初めに
どうも、クソ雑魚のなんちゃてエンジニアです。
今回の記事は本物のラミィ(HoloLive 5, 6期生)を判定するAIサービスを作ったので、その紹介をさせていただこうといった記事になります。
HoloLiveをもっと盛り上げたいといった方向けに執筆いたしますので、ご参考にしていただければと思います。
背景
まずは以下の切り抜き動画を視聴してみてほしい。
ラ「世の中にはねぇ...そう...『俺が雪花ラミィ本物』って人もいるんですよ~」
「頑なに自分のことを雪花ラミィだと思っているリスナーさんがおるんだけど...」
視「俺もラミィちゃんかもしれない...」
ラ「どういう事だよ!w」
「ラミィちゃんではないだろ...」
視「案外本物かもしれないよ?...」
ラ「どういうこtwww」
このように自分が本物だと自称している精神異z....楽しそうな人が沢山いたようなので、本物は一体誰なのか!紛れ込んでいる不届き者はいるのか!自分はラミィちゃんだと思い込んでいる他のライバーなのではないのか?といった疑問が出てきたわけである。
そこで、本物を導くためにAIさんに判定してもらおうといった趣旨で本サービスを作成したのである。
サービス概要
基礎情報
サービス名:俺が本物のラミィだ
サービスURL:https://www.lamy-ai-judgment.com/
ソースコード:https://github.com/schecthellraiser606/Lamy-MLsite
※現在はサービスを停止しております。
使い方

ログインが必須なわけですが、基本的に画面偏移していけばログインできると思います。
ログイン後はTopページに戻り、AI判定させたい画像をアップロードするだけ。
ラミィちゃんなのか、はたまたラミィちゃんと思い込んでいるだけの違うライバーなのか判定できます。
※その他の判定としてホロライブの5期生と6期生を判定できるようにしています。
また、ユーザーがプロフィールに設定した画像でランキングを閲覧したり、掲示板で「俺こそ本物のラミィだ」と息巻くこともでき、リスナー同士との交流を図ることが出来ます。
雪花ラミィ、ひいてはホロライブを盛り上げていきたい方は是非とも使ってみてはいかがでしょうか!
使用技術
- Frontend
- Lang: JavaScript/TypeScript
- FW: Next.js
- UI library: Chakra UI
- other: ESLint, Cypress, react-dropzone, react-snowfall ...
- Backend
- Lang: Python 3.7.12
- FW: Django 3.2.12
- other: tensorflow, djangorestframework, django-storages, Pillow, ...
- Infra
- AWS(ECS, ECR, RDS, ALB, S3, CloudWatch...)
- DB: MariaDB 10.6
- container: Docker
- IaC: Terraform
- Auth: Firebase Auth
AI詳細
今回のAI技術としてはtensorflow(のKeras…)を用いた。基本的に画像認識に関してはある程度基本となるモデルがすでにくみ上げられているので転移学習でVGG19の学習済の深層学習モデルを採用した。
※詳細はGitHubのソースコードを参照してください。
学習用データ収集
以下ソースを実行し、Google画像から各種かわいいデータを取ってくる。
何の画像を収集するかはコマンドラインから打ち込めばその画像を400件ほど収集してくるので、そのデータをもとに学習する。
import requests
import shutil
import bs4
import os, time
wait_time = 1.5
path = os.path.dirname(os.path.abspath(__file__))
savedir = path + "/images/"
Googleurl = "https://www.google.co.jp/search"
imagenum = 400
# 保存するURLの取得
def image(data, num, val):
