こんにちは!株式会社マクニカで Databricks のエンジニアをしています。@satoshy2です。
Databricksとは?(マクニカ紹介ページ)
はじめに
Agent Bricks(ベータ版) は Databricks の Data + AI Summmit 2025 で初めて紹介された機能ですが、それから既に数ヶ月が経過していて触っている人は何人もいると思います。
遅まきながら私も触ってみたので、触って分かった良い点と悪い点を記載していきたいと思います。
また、リリース時期は少しズレますが、6月25日に PDF や画像ファイルからデータを抽出する機能(ai_parse_document)がリリースされていたので、その機能との比較も少しだけ記載します。
Agent Bricks(ベータ版)のナレッジアシスタントの概要
本記事記載時点(2025/08/28)では Agent Bricksはベータ版です。そのため、今後のリリースでは以降で記載している問題点も大きく改善されていることが期待されます。また、本記事はあくまで検証した2025/08/28時点での情報である点にご注意ください。
- ドキュメントファイル(txt、pdf、md、ppt/pptx、doc/docx)またはDatabricksベクトル検索インデックスを用意するだけで、ノーコードで簡単にRAG(Retrieval-augmented generation)チャットボットが作れます。
- us-east-1 または us-west-2 のどちらかのリージョンでのみ対応しています。
- その他にも、必要条件に記載の条件を満たしている必要があります。
簡単な設定手順については、弊社の別社員が記載した以下の記事に記載されていますのでご確認下さい。
ナレッジアシスタントの裏側で作成されるオブジェクト
現時点ではマニュアルなどに記載はありませんが、ナレッジアシスタントを設定すると以下のAI Playgroundを使用したRAGアプリイメージ図の濃い紫色のオブジェクト部分が裏側で作成されるのを確認しています。
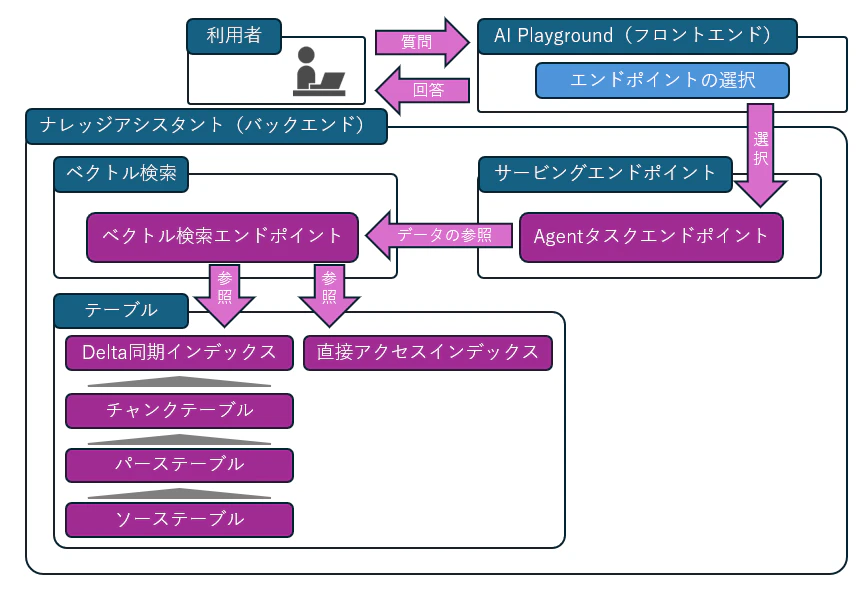
それぞれがどのように見えるか以下で簡単に記載します。
-
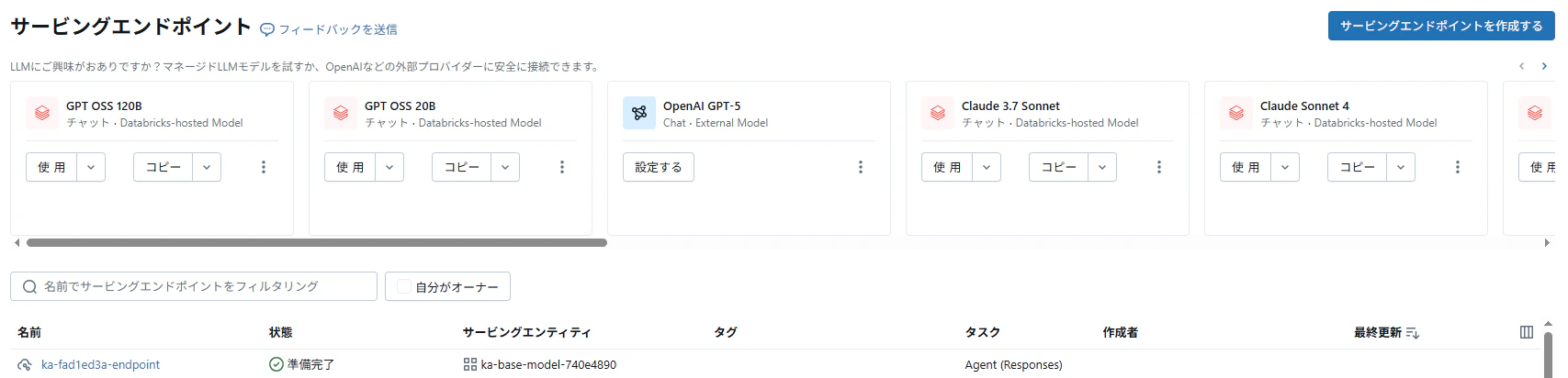
サービングエンドポイント(ナレッジアシスタントのAIエージェントを起動)
-
ベクトル検索(ナレッジアシスタントの検索対象データベースを起動)
