はじめに
ニューラルネットのブーム再燃 → Googleインターン生によるAttention機構の発明 → OpenAI社のChatGPT-4登場による衝撃 → LLMブーム → DeepSeekを筆頭としたOSS系LLMの台頭 → ...... という激動の1年間を経て、大規模言語モデル(LLM)の技術分野はほぼ確立されました。現在、世界中で取り組まれているのは「軽量化」と「高性能化」です。
特に、LLMをOSS化する流れと、「量子化(Quantization)」や「蒸留モデル(Distilled Model)」といった技術の進展により、高性能かつ軽量で技術的透明性の高いモデルが無料で公開されています
この流れを受け、OllamaやAnythingLLMといったOSSツールが登場し、個人でも高度な大規模言語モデルをローカル環境に簡単に導入できるようになっています。ローカル環境でLLMを動かすメリットはたくさんありますね。
- 無料で使い放題
- 機密情報を安心して入力可能
- 自分好みにカスタマイズできる
というわけで今回は、M2 Macbook Proを用いて環境を構築しました。OSSツールのみを使用して、具体的にはOllamaとAnythingLLMで以下のような環境を実現しています。
作業時間は半日くらいですが、大部分はモデルのダウンロード(数GB単位)にかかる時間です。ネット環境が高速な場合は、より短時間で完了できると思います。
環境要件