# Google画像検索のURL取得
p = {'q': data, 'safe': 'off', 'btnG':'Google+Search', 'tbm': 'isch', 'start': val}
res = requests.get(Googleurl, params=p)
html = res.text # text化
soup = bs4.BeautifulSoup(html,'lxml') # 整形
links = soup.find_all("img") # img elementの取得
link = links[num+1].get("src") # num番目のsrcURLの取得
return link
# 該当するURLからdownload
def download(url, file_name):
req = requests.get(url, stream=True)
if req.status_code == 200:
with open(file_name + ".jpg", 'wb') as f: # binでfileに書き出し
req.raw.decode_content = True
shutil.copyfileobj(req.raw, f) # fileに画像データをコピー
# 検索する子の名前を指名してお出迎え
name = input("なんの画像収集する?:")
filepath = savedir + "/" + name + "/" + name
for val in range(0, imagenum, 20):
for i in range(19):
link = image(name,i, val)
download(link, filepath + str(val+i))
print(link)
time.sleep(wait_time)
VGG19モデル
詳しいモデルのお話は以下の公式ドキュメントを参照してほしい。
上記ソースコードで収集してきた画像を反転させてデータを水増しさせつつ、sklearnで学習データと訓練データを分ける。
そのデータセットをnpyファイルで保存し、再度別224サイズモデルへの比較もできるようにしておく(機械学習は時間がかかるので)
model定義部分(opt関数等、または転移学習後の出力層)は出力されるaccuracyを参考に調整し、モデルを決定していく。
※ちなみに5期生と6期生判定しかされません(笑)
import numpy as np
from tensorflow import keras
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.optimizers import SGD, Adam
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.utils import np_utils
from tensorflow.keras.applications import vgg19
import os, glob
from PIL import Image, ImageOps
from sklearn.model_selection import train_test_split
#パラメータの初期化
classes = ["雪花ラミィ", "獅白ぼたん", "桃鈴ねね", "尾丸ポルカ", "沙花叉クロヱ", "ラプラスダークネス", "鷹嶺ルイ", "博衣こより", "風間いろは"]
num_classes = len(classes)
image_size = 224 #xceptionなどは299
path = os.path.dirname(os.path.abspath(__file__))
X = []
Y = []
for index, classlabel in enumerate(classes):
photos_dir = path + "/images/" + classlabel
files = glob.glob(photos_dir + "/*.jpg")
for i, file in enumerate(files): #各画像を反転させて学習データの水マシ
image = Image.open(file)
image_flip = ImageOps.mirror(image)
image_origin = image.convert("RGB")