-
1つのベクトル検索エンドポイント

-
1つ以上のDelta同期インデックス(データ検索用)と1つの直接アクセスインデックス(品質改善用)(実体はテーブル内に存在)
(以下はナレッジソースの設定でUCファイルタイプのソースを2つ指定した場合の例)

-
-
テーブル(ナレッジアシスタントが検索して取得する元データを保存)
ベクトル検索のインデックスを作成するためのテーブルです。- UCファイルタイプのソース1つにつき、3つのテーブル構成(タイプで「UCファイル」を指定した場合)
(以下はナレッジソースの設定でUCファイルタイプのソースを2つ指定した場合の例)
または、 - 1つ以上のテーブル構成(タイプで「ベクトル検索インデックス」を指定した場合)
- UCファイルタイプのソース1つにつき、3つのテーブル構成(タイプで「UCファイル」を指定した場合)
触って分かったナレッジアシスタントの良い点と悪い点(UCファイル編)
■ 良い点
-
設定が簡単(UI のみで完結できる)でほとんど迷う事なく設定できる。
-
対象ファイル数がある程度多くても(300以上のファイル数でも)問題なく処理できる。
- GUI から設定した ai_parse_document はファイル数が多いと(内容によっては50程度のファイル数でも)ジョブがエラーになる時がある。また、エラー内容も 「Internal error」 と表示されるだけで詳細が不明でどう対応したらよいか分からない
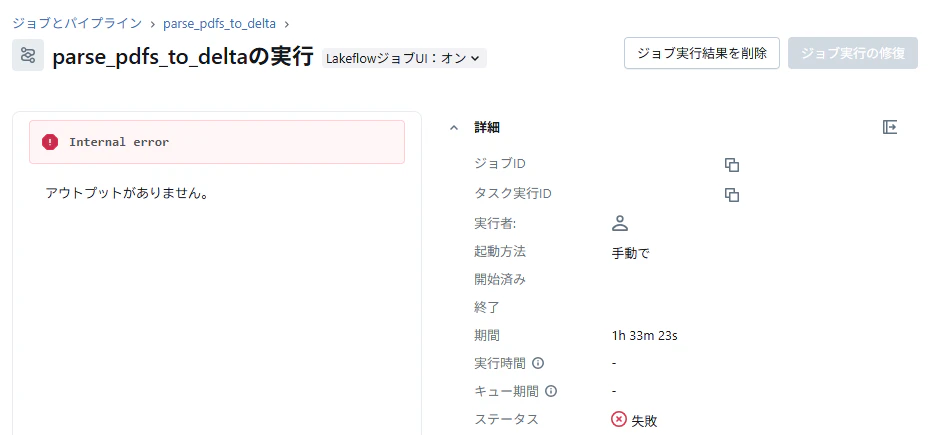
- GUI から設定した ai_parse_document はファイル数が多いと(内容によっては50程度のファイル数でも)ジョブがエラーになる時がある。また、エラー内容も 「Internal error」 と表示されるだけで詳細が不明でどう対応したらよいか分からない
-
テーブルが以下の3段階で作成されるため、動作に問題があった時に切り分けがしやすい。
-
ソーステーブル:1ファイル1行でファイルデータをバイナリ形式で保存(Bronzeテーブル相当)
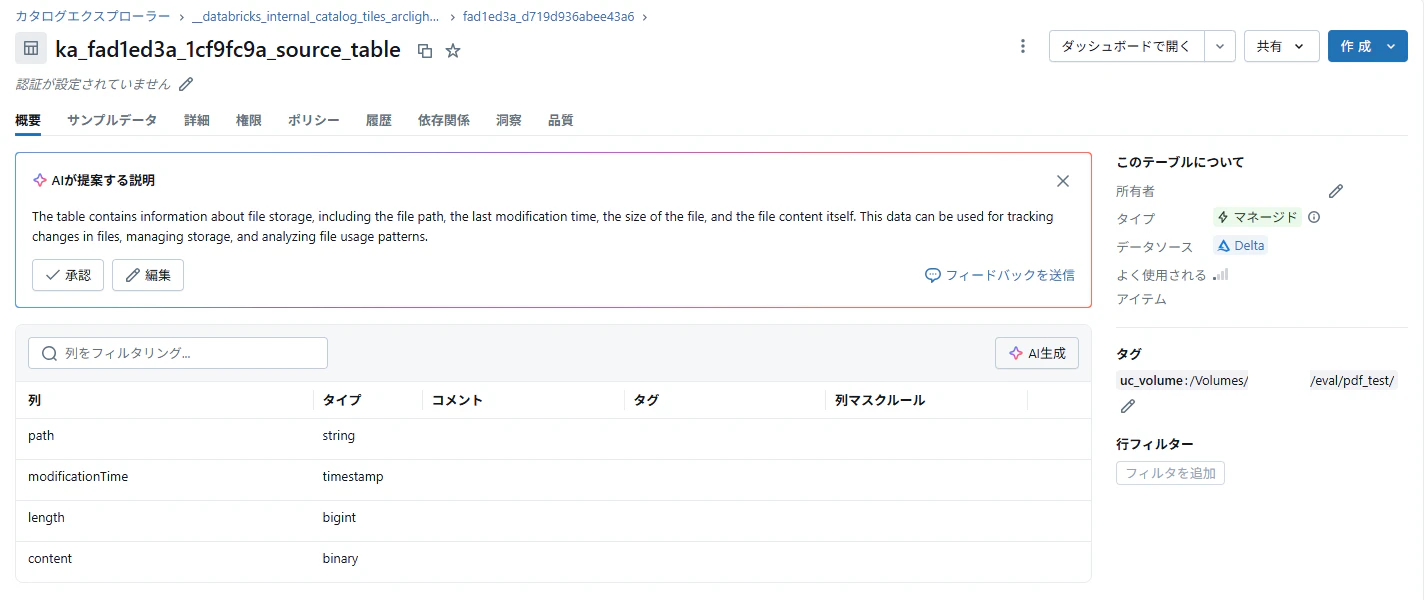
-
パーステーブル:1ファイル1行でファイルデータをテキスト形式で保存(Silverテーブル相当)
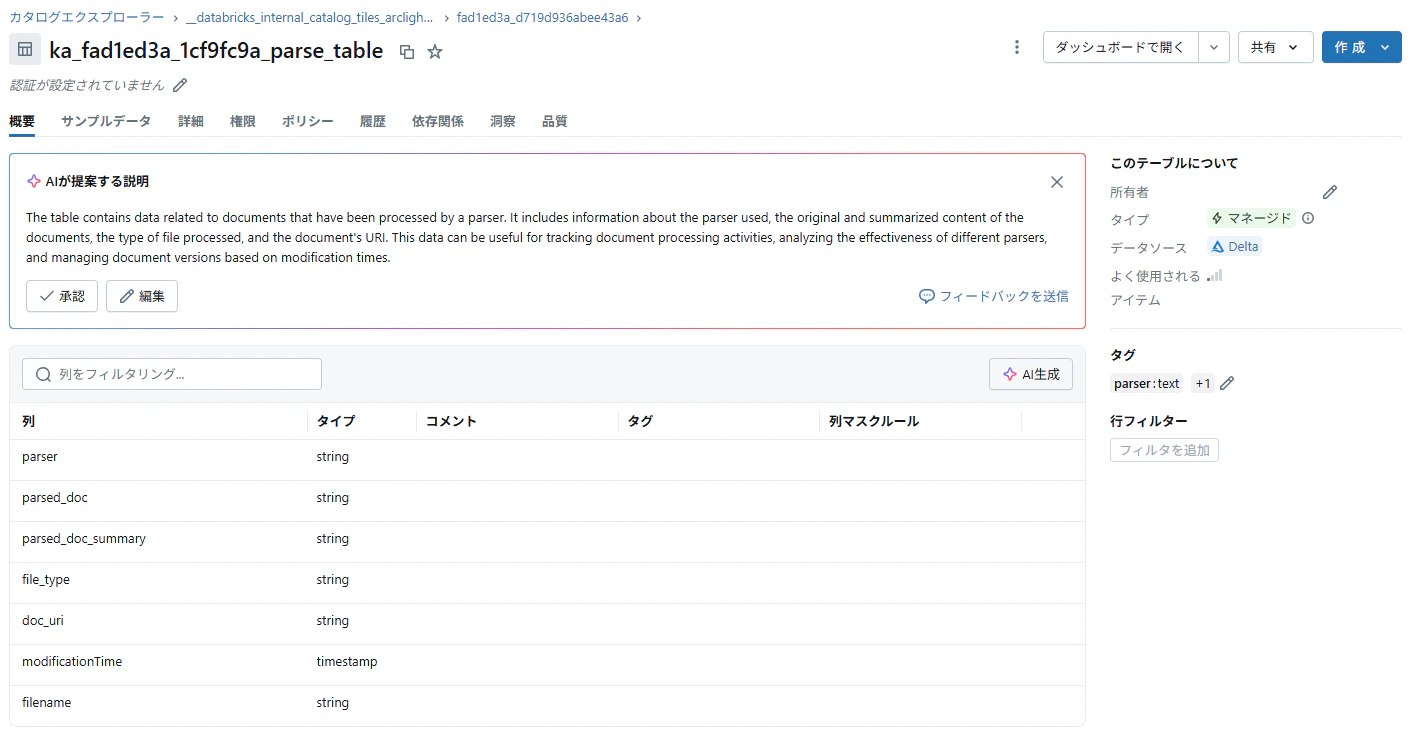
-
