前回の記事では事前学習済みのモデルを使用した類似画像検索を実装しました。今回はこのモデルをさらに学習し、類似検索の精度を高めることを試してみます。前回同様以下リンク先の内容を参考にしています。
https://jifuzhao.github.io/2018/04/13/landmark.html
https://github.com/JifuZhao/Landmark-Recognition
類似度学習
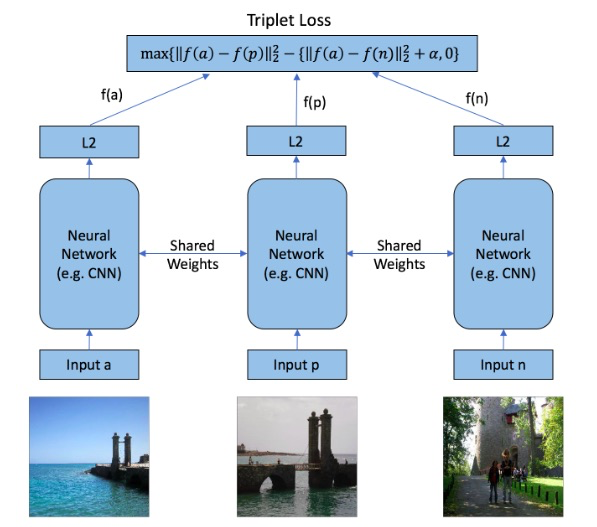
類似度学習に上記リンク先でも紹介されている triplet loss を使用した方法を使用します。triplet には anchor image(a)、positive image(p)、nagative image(n) を含め、これが与えられた時に、n に比べて p がより a に類似している、という結果になることを目指します。下図ように a、p、q を各々同じCNNに入力した際に、出力される特徴ベクトル f(a)、f(p)、f(n) から triplet loss (損失) を算出し、これが小さくなるようにネットワークを学習していきます。
