はじめに
今回はDataprepで国勢調査のデータをBigQueryに入れてみたいと思います。
GoogleではBigQueryに色んな公開されているデータが入っているのですが、ほとんどがアメリカのデータで日本のデータもどうにかならんかなぁと思っていた矢先に、Dataprepが出てくれました。これなら面倒なデータの準備も楽に出来るかなと。
あと、最近になって政府が公開しているデータも細かなものになってきました。
と、いうことで国勢調査のうちの町単位で人口が入っているデータを今回はDataprepで加工して、BigQueryに入れてみたいと思います。
データを用意する
ファイルをダウンロード
データはこちらのサイトからダウンロードしてきました。
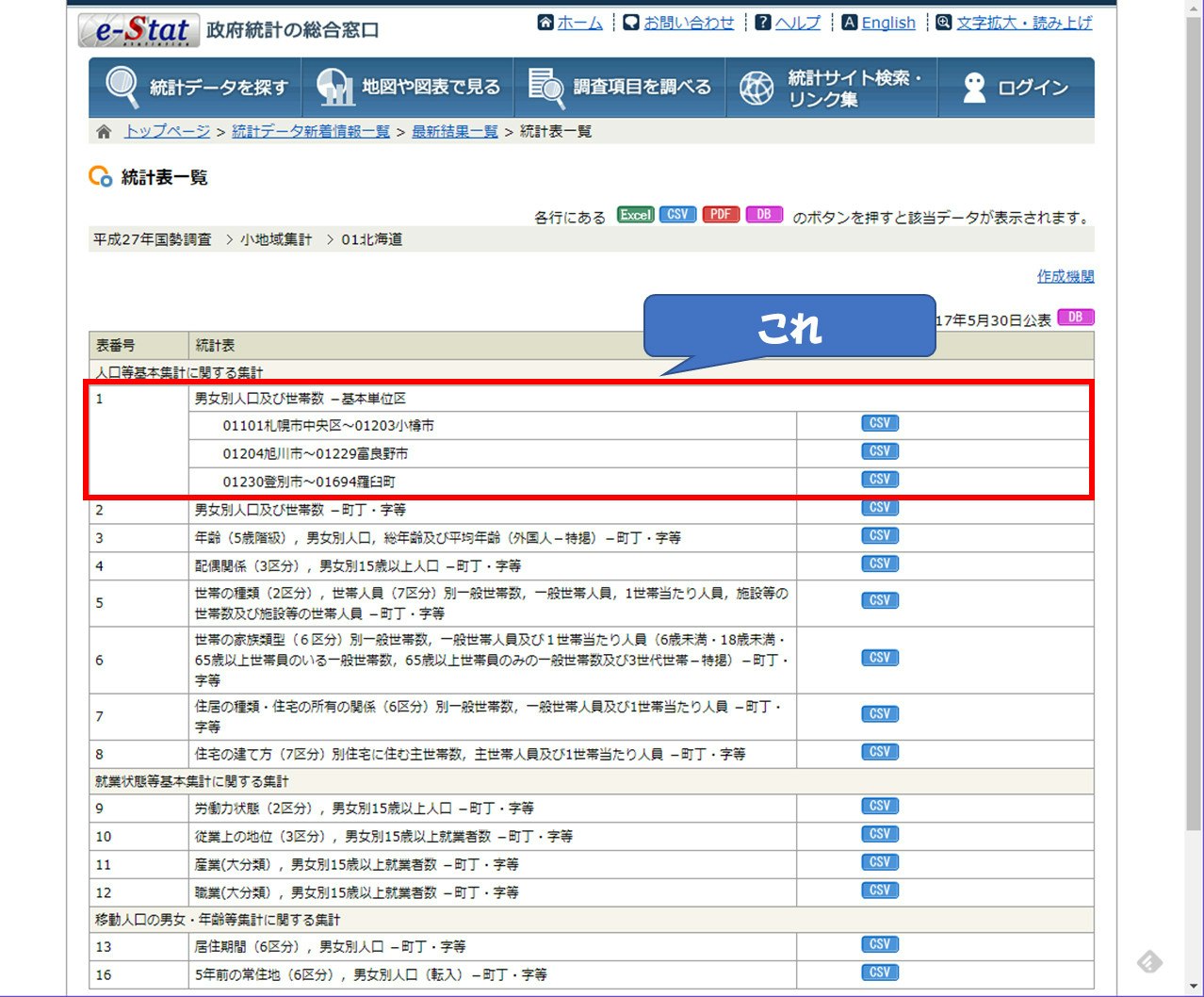
直近では平成27年の国勢調査はこちらでダウンロードできます。今回使うデータは出来るだけ細かいものが欲しいので、ページの一番下の方に折りたたまれている『小地域集計』から各県を選んで『男女別人口及び世帯数 -基本単位区』をダウンロードします。今回は北海道3ファイルでやってみます。
UTF-8に変更する
ダウンロードしてきたファイルですが、ご多分に漏れず文字コードはShift-JISです。
DataprepおよびBigQueryはUTF-8にしか対応していませんので、文字コードを変換してください。自分はnkfで一気に変換しました。