チャンクテーブル:1ファイル複数行でファイルデータを分割したテキスト形式(チャンクデータ)で保存(Goldテーブル相当)
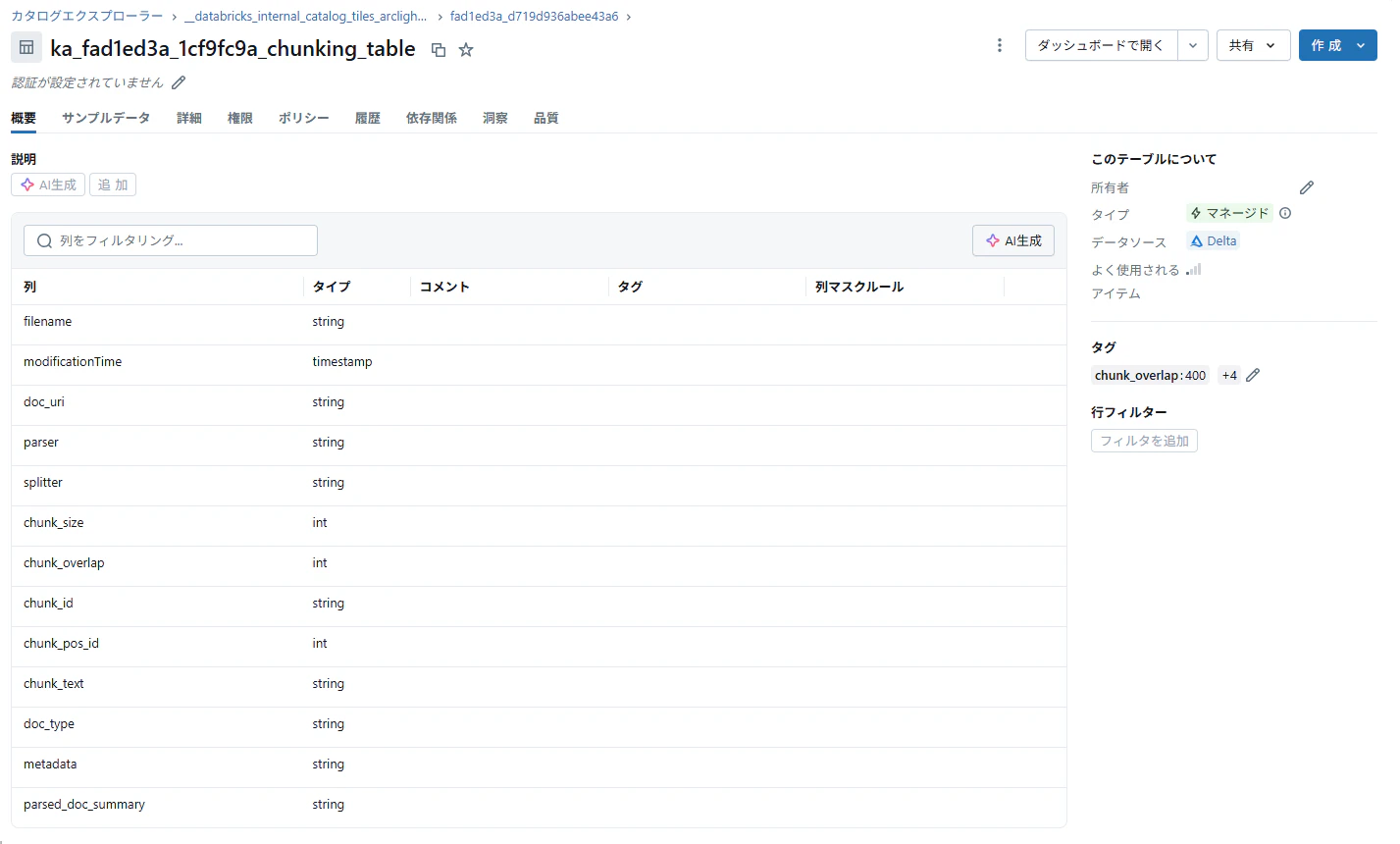
-
ソーステーブル:1ファイル1行でファイルデータをバイナリ形式で保存(Bronzeテーブル相当)
-
ai_parse_document よりデータ抽出費用が安いように見える(ベクトル検索やサービングエンドポイントのコンピュート費用は計算に含めない)。
- 正確な料金プランが記載されていないため詳細は不明だが、支払い明細を見る限りでは ai_parse_documentを使用していない方が費用は安いように見える。
- 正確な料金プランが記載されていないため詳細は不明だが、支払い明細を見る限りでは ai_parse_documentを使用していない方が費用は安いように見える。
-
ファイルの追加が簡単
- UCファイルで指定したボリュームパスにファイルを追加し、設定画面から同期ボタンをクリックするだけでデータの更新ができる。
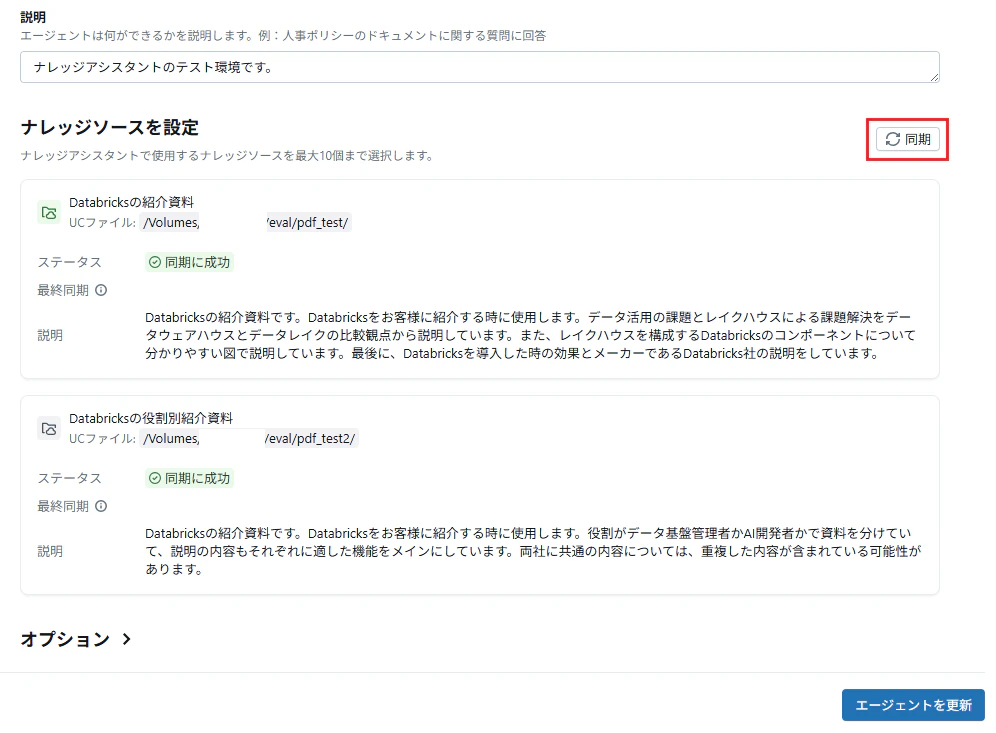
- UCファイルで指定したボリュームパスにファイルを追加し、設定画面から同期ボタンをクリックするだけでデータの更新ができる。
