Background
AWS Lambda を使ってFizzBuzzしたったの続き。
今回はスクレイピングで外部のWebページからデータを取得してみた。
AWS Architecture

- S3(データ保存)
- AWS Lambda(データ処理)
- Amazon EventBridge(定期実行)
の3つのサービスを使っています。
Setting
S3
データ保存用のバケットを作成します。
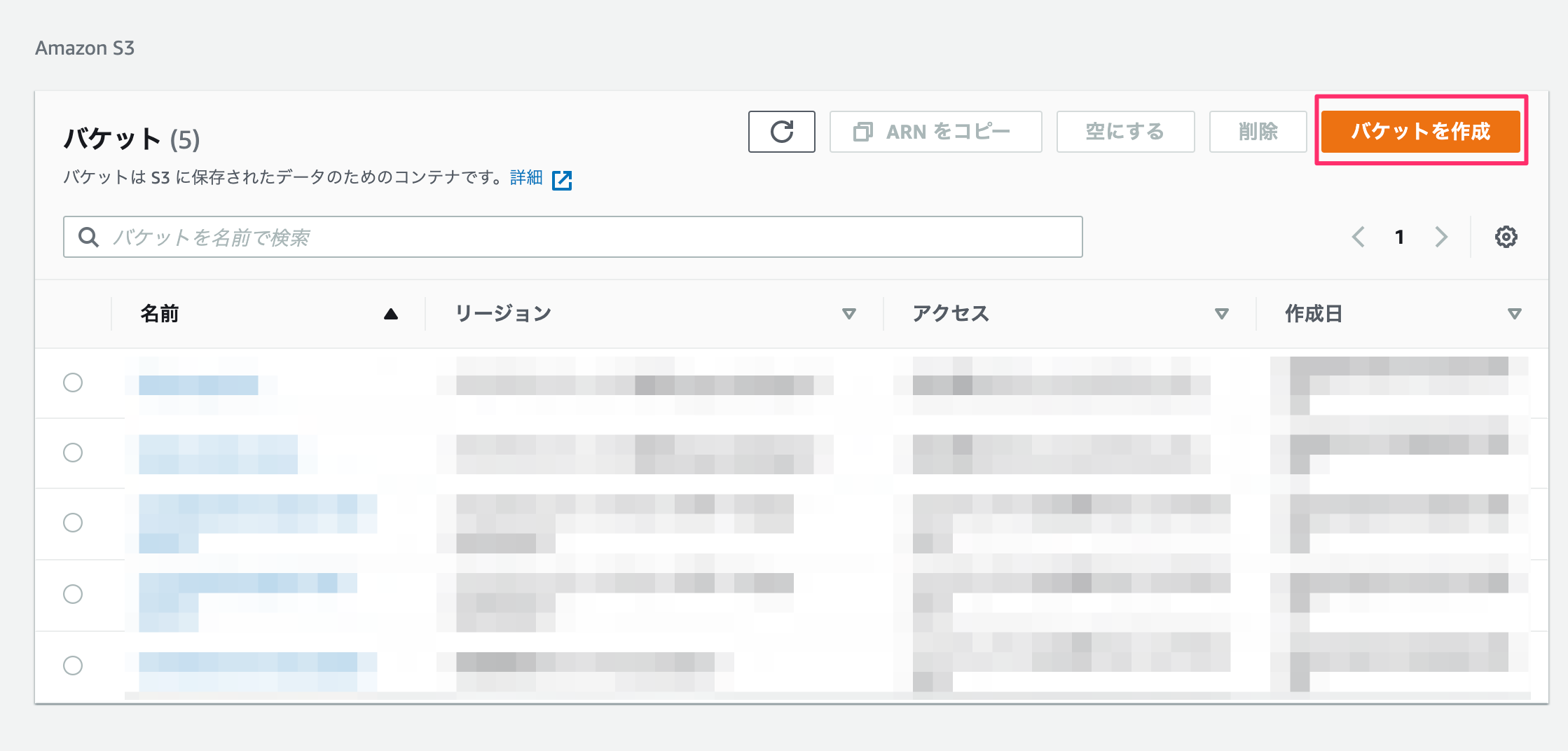
バケット名のみ入力して、その他の設定はデフォルトのままにします。(リージョンは適宜選択する。)
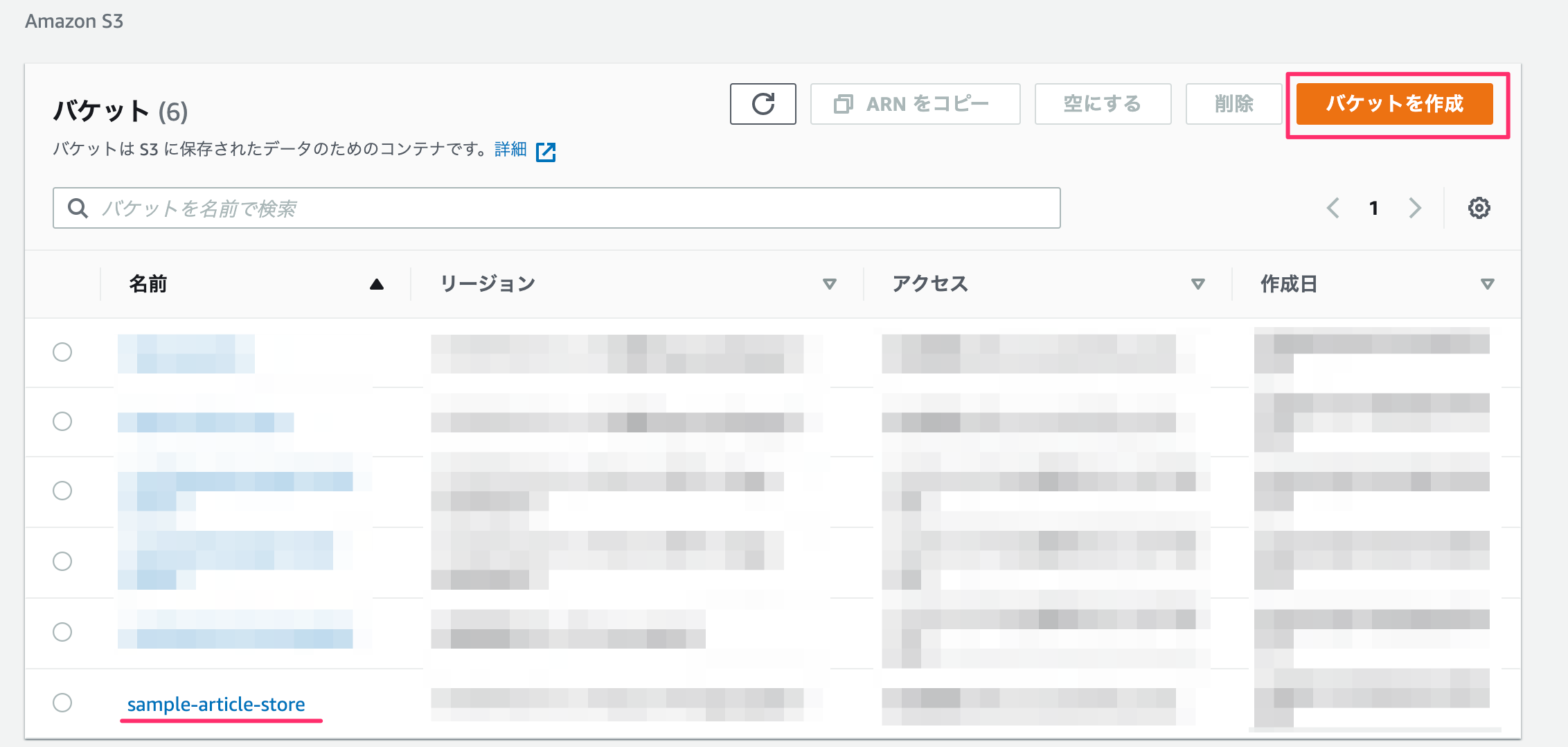
バケットの作成は完了。
Lambda
データ処理用のlambdaを作成します。
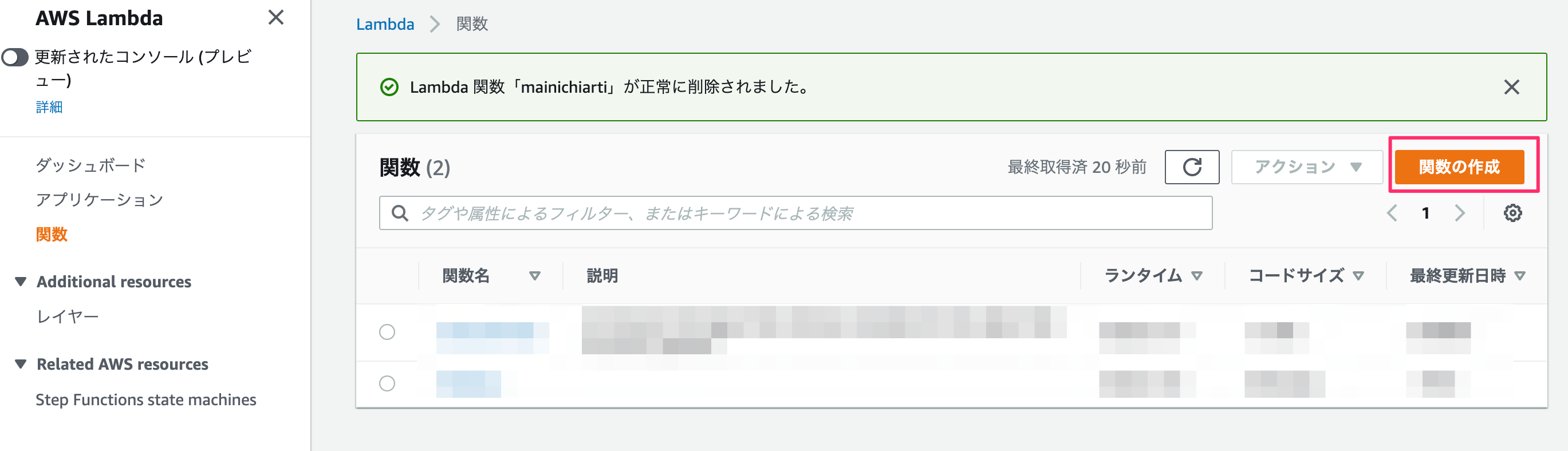
一から作成、、、ではなく、
ここでは「設計図の使用」のなかの「s3-get-object-python」を使います。
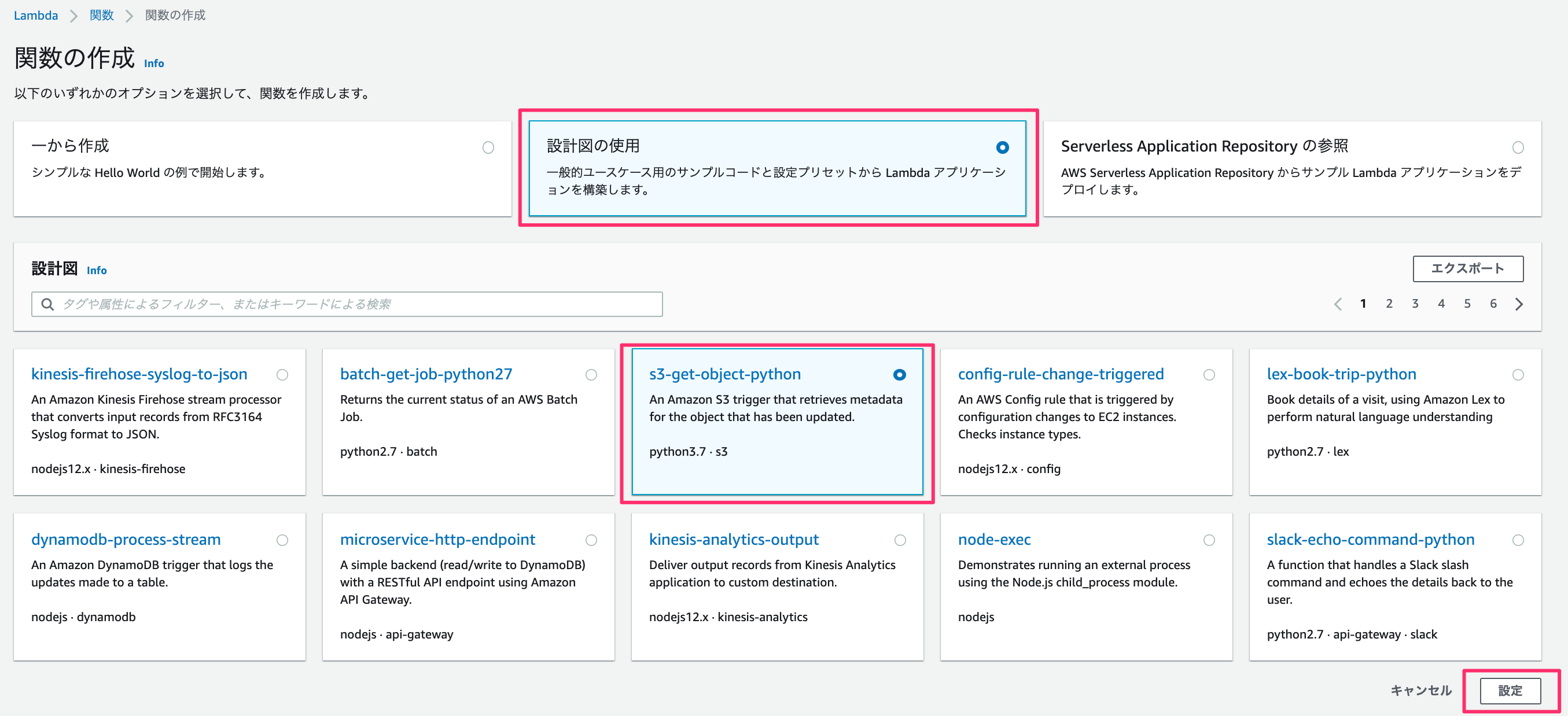
関数名・ロール名を入力。
今回はS3にファイルをuploadするので「読み取り専用のアクセス」のポリシーテンプレートを削除します。
