Background
普段はテレビを見ていないのですが、ジュキヤの動画をうっすらと見た後にたまたまオススメ動画で出てきた月曜から夜ふかしのとあるコーナーを見て、![]()
![]() となりました。
となりました。
これは![]() になるんじゃね?
になるんじゃね?![]()
そのコーナーとはフェフ姉さんがニュースを読み上げる滑舌の悪さを直す企画で、苦手とする発音がてんこ盛りの原稿を読んでいくものっす。で、よくよく聞いてみるとさ行の言葉がは行の言葉になっていないかと気付きました。(テレビに登場した頃から「フェス」を「フェフ」と言っちゃっている。)そこで、新聞記事などを読ませてフェフ姉さんの滑舌の悪い読み方になるかpythonと自然言語処理で使われているモジュールを使って再現をしてみました。
多分、これはオモロイ![]()
Hypothesis
文章をローマ字に変換して、さ行の文字をは行の文字(s -> h)にするとわりとフェフ姉言葉になる説
Method
- MeCabを使って文章を形態素分析して最小単位の単語に分割
- 日本語をローマ字に変換
- さ行(sa,shi,su,se,so)の文字があった場合は、は行(ha,hi,hu,he,ho)の文字に変換する
- ローマ字をカタカナに変換
- 文字をもう一度連結して文章にする
- Done!!!

Development
package
| name | explain | url |
|---|---|---|
| MeCab | 形態素解析システム | https://pypi.org/project/mecab-python3/ |
| pykakasi | 日本語をローマ字にするモジュール | https://github.com/miurahr/pykakasi |
| romkan | ローマ字をひらがな・カタカナにするモジュール | https://pypi.org/project/romkan/ |
| gtts | 文章を音声に変換するモジュール(powered by Google) | https://pypi.org/project/gTTS/ |
で、インストールは単純に
pip3 install MeCab pykakasi romkan gtts
でOK。
code
import MeCab
import pykakasi
import romkan
import re
from gtts import gTTS