ターミナルで以下のコマンドを実行し、arm64 が出力されればOKです。
% uname -m
arm64 # → ARM (Apple Silicon) なのでOK
ダメな例
% uname -m
x86_64 # → Intel(従来のMac)なのでダメ
筆者は、2022年モデルの M2 MacBook Pro(8コアCPU / 16GBメモリ) を使用しています。ノートPCでLLMが動作するなんてすごい時代ですね。
本編
Ollama のインストール
以下のページからOllamaをダウンロードし、インストールします。
インストール後、チュートリアルに沿ってテストを実行します。最初のチュートリアルでは、Meta社の軽量モデル Llama 3.2 を試すよう案内されるはずです。
ターミナルで以下を実行します。
% ollama run llama3.2
初回実行時には、約3.2GBのモデルがダウンロードされます。その後、プロンプト入力待ちの状態になれば成功です。
% ollama run llama3.2
pulling manifest
pulling dde5aa3fc5ff... 100% ▕██████████████████████████████████████████▏ 2.0 GB
...
success
>>> Send a message (/? for help)
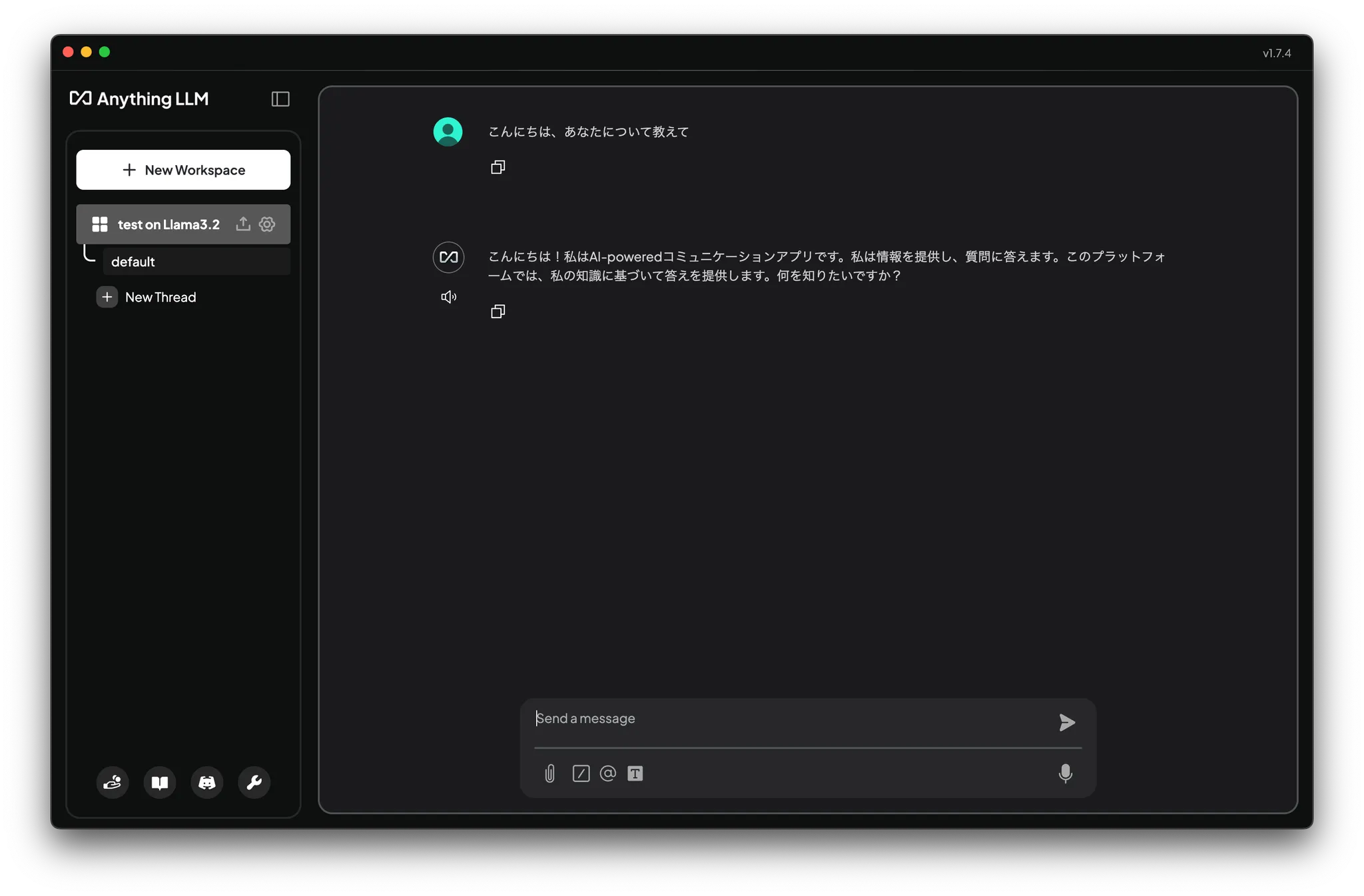