S3トリガーですが、バケット名には先ほど作成したバケットを入力します。
あとは、プレフィックス - オプションには任意の文字を入力してください。
ここで言っている任意の文字とは、lambdaにてファイルを作成するのですがファイル名の先頭と重複しない文字です。
もし、未入力や重複する文字を入力した場合は lambdaへ無限ループにトリガーを作動させ、多額の料金が発生する![]() ことになるので重要です。
ことになるので重要です。
他の対処法としては、イベントタイプをコピーのみにするなどの制限を加えるのもいいと思います。
全ての入力が終わったあとは、「関数の作成」を押します。
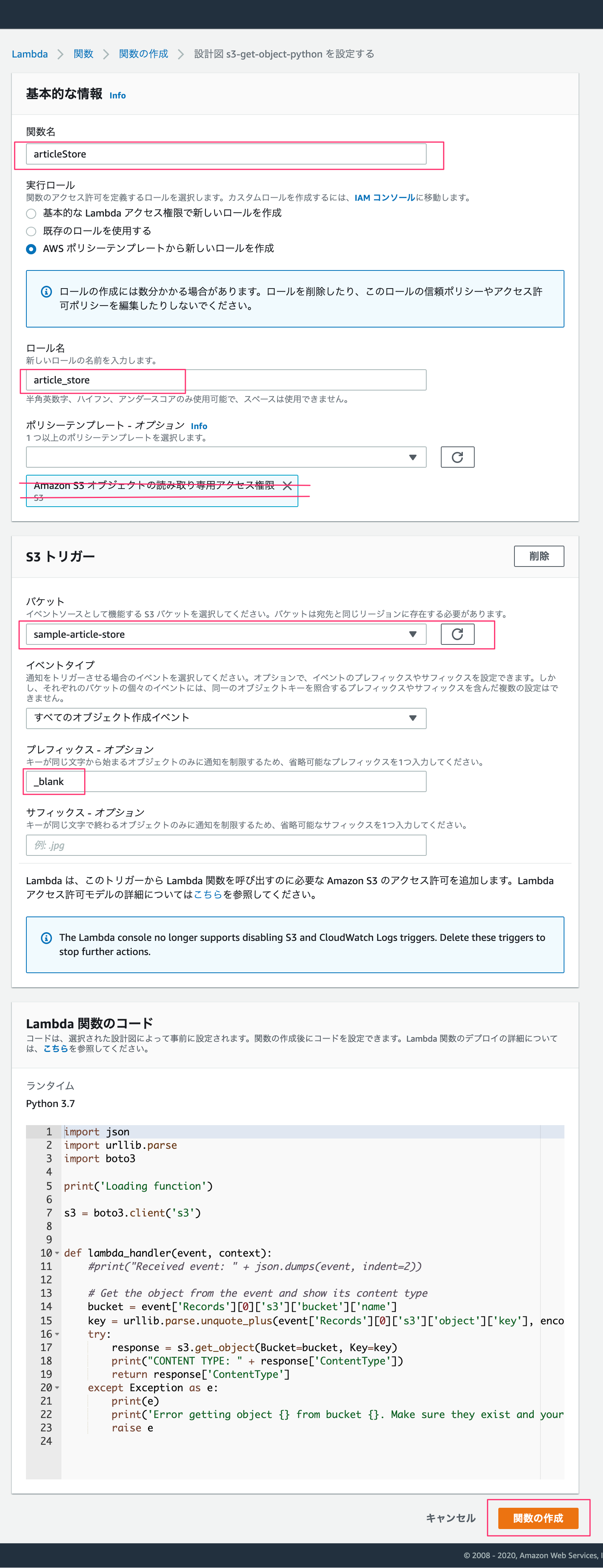
テンプレートが作成されますが、このまま開発を進めてデプロイ、テストしても権限エラーが発生します。
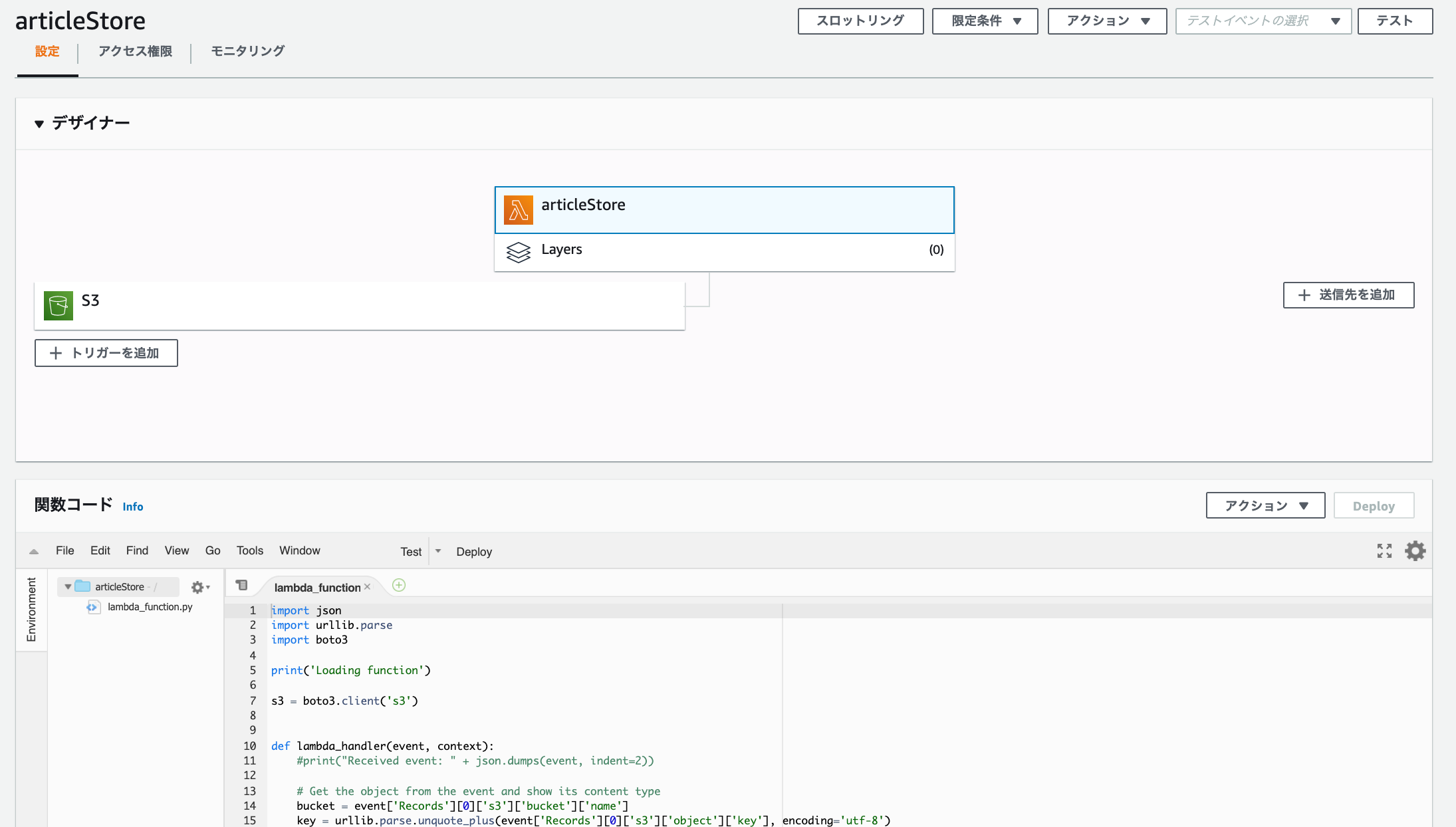
S3の設定
まずS3を有効化させます。
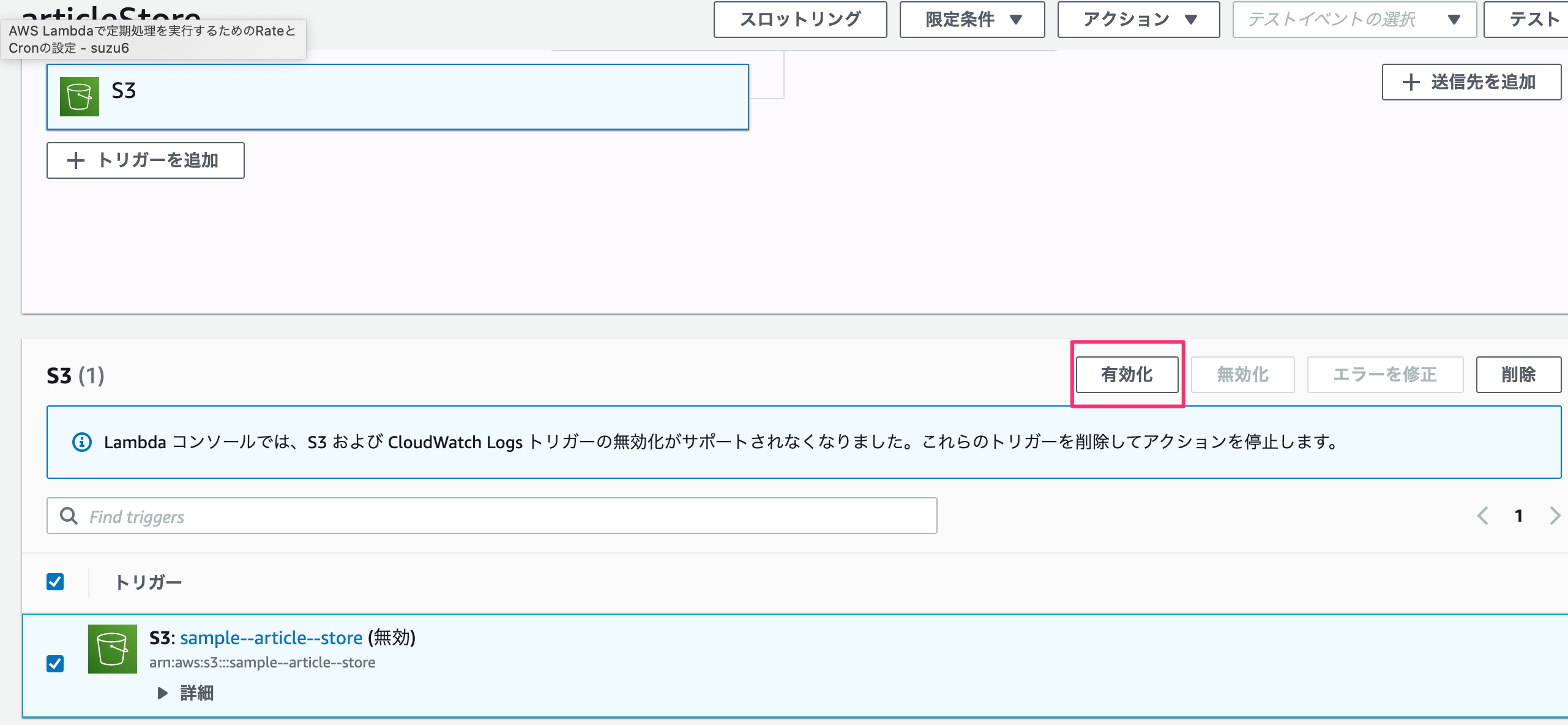
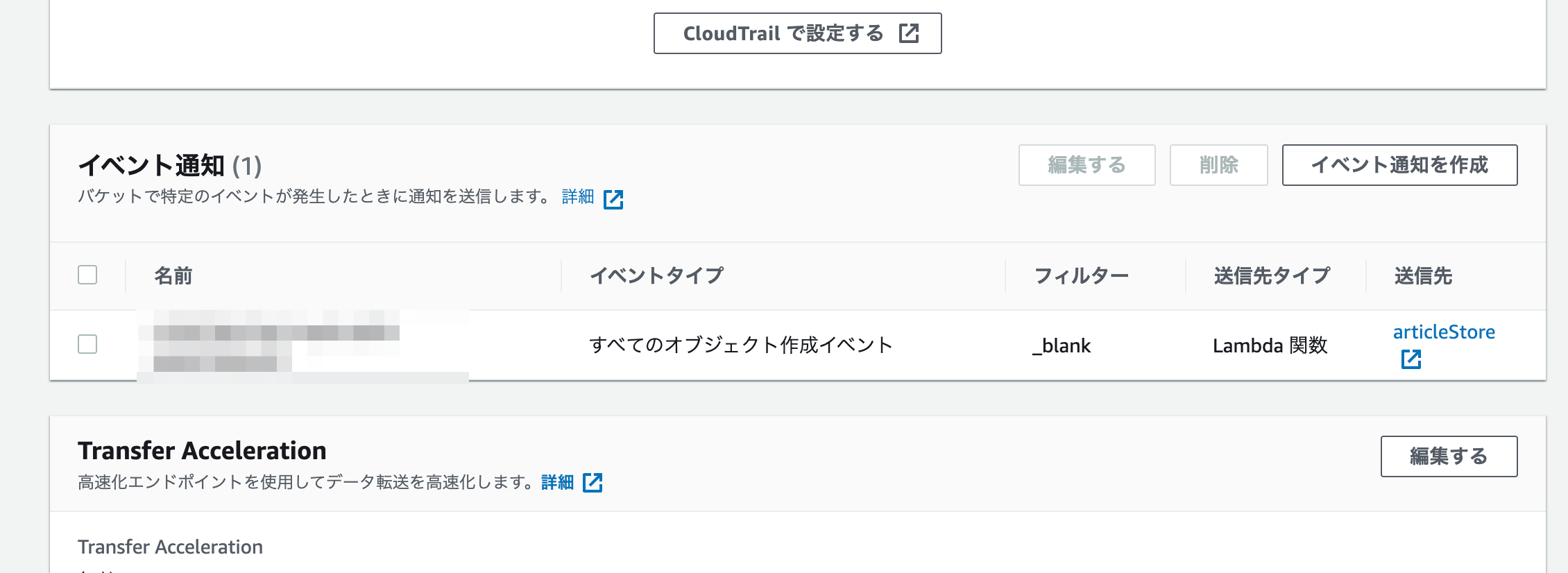
S3でバケットのプロパティ内にあるイベント通知を見ると追加されているのが分かります。
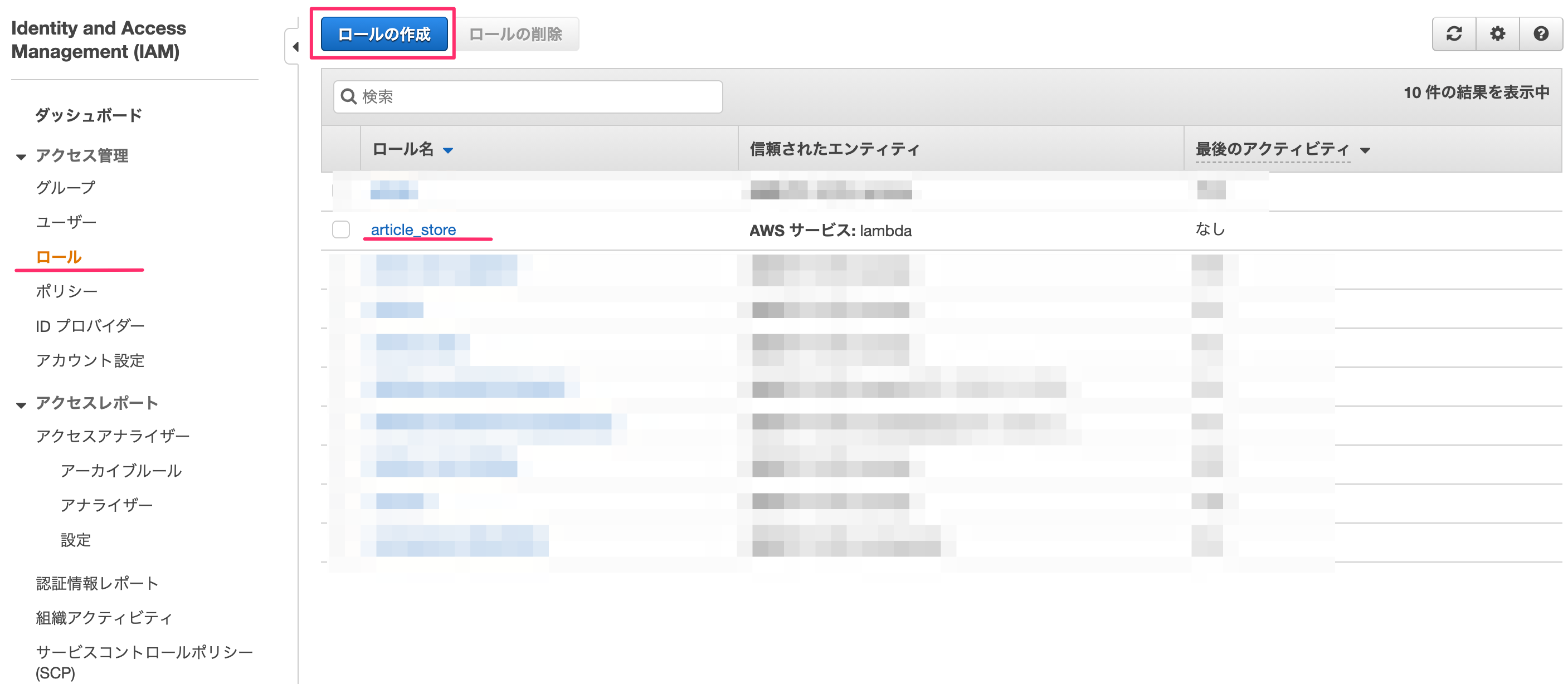