# 日本語からローマ字に変換
def j2roma(src):
kakasi = pykakasi.kakasi()
kakasi.setMode('H', 'a')
kakasi.setMode('K', 'a')
kakasi.setMode('J', 'a')
conv = kakasi.getConverter()
#"つ"はさ行を変換しやすいようにtsu -> tuに変換
return conv.do(src).replace("tsu","tu")
# ローマ字から日本語に変換
def roma2j(src):
return romkan.to_katakana(src)
# フェフ姉言葉に変換 さ行 -> は行
def s2h(src):
dst = src.replace("sa","ha")
dst = dst.replace("shi","hi")
dst = dst.replace("su","hu")
dst = dst.replace("se","he")
dst = dst.replace("so","ho")
return dst , src != dst
# 文章を音声に変換
def makebot(src, filename="output.mp3"):
tts = gTTS(text=src, lang='ja')
tts.save(filename)
def main():
sentence_list = None
with open("sentence.txt", "r") as fin:
sentence_list = fin.readlines()
compose_sentence = ""
for s in sentence_list:
#形態素分析
mecab = MeCab.Tagger()
words = mecab.parse(s).split("\n")
for w in words:
if -1 < w.find("\t"):
tab_index = w.index("\t")
hinshi = w[tab_index+1:].split(",")[0]
#助詞と記号はスルー
if hinshi in ["助詞", "助動詞", "記号"]:
compose_sentence += w[:tab_index] + "\n"
else :
#それ以外は変換対象(名詞、形容詞、etc)
result, is_diff = s2h(j2roma(w[:tab_index]))
