はじめに
朝日新聞社メディア研究開発センターの嘉田です。
最近類似話者検索を実現するために、OpenSearchのベクトル検索機能を利用して実験を行いました。音声データから抽出した話者の埋め込みベクトルを活用し、クエリとなる話者に近い既存の話者を特定します。
本記事では、類似話者検索の流れを解説するとともに、OpenSearchのベクトル検索を利用する上で確認しておくとよいことをご紹介します。
※ベクトル検索の技術説明、ベクトルデータベース比較、各アルゴリズムの技術説明は行いません。
類似話者検索の仕組み
筆者のケースでは、話者分離後の各話者に対して類似話者を検索するというフローを想定しました。そのため、既存の話者分離フローと組み合わせて次のプロセスで実現を目指しました。
1. 話者分離と話者の埋め込みベクトル生成
話者分離にはpyannote.audioというフレームワークを使用しています。pyannote.audioについては下記の記事も参考にしてください。
pyannote.audioでは話者分離の結果とともに、各話者の埋め込みベクトル(各クラスタのセントロイド)を取得できます。下記のようにreturn_embeddings=Trueを指定します。
diarization, embeddings = pipeline("sample.wav", return_embeddings=True)
for i, speaker in enumerate(diarization.labels()):
print(speaker, embeddings[i].shape)
# SPEAKER_00 (256,)
# SPEAKER_01 (256,)
ちなみに話者分離は不要という方は下記を使って埋め込みベクトルを取得するとよさそうです(pyannote.audioの内部で使われているものです)。
2. ベクトル検索
埋め込みベクトル間の類似度を計算し、クエリとなる話者に近い既存の話者を取得します。
ベクトル検索エンジンにはOpenSearchを利用しました。これはシステムの制約により決定しており、本記事では他のベクトルデータベース(Pinecone等)との比較は行いません。
以降ではOpenSearchの利用に焦点を当てて紹介しています。
実験設定を決めるまでの道のり
OpenSearchでベクトル検索を行う際、エンジンや類似度指標の選択肢が多いので、実験設定の洗い出しにも時間がかかりました。筆者が確認したポイントを下記に整理します。OpenSearchでベクトル検索を検証したい方の参考になれば幸いです。
エンジン
個人的にはまずメタデータフィルタリングの有無や要件を確認するのが良いかと思います。下記のようにフィルタリング方法によってサポートしているエンジンが異なります。
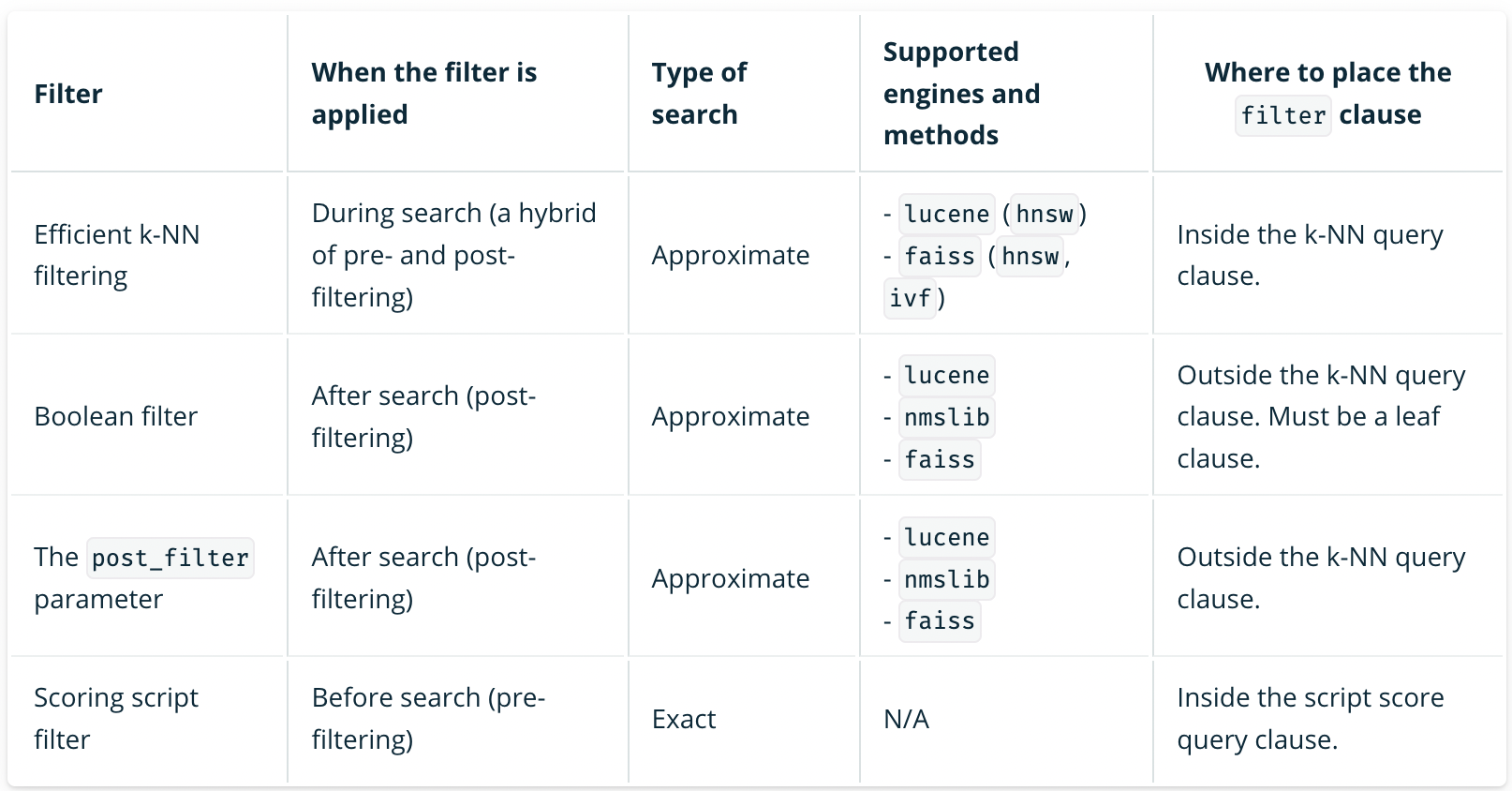
出典:https://opensearch.org/docs/latest/search-plugins/knn/filter-search-knn/
筆者のケースでは、実際のフローでメタデータフィルタリングを必要としており、フィルタリング手法としてEfficient k-NN filtering が適していると判断したため、この時点でエンジンに「Lucene、Faiss」という制約が発生しました。
アルゴリズムと類似度指標
各エンジンが対応しているアルゴリズムと類似度指標は下記に記載があります。
https://opensearch.org/docs/latest/search-plugins/knn/knn-index/#method-definitions
今回は簡易に実験すべく、学習不要なHNSWで検証を行いました。IVFはまたの機会に...。
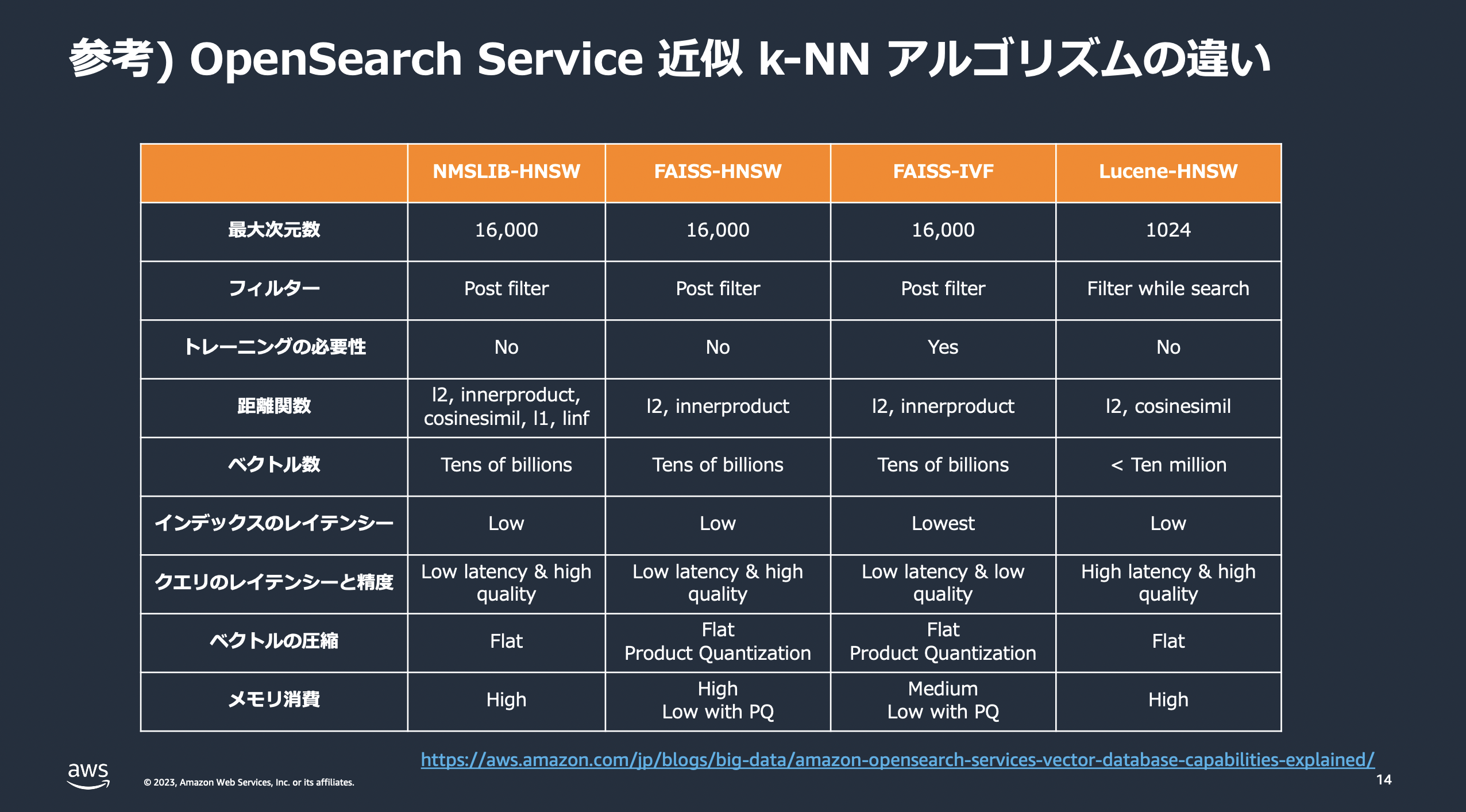