ロールに権限の追加
IAM→ロールを選ぶとロールリストが表示されます。ここで先ほどlambda作成時に記載したロール名を選択します。
何も考えずに「ポリシーをアタッチします」を押す。

"LambdaFull"でフィルタをかけ、「AWSLambdaFullAccess」を選んで「ポリシーのアタッチ」を押します。
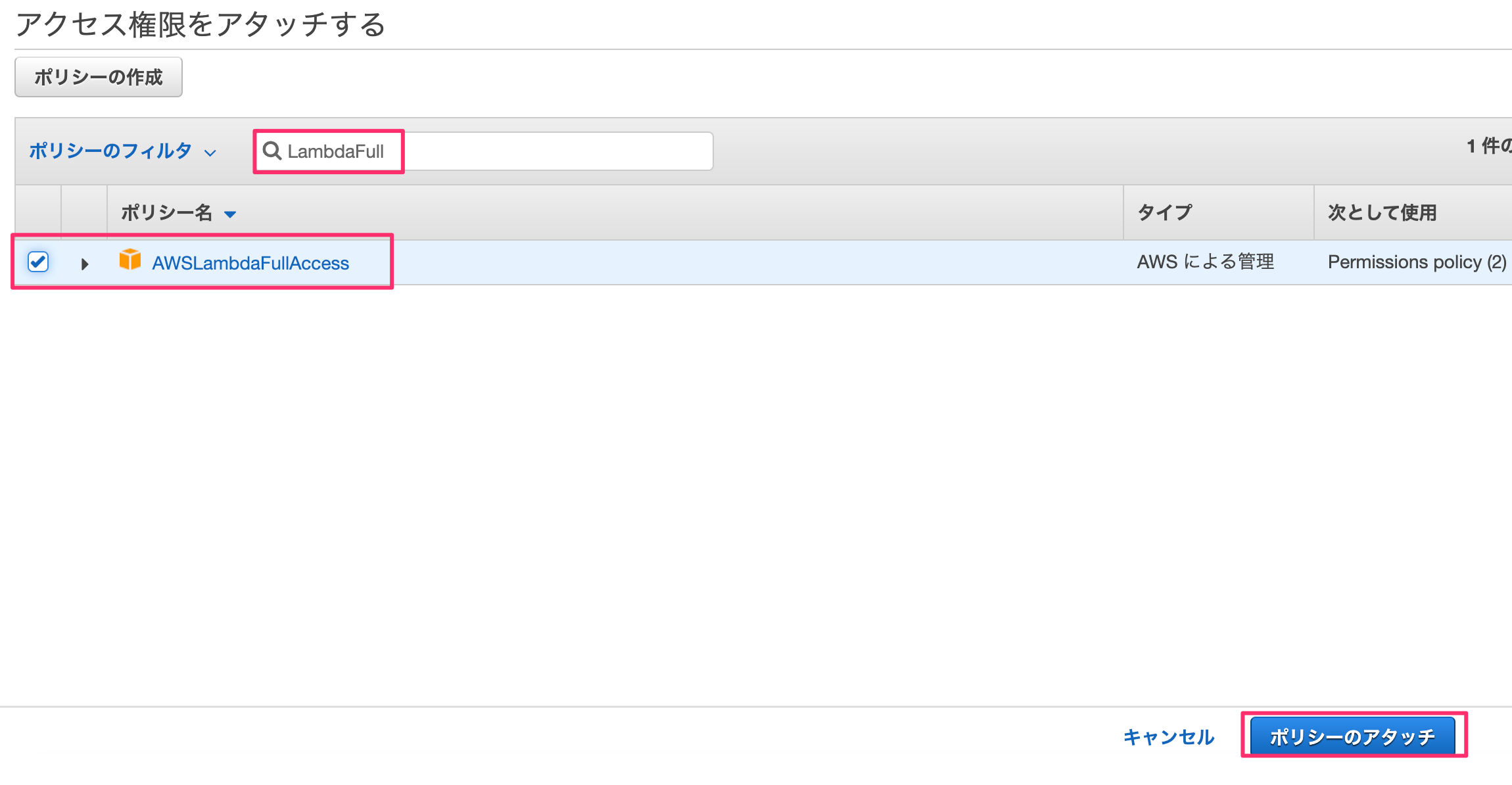
これで権限の追加が完了しました。
基本設定
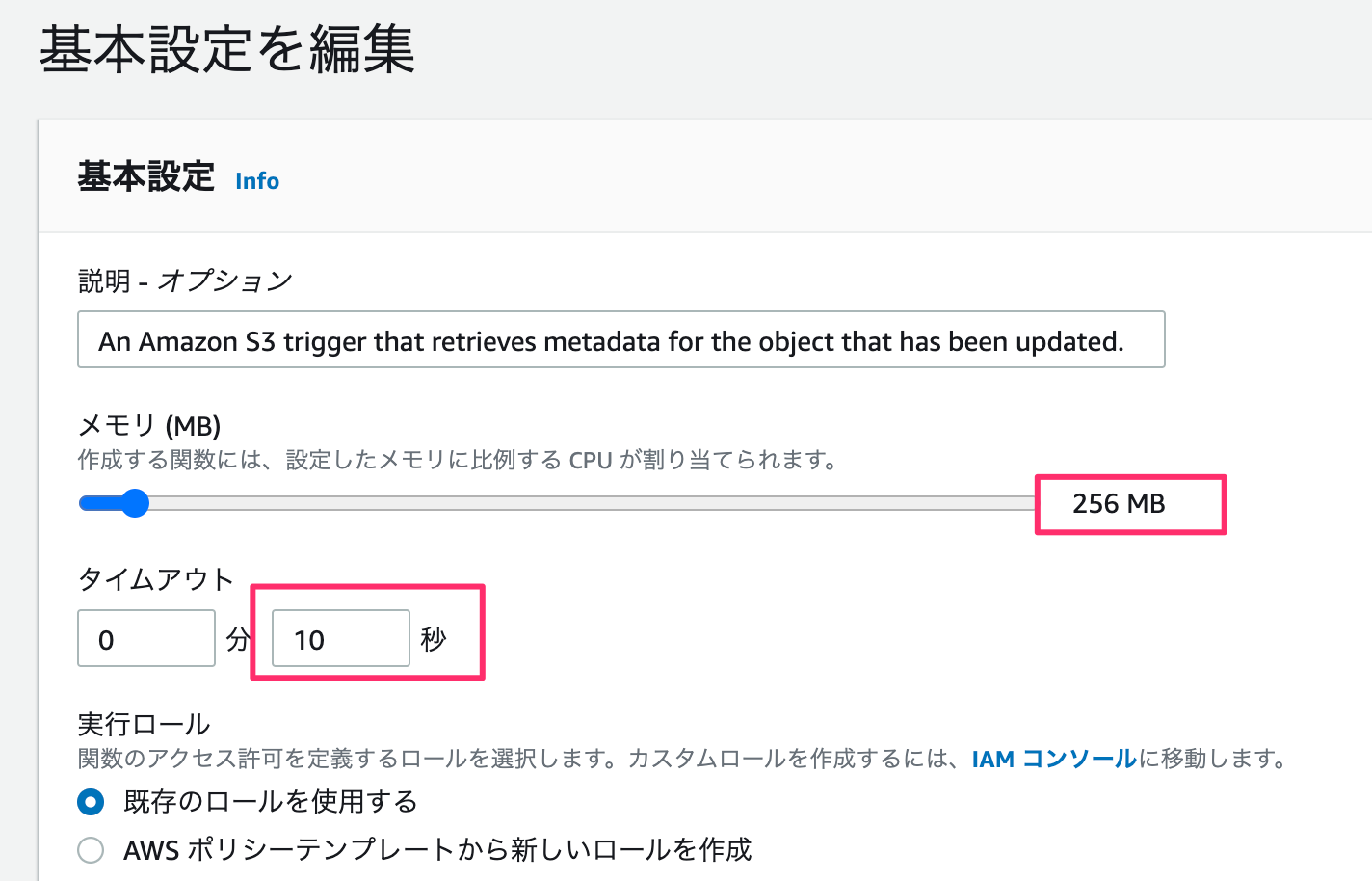
メモリが小さいと処理落ちしました。
てことでメモリ:256MB、タイムアウトを10秒にセットします。
これで完了。
Development (ファイル送信)
S3バケットの送受信にはboto3パッケージを使います。 lambda作成時にs3-get-object-pythonを選ぶと付属でついてきます。最初からパッケージをuploadするとbote3自体の容量が大きく10MB以上になるので既存のものを使った方が良さげです。
import json
import urllib.parse
import boto3
import datetime
def lambda_handler(event, context):
