目次
RAGとは何か?
RAG(Retrieval-Augmented Generation) は、日本語で「検索拡張生成」と呼ばれる技術です。大規模言語モデル(LLM)に外部の知識を与えることで、より正確で最新の情報に基づいた回答を生成できるようにする仕組みです。
RAGが解決する課題
LLMには以下のような制限があります:
- 知識の鮮度: 学習データの時点までの情報しか知らない
- 専門知識の不足: 特定の企業や個人の情報は持っていない
- ハルシネーション: 不正確な情報を生成してしまうことがある
RAGは、これらの問題を「必要な情報を検索して、その情報をもとに回答を生成する」ことで解決します。
RAGのアーキテクチャ
RAGシステムは大きく2つのフェーズで動作します:
【準備フェーズ】ドキュメントをベクトル化して保存
ドキュメント → 埋め込みモデル → ベクトル → VectorDB
(文章) (Embedding) (数値配列) (ChromaDB)
例:
「Q1. プロジェクトが3コミットで終わってしまうのですが、どうしたらよいですか?
A1. 最初から「1週間で完成するもの」に絞りましょう。」
↓
[0.23, -0.15, 0.67, ...]
↓
ChromaDBに保存
【検索・生成フェーズ】質問に関連する情報を検索して回答
質問 → 埋め込み → 類似検索 → 関連ドキュメント → プロンプト → LLM → 回答
例:「プロジェクトがすぐ終わってしまうのですが、どうしたらよい?」
↓
[0.21, -0.17, 0.65, ...](質問をベクトル化)
↓
ChromaDBで類似度計算
↓
「Q1. プロンプトが... A. 最初から...」(最も近いドキュメントを取得)
↓
質問 + 取得したドキュメント → LLMに入力
↓
「個人開発は最初から「1週間で完成するもの」に絞りましょう。...」
主要な概念の解説
1. VectorDB(ベクトルデータベース)
VectorDBは、テキストを数値の配列(ベクトル)として保存し、類似度検索を高速に行えるデータベースです。
通常のデータベースでは「完全一致検索」しかできませんが、VectorDBでは「意味が似ているものを探す」ことができます。
通常のDB検索:
「テスト」で検索 → 「テスト」という単語を含む文書のみ
VectorDB検索:
「テスト」で検索 → 「テスト」「テストコード」「ユニットテスト」
「品質保証」など、意味的に関連する文書も発見
2. ChromaDB
ChromaDBは、Python向けの軽量なVectorDBです。特徴は以下の通り:
- インストールが簡単で、すぐに使える
- ローカルファイルとして永続化できる
- LangChainと統合されている
他のVectorDBには、Pinecone(クラウド)、Qdrant(高性能)、FAISS(Meta製)などがありますが、学習目的ならChromaDBが最適です。
3. Embedding(埋め込み)
Embeddingは、テキストを数値の配列(ベクトル)に変換することです。意味が似ている文章は、似たようなベクトルになります。
「犬が走っている」 → [0.8, 0.2, -0.3, ...]
「猫が歩いている」 → [0.7, 0.3, -0.2, ...]
「雨が降っている」 → [-0.1, 0.9, 0.6, ...]