出典:https://pages.awscloud.com/rs/112-TZM-766/images/20231005-Analytics-03-AWS.pdf
類似度指標は対応しているものを全て試しました(コサイン類似度、ユークリッド距離、内積)。
ここで、埋め込みベクトルの類似度指標でメジャーと思われるコサイン類似度がFaissではサポートされていないので、検索対象・クエリの両方のベクトルを正規化してユークリッド距離を指標にすることでコサイン類似度に対応させました(方法は後述)。
※添付した画像には記載がないですが、筆者が確認した時点ではLucene-HNSWのサポートする距離関数(類似度指標)に内積も含まれていました:https://opensearch.org/docs/latest/search-plugins/knn/knn-index/#supported-lucene-methods
メモリ消費量の試算
ベクトル検索を実現するにあたって精度の検証はもちろん重要ですが、OpenSearchのスペック的に現実的かどうかも確認する必要があります。OpenSearchのベクトル検索では、アルゴリズムや格納するデータ量によってメモリ消費量が大きく変動するため、事前に適切な試算を行うことが不可欠です。以下に、ベクトル検索におけるメモリ消費量の試算の流れを整理します。
1. 格納するベクトルの次元と数を確認
筆者のケースでは256次元のベクトルで、100,000件程度を想定しています。
2. 使用するアルゴリズムのメモリ消費量を計算
例えばHNSWでは下記のようにメモリ消費量を計算できます。
1.1 \times (4 \times \text{dimension} + 8 \times \text{m}) \times \text{num_of_vectors} \times (1 + \text{num_of_replicas}) \text{ bytes}
-
dimension:ベクトルの次元数 -
m:HNSWのパラメータ(デフォルト16) -
num_of_vectors:ベクトル数 -
num_of_replicas:レプリカシャード数
参考:https://opensearch.org/docs/latest/search-plugins/knn/knn-index/#hnsw-memory-estimation
3. メモリ消費量から必要なデータノード数を計算
ノードごとに利用可能なメモリ量は下記のように計算でき、2のメモリ消費量に対して何台のノードが必要か計算します。
(\text{node_memory} - \text{jvm_size}) \times \text{circuit_breaker_limit} \text{ GB}
-
node_memory:インスタンスの全メモリ容量 -
jvm_size:OpenSearchのJVMヒープサイズ(インスタンスRAMの半分に設定され、約32GBで上限が設定される) -
circuit_breaker_limit:サーキットブレーカーのネイティブメモリ消費量の閾値(0.5に設定されている)
例えば筆者のケースでは下記のようになります。インスタンスタイプはm6g.large.search を想定しています。
\begin{align}
&\text{dimension} = 256\\
&\text{m} = 16\\
&\text{num_of_vectors} = 100,000\\
&\text{num_replicas} = 1\\
&\text{node_memory} = 8\\
&\text{jvm_size} = 8 \div 2 = 4\\
&\text{メモリ消費量} = 1.1 \times (4 \times 256 + 8 \times 16) \times 100,000 \times (1 + 1) = 0.236 \text{ GB}\\