■ 悪い点
-
Embedding(埋め込み)のモデルが選択できない。
- databricks-gte-large-en が自動的に使用されるため、日本語などの英語以外の言語については検索精度に不安が残る。
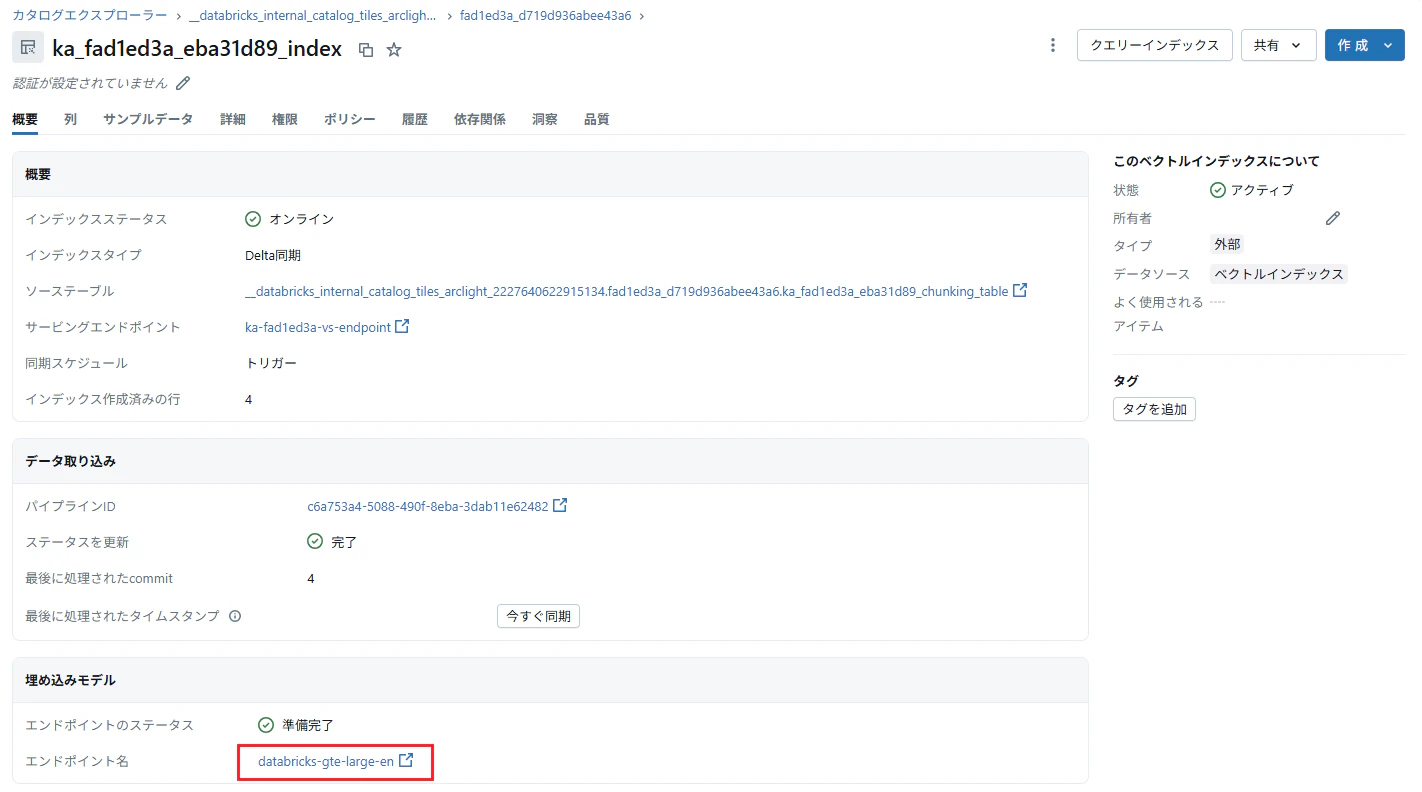
- databricks-gte-large-en が自動的に使用されるため、日本語などの英語以外の言語については検索精度に不安が残る。
-
内部で使用するために自動で作成される要約の言語が英語になる。
- 元が日本語の文書であっても英語で要約される。
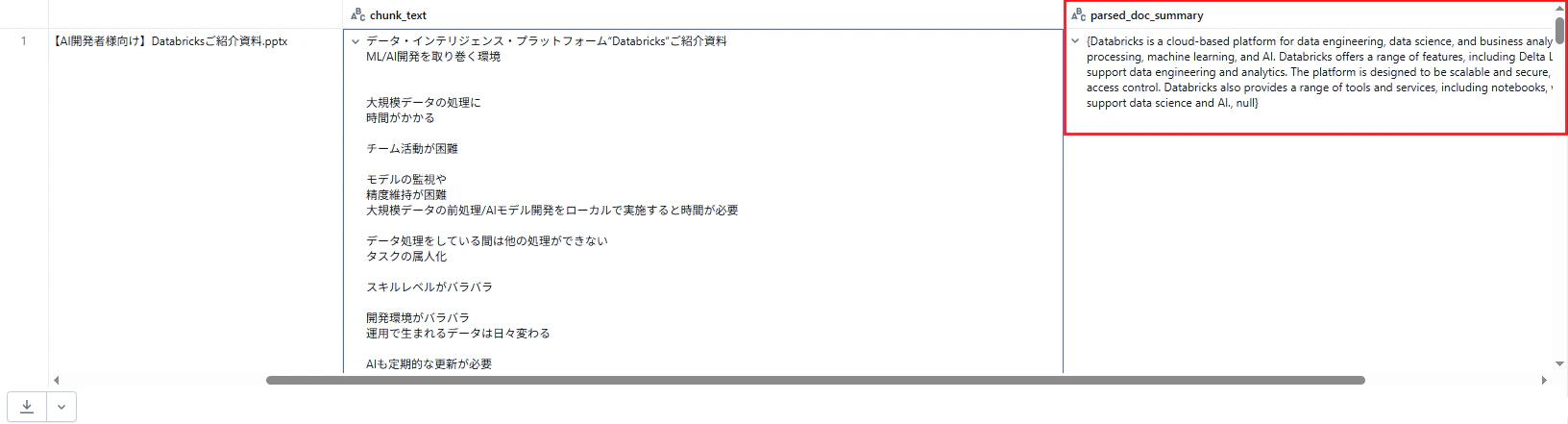
- 元が日本語の文書であっても英語で要約される。
-
テキスト文の抽出は問題無くされるが、表や図が抽出されない。
- ai_parse_document は表や図の内容も可能な限り抽出される(抽出できない表や図もある)。
- ai_parse_document は表や図の内容も可能な限り抽出される(抽出できない表や図もある)。
-
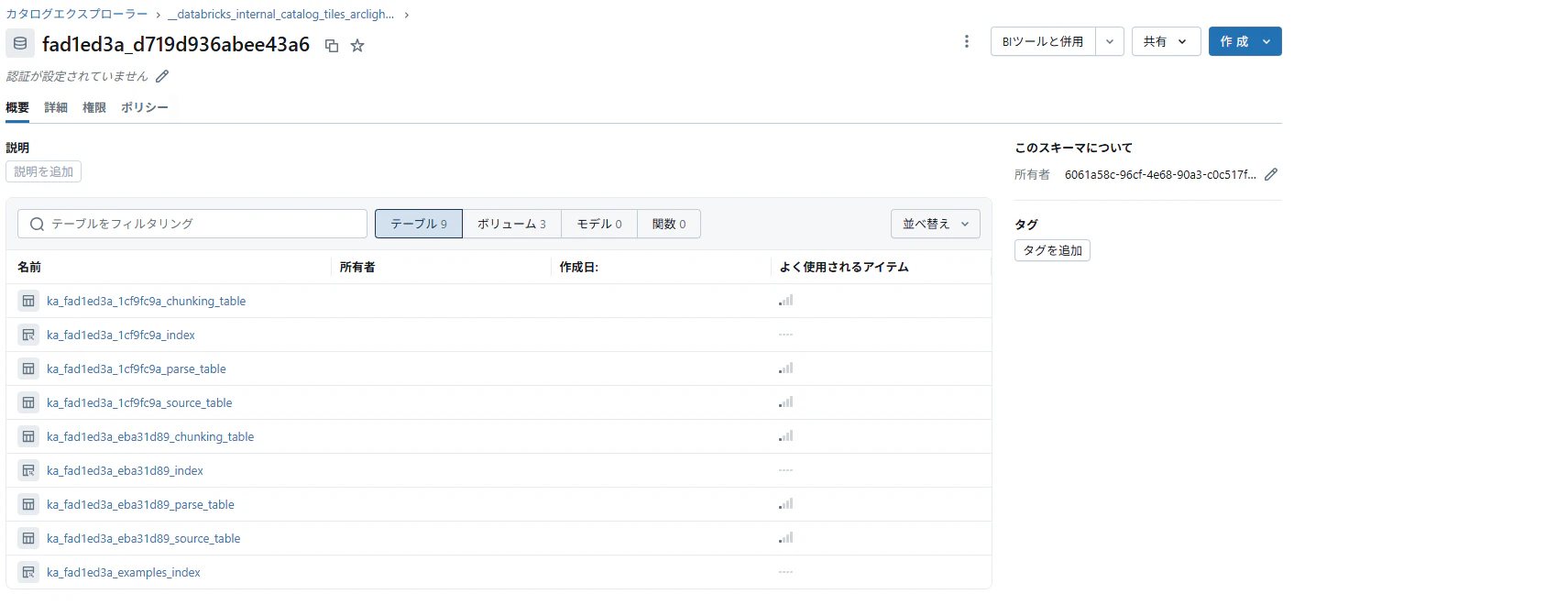
