Watson Discovery ではデータの投入の方法として Data Crawler が提供されていますが、残念ながら肝心の Web クローラーがありません。それでも Web クローリングをしたいという要件に対応するために、オープンソースの Web クローラーである Apache Nutch のプラグインとしてDiscovery の Indexer プラグインが提供されています。本記事ではこのプラグインを使用する手順を記載します。
設定手順
Mac OSで実施しましたが、基本的にはこちらに記載の手順で問題ありませんでした。
ソースコードを取得します。
$ git clone https://github.com/IBM-Watson/nutch-indexer-discovery.git
JAVA_HOMEを設定します。私は .bash_profile に以下を追記しました。
$ export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home
手順に従って Gradle wrapper、HBase をセットアップします。
$ ./gradlew
$ ./gradlew setupHbase
build/hbase-0.98.8-hadoop2/bin/ で HBase を起動します。
$ ./start-hbase.sh
以下のコマンドを実行すると Nutch がセットアップされます。
$ ./gradlew setupNutch
IBM Cloud で Watson Discovery の Collection を作成し(手順は省略)、作成した環境に合わせて conf/nutch-discovery/nutch-site.xml を修正します。
<property>
<name>discovery.endpoint</name>
<value>https://gateway.watsonplatform.net/discovery/api</value>
</property>
<property>
<name>discovery.username</name>
<value>xxxxxxxxxxxxxxxxxx</value>
</property>
<property>
<name>discovery.password</name>
<value>xxxxxxxxxxxxxxxxxx</value>
</property>
<property>
<name>discovery.configuration.id</name>
<value>xxxxxxxxxxxxxxxxxx</value>
</property>
<property>
<name>discovery.environment.id</name>
<value>xxxxxxxxxxxxxxxxxx</value>
</property>
<property>
<name>discovery.api.version</name>
<value>2017-11-07</value>
</property>
<property>
<name>discovery.collection.id</name>
<value>xxxxxxxxxxxxxxxxxx</value>
</property>
プラグインを build します。
$ ./gradlew buildPlugin
seed/url.txt にクロールするサイトのURLを記載します。今回はあらかじ設定してある以下のURLを使用します。
https://en.wikipedia.org/wiki/Apache_Nutch
https://en.wikipedia.org/wiki/Watson_(computer)
クロールを実行します。
$ ./crawl
Injecting urls from ./seed/urls.txt
./build/apache-nutch-2.3.1/runtime/local/bin/nutch inject ./seed/urls.txt
InjectorJob: starting at 2018-05-18 13:54:17
InjectorJob: Injecting urlDir: seed/urls.txt
InjectorJob: Using class org.apache.gora.hbase.store.HBaseStore as the Gora storage class.
InjectorJob: total number of urls rejected by filters: 0
InjectorJob: total number of urls injected after normalization and filtering: 2
Injector: finished at 2018-05-18 13:54:24, elapsed: 00:00:06
Generate urls:
./build/apache-nutch-2.3.1/runtime/local/bin/nutch generate -topN 5
GeneratorJob: starting at 2018-05-18 13:54:26
GeneratorJob: Selecting best-scoring urls due for fetch.
