はじめに
Microsoftが公開しているOSS「KAITO」について概要をまとめました。KAITOは昨年11月に開催されたMicrosoft Igniteでも取り上げられており、AIシステムを構築する際のツールとして現在注目されているOSSです。私はこの1年間Kubernetesを勉強する機会があり、その中で「AIシステムをKubernetes上でどのように動作させるのか」に興味を持ちました。そこで今回は、KAITOの概要について調査した内容をまとめました。次回の記事では、実際に試用した結果についても紹介する予定です。
KAITOとは
一言で言うと、AIのモデルのデプロイや管理を自動化して、GPUで推論するためのインフラの運用負荷を低減するためのツールです。KAITOはKubernetes上で動作し、AIモデルを実行するための環境構築や運用を効率化します。具体的には、以下のような機能を提供します。
- GPUリソースのプロビジョニングの自動化
- AIモデル推論のランタイムの提供
- Kubernetes上でのLLMやAIジョブの実行管理
これにより、Kubernetesクラスタ上でLLMなどのAIモデルを扱う際の運用を簡素化できます。少しイメージしづらいかもしれませんが、より簡単に表現すると「Kubernetes上でAIシステムの実行と管理を自動化するためのOSS」と言えます。KAITOがどのような用途で利用できるのかを理解するために、次にMicrosoft Igniteで紹介された資料をもとに具体的なユースケースを見ていきます。
引用
「Running AI on Azure Storage: Fast, secure, and scalable」
以下のように、1台のマシンではできない大規模言語モデルの推論を複数ノードやGPUに分散して処理する分散推論をKAITOにより実現可能だそうです。

引用元:https://ignite.microsoft.com/en-US/sessions/BRK174 スライドより
同講演の紹介資料では、KAITOをデプロイした状態で分散推論すると実行時間が5.6倍速くなるとの報告があります。