try:
# Get the object from the event and show its content type
s3 = boto3.resource('s3')
bucket = '[バケット名]'
key = 'test_{}.txt'.format(datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S'))
file_contents = 'Lambda test'
obj = s3.Object(bucket,key)
obj.put( Body=file_contents )
except Exception as e:
print(e)
raise e
あとはデプロイして、テストするとバケットにファイルがuploadされます。
あと、テストイベントの設定ですが空のjsonでも起動します。
Development (Webスクレイピング)
スクレイピングするには、requests beautifulsoupがいるのですがpipでインストールしているパッケージをlambdaにuploadする必要があります。
方法はフォルダにpipでパッケージをインストールし、zipでフォルダを圧縮化します。
ここで実行ファイルを作成し、lambdaで書いたコードをコピーします。
mkdir packages
cd packages
pip install requests -t ./
pip install beautifulsoup -t ./
touch lambda_function.py


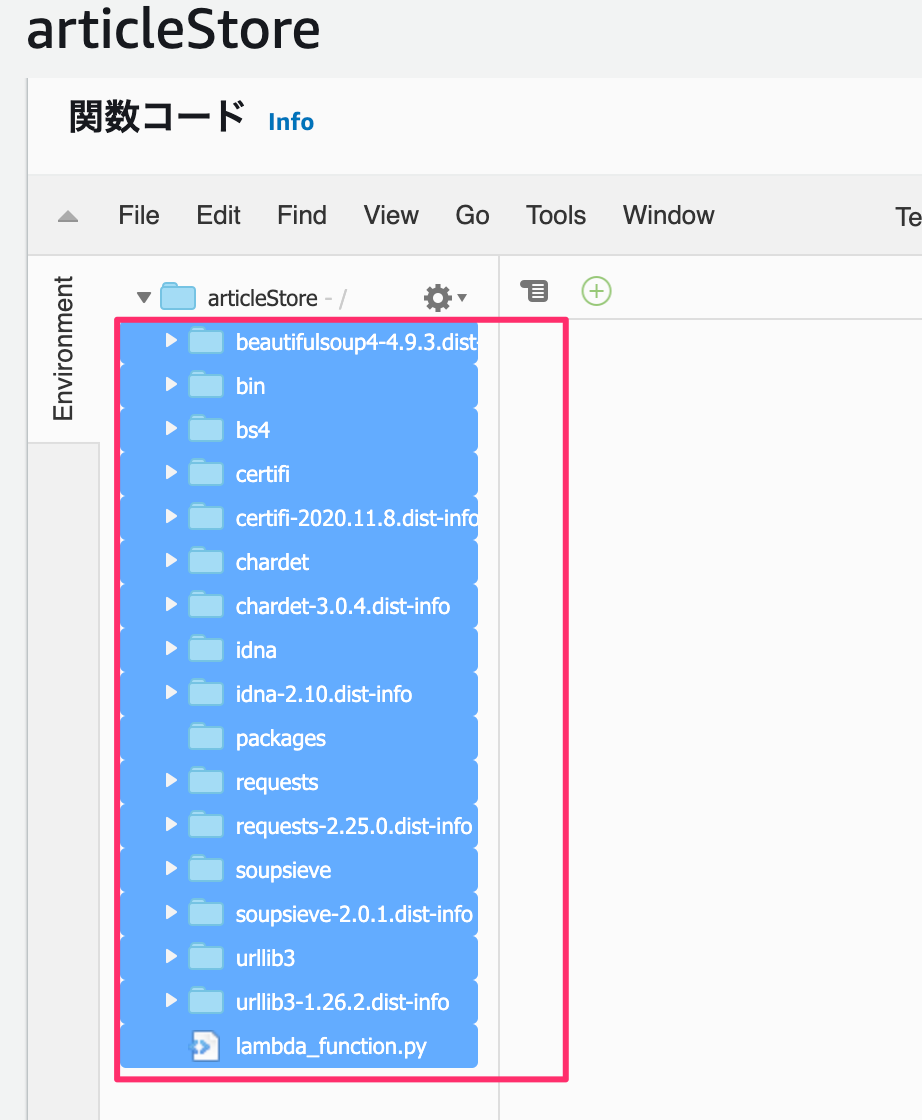
プロジェクト内にパッケージが置かれます。
で、packages配下のフォルダ・ファイルをひとつ上の階層のarticleStoreに移動させます。
その後で、デプロイしてテストするとS3にファイルが追加されます。
あとは、webスクレイピングするだけです。
ここでは今日付の毎日新聞の社説を取得してみます。
import json
import urllib.parse
import boto3
import datetime
from datetime import timedelta, timezone
import random
import os
import requests
from bs4 import BeautifulSoup
print('Loading function')
s3 = boto3.resource('s3')
def lambda_handler(event, context):