適当な質問(例:「こんにちは、あなたについて教えて」)を入力し、応答が返ってくればOllamaの動作確認は完了です。
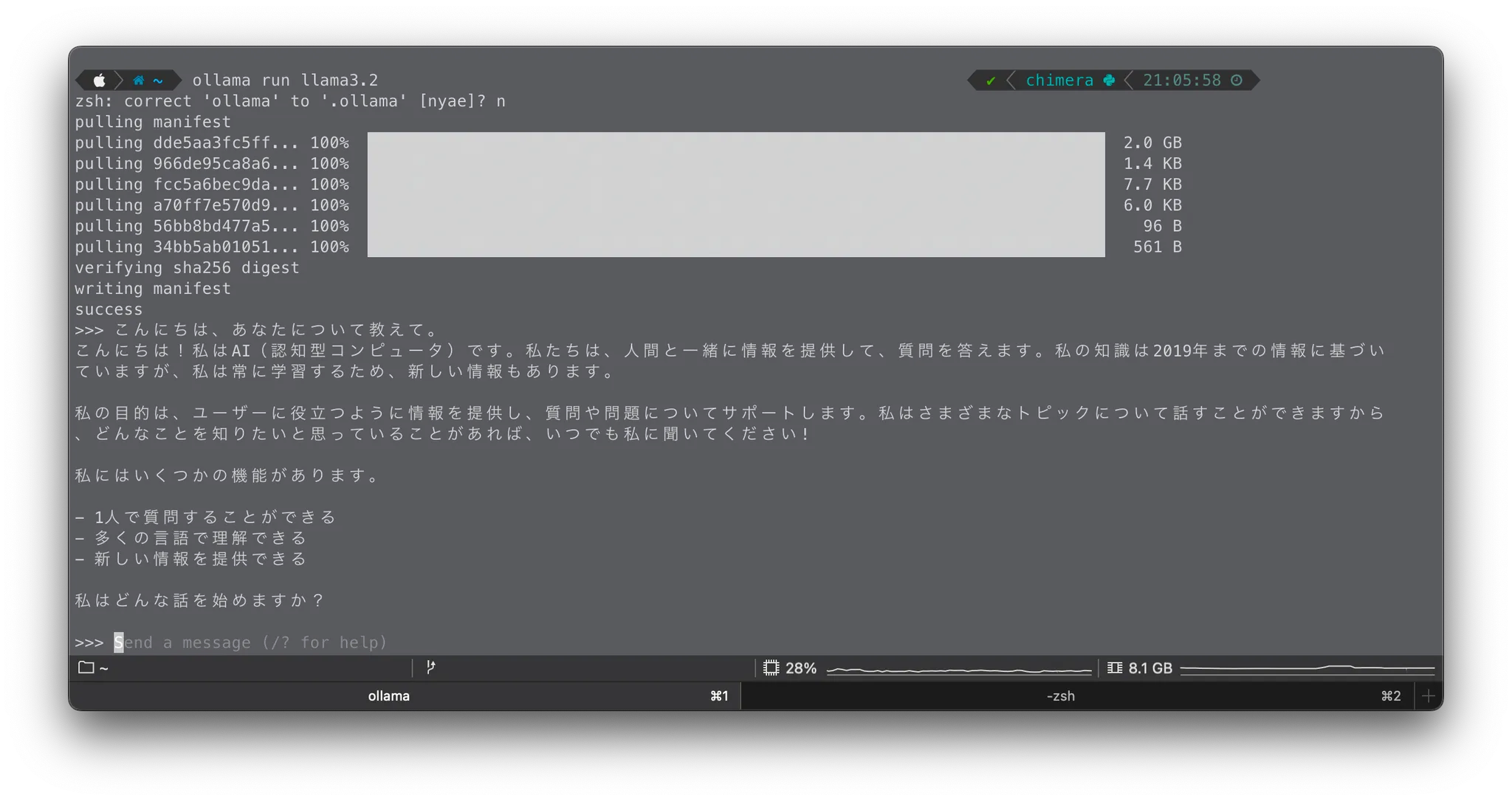
軽量なのでちょっとアホの子ですが、動作はいい感じです。
終了するには Ctrl + D を押すか、/bye と入力します。
AnythingLLM のインストール
以下のページからAnythingLLMのデスクトップアプリをダウンロードし、インストールします。
Apple Silicon版を選択してください。
インストール後、起動するとセットアップ画面が表示されます。「LLM Preference」を設定する画面で Ollama を選びます。
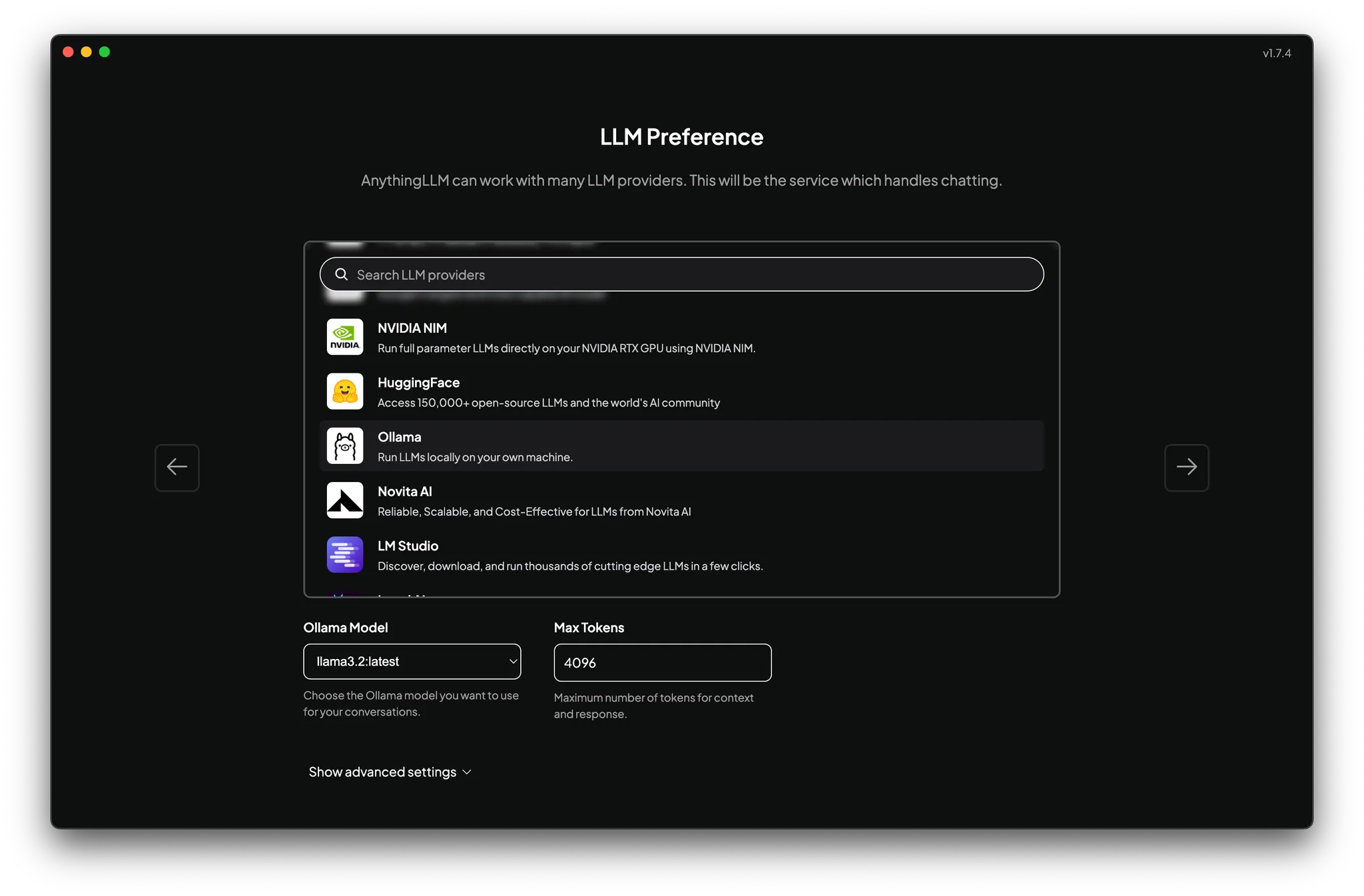
「ローカル環境だから情報はどこにも送信されませんよ〜」だそうです。
さらに進んで、アンケートに答えたり答えなかったりして、ようやくLLM環境の準備が完了です。
Chat GPTライクで馴染みやすいUIですね。
モデルのインストール
Ollamaを使って、どんどんモデルを追加していきましょう。DeepSeek社やMeta社といった有名どころが提供するモデルについては、Ollama公式ライブラリ に掲載されており、比較的簡単に導入可能です。
ここでは、公式ライブラリにはない CyberAgent社が日本語向けにファインチューニングしたモデル の導入方法も紹介します。