&\text{ノードごとに使用可能なメモリ量} = (8 - 4) \times 0.5 = 2 \text{ GB}\\
&\text{必要なデータノード数} = 0.236 \div 2 = 0.118 → 1 \text{ 台}
\end{align}
というように、計算上は1台運用でも問題なさそうだとわかります(実際は冗長化のためにデータノードは2つ以上が推奨されています)。
量子化
上記でメモリ消費量を試算しましたが、ベクトル数が10倍、100倍となる場合は、ノード数を増やすか、よりサイズの大きいインスタンスタイプを使用する必要があります。少しでもメモリ消費量を抑えたい...という方は量子化も検討しましょう。
量子化手法は様々ありますが、OpenSearchバージョンによって対応状況が異なるので注意が必要です。現状はv2.17以降であれば全て対応しています。詳しくは下記からご確認ください。
https://opensearch.org/docs/latest/search-plugins/knn/knn-vector-quantization/
例えばv2.17で対応したBinary quantizationの 1-bit quantization では、上記と同様のケースでメモリ消費量が下記の通りとなり、1/7程度になります。
1.1 \times ((256 \times 1 / 8) + 8 \times 16) \times 100,000 \times (1 + 1) = 0.0328 \text{ GB}
今回の検証では Binary quantization と Scalar quantization を試しました。
実験
類似話者検索を試した際のコードや実験結果をご紹介します。
検証環境
ローカル環境でOpenSearchを起動して実験を行いました。
ここではAmazon OpenSearchで対応している最新バージョン「v2.17.0」を使用した設定例を示します。なお、一時的なテスト環境のため認証を無効化していたり、細かい設定は行っていません。詳細は下記も参考にしてください。
https://opensearch.org/docs/latest/install-and-configure/install-opensearch/docker/
1. DockerによるOpenSearchの起動
バージョンは必要に応じて変更してください。
docker pull opensearchproject/opensearch:2.17.0
docker run -d --name opensearch -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" -e "plugins.security.disabled=true" -e "OPENSEARCH_INITIAL_ADMIN_PASSWORD=Hogehoge1!" opensearchproject/opensearch:2.17.0
OPENSEARCH_INITIAL_ADMIN_PASSWORDは管理者パスワードを設定する変数であり、設定必須でした。形式にも注意が必要です。
2. 起動確認
curl -X GET http://localhost:9200/
結果として下記のようなレスポンスが返れば正常に起動しています。
{
"name" : "79c19f8ace33",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "YiVqLhZ8TZqb83wbaXIsEQ",
"version" : {
"distribution" : "opensearch",
"number" : "2.17.0",
"build_type" : "tar",
"build_hash" : "8586481dc99b1740ca3c7c966aee15ad0fc7b412",
