前説
「PythonでFlickr APIから画像取得」に掲載されているテンプレートコードをリファクタリングしてみた(前編) の続きです。 FlickrAPIを使って画像を取得するところまでは終わりました。ですが、逐次処理をしているため多くのキーワードを使って尚且つ多くの画像を取得することは厳しいです。ここでは並列処理に修正してどのくらい処理速度がいい感じになったか確認したいと思います。
前回のコード
from flickrapi import FlickrAPI
import requests
import os, time, sys
import configparser
import time
#画像フォルダパス
imgdir = os.path.join(os.getcwd(), "images")
#Flickr APIを使う
def request_flickr(keyword, count=100, license=None):
# 接続クライアントの作成とサーチの実行
config = configparser.ConfigParser()
config.read('secret.ini')
flickr = FlickrAPI(config["private"]["key"], config["private"]["secret"], format='parsed-json')
result = flickr.photos.search(
text = keyword, # 検索キーワード
per_page = count, # 取得データ数
media = 'photos', # 写真を集める
sort = 'relevance', # 最新のものから取得
safe_search = 1, # 暴力的な画像を避ける
extras = 'url_l, license' # 余分に取得する情報(ダウンロード用のURL、ライセンス)
)
return list(filter(lambda x : multiConditionLicenses(int(x["license"]), license), result["photos"]["photo"]))
def multiConditionLicenses(src, license=None):
dst = []
if license is None:
dst.append(lambda x : 0 <= x)
else :
license_types = license.split("|")
for t in license_types:
if t == "All_Rights_Reserved": #コピーライト
dst.append(lambda x : x == 0)
elif t == "NonCommercial": #非商用化
dst.append(lambda x : 1 <= x and x <= 3)
elif t == "Commercial": #商用化
dst.append(lambda x : 4 <= x and x <= 6)
elif t == "UnKnown": #商用化
dst.append(lambda x : x == 7)
elif t == "US_Government_Work": #商用化
dst.append(lambda x : x == 8)
elif t == "PublicDomain": #商用化
dst.append(lambda x : 9<= x and x <= 10)
return 0 < sum([item(src) for item in dst])
# 画像リンクからダウンロード
def download_img(url, file_name):
r = requests.get(url, stream=True)
if r.status_code == 200:
with open(file_name, 'wb') as f:
f.write(r.content)
if __name__ == "__main__":
# 処理時間計測開始
start = time.time()
#クエリを取得
query = None
with open("query.txt") as fin:
query = fin.readlines()
query = [ q.strip() for q in query]
# 保存フォルダ
for keyword in query:
savedir = os.path.join(imgdir, keyword)
#なければフォルダ作成
if not os.path.isdir(savedir):
os.mkdir(savedir)
photos = request_flickr(keyword, count=500, license="NonCommercial|Commercial")
for photo in filter(lambda p : "url_l" in p.keys(), photos):
url = photo['url_l']
filepath = os.path.join(os.path.join(imgdir, keyword), photo['id'] + '.jpg')
download_img(url, filepath)
time.sleep(1)
print('処理時間', (time.time() - start), "秒")
修正したい部分
- FlickrAPIを使った複数のキーワード検索を並列処理をしたい
- 画像リンクからダウンロードする処理を並列処理したい
方法
並列処理だと concurrent.futures.ThreadPoolExecutor を使おうかなと思ったのですが、
joblib の方が記述がシンプルなのでこちらを使ってみます。 次の通り、リスト内包表記で1行で書くことができます。
Parallel(n_jobs=8)([delayed({callback_func})(param1, param2, ...) for {element} in {list}])
ここでは複数のキーワードをflickrAPIにリクエストすることと、APIのレスポンスを取得した後にひとつのキーワードから複数の画像URLを取得することの大きく二つの処理を階層・並列化してみます。
#親階層での処理
def main_process(keyword, count=100, wait_time=1):
# 結果の取り出しと格納
photos = request_flickr(keyword, count=count)
#画像をダウンロード
#keyに"url_l"が含まれているものだけ抽出(子階層プロセスの呼び出し元)
Parallel(n_jobs=-1)([delayed(sub_process)(photo, keyword=keyword, wait_time=wait_time) for photos])
#子階層での処理
def sub_process(src, keyword, wait_time=1):
url = "https://farm{farm_id}.staticflickr.com/{server_id}/{id}_{secret}.jpg" \
.format(farm_id=src["farm"],
server_id=src["server"],
id=src["id"],
secret=src["secret"])
filepath = os.path.join(os.path.join(imgdir, keyword), src['id'] + '.jpg')
download_img(url, filepath)
time.sleep(wait_time)
if __name__ == "__main__":
...