if is_diff :
compose_sentence += roma2j(result) + "\n"
else :
compose_sentence += w[:tab_index] + "\n"
#文章を音声に変換
makebot(compose_sentence.replace("\n",""), "convert.mp3")
# 変換なしでmp3化
def raw():
sentence_list = None
with open("sentence.txt", "r") as fin:
sentence_list = fin.readlines()
compose_sentence = "".join(sentence_list)
makebot(compose_sentence, "raw.mp3")
if __name__ == "__main__":
raw()
main()
Result
実際に使った文章
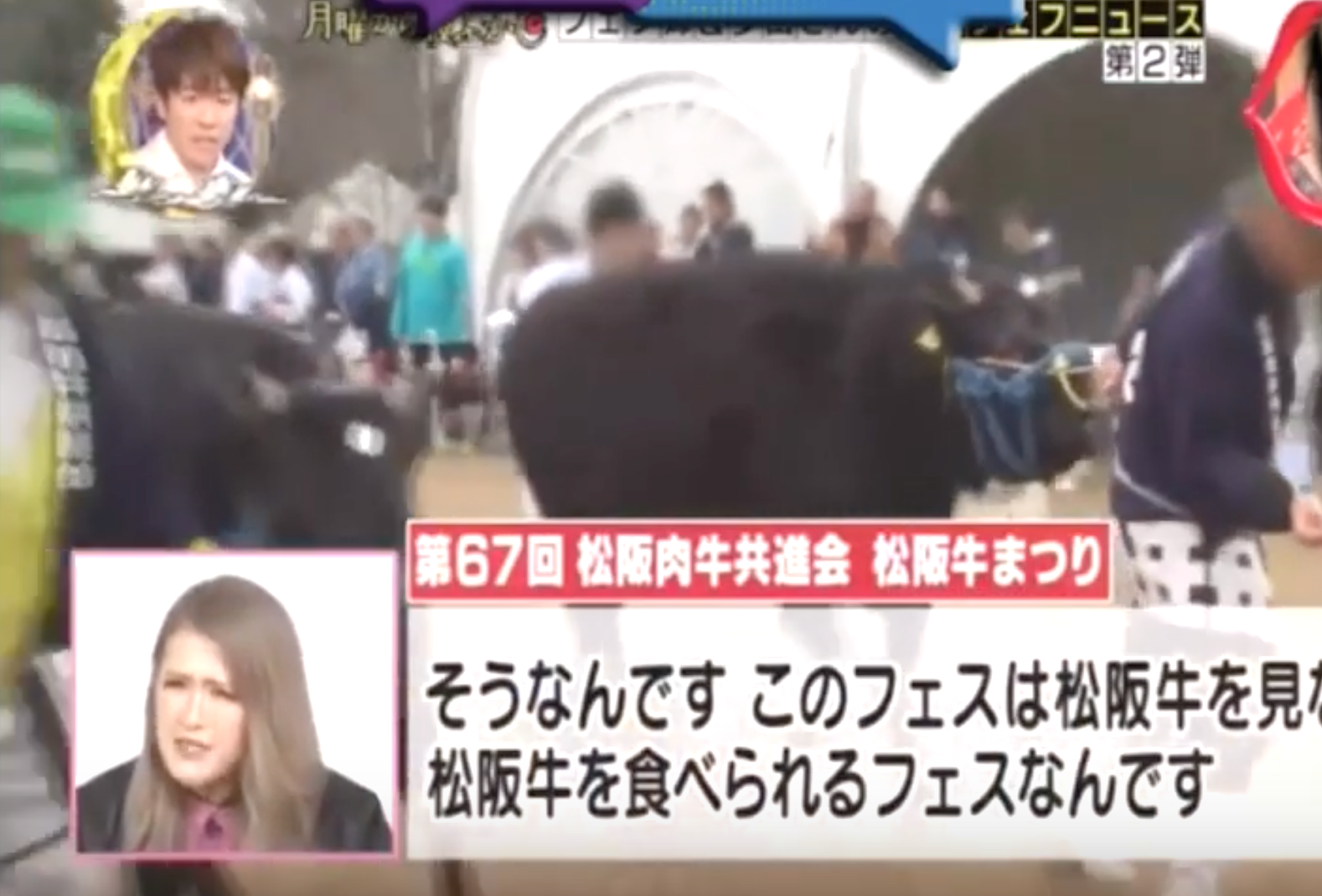
続いてのフェスは三重県からです。
三重県松坂市で松阪牛フェスが開催されました。
近江牛神戸ビーフとともに日本三大和牛に数えられる松阪牛。
中でも松阪牛はきめの細かいサシと上品な香りが特徴。
そんな松阪牛を存分に味わえるのがこのフェス。
そうなんです。このフェスは松阪牛を見ながら松阪牛を食べられるフェスなんです。
ここで行われるのは50頭の松阪牛の品評会。
続いてのフェフは三重県からです。
三重県マツハカヒでマツハカウヒフェフがカイハイハれました。
近江ウヒ神戸ビーフとともに日本ハン大和牛に数えられるマツハカウヒ。
中でもマツハカウヒはきめの細かいハヒと上品な香りが特徴。
ホンアマツハカウヒを存分に味わえるのがこのフェフ。
ホウなんです。このフェフはマツハカウヒを見ながらマツハカウヒを食べられるフェフなんです。
ここで行われるのは50頭のマツハカウヒの品評会。
Consideration
ローマ字を変えただけなのですが、結構再現ができていると思います![]()
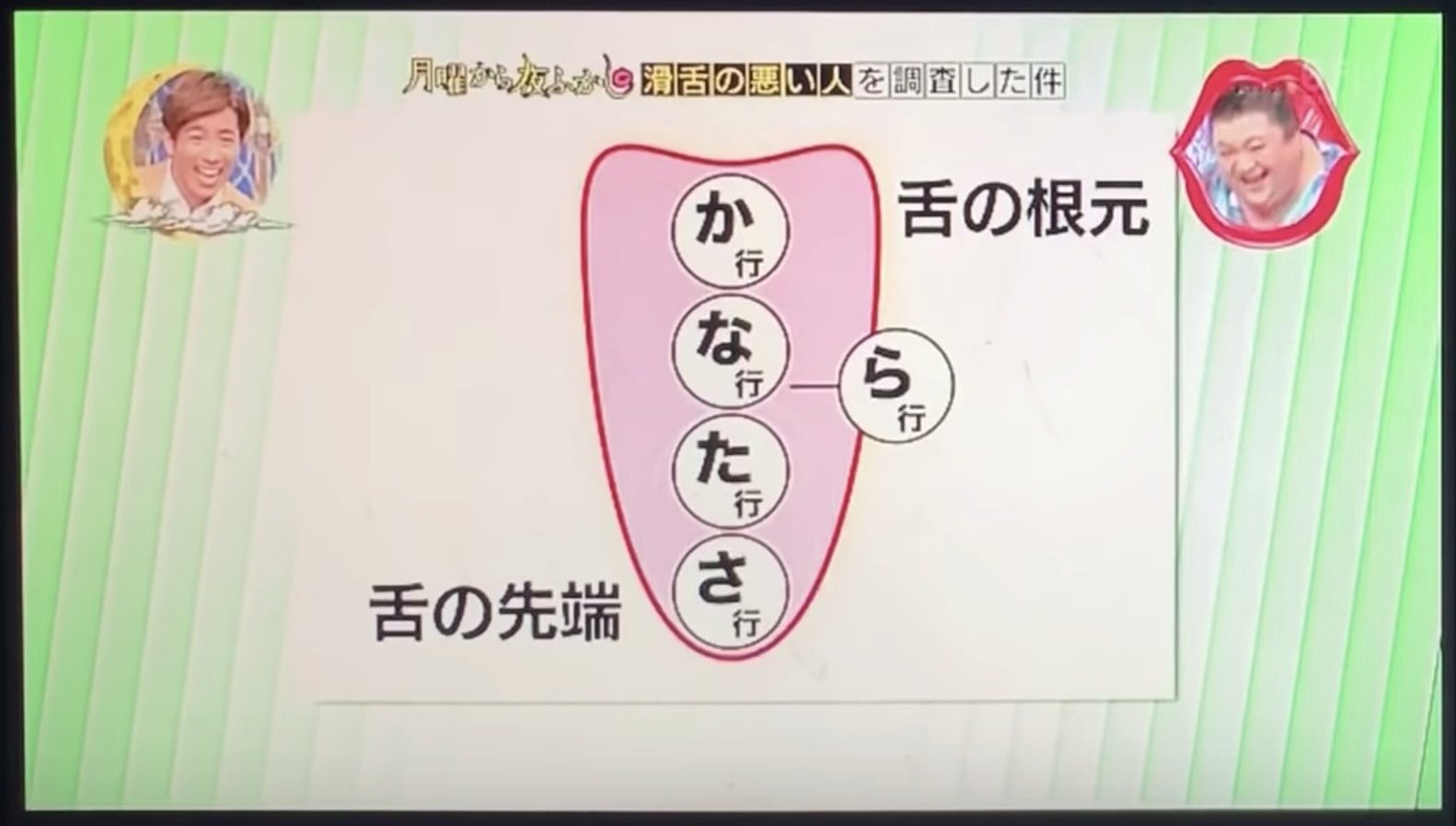
詳細を聞くとフェフ姉さんはさ行の他にか行、た行も言いにくいみたいです。
(イチジク、樹木希林、アスパラガスetc)