ファイルをアップロードする
ファイルをアップロードします。Dataprepから直接アップロードするのでも、Cloud Storageに一旦あげるのでもどちらでも構いません。
今回はCloud Storageに一旦アップロードしてからDataprepでインポートしたいと思います。
Cloud Storageにアップロード
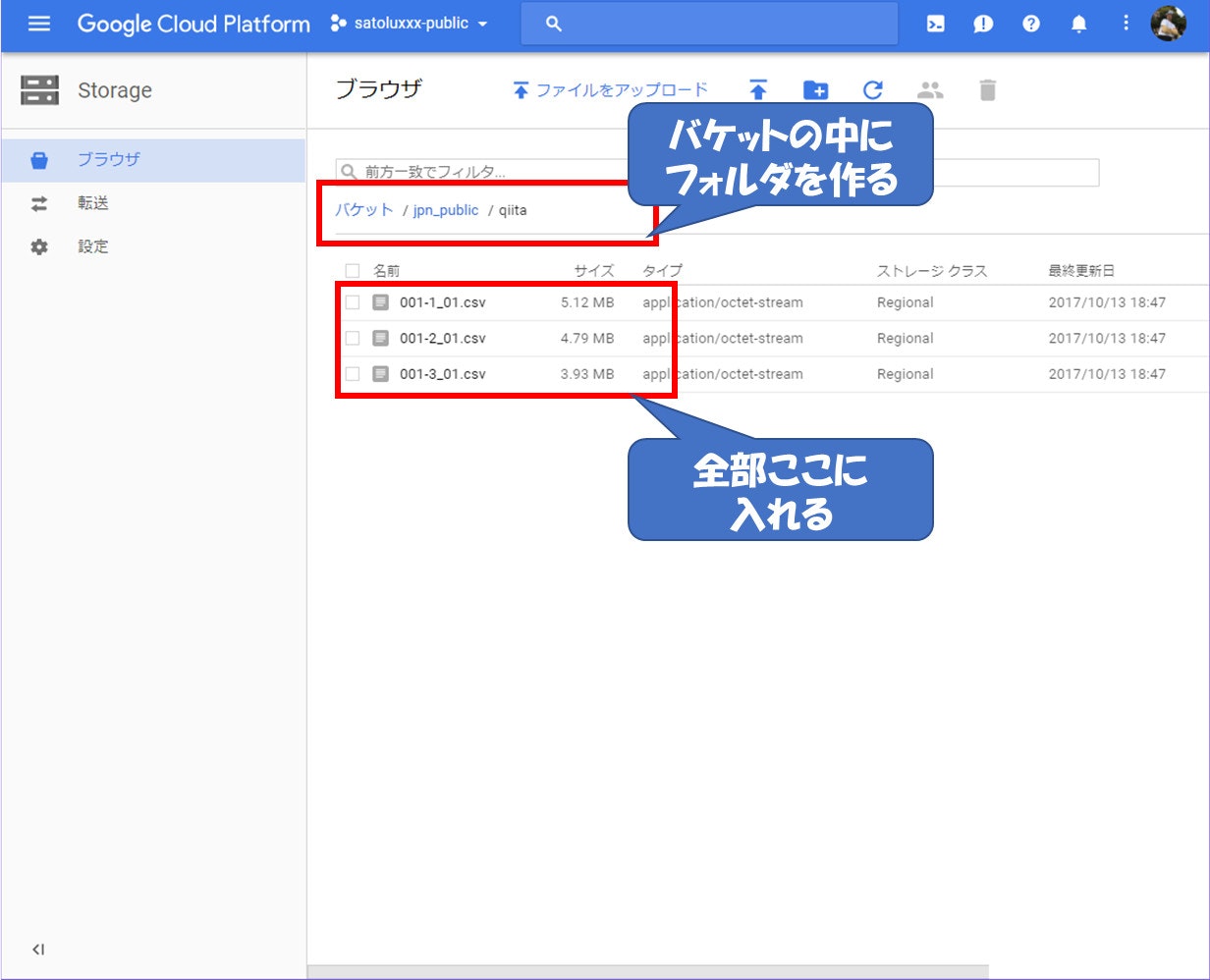
バケットを作成して、その中にさらにフォルダを作ってそこにアップロードしてください。
そうすることでDataprep側で処理するデータ元を指定する際に、フォルダを指定するとその中に入っているファイル全てに対して処理を実行してくれます。