query = ["池袋","大塚","巣鴨","駒込","田端"]
#複数のキーワードをflickrAPIへリクエスト(親階層プロセスの呼び出し元)
Parallel(n_jobs=-1)([delayed(main_process)(keyword, count=500, wait_time=1) for keyword in query])
...
n_jobs のパラメータはプロセス数を表しています。 1の場合は実質逐次処理を、-1の場合は実行するCPUの最大プロセス数を指定することができます。
実際にやってみた
準備
キーワードですが、山手線の駅名を用いました。
池袋
大塚
巣鴨
駒込
田端
西日暮里
日暮里
鶯谷
上野
御徒町
秋葉原
神田
東京
有楽町
新橋
浜松町
田町
品川
大崎
五反田
目黒
恵比寿
渋谷
原宿
代々木
新宿
新大久保
高田馬場
目白
コード全体
from flickrapi import FlickrAPI
from urllib.request import urlretrieve
import requests
import os, time, sys
import configparser
import time
from joblib import Parallel, delayed
#画像フォルダパス
imgdir = os.path.join(os.getcwd(), "images")
__JOB_COUNT__ = 1
#Flickr APIを使う
def request_flickr(keyword, count=100, license=None):
# 接続クライアントの作成とサーチの実行
config = configparser.ConfigParser()
config.read('secret.ini')
flickr = FlickrAPI(config["private"]["key"], config["private"]["secret"], format='parsed-json')
result = flickr.photos.search(
text = keyword, # 検索キーワード
per_page = count, # 取得データ数
media = 'photos', # 写真を集める
sort = 'relevance', # 最新のものから取得
safe_search = 1, # 暴力的な画像を避ける
extras = 'license' # 余分に取得する情報(ダウンロード用のURL、ライセンス)
)
return list(filter(lambda x : multiConditionLicenses(int(x["license"]), license), result["photos"]["photo"]))
def multiConditionLicenses(src, license=None):
dst = []
if license is None:
dst.append(lambda x : 0 <= x)
else :
license_types = license.split("|")
for t in license_types:
if t == "All_Rights_Reserved": #コピーライト
dst.append(lambda x : x == 0)
elif t == "NonCommercial": #非商用化
dst.append(lambda x : 1 <= x and x <= 3)
elif t == "Commercial": #商用化
dst.append(lambda x : 4 <= x and x <= 6)
elif t == "UnKnown": #商用化
dst.append(lambda x : x == 7)
elif t == "US_Government_Work": #商用化
dst.append(lambda x : x == 8)
elif t == "PublicDomain": #商用化
dst.append(lambda x : 9<= x and x <= 10)
return 0 < sum([item(src) for item in dst])
# 画像リンクからダウンロード
def download_img(url, file_name):
r = requests.get(url, stream=True)
if r.status_code == 200:
with open(file_name, 'wb') as f:
f.write(r.content)
else :
print("not download:{}".format(url))
#親階層での処理
def main_process(keyword, count=100, wait_time=1):
# 結果の取り出しと格納
photos = request_flickr(keyword, count=count)
#画像をダウンロード
#keyに"url_l"が含まれているものだけ抽出(子階層プロセスの呼び出し元)
Parallel(n_jobs=__JOB_COUNT__)([delayed(sub_process)(photo, keyword=keyword, wait_time=wait_time) for photo in photos ])
#子階層での処理
def sub_process(src, keyword, wait_time=1):
url = "https://farm{farm_id}.staticflickr.com/{server_id}/{id}_{secret}.jpg" \
.format(farm_id=src["farm"],
server_id=src["server"],
id=src["id"],
secret=src["secret"])
filepath = os.path.join(os.path.join(imgdir, keyword), src['id'] + '.jpg')
download_img(url, filepath)
time.sleep(wait_time)
if __name__ == "__main__":
# 処理時間計測開始
start = time.time()
#クエリを取得
query = None
with open("query.txt") as fin:
query = fin.readlines()