GeneratorJob: starting
GeneratorJob: filtering: true
GeneratorJob: normalizing: true
GeneratorJob: topN: 5
GeneratorJob: finished at 2018-05-18 13:54:30, time elapsed: 00:00:04
GeneratorJob: generated batch id: 1526619266-1145068029 containing 2 URLs
Fetch urls:
./build/apache-nutch-2.3.1/runtime/local/bin/nutch fetch -all
FetcherJob: starting at 2018-05-18 13:54:32
FetcherJob: fetching all
(以下省略)
クロールが完了すると、Discovery にデータが投入されていることが確認できました。
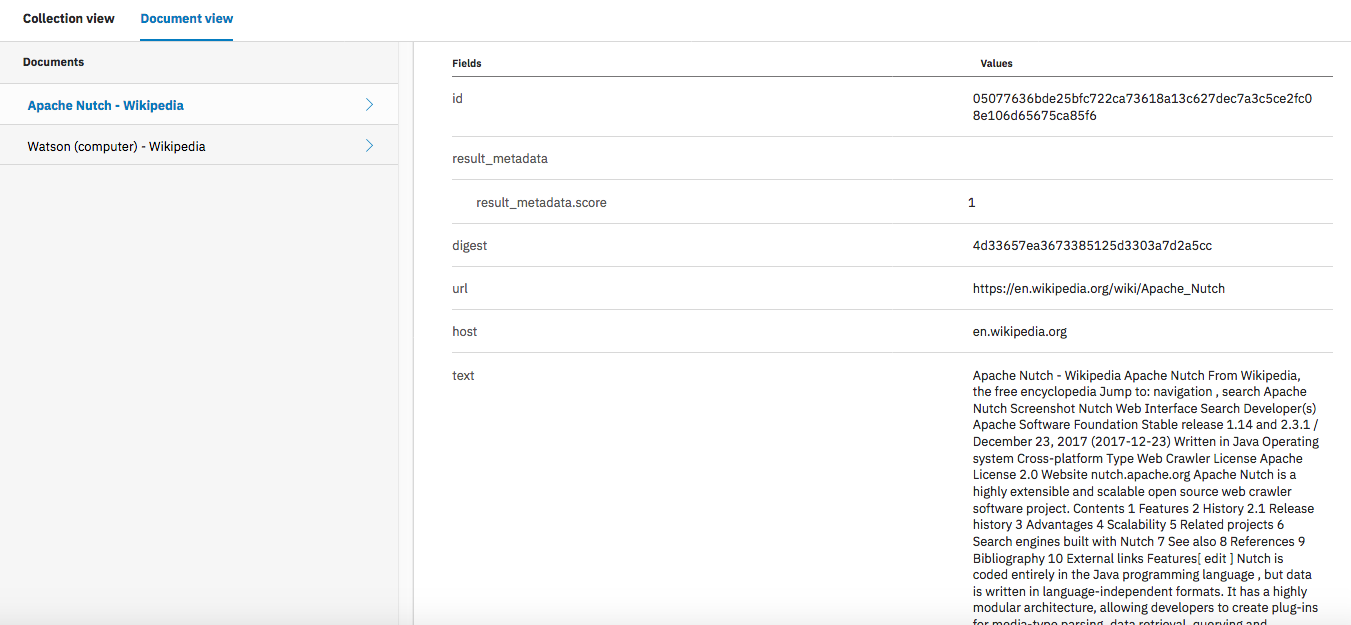
ニュース記事のクロール
応用編として日本語のニュースサイトをクロールしてみたので設定を紹介します。
Discovery の Collection 作成
日本語用のCollectionを作成し、Configurationを新規作成します。Configurationでは "text" フィールドのエンリッチ対象として 日本語対応している "cotegories" と "concepts" を選択します。
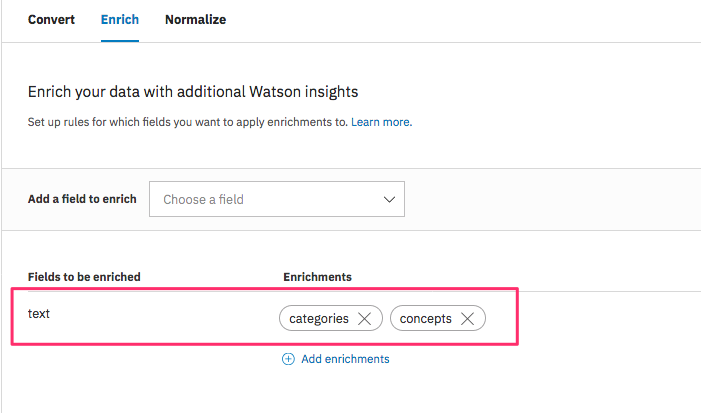
Nutch の設定
作成したCollection に合わせて conf/nutch-discovery/nutch-site.xml を修正し、プラグインを build します。
$ ./gradlew buildPlugin
seed/url.txt にクロールするサイトのURLを記載します。今回はニュースサイトとして「朝日新聞デジタル」と「日本経済新聞 電子版」を対象にし、以下のように設定しました。
http://www.asahi.com/news/
https://www.nikkei.com/news/category/
build/apache-nutch-2.3.1/runtime/local/conf/regex-urlfilter.txt にURLフィルターを設定します。URLフィルターを使用すると、正規表現でクロール対象を限定することができます。今回はニュース記事だけを対象にするように、以下のように設定しました。
+^https?://www.asahi.com/news/$
+^https?://www.asahi.com/articles/[0-9a-zA-Z_]+\.html$
+^https?://www.nikkei.com/news/category/$
+^https?://www.nikkei.com/article/[0-9a-zA-Z_]+/$
# accept anything else
# +.
./crawl スクリプトを修正します。今回は以下のように generate コマンドの topN オプションの値だけ変更しました。
# Generate a new set of URLs to fetch. topN parameter decides how many pages nutch should crawl per depth. If you estimate a website to have 3000 pages then you can specify a depth value of 3 and a topN value of 1000 for a successful crawl of 3000 documents.