"build_date" : "2024-09-13T01:04:14.707418737Z",
"build_snapshot" : false,
"lucene_version" : "9.11.1",
"minimum_wire_compatibility_version" : "7.10.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
3. ダッシュボードの利用(任意)
OpenSearch Dashboardを使用する場合、下記のコマンドでダッシュボードを起動できます。ダッシュボードは http://localhost:5601 でアクセス可能です。
docker pull opensearchproject/opensearch-dashboards:2.17.0
docker run -d --name opensearch-dashboards -p 5601:5601 --link opensearch:opensearch -e "OPENSEARCH_HOSTS=http://opensearch:9200" -e "DISABLE_SECURITY_DASHBOARDS_PLUGIN=true" opensearchproject/opensearch-dashboards:2.17.0
インデックス作成
実験では、エンジンや類似度指標、量子化手法ごとにインデックスを作成しました。上述の通りアルゴリズムはHNSWを使用し、HNSWのパラメータも固定しています。下記はインデックス作成のコード例です。
import json
import requests
url = "http://localhost:9200"
headers = {"Content-Type": "application/json"}
indexes = [
{
"index_name": "faiss_l2",
"vector_mapping": {
"type": "knn_vector",
"dimension": 256,
"method": {
"name": "hnsw",
"engine": "faiss",
"space_type": "l2",
"parameters": {
"ef_construction": 100,
"m": 16,
},
},
},
"requires_normalization": False, # ベクトルを正規化するかどうかを表すフラグ
},
...,
]
for index in indexes:
mapping = {
"settings": {
"index": {
"knn": True,
"number_of_shards": 1,
"number_of_replicas": 1,
"knn.algo_param.ef_search": 100,
}
},
"mappings": {
"properties": {
"vector": index["vector_mapping"],
"speaker_id": {"type": "keyword"}, # メタデータ
"user_id": {"type": "keyword"}, # メタデータ
}
},
}
index_name = index["index_name"]
response = requests.put(f"{url}/{index_name}", headers=headers, data=json.dumps(mapping))
print(response.json())
検索対象のデータ格納
下記のような形式のCSVを用意しました。
| embedding_path | speaker_id | user_id |
|---|---|---|
| speaker1.npy | speaker1 | user1 |
