにより,遅くなる可能性がある。
5 回実行した結果は次のとおりであった。
| 回 | 時間(sec) |
|---|---|
| 1 | 7.51 |
| 2 | 7.48 |
| 3 | 7.59 |
| 4 | 7.77 |
| 5 | 7.50 |
平均 7.57,標準偏差 0.11
と,とくに遅くはなっていないようだ……。
数字自体はむしろ小さくなっているが,べつに速くなっているわけでもないと思う。
有意に遅くなると予想していたので,意外だった。
Ractor 版(2 ワーカー)
ワーカーを 2 個にしてみよう。
| 回 | 時間(sec) |
|---|---|
| 1 | 5.09 |
| 2 | 5.21 |
| 3 | 5.17 |
| 4 | 5.24 |
| 5 | 5.14 |
平均 5.17,標準偏差 0.05
一人体制を二人体制にしたのに,時間は半分になっていない。少し短くなっただけ。
まあそんなものなのだろう。
Ractor 版(1〜8 ワーカー)
私の環境(後述)は CPU コアが 8 つあるようなので,ワーカーを 8 個まで増やしてみる。
以下のようになった。
| ワーカー数 | 平均 | 標準偏差 |
|---|---|---|
| 1 | 7.57 | 0.11 |
| 2 | 5.17 | 0.05 |
| 3 | 4.31 | 0.12 |
| 4 | 4.03 | 0.13 |
| 5 | 4.57 | 0.03 |
| 6 | 4.84 | 0.11 |
| 7 | 5.07 | 0.13 |
| 8 | 5.28 | 0.08 |
グラフにするとこんな感じ:
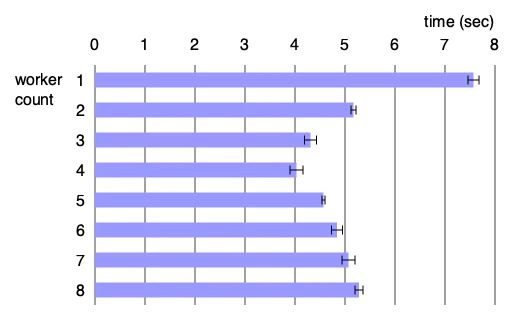
ぐぬ……,ワーカーを 4 個(4 人?)まで増やすと時間が短縮されていくが,それ以上増やすとかえって時間がかかるという結果に……。
考察?
並列化の効果が最も高かったケース(ワーカー 4 個)でも,時間は半減までいかなかった。半減に近いが。
また,コアが 8 個もあるのに,ワーカーを 5 個以上にするとかえって時間が増えた。
ここで動作環境を確認しておく。
- MacBook Air
- チップ: Apple M1
- コアの総数: 8(パフォーマンス: 4、効率性: 4)
- メモリー: 8 GB
- Ruby 4.0.2
8 個の CPU コアのうち,4 個が「パフォーマンス」,残りが「効率性」となっている。
M1 チップの説明によると,高速だが消費電力の大きいものと,低速だが消費電力の小さいもの,ということらしい。
ワーカーを増やすと,低速のコアに仕事が振られるのだろう。
とはいえ,仕事の速い 4 人で分担していたところへ仕事の遅い 4 人が加わって全体の時間が増えるものだろうか?
人間の 労働者 の場合,極端に仕事の遅い人が加わると,その人に仕事を教えたりコミュニケーションを取ることに時間が割かれて効率が落ちることはあるだろう。
しかし,いまの場合,あるワーカーの仕事が遅くても直接他のワーカーが影響を受けるわけではない。
ワーカーとオブジェクトをやり取りするコストだって,たぶん速いコアと遅いコアでそう変わりはないような気がする。
だから猫の手だって無いよりマシなのではないだろうか?
なお,ワーカーが 4 個の場合,Ractor の個数は 5 である。メイン Ractor があるから。
だからこの最良ケースでは,おそらく速いコア 4 個と遅いコア 1 個が使われているのだと思う。
大した仕事をしていないであろうメイン Ractor がどっちのコアで動いているのかは気になるところだ。最初に走る Ractor だから速いコアのほうなんじゃないかという気がする。
感想
筆者は並列処理のなんたるかをほとんど理解していないので,今回の実験と記事の執筆に多大な時間を費やした。
その労力のわりにはやや残念な結果であった,
いや,6 分かかる処理が 3 分で終わるなら,嬉しいは嬉しいけれども,涙ちょちょぎれるほどでもない。
ただ,もしかすると何らかの工夫によってもっと速くなるのかもしれない。
もう少し勉強してみようと思う2。
連載はいったんこれで終わりにする。Ractor について新たに分かったことがあったら,内容に応じて連載に記事を追加するか連載とは別の記事にしたい。
記事投稿キャンペーン「みんなでRubyの知見を共有しよう - Qiita」に乗っかって書いてみたけど,ほとんど何の反応も無かった(笑)
キャンペーン自体も盛り上がっていないようだ3。