※ 実際は数百〜数千次元のベクトル
このプロジェクトでは、OpenAIのtext-embedding-3-largeモデルを使用しています。
4. LangChain
LangChainは、LLMを使ったアプリケーション開発を簡単にするフレームワークです。以下のような機能を提供します:
- VectorDBとの統合
- プロンプトテンプレートの管理
- LLMの呼び出しを簡潔に記述
- 複数の処理をパイプラインで繋げる(LCEL)
5. LCEL(LangChain Expression Language)
LCELは、LangChainで処理の流れを記述するための記法です。パイプ演算子(|)を使って、処理をつなげていきます。
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
これは以下の流れを表現しています:
入力(質問)
↓
retrieverで関連ドキュメントを検索 + 質問をそのまま渡す
↓
promptテンプレートに埋め込む
↓
LLMで回答を生成
↓
文字列として出力
実装の流れ
ステップ1: Embeddingモデルの準備
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
テキストをベクトル化するためのモデルを初期化します。OpenAIのAPIキーが必要です。
ステップ2: VectorStoreの作成
from langchain_chroma import Chroma
vector_store = Chroma(
collection_name="example_collection",
embedding_function=embeddings,
persist_directory="./chroma_langchain_db",
)
ChromaDBのインスタンスを作成し、persist_directoryでローカルに保存します。
ステップ3: ドキュメントの追加
from langchain_core.documents import Document
document = Document(
page_content="Q1. プロジェクトが3コミットで終わってしまう...",
metadata={"source": "personal_dev_guide", "category": "継続"},
id=1,
)
vector_store.add_documents(documents=[document], ids=[uuid])
Documentオブジェクトでテキストとメタデータを管理し、VectorStoreに追加します。
ステップ4: 類似度検索
results = vector_store.similarity_search(
"考えるだけで満足して手が動きません",
k=2,
filter={"source": "personal_dev_guide"},
)
質問に関連するドキュメントを検索します。k=2で上位2件を取得し、filterで特定のメタデータに絞り込みます。
ステップ5: Retrieverの作成
retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={"k": 1, "fetch_k": 5}
)
as_retriever()でVectorStoreを検索エンジンとして使えるようにします。mmr(Maximal Marginal Relevance)は、似たような結果を避けて多様な結果を返す検索手法です。
ステップ6: RAGチェーンの構築
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
prompt = ChatPromptTemplate.from_template('''
文脈: """{context}"""
質問: "{question}"
''')
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
LCELを使って、検索→プロンプト作成→LLM呼び出し→出力という一連の処理をチェーンとして定義します。
ステップ7: 質問の実行
output = chain.invoke("煮詰まったときの対処法について")
print(output)
invoke()でチェーンを実行し、RAGによる回答を取得します。
アーキテクチャ図(詳細版)
==============================================
RAGシステム全体構成
==============================================
┌─────────────────────────────────────────┐
│ 【準備フェーズ】 │
│ ドキュメントをVectorDBに登録 │
└─────────────────────────────────────────┘
1. ドキュメント作成
┌─────────────────────────┐
│ Document │
│ - page_content (本文) │
│ - metadata (メタ情報) │
│ - id (識別子) │
└─────────────────────────┘
↓
2. Embeddingでベクトル化
┌─────────────────────────┐
│ OpenAIEmbeddings │
│ model: text-embedding │
│ -3-large │
└─────────────────────────┘
↓
「テストは不要」
→ [0.23, -0.15, 0.67, ...]
↓
3. ChromaDBに保存
┌─────────────────────────┐
│ ChromaDB (VectorDB) │
│ - ベクトルデータ │
│ - メタデータ │
│ - 高速類似度検索 │
└─────────────────────────┘
┌─────────────────────────────────────────┐
│ 【検索・生成フェーズ】 │
│ 質問に対して回答を生成 │
└─────────────────────────────────────────┘
1. ユーザーからの質問
┌─────────────────────────────────────┐
│ 入力質問 │
│ 「個人開発ではテストどうすればいい?」 │
└─────────────────────────────────────┘
↓
2. 質問をベクトル化
┌─────────────────────────┐
│ OpenAIEmbeddings │
└─────────────────────────┘
↓
[0.21, -0.17, 0.65, ...]