もちろん1つ1つファイルを指定してDataprep側で結合(UNION)することも可能です。
Dataprepでデータを処理する
ではデータが準備できたのでDataprepで処理を作っていきたいと思います。
Dataprepを起動する
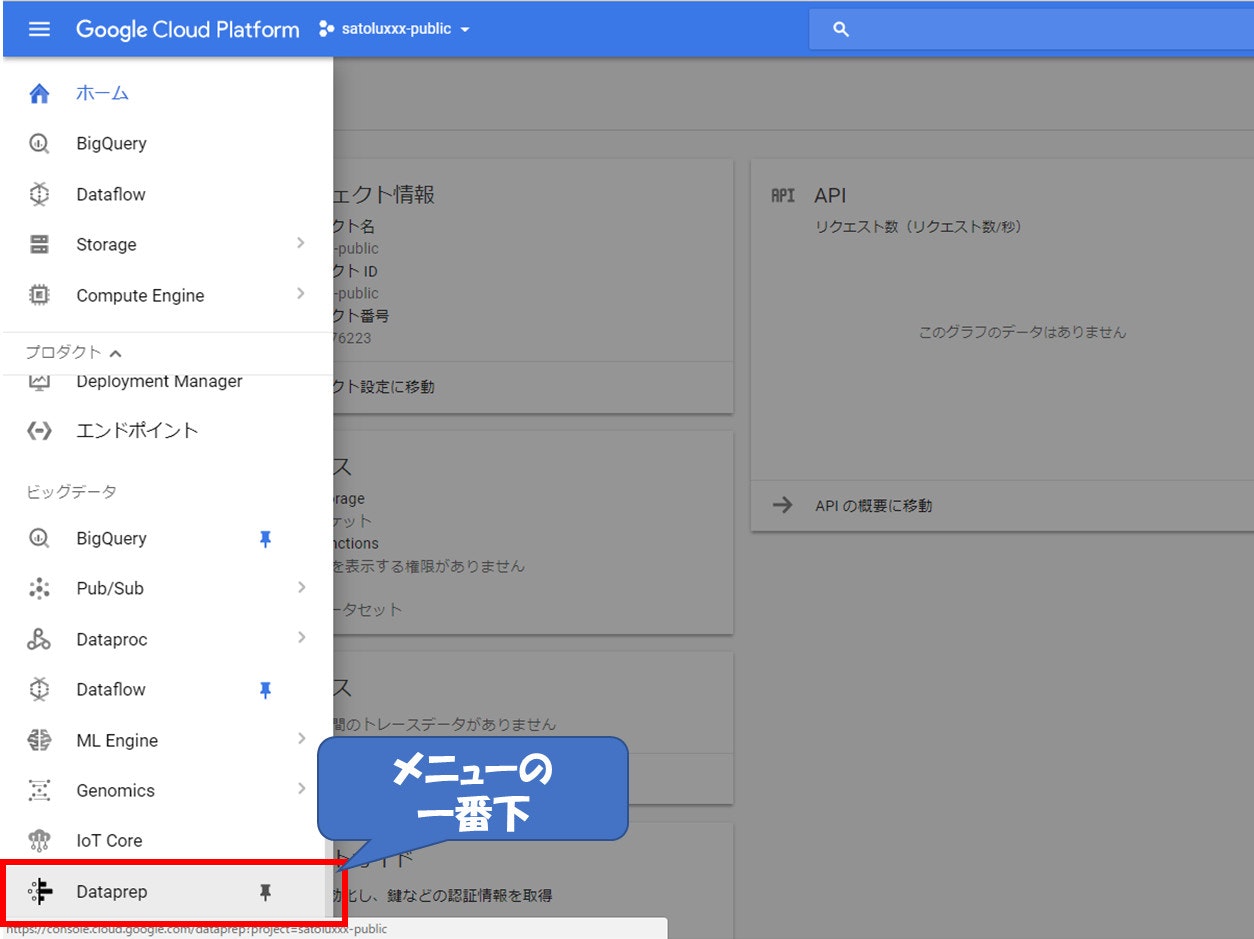
Cloud Consoleのメニューの一番下にある『Dataprep』を押下すると起動します。少し時間がかかるかもしれません。
起動するとこのような画面が表示されます。
処理するデータ元を指定する
処理するデータ元を指定します。画面上部の『DATASETS』を押下し、画面の真ん中にある『Import Data』を押下してください。