| speaker2.npy | speaker2 | user1 |
-
embedding_path:埋め込みベクトルを出力したファイルパス -
speaker_id:話者ID -
user_id:話者を登録したユーザーID(メタデータフィルタリングに必要)
下記はデータ格納のコード例です。np.linalg.normを使ってベクトルを正規化し、Faissでコサイン類似度での評価を行っています。
import json
import numpy as np
import pandas as pd
import requests
url = "http://localhost:9200"
headers = {"Content-Type": "application/json"}
df = pd.read_csv("sample.csv")
for index in indexes:
bulk_data = ""
for row in df.itertuples():
embedding = np.load(row.embedding_path)
if index.get("requires_normalization"):
embedding = embedding / np.linalg.norm(embedding, ord=2, keepdims=True)
item = {
"vector": embedding.tolist(),
"speaker_id": row.speaker_id,
"user_id": row.user_id,
}
bulk_data += json.dumps({"index": {"_index": index["index_name"], "_id": row.speaker_id}}) + "\n"
bulk_data += json.dumps(item) + "\n"
response = requests.post(f"{url}/_bulk", headers=headers, data=bulk_data)
print(response.status_code)
検索
下記はメタデータ(例:user_id)でフィルタリングしながら検索を行うコード例です。なお今回のケースでは、Top1検索結果のみを評価対象としているため、上位1件を取得しています。
import json
import numpy as np
import requests
url = "http://localhost:9200"
headers = {"Content-Type": "application/json"}
index_name = "faiss_l2"
search_url = f"{url}/{index_name}/_search"
query_vector = np.load("query_vector.npy")
if index.get("requires_normalization"):
query_vector = query_vector / np.linalg.norm(query_vector, ord=2, keepdims=True)
search_query = {
"size": 1,
"query": {
"knn": {
"vector": {
"vector": query_vector.tolist(),
"k": 1,
"filter": {"bool": {"must": [{"term": {"user_id": "user1"}}]}},
}
}
},
}
response = requests.post(search_url, headers=headers, data=json.dumps(search_query))
result = response.json()
if len(result["hits"]["hits"]) > 0:
print(result["hits"]["hits"][0]["_id"], result["hits"]["hits"][0]["_score"])
ちなみに、Radial search を使うと距離(max_distance)・類似度スコア(min_score)の閾値を指定して検索結果を取得することもできます。実際のフローでは使う場面も多そうです。とはいえ現時点ではFaissでしか対応していません...。

出典:https://opensearch.org/docs/latest/search-plugins/knn/approximate-knn/#ef_search
評価方法
独自のテストデータを構築し、検索結果の評価を行いました。具体的にはTop1検索結果のspeaker_idが正解の類似話者のspeaker_idと一致しているかを確認しました。実際のコードではありませんが、下記のようなイメージです。
speaker_id = "speaker1"
similar_speaker_ids = ["speaker10"]
inf_speaker_id, score = search(query_vector) # ベクトル検索の結果
result = "OK" if inf_speaker_id in similar_speaker_ids and score >= score_thresh else "NG"
一致を判定する閾値(score_thresh)は、一番精度が高くなる値を0.05刻みで探索して決定しました。各類似度指標のスコアの閾値は下記の通りです。
- コサイン類似度:0.65
- ユークリッド距離:0.2
- 内積:6.2
このスコアはあくまでOpenSearchが検索時に付与するスコアであり、純粋な類似度指標の値ではない点にご注意ください。OpenSearchのスコア付けの詳細については下記に記載があります(コサイン類似度の場合、OpenSearchスコアが0.65 = コサイン類似度で約0.86)。
https://opensearch.org/docs/latest/search-plugins/knn/approximate-knn/#spaces
なお、データ数は下記の通りです。
-
検索クエリとなる評価用データ:30件
- 検索対象内に同一話者が含まれる:20件
- 検索対象内に同一話者が含まれない:10件
-
OpenSearchに格納する(検索対象となる)データ総数:420件
-
similar_speaker_idsに含まれる話者(類似話者候補):35件 -
similar_speaker_idsに含まれない話者:385件
-
結果
実験設定が多岐に渡るため詳細な値は割愛しますが、結果は下記の通りでした。
- HNSWのパラメータを一致させると、FaissとLuceneの結果は同一であった
- コサイン類似度を使用した場合は100 %の精度であった(30/30)
- ユークリッド距離:93 %
- 内積:73 %
- 量子化による精度の低下は見られなかった
- Faissはスコア含め変化なし
- Luceneではスコアが微妙に変化したが、精度は変わらず
追加実験としては、m のようなHNSWのパラメータを変化させて検証することも検討中です。
おわりに
無事に類似話者検索を実現できそうで、めでたしめでたし。
加えて、今回の検証を通じてOpenSearchでベクトル検索を実装する際の知見を様々得ることができました。「ベクトル検索すればいいだけ」ではありますが、思っていたよりも検討すべきことが多く、実際のフローを検討した上で公式ドキュメントをあちこち確認したり、様々な設定で検証したりと、予想以上に時間を費やしました。
類似話者検索の実装や、OpenSearchを活用したベクトル検索機能の検証を進めたい方にとって、少しでも参考になれば幸いです。