query = [ q.strip() for q in query]
# 保存フォルダ
for keyword in query:
savedir = os.path.join(imgdir, keyword)
#なければフォルダ作成
if not os.path.isdir(savedir):
os.mkdir(savedir)
#複数のキーワードをflickrAPIへリクエスト(親階層プロセスの呼び出し元)
Parallel(n_jobs=__JOB_COUNT__)([delayed(main_process)(keyword, count=10, wait_time=1) for keyword in query])
print('並列処理', (time.time() - start), "秒")
前回との異なる点は、画像をより確実に取得するために https://farm{farm-id}.staticflickr.com/{server-id}/{id}_{secret}.jpg のリンクを使っています。 (Flickr API :Photo Source URLsを参照)
今回はダウンロードの処理速度を目的としているのでlicenseのパラメータは振っていないです。countは10にしています。これで290枚の画像を取得しています。各画像URLからダウンロードした後のスリープタイムは0.5秒にしました。
それで、プロセス数が 1,2,4,8,16,24,32,max(-1) のそれぞれの時にどのくらいの処理速度になるのかを計測してみました。
結果
| プロセス数 | 処理時間(sec) |
|---|---|
| 1 | 360.21357011795044 |
| 2 | 83.60558104515076 |
| 4 | 27.984444856643677 |
| 8 | 11.372981071472168 |
| 16 | 8.048759937286377 |
| 24 | 11.179131984710693 |
| 32 | 11.573050022125244 |
| max (n_jobs=-1) | 25.939302921295166 |
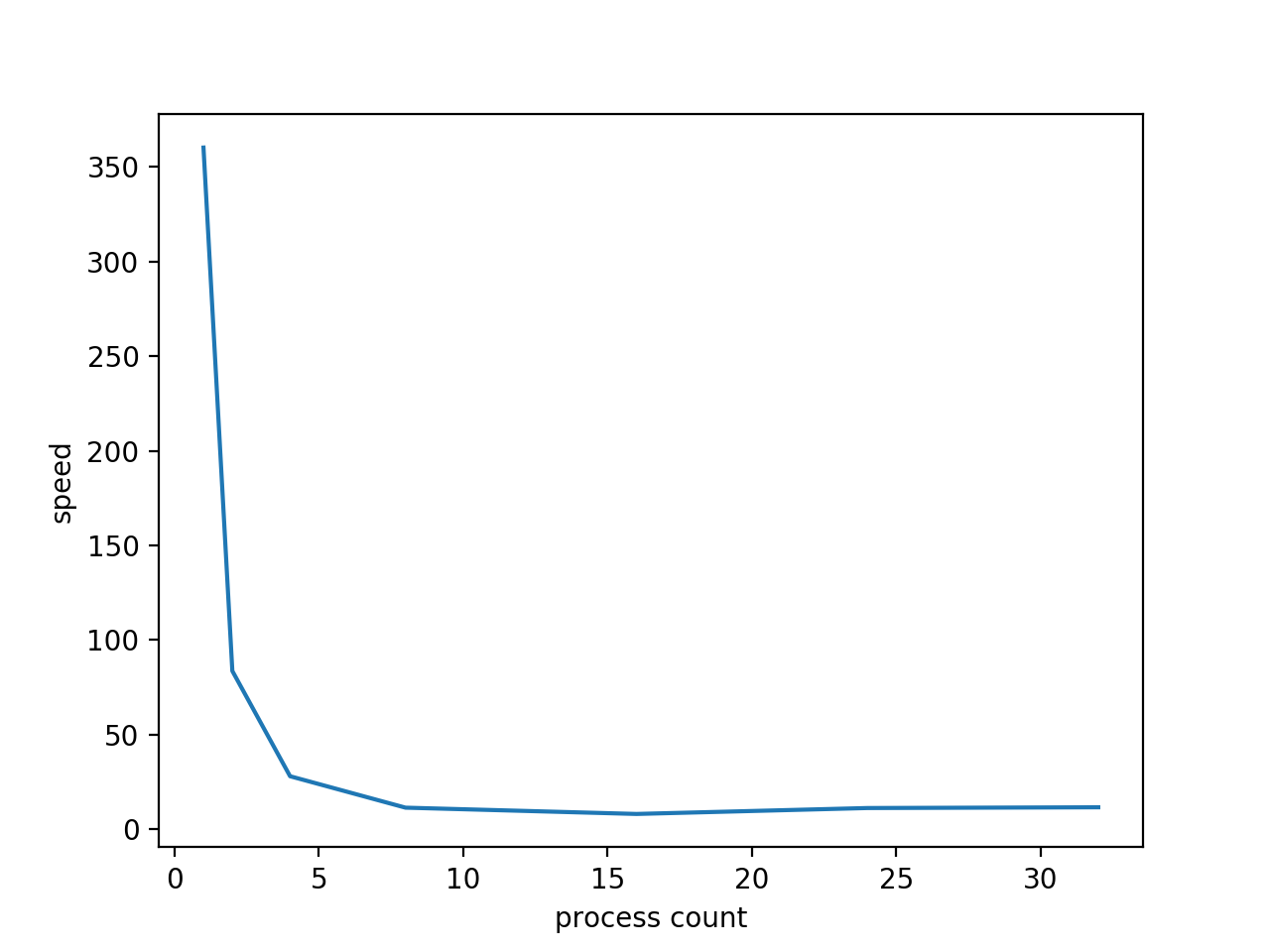 なまデータ
なまデータ
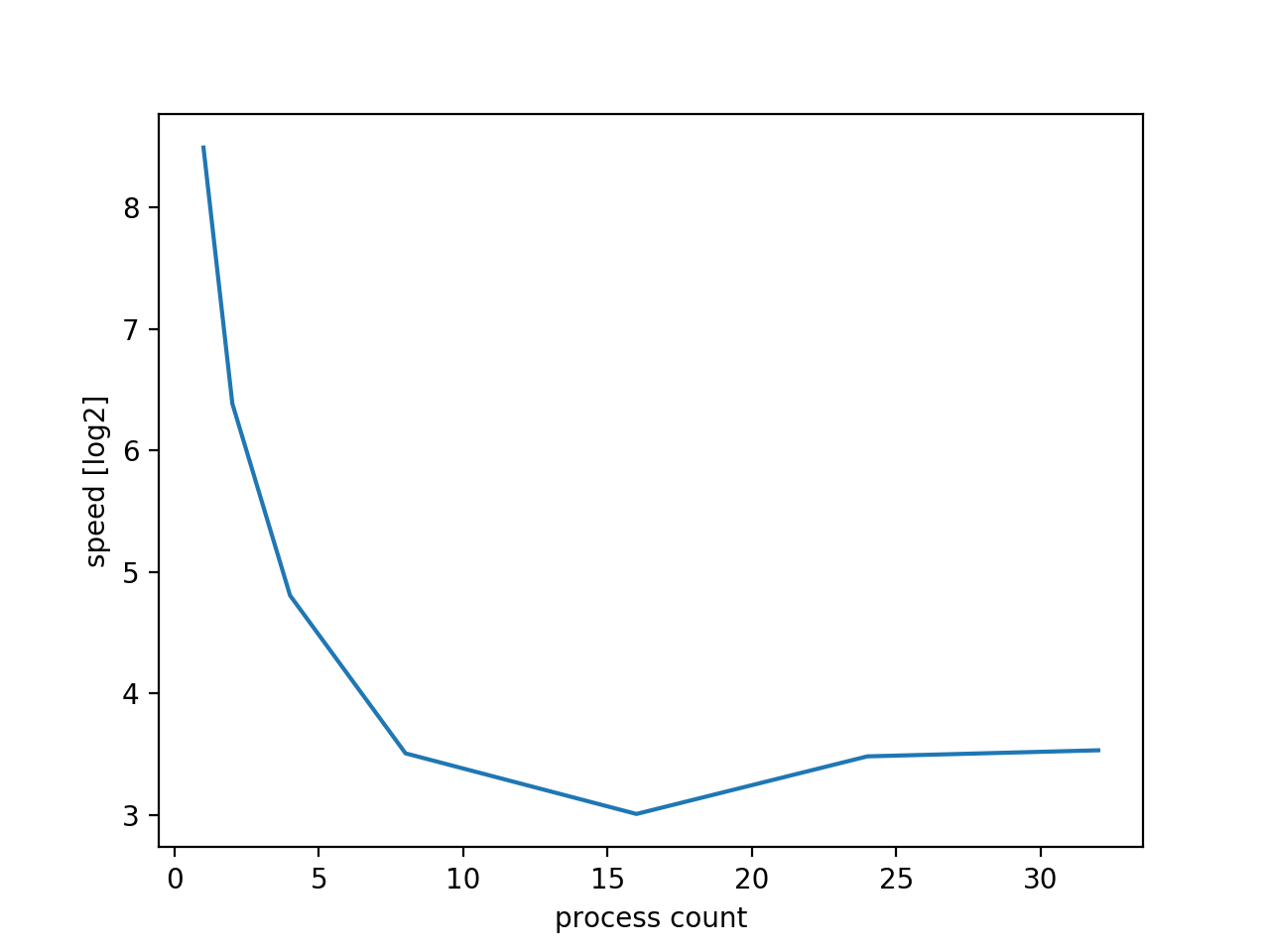 速度を対数にした時
速度を対数にした時
逐次処理するよりも40~50倍の速度で処理が完了しています。 ![]()
n_jobs=-1 のパラメータですが最大値設定をしているものの固定値16を入力した方が速いです。 実行環境では import os os.cpu_count()=4 であるため、おそらくcpuのプロセス数に依存していると思います。
余談ですがflickrAPIは 3600 data/hour と制限があります。ですが、多めのループ処理には結構使えそうです。
おわりに
Fluent Python 第17章では国旗を並列処理でダウンロードするサンプルが掲載されているが、今回のflickrAPIの方がより実践的です。 Futureを使った場合やもっと最適化した並列処理をしたいと思った時は良いサンプル題材にもなるのも良いポイントです。![]()