LLM には .safetensors や .gguf といった種類があり、Ollamaは .safetensors 形式には直接対応していません (2025年2月現在)。一方で、huggingFace を介したモデル配布で一般的なのは .safetensors 形式となっています。そこで、ここでは有志の方が .gguf 形式に変換してくださったものを引っ張ってくる (pull) ことになります。
本家 DeepSeek モデルの導入
DeepSeek(ディープシーク)は、中国・杭州市に拠点を置くAIスタートアップです。2023年に設立され、オープンソースの大規模言語モデル(LLM)の開発を行っています。2025年1月にリリースされた「DeepSeek-R1」は、約8~9億円という低コストで開発されながら、OpenAIのChatGPTと同等の性能を持つとされています。
本家Deep Seek社が提供するモデルは、Ollama公式サイトにあるため、比較的かんたんに導入できます。
Llama3.2のときと同じ要領で、ターミナルから以下のコマンドを実行すればOKです。
% ollama run deepseek-r1:14b
M2 MacBook Pro(8コアCPU / 16GBメモリ)では、「deepseek-r1:32b(19GB)」は動作が重すぎ (2秒かけて1文字くらい) でしたが、「deepseek-r1:14b(9GB)」ならサクサク動作 しました。
AnythingLLM側の設定を行います。