3.1 CNNの学習
前回使用した Inception V3 をベースに、上記の形のネットワークを構築し、triplet lossによる学習を行います。以下のpython のコードをダウンロードして zip に圧縮します。
こちらに記載のとおり、Experimentを作成しネットワークを学習します。
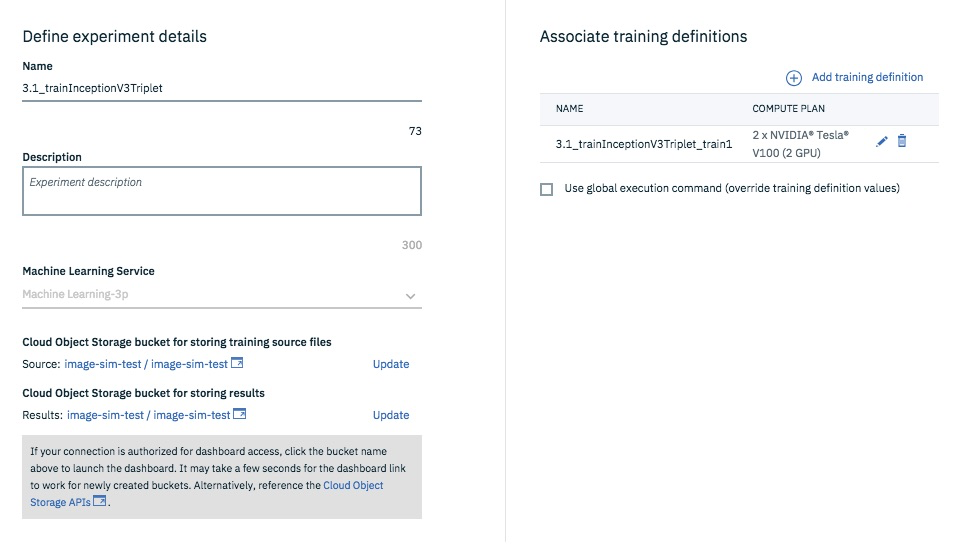
3.1.1 historyの表示(Optional)
以下のURLからNotebookを作成します。
https://github.com/schiyoda/ImageSimilaritySearch/blob/master/3.1.1_VisualizeTrain.ipynb
Notebookを実行すると、学習のhistoryが参照可能です。
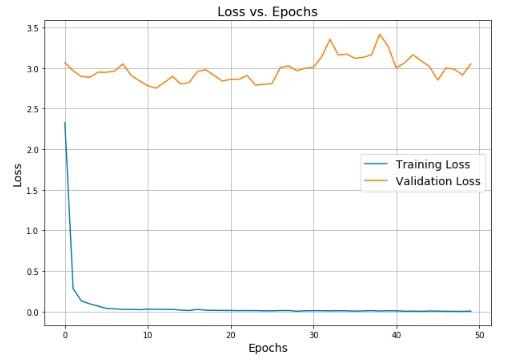