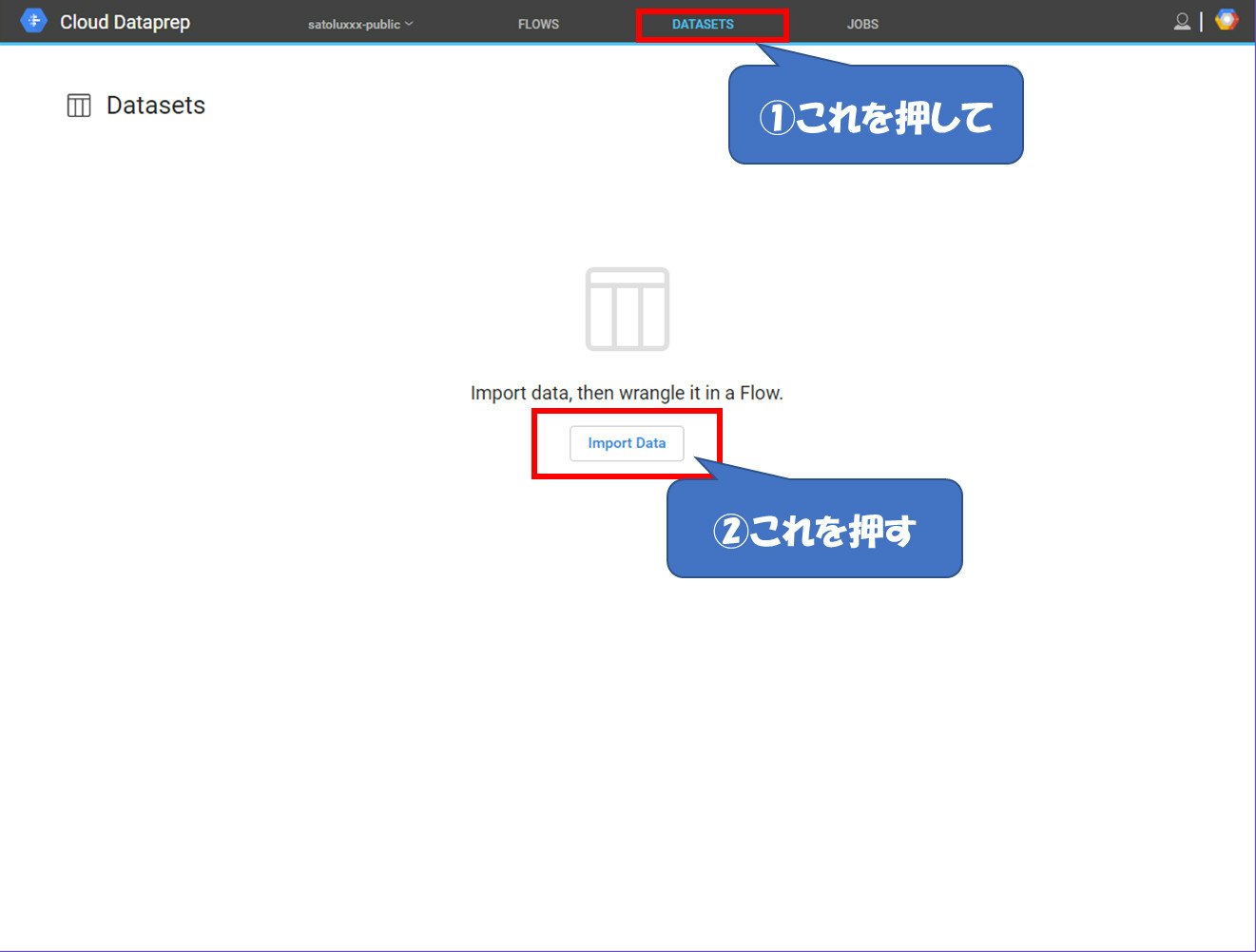
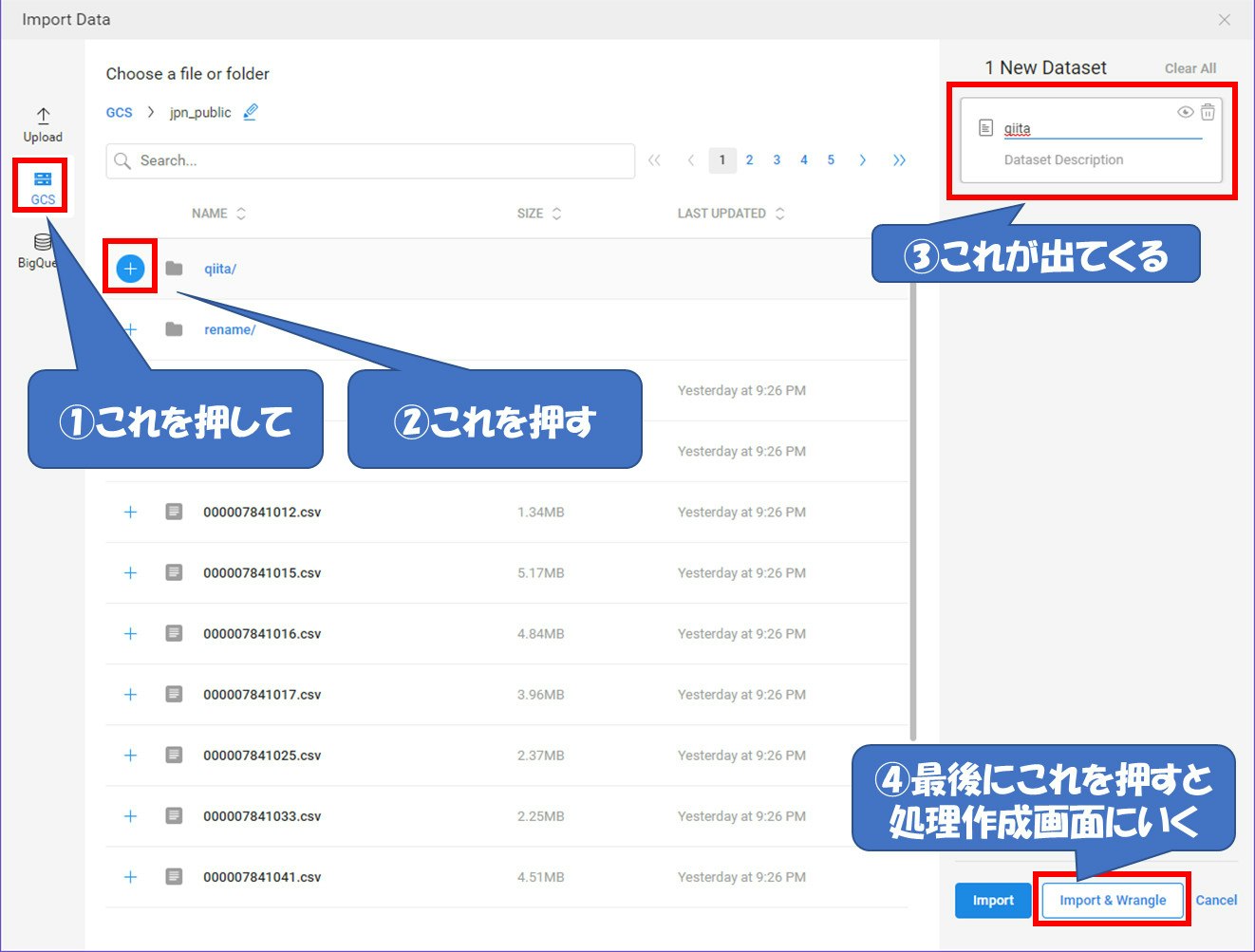
データ元はUpload(裏ではGCSに保存されます)、GCS(Cloud Storage)、BigQueryを選ぶことが出来ます。今回はGCSを選んで作成したバケットを押下し、その中に作ったフォルダの横にある『+』を押下してフォルダをデータ元として指定します。
最後に『Import & Wrangle』を押下すると処理作成画面に遷移します。
データを処理する
では実際にデータを処理していきましょう。
初期画面