で、放送では平均よりも舌の筋肉がないらしくて先端のさ行とた行が言いにくいと説明していました。単なるバラエティかと思えばよく聞いてみると地味にscienceにして説明しています。今回データとして使った上記の文章ですがフェフ姉さんが突っ掛かりそうな部分を含めつつ作成しているのでかなり良くできています。NTVのスタッフ恐るべし![]() 。
。
Future
-
今回はさ行の文字からは行の文字へ変換するだけだったのですが、残りの苦手とする「か行」と「た行」はローマ字変換のみで再現しようとした場合はどのように変換するかまだ思いついていないです。上記の方法は子音のみですが、母音と子音のセットじゃないとキツイかもしれません。これはyoutubeでFEFNewsを通しで見てある一定の法則を推測するしかないかなと思っています。
-
もしかすると方言もローマ字変換のみで再現できるかもしれないです。本格的に着手するとなると音の波長を読み書きしつつ方言特有の抑揚もつけつつと特殊技能を持った音声認識のエキスパートじゃないと厳しいはずです。今回は法則性が見つかれば文字変換だけなので簡単にできると思います。
-
そもそも滑舌が悪い話は医学的な話です。よし!ヨミドクター に相談だ!
-
そういえばフランス語はhは発音しないし、ドイツ語はpHをペーハー(英語ではピーエイチ)と読むから
e -> iと読み上げたら日本語なのにエセ外国語読みになりそう。 文章の内容を変換している点では異なりますが我偽中国語翻訳機作成了 と考え方は近い、はずです。
Editor's Note
日曜からよふかしして書いてしまった。思いついてもMethod(方法)へ持っていくまでのbackground(背景)の説明書きが一番面倒です。
それにしても、多田さんのツッコミがナチュラル過ぎて新人の芸人では太刀打ちできないくらいの切れ味があります![]() 。これもネタになるんすかね
。これもネタになるんすかね![]()
Reference
Technology
- [Python] (https://www.python.org/)
- [MeCab] (https://taku910.github.io/mecab/)
- pykakasi
TV Program
Relation
- [我偽中国語翻訳機作成了] (https://qiita.com/shoichiro-k/items/5d28be844f664100387b)
- [我为中国人创作了翻译。] (https://qiita.com/kg1/items/cc8b2daa2ba8499fb9cb)