引用元:https://ignite.microsoft.com/en-US/sessions/BRK174 スライドより
KAITOでできること
通常コンテナの用意からランタイムの設定、スケールリング設定まで手動でする必要があったものを、KAITOを使用することで1つのYAMLファイルで同工程を実現できます。簡単に言えば、デプロイからスケールまでパッケージ化してくれるのです。KAITOで実現可能な機能は、以下の9つとなります。
| 機能 | 説明 |
|---|---|
| 推論 | LLMをKubernetes上でGPUを使って動かす。 |
| マルチノード推論 | 複数ノードで分散処理して推論する。 |
| 自動スケール | 推論ワークロードの自動スケーリングを行う。 |
| ファインチューニング | モデルを微調整する。 |
| RAG | 外部知識を組み込んだ推論を可能とする。 |
| カスタムモデル統合 | 独自モデルをKAITOで使用する。 |
| ツール呼び出し | 外部ツールやAPIを呼び出す。 |
| OCI形式モデル対応 | モデルをOCI準拠として扱う。 |
| Headlamp KAITO | 可視化するためのダッシュボード。 |
これらの機能はシステムの裏側では、「HelmとkubectlでKAITOのワークスペース(もしくはRAGEngine)を動作させ、最終的にはGPUのノードを操作する」ことによって動いております。
ここで「ワークスペース」と「RAGEngine」が出てきましたが、KAITOの操作のタイプとして2種類存在します。
- Workspace
推論とモデルのファインチューニングとリソースのプロビジョニングを行う - RAGEngine
ベクトルストアや埋め込みモデルなどRAGを管理する
「Workspace」と「RAGEngine」の動作イメージが公式サイトに載っていたので、順にご紹介いたします。
Workspaceのアーキテクチャ
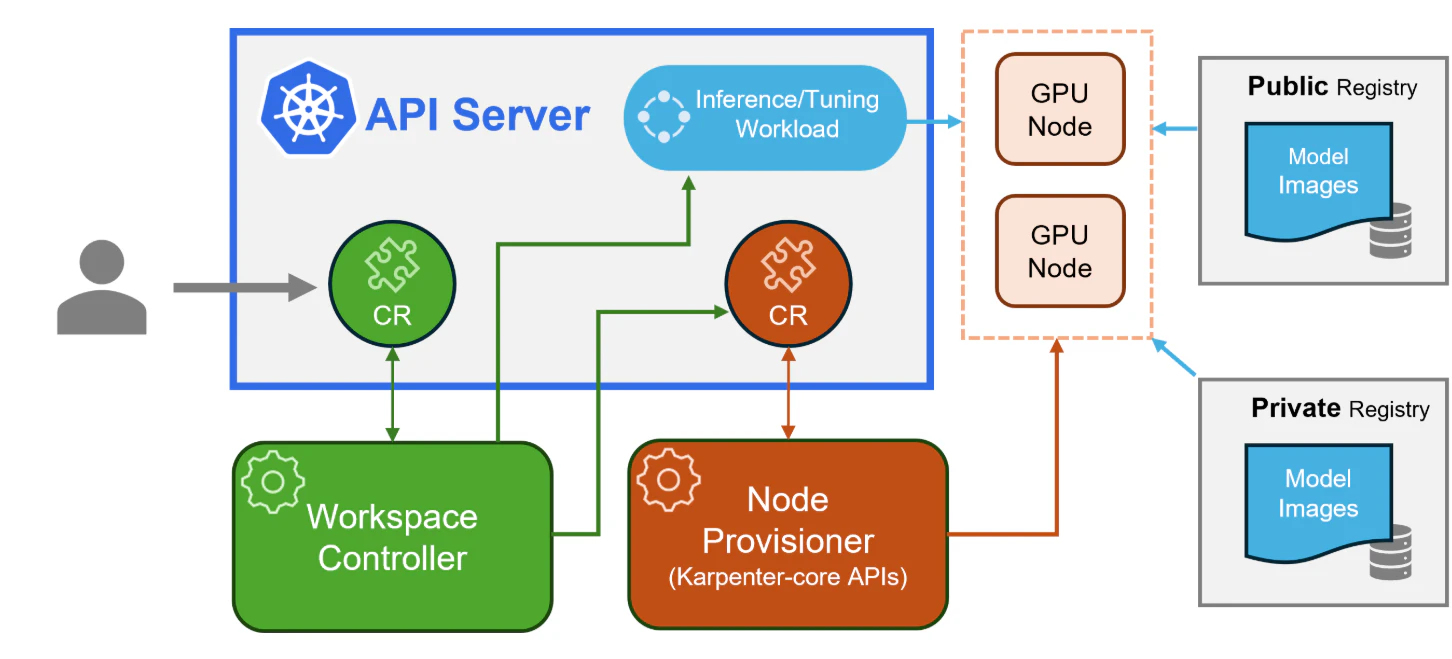
引用
図中の「CR」はCustom Resourceのことであり、PodやDeploymentの他に独自でリソース追加したものを示します。この前提の元、Workspaceのアーキテクチャについてお伝えします。
GPUや使う推論やチューニング要件を定義したCR(図左側のCustom Resource)をインプットし、Workspace ControllerがCR(左)の情報をもとに、CR(右)を生成し、推論やチューニングに必要なワークロードを作成します。その後、Node ProvisionerはCR(右)の定義に基づき、Kubernetes上のクラスターにGPUのノードを追加します。「Node Provisioner」はその名の通りGPUのプロビジョニングを行ってくれるもので、REST APIと連携してKubernetesのクラスタに新しいGPUノードを追加してくれます。
RAGEngineのアーキテクチャ

引用
RAGサービスを使用するための要件を定義したCR(図のCustom Resource)をインプットすると、「RAGEngine Controller」がCRの情報を基に一連のRAGサービスのデプロイを行ってくれるというものです。ここで言うRAG Serviceとは、推論やデータのベクトル化やベクトルデータベースを指します。
おわりに
皆さんKAITOについて少しでも分かっていただけましたでしょうか。前述したようにMicrosoft Igniteでも紹介されており、今ホットなOSSとなっております。皆さんも使用を検討していただければ幸いです。第2弾では実際に試使用してみて、その結果を共有したいと思っております。こうご期待ください。