↓
3. ChromaDBで類似検索
┌─────────────────────────┐
│ Retriever (MMR) │
│ - k=1 (取得件数) │
│ - fetch_k=5 (候補数) │
└─────────────────────────┘
↓
関連ドキュメントを取得
↓
4. プロンプト生成
┌─────────────────────────┐
│ ChatPromptTemplate │
│ 文脈: {検索結果} │
│ 質問: {ユーザー質問} │
└─────────────────────────┘
↓
5. LLMで回答生成
┌─────────────────────────┐
│ ChatOpenAI │
│ model: gpt-4o-mini │
│ temperature: 0 │
└─────────────────────────┘
↓
6. 文字列として出力
┌─────────────────────────┐
│ StrOutputParser │
└─────────────────────────┘
↓
「個人開発の初期段階では
テストは不要です... [A19]」
まとめ
このプロジェクトでは、以下の技術を使ってRAGシステムを構築しました:
- LangChain: RAGパイプラインの構築
- ChromaDB: ベクトルデータの保存と検索
- OpenAI Embeddings: テキストのベクトル化
- OpenAI GPT-4o-mini: 回答の生成
- LCEL: 処理フローの記述
RAGは、LLMに最新の情報や専門知識を与える強力な手法です。この基本構造を理解すれば、社内ドキュメント検索や顧客サポートボットなど、さまざまな応用が可能になります。
おまけ
Streamlit を使用してフロントを作成しWebアプリケーションにしてみました。
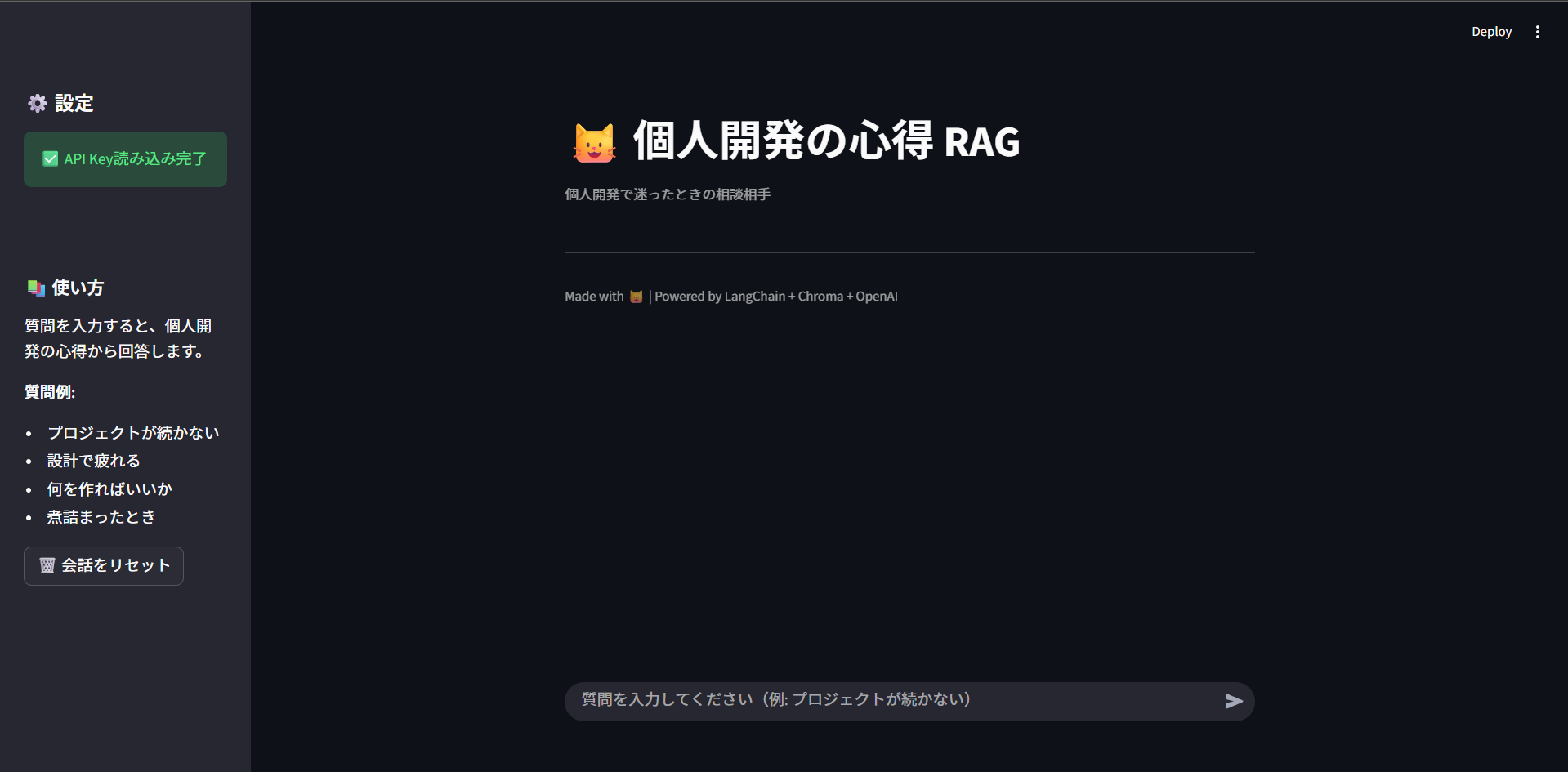
検索すると以下のように回答してくれる(※テスト用に分かりやすいナレッジを探させる質問をしています)。