3.2 特徴ベクトルの抽出
以下のpython のコードをダウンロードして zip に圧縮します。
こちらに記載のとおり、Experimentを作成し特徴ベクトルを抽出します。
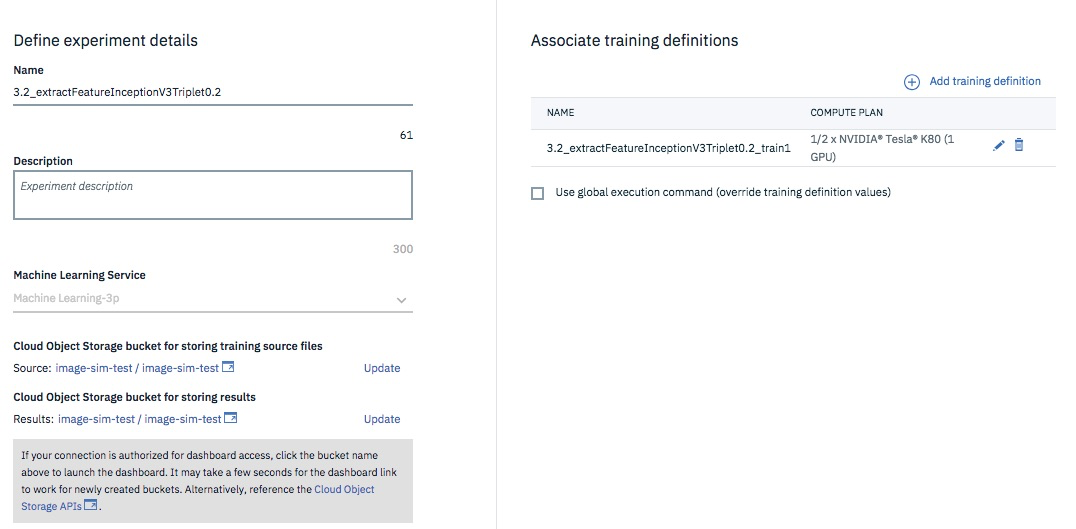
3.3 画像類似度の算出
抽出された各画像の特徴ベクトルから、画像間の類似度を算出します。
以下のURLから新規Notebookを作成します。
セルを全て実行すると以下のように Accuracy が表示され、前回よりも改善されていることが分かります。
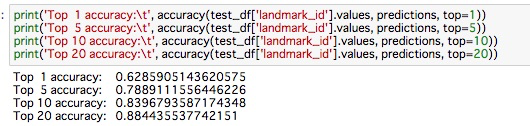
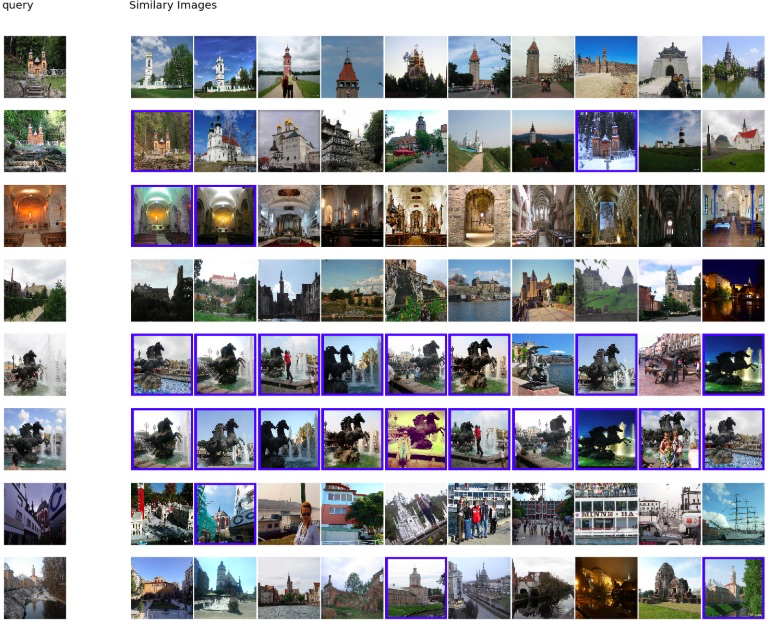
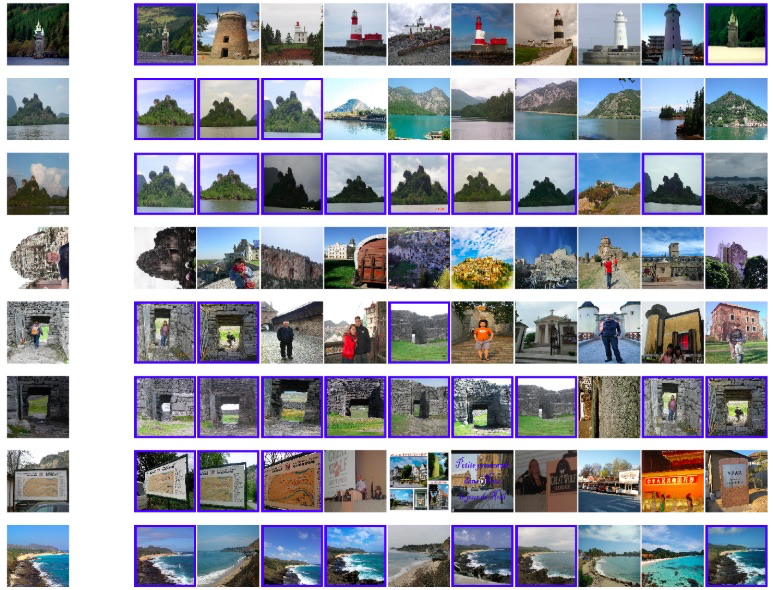
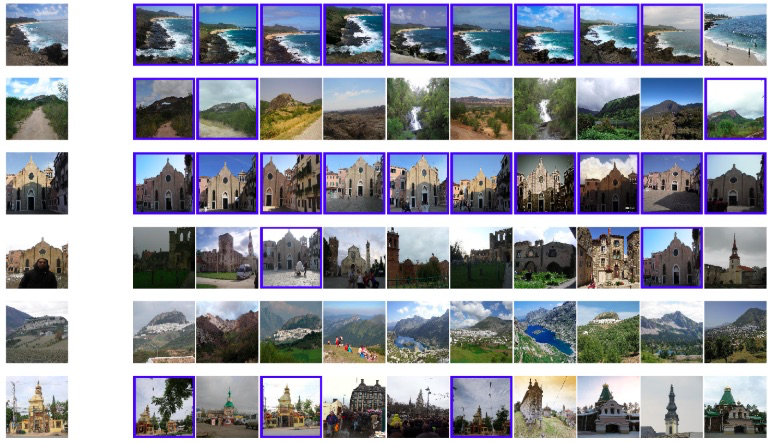
検索された画像は以下の通りです。一番最後のQueryとかは学習の結果、精度が上がっているように思います。