画面左上の + New Workspace から新しいワークスペース (≒チャットルーム) を作成し、歯車アイコンを押して設定を開きます。
Chat Settings タブから
-
Workspace LLM Providerを Ollama に、 -
Workspace Chat modelを先程インストールした deepseek-r1 に
それぞれ変更します。
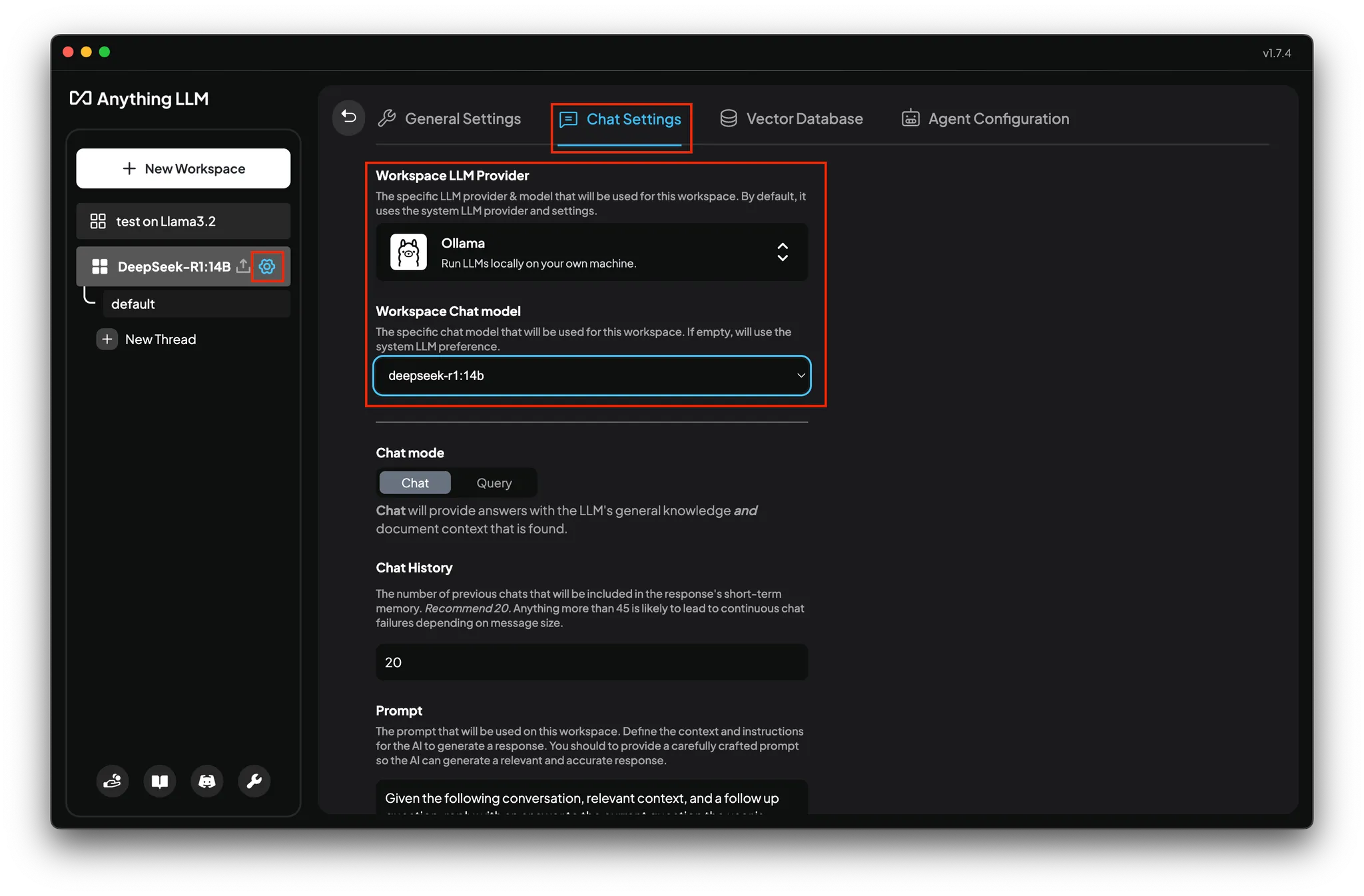
赤枠で囲ったところです。
最後に一番下の Update workspace を忘れず押して (一敗)、
セットアップは完了です。
日本語で「こんにちは、あなたについて教えて」と聞いてみると…
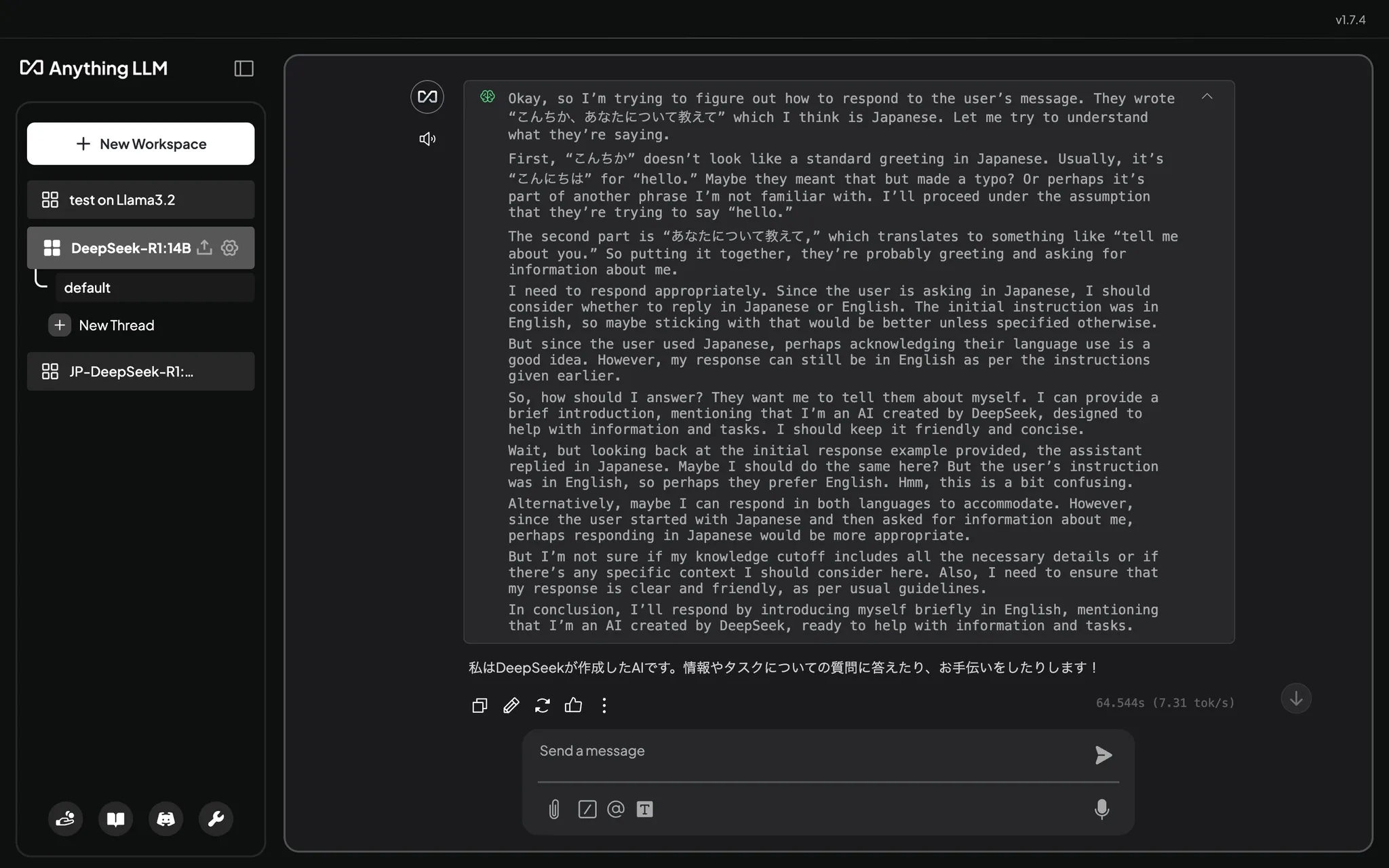
英語で推論しているようです。一行の挨拶の裏側ですごい考えていますね、なんだか親近感が湧いてきます。
ただ、このモデルにはいくつか問題があり、端的に言うと「天安門事件」とか「台湾独立がNvidiaの株価に与える影響」といったことに回答できないと言われています。
やってみましょう。
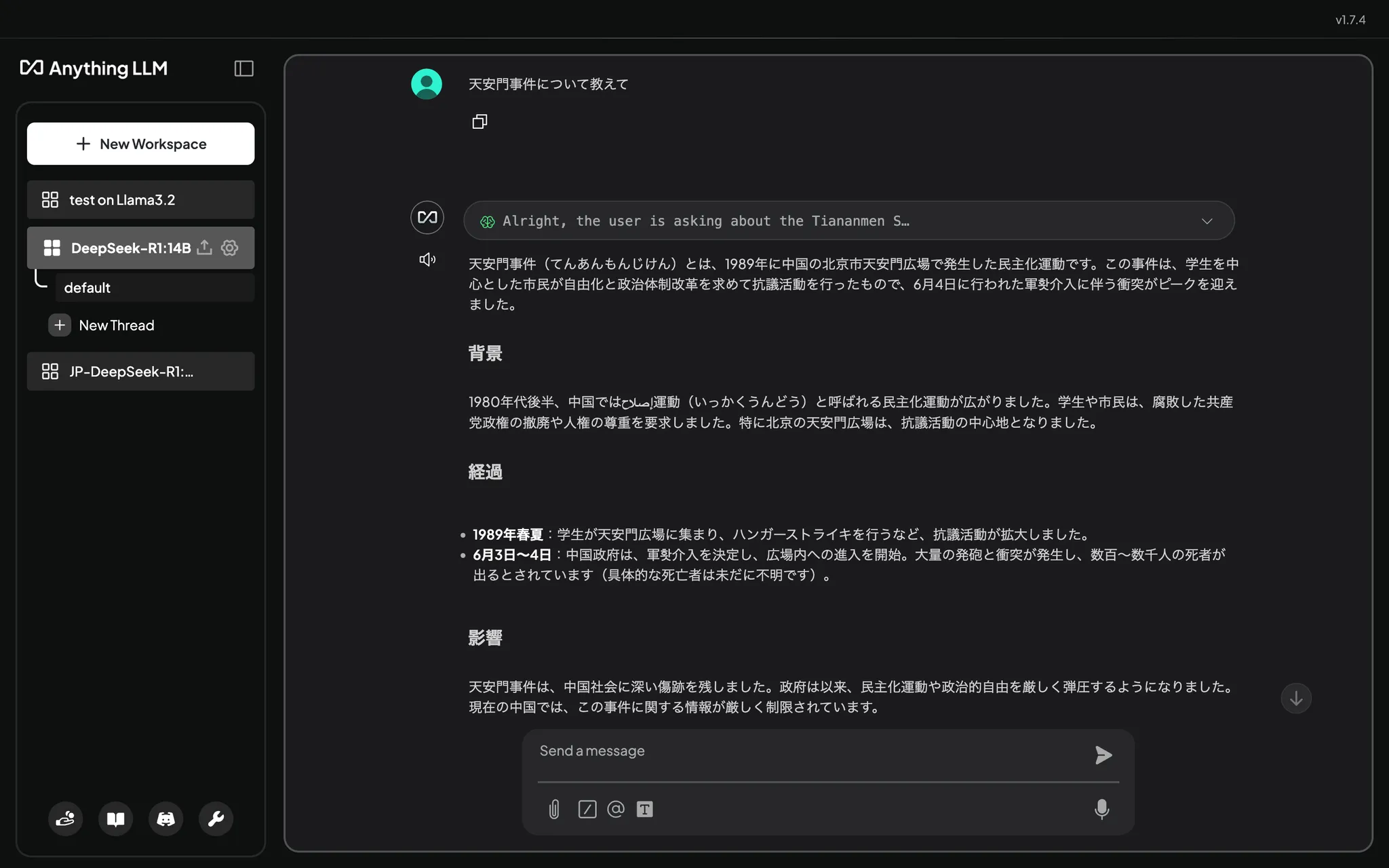
......あれ?普通に答えてくれちゃった。ローカルだから、フィルタリングが甘いんでしょうか。
CyberAgent版 DeepSeek モデルの導入
CyberAgent社がDeepSeek-R1をベースに蒸留+日本語追加学習を施した日本向けのモデルを導入します。