image_flip = image_flip.convert("RGB")
image_origin = image_origin.resize((image_size, image_size))
image_flip = image_flip.resize((image_size, image_size))
data_origin = np.asanyarray(image_origin)
data_flip = np.asanyarray(image_flip)
X.extend([data_origin, data_flip])
Y.extend([index, index])
X = np.array(X)
Y = np.array(Y)
#学習データと訓練データを分ける
X_train, X_test, y_train, y_test = train_test_split(X, Y)
xy = (X_train, X_test, y_train, y_test)
#データ保存
np.save(path + "/data_save/imagefiles_224.npy", xy)
#データの読み込み正規化
X_train, X_test, y_train, y_test = np.load(path + "/data_save/imagefiles_224.npy", allow_pickle=True)
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
X_train = X_train.astype("float")/255.0
X_test = X_test.astype("float")/255.0
# model定義
model = vgg19.VGG19(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
# model.summary()
top_model = Sequential()
top_model.add(Flatten(input_shape=model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(num_classes, activation='softmax'))
model = Model(inputs=model.input, outputs=top_model(model.output))
for layer in model.layers[:15]:
layer.trainable = False
opt = Adam(lr=0.0001)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=32, epochs=14)
score = model.evaluate(X_test, y_test, batch_size=32)
model.save("./model_sample/vgg19_transfer.h5")
インフラ構成図
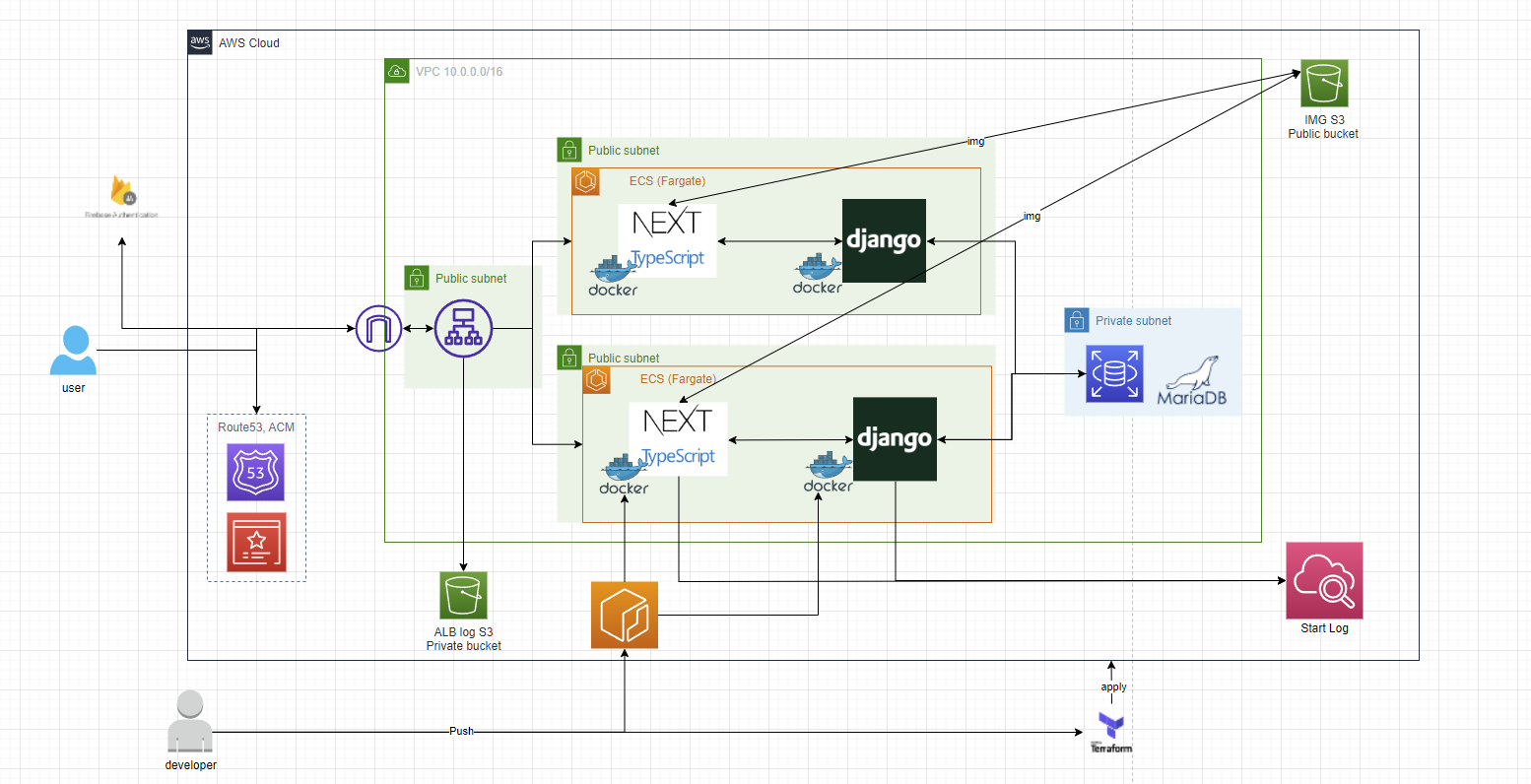
AIモデルファイルを含有したDockerイメージをもとにECRへPushし、そのイメージからECSコンテナを作成しています。
コンテナへの通信はALBでPathルーティングする形にしています。
投稿した画像はDjangoからS3へ保存する形で、その画像をNextコンテナから引っ張ってくるように設計しています。
認証はFirebase Authを利用し、管理を任せています。
AWSリソースは基本的にTerraformで管理しています。
機能群
- AI機能
- 画像投稿機能
- AI判定機能
- クラスタリング
- 精度表示
- プロフィール画像設定機能
- ランキング機能
- 月間ソート
- AllTimeソート
- ライバー判定ごとのソート
- 掲示板機能
- 掲示板作成機能
- コメント機能
- 返信機能
- コメント削除機能
開発環境
IDE: Visual Studio Code
プロジェクト管理: GitHub
デザイン: drawio
まとめ
第十二回の投稿はいかがだったでしょうか?
今回はHoloLiveのさらなる発展の手助けとなればと思います。
...クロエ推し(飼育員)とは言えない...
ラミィちゃんも可愛いなぁ~( ゚Д゚)