# Get the object from the event and show its content type
JST = timezone(timedelta(hours=+9), 'JST')
dt_now = datetime.datetime.now(JST)
date_str = dt_now.strftime('%Y年%m月%d日')
response = requests.get('https://mainichi.jp/editorial/')
soup = BeautifulSoup(response.text)
pages = soup.find("ul", class_="list-typeD")
articles = pages.find_all("article")
links = [ "https:" + a.a.get("href") for a in articles if date_str in a.time.text ]
for i, link in enumerate(links):
bucket_name = "[バケット名]"
folder_path = "/tmp/"
filename = 'article_{0}_{1}.txt'.format(dt_now.strftime('%Y-%m-%d'), i + 1)
try:
bucket = s3.Bucket(bucket_name)
with open(folder_path + filename, 'w') as fout:
fout.write(extract_article(link))
bucket.upload_file(folder_path + filename, filename)
os.remove(folder_path + filename)
except Exception as e:
print(e)
raise e
return {
"date" : dt_now.strftime('%Y-%m-%d %H:%M:%S')
}
# 社説を抽出
def extract_article(src):
response = requests.get(src)
soup = BeautifulSoup(response.text)
text_area = soup.find(class_="main-text")
title = soup.h1.text.strip()
sentence = "".join([txt.text.strip() for txt in text_area.find_all(class_="txt")])
return title + "\n" + sentence