このモデルはOllama公式には掲載されていませんが、有志の方が .gguf 形式に変換してくださったものがあるので、そちらを利用します。
最近のOllamaは run コマンドでhuggingFaceから直接インストールできるようになっています。便利ですね。
% ollama run hf.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf
pulling manifest
pulling daf92c0e1436... 100% ▕███████████████████████████████████████████████████████████████████████████▏ 9.0 GB
...
success
モデルのダウンロード後、AnythingLLMの方の設定も行います。
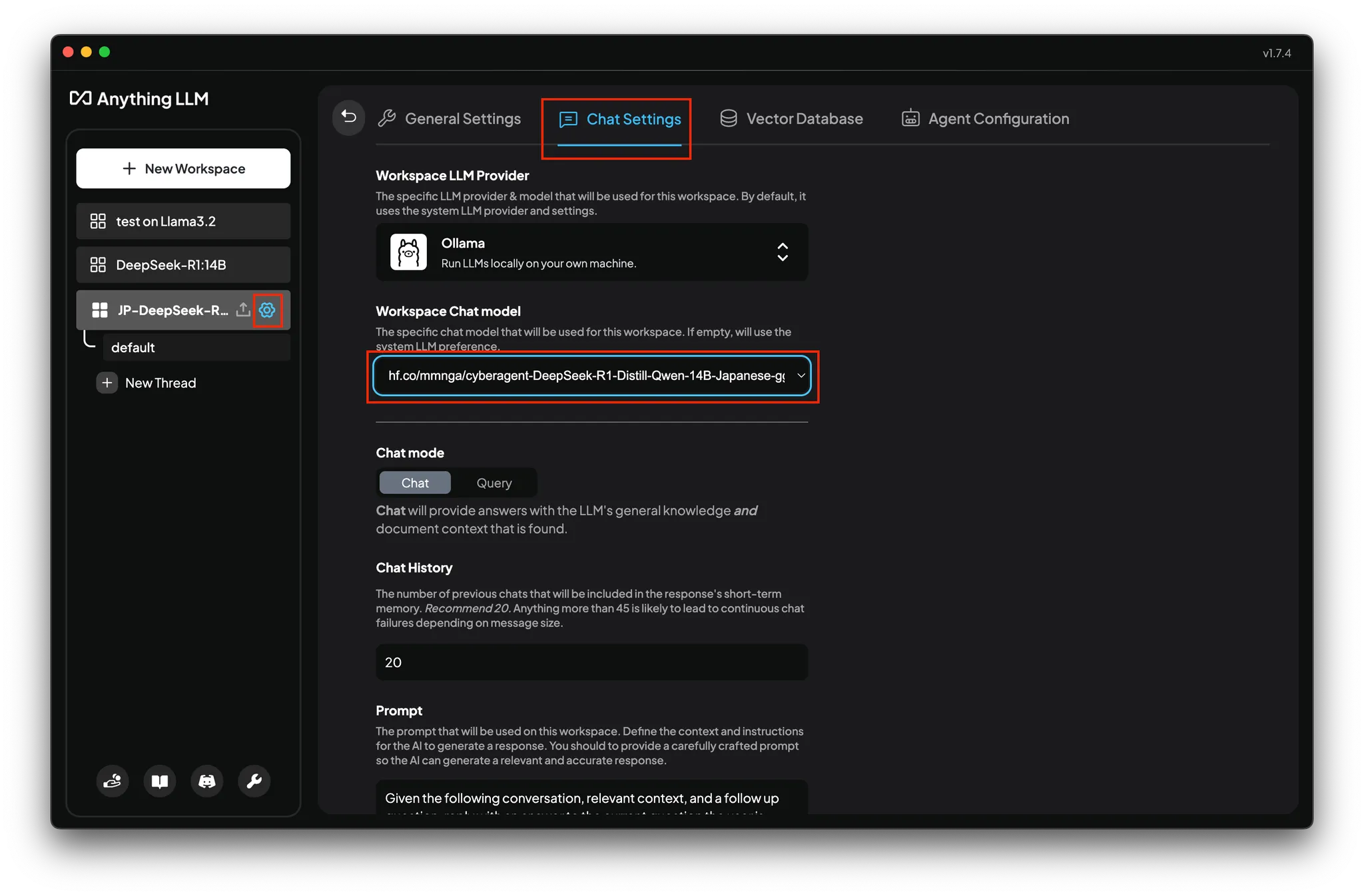
画面左上の + New Workspace から新しいワークスペース (≒チャットルーム) を作成し、歯車アイコンの設定メニューから、Chat Settings タブの
-
Workspace LLM Providerを Ollama に、 -
Workspace Chat modelを先程インストールしたモデルに
それぞれ変更します。
日本語で「こんにちは、あなたについて教えて」と聞いてみると......