作成されたテーブルやベクトル検索インデックスがカタログから直接探せない。

- Databricksベクトル検索からインデックスのリンクを辿ることで見つけることは可能。
触って分かったナレッジアシスタントの良い点と悪い点(ベクトル検索インデックス編)
■ 良い点
-
設定が簡単(UI のみで完結できる)でほとんど迷う事なく設定できる。
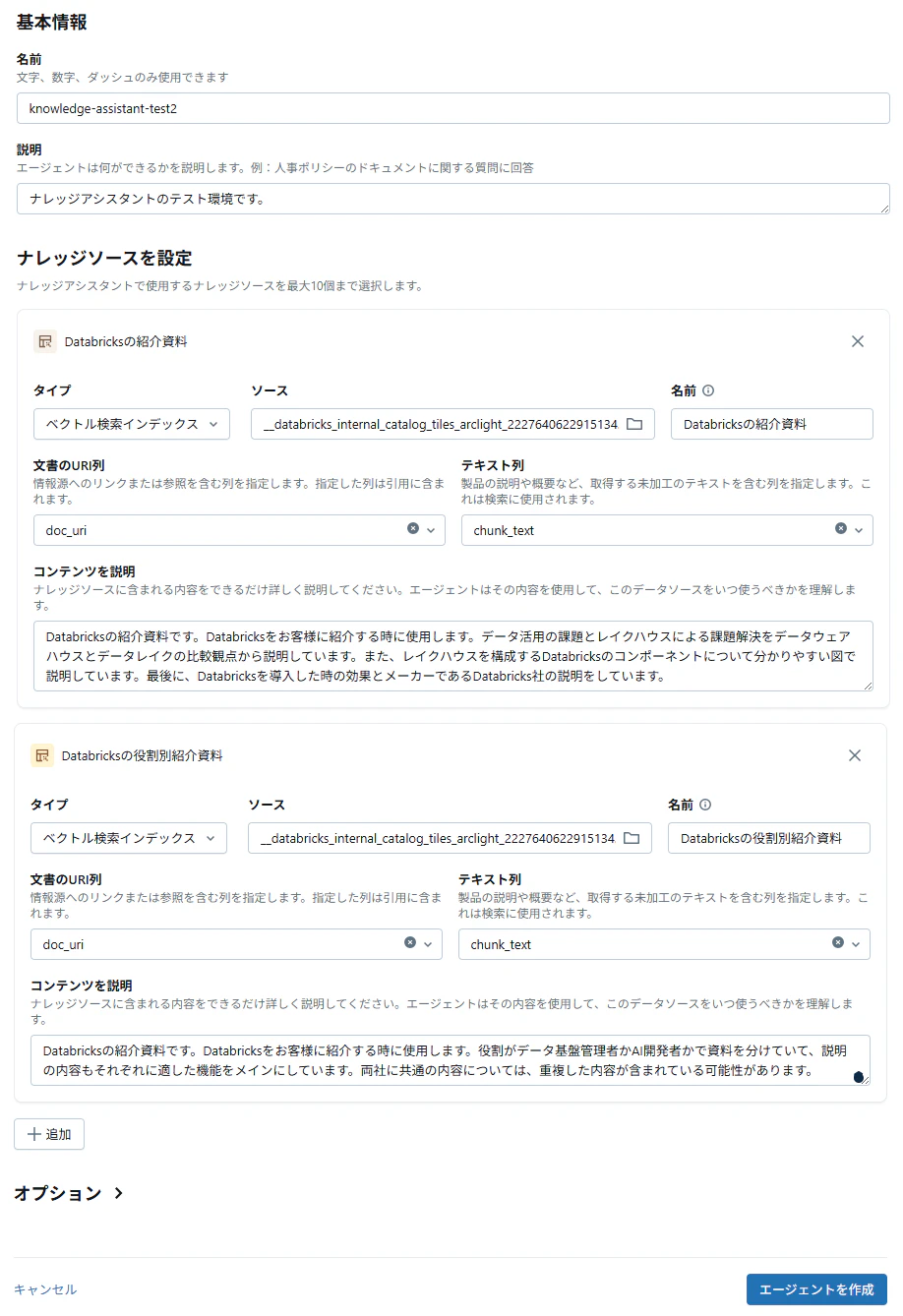
- 既存のDatabricksベクトル検索のインデックスが使用できるので、新たにインデックスを作成する必要が無い。
■ 悪い点
-
Embedding(埋め込み)結果を含んだテーブルから作成した既存のDatabricksベクトル検索インデックスは使用できない。
- 文章をベクトル変換する処理が含まれなくなるため、ベクトル検索が正常に動作しない。
- 文章をベクトル変換する処理が含まれなくなるため、ベクトル検索が正常に動作しない。
-
任意のEmbedding(埋め込み)モデルが使用できない。
- 任意の Embedding(埋め込み)モデルを使用したところ、エラーが表示されて動作しなかった。
- Databricks に最初から設定されている基盤モデルの Embedding(埋め込み)モデル(databricks-gte-large-en)を使用したところ、問題無く動作した。
-
既存のDatabricksベクトル検索エンドポイント(コンピュート部分)をそのまま再利用することは出来ない。
- 新規にDatabricksベクトル検索エンドポイント(コンピュート部分)が作成されるため、コンピュート費用が余分にかかる。

- 新規にDatabricksベクトル検索エンドポイント(コンピュート部分)が作成されるため、コンピュート費用が余分にかかる。
既存のDelta同期インデックスと上位のスキーマとカタログに対してAgent Bricks作成者の権限を適切に設定しないとエラーが発生するので注意して下さい。
おわりに
Agent Bricksのナレッジアシスタントはベータ版ということもあり、まだ足りない点が感じられましたが、簡単な設定でRAGを使ったAIエージェントが作成できるところ、ファイルを追加した時の処理も簡単であるところに魅力を感じました。
また、AI Playground画面で実際の動作確認をした時に、回答(赤枠)前の思考段階(ピンク枠)が見えるのも分かりやすくてとても良かったです(青枠は回答に使用した参考情報)。