これで、「デプロイ」→「テスト」でS3バケットに抽出した記事が書かれた2つのテキストファイルが追加されます。
とても、長くなりましたがLambdaの設定は完了です。
Amazon EventBridge
処理はできたのですが、毎朝「テスト」ボタンを押すのはマジだるです。
そのため、Amazon EventBridgeを使って定期実行を設定します。
Amazon EventBridge → イベント → ルール を選んで、
「ルールの作成」を押します。
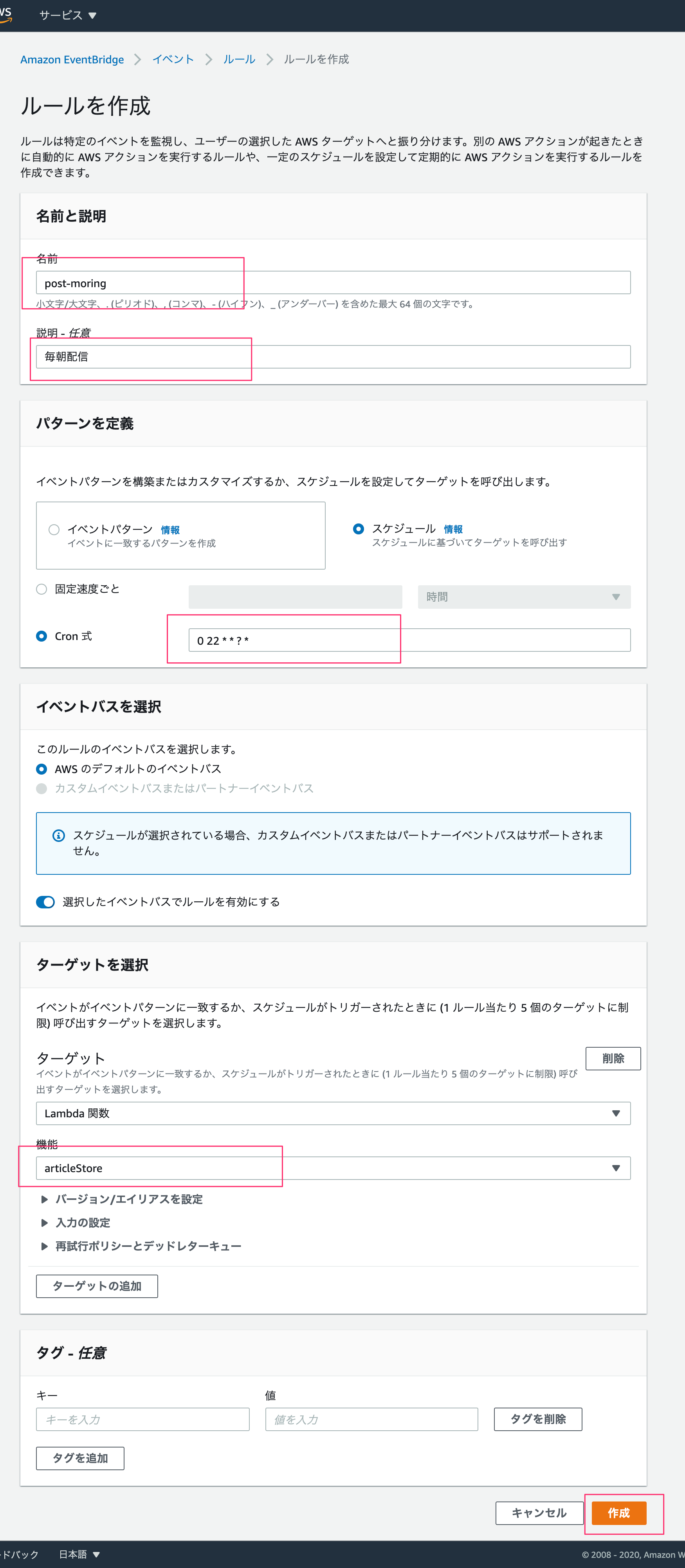
ルール名・説明を書き、cron式は標準時間で実行されるので0 22 * * ? *として日本時間午前7時に実行するようにします。
ターゲットで対象のlambda名を選び、作成します。
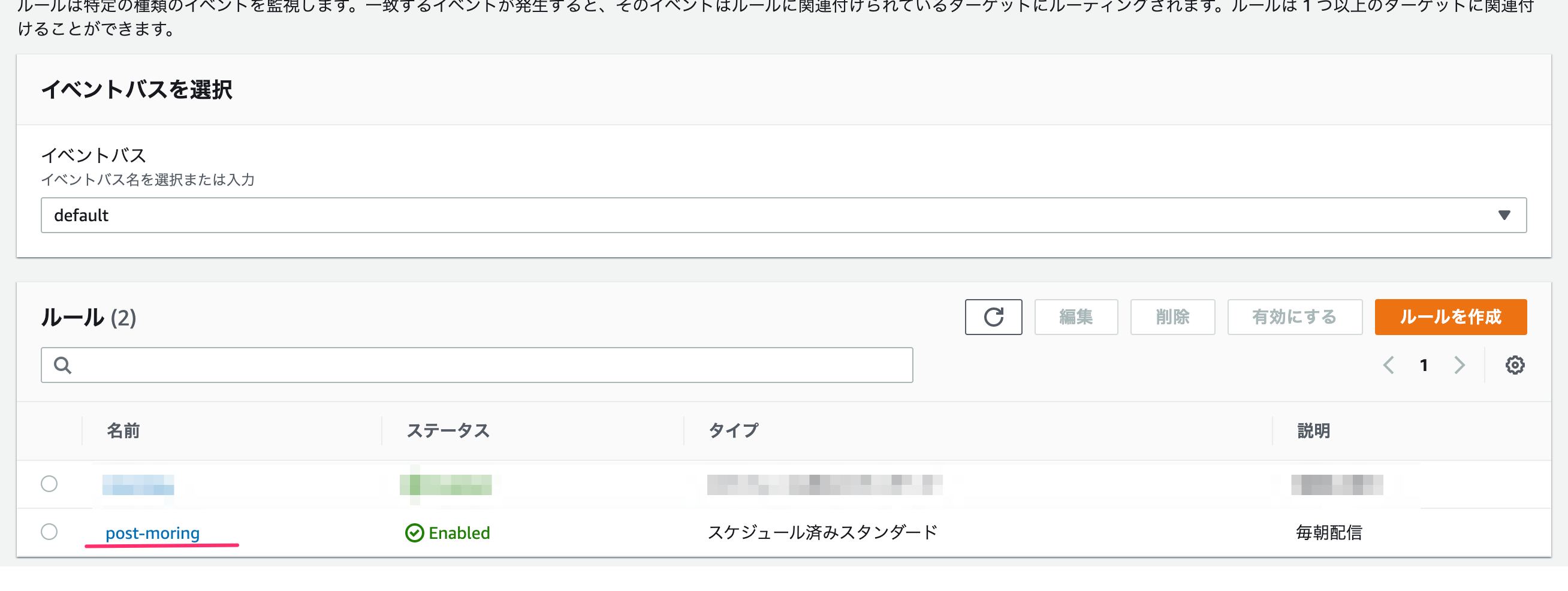
これで完了。
Post-Scripting
この後の予定として、いくつかの新聞社の社説を1年分ストックして機械学習してみようと思っています。
requestsで全てのページを取得できる場合はいいのですが、ページロード時にさらにロードして一覧表示しているサイト(例えば、朝日新聞)がある場合は seleniumでブラウザをコントロールする必要があります。