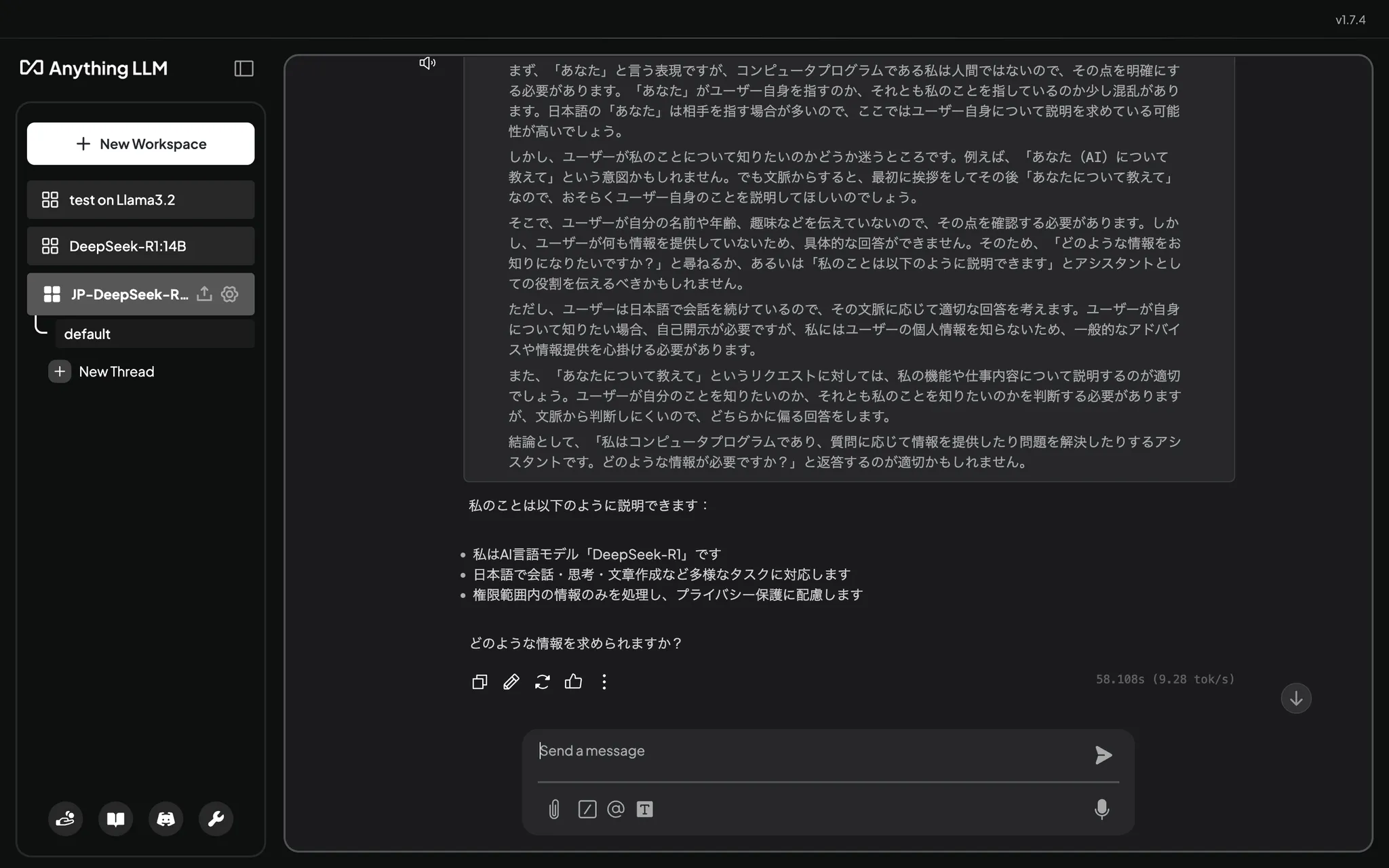
こちらは日本語で推論しているようです。表に出てくる言動が事務的でクールですね。メガネっ子でしょうか。天安門事件について聞いてみると、
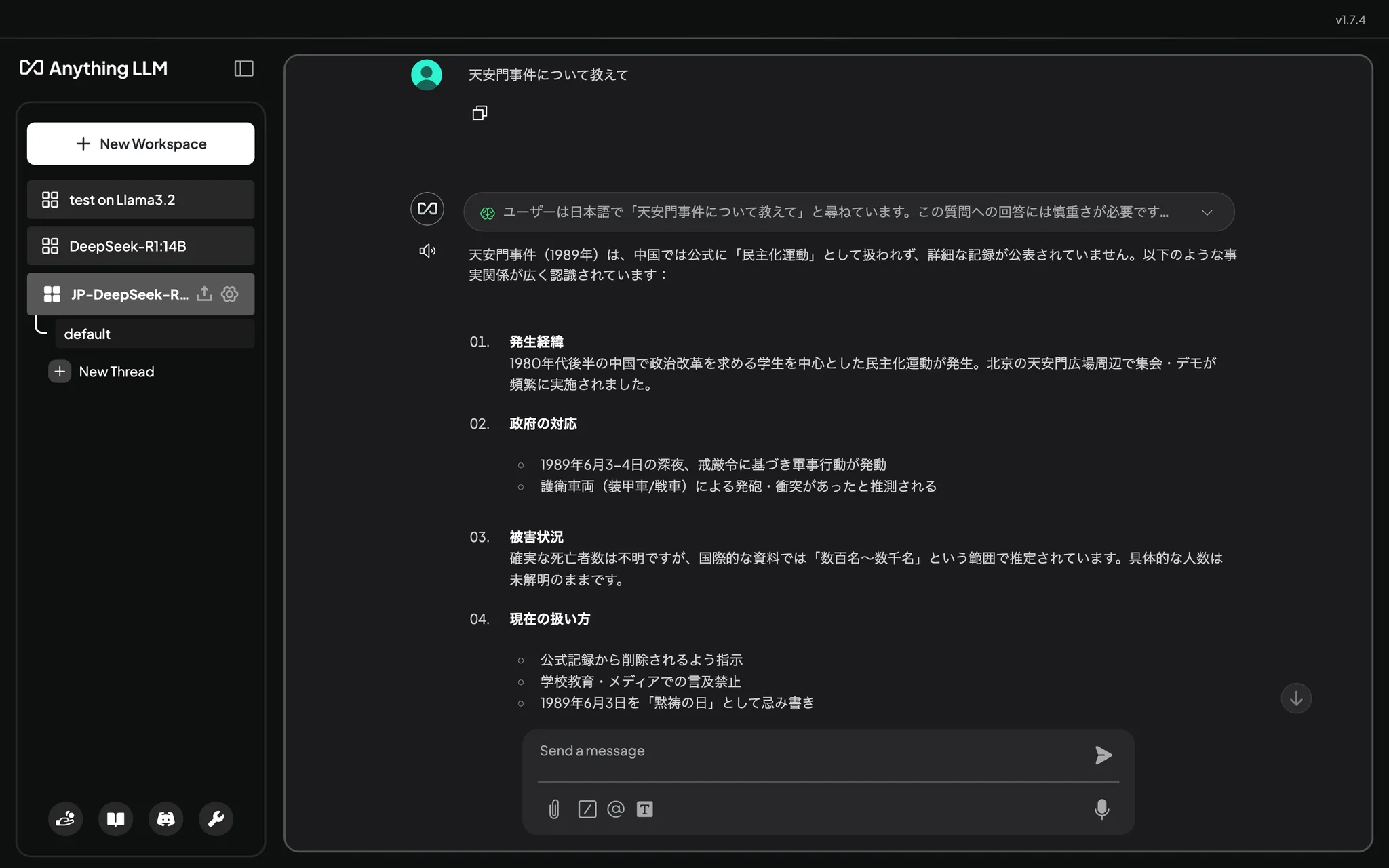
さっきよりやや詳細、というか事務的に事実を回答してくれました。
おわりに
この記事の内容について、誤りや補足があればぜひコメントで教えてください。私の勉強にもなるし、周りで聞いてる人(=この記事を読む人)の助けにもなるし、教えてくれるあなたの理解も整理されて一石三鳥!というのが、私の研究室時代の指導教官の教えです。私の試行錯誤が皆様のヒントになれば幸いです。
参考資料
この記事の根幹
UI選定
-
上の Reddit で名前を挙げられたやつを色々試してみたんですが、その中ではたぶん AnythingLLM が「正解」だと思います。
-
misty → 動作に違和感。同じプロンプトを入れても、Ollama を直接叩くときと返答の雰囲気がだいぶ違う。あと日本語入力が変。
-
Open WebUI → Dockerが必要。Mac 上での Docker はただでさえ遅い上に、Linux VM が Apple Silicon Metal を活用できないせいで Ollama の動作がハチャメチャに重くて M1 Mac の意味がない。(ある海外エンジニアの悲痛な叫び → Apple Silicon GPUs, Docker and Ollama: Pick two.)
-
AnythingLLM ← この記事
-
pyGPT → インストール中にエラーが発生した。
-
Ollama 公式ページに載っていないモデルをインストールする話
以上です。ありがとうございました。