echo "Generate urls: "
__bin_nutch generate -topN 100
それでは、クロールしてみます。真っさらな状態から実施する場合はこちらの手順で HBase のデータを truncate するとよいです。
$ ./crawl
Injecting urls from ./seed/urls.txt
./build/apache-nutch-2.3.1/runtime/local/bin/nutch inject ./seed/urls.txt
InjectorJob: starting at 2018-05-18 15:37:16
InjectorJob: Injecting urlDir: seed/urls.txt
InjectorJob: Using class org.apache.gora.hbase.store.HBaseStore as the Gora storage class.
InjectorJob: total number of urls rejected by filters: 0
InjectorJob: total number of urls injected after normalization and filtering: 2
Injector: finished at 2018-05-18 15:37:22, elapsed: 00:00:06
Generate urls:
./build/apache-nutch-2.3.1/runtime/local/bin/nutch generate -topN 100
GeneratorJob: starting at 2018-05-18 15:37:24
GeneratorJob: Selecting best-scoring urls due for fetch.
GeneratorJob: starting
GeneratorJob: filtering: true
GeneratorJob: normalizing: true
GeneratorJob: topN: 100
GeneratorJob: finished at 2018-05-18 15:37:29, time elapsed: 00:00:04
GeneratorJob: generated batch id: 1526625444-674207642 containing 2 URLs
Fetch urls:
./build/apache-nutch-2.3.1/runtime/local/bin/nutch fetch -all
FetcherJob: starting at 2018-05-18 15:37:31
初回クロールでは url.txt に設定されたページしかクロールされないので、リンク先の記事は2回目以降の crawl コマンド実行時に取得されます。クロールが終了すると、Discovery にニュース記事が投入されていることが確認できました。
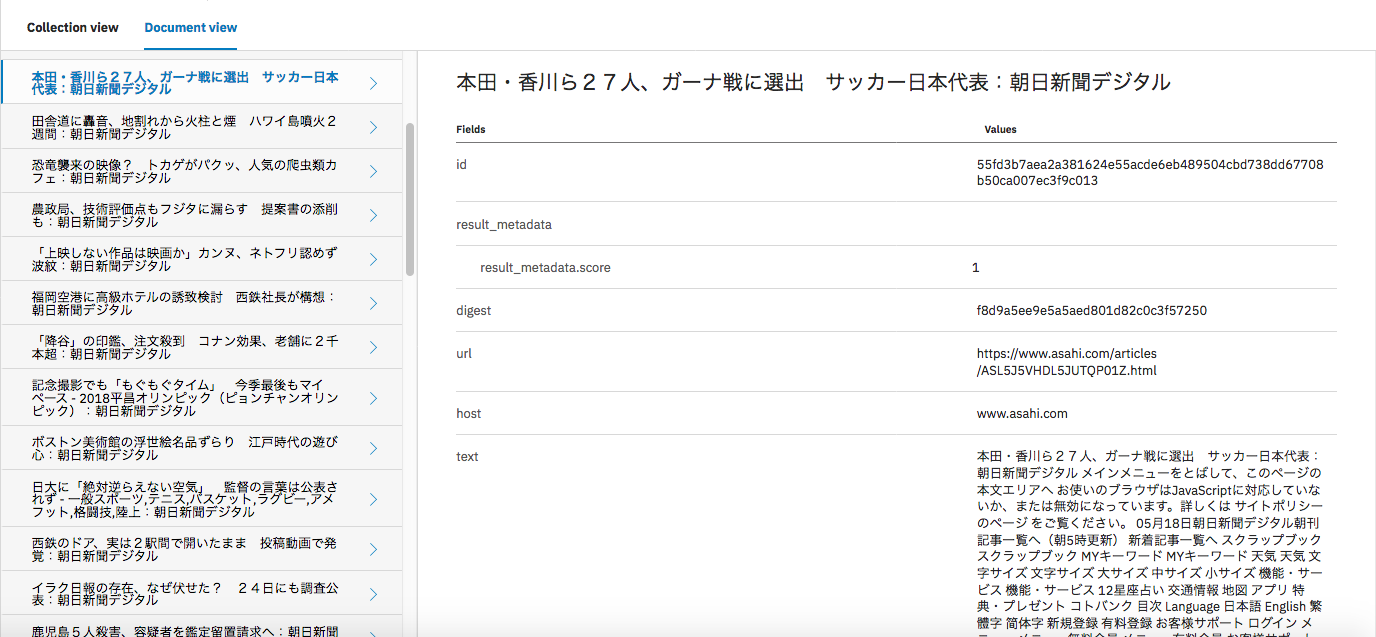
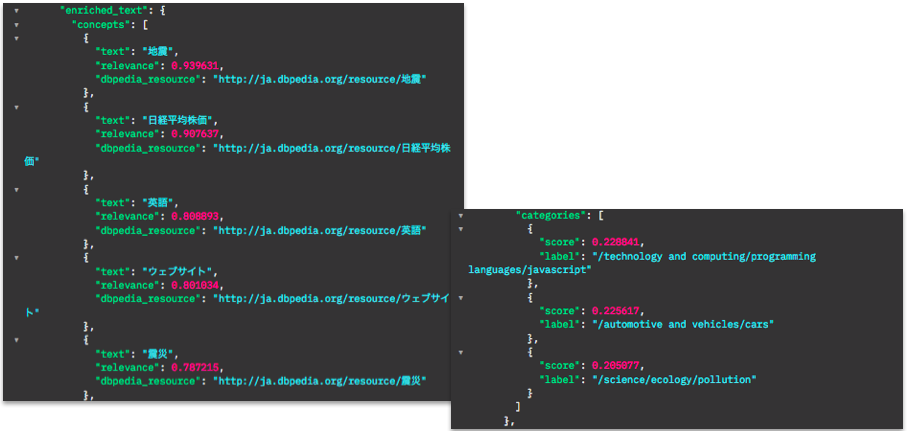
Concept や Category も抽出されてはいますが、 "text" フィールドにニュース記事だけでなく、周りのメニュー等のテキストも入ってきてしまっているので、適切な抽出ができていないようにも見えます。Web ページの必要な箇所のみ切り出す方法については次回考えてみたいと思います。
参考(HBaseの操作)
Nutch 2.x ではクロールしたデータの保存ためにオープンソースの NoSQLデータベース Apache HBase を使用しています。Nutch を使用する上で知っておくと便利な HBase の超基本的な操作を紹介します。
HBase の shell を起動
$ ./hbase shell
2018-05-18 14:14:53,175 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14 18:26:29 PST 2014
hbase(main):001:0>
クロールされたデータの参照
hbase(main):001:0> scan "webpage"
2018-05-18 14:18:52,413 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
ROW COLUMN+CELL
org.wikipedia.en:https/w/opensearch_desc.php column=f:fi, timestamp=1526619305780, value=\x00'\x8D\x00
org.wikipedia.en:https/w/opensearch_desc.php column=f:rsf, timestamp=1526619305780, value=\x00\x00\x00\x00
org.wikipedia.en:https/w/opensearch_desc.php column=f:st, timestamp=1526619305780, value=\x00\x00\x00\x01
org.wikipedia.en:https/w/opensearch_desc.php column=f:ts, timestamp=1526619305780, value=\x00\x00\x01cq\x99\xF3I
org.wikipedia.en:https/w/opensearch_desc.php column=il:https://en.wikipedia.org/wiki/Apache_Nutch, timestamp=1526619305780, value=
org.wikipedia.en:https/w/opensearch_desc.php column=il:https://en.wikipedia.org/wiki/Watson_(computer), timestamp=1526619305780, value=
org.wikipedia.en:https/w/opensearch_desc.php column=mk:dist, timestamp=1526619305780, value=1
org.wikipedia.en:https/w/opensearch_desc.php column=mtdt:_csh_, timestamp=1526619305780, value=\x00\x00\x00\x00
org.wikipedia.en:https/w/opensearch_desc.php column=s:s, timestamp=1526619305780, value=\x00\x00\x00\x00
org.wikipedia.en:https/wiki/42_(number) column=f:fi, timestamp=1526619305780, value=\x00'\x8D\x00
org.wikipedia.en:https/wiki/42_(number) column=f:rsf, timestamp=1526619305780, value=\x00\x00\x00\x00
クロールされたデータの削除
hbase(main):001:0> truncate "webpage"
Truncating 'webpage' table (it may take a while):
2018-05-18 14:23:14,852 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- Disabling table...
- Truncating table...
0 row(s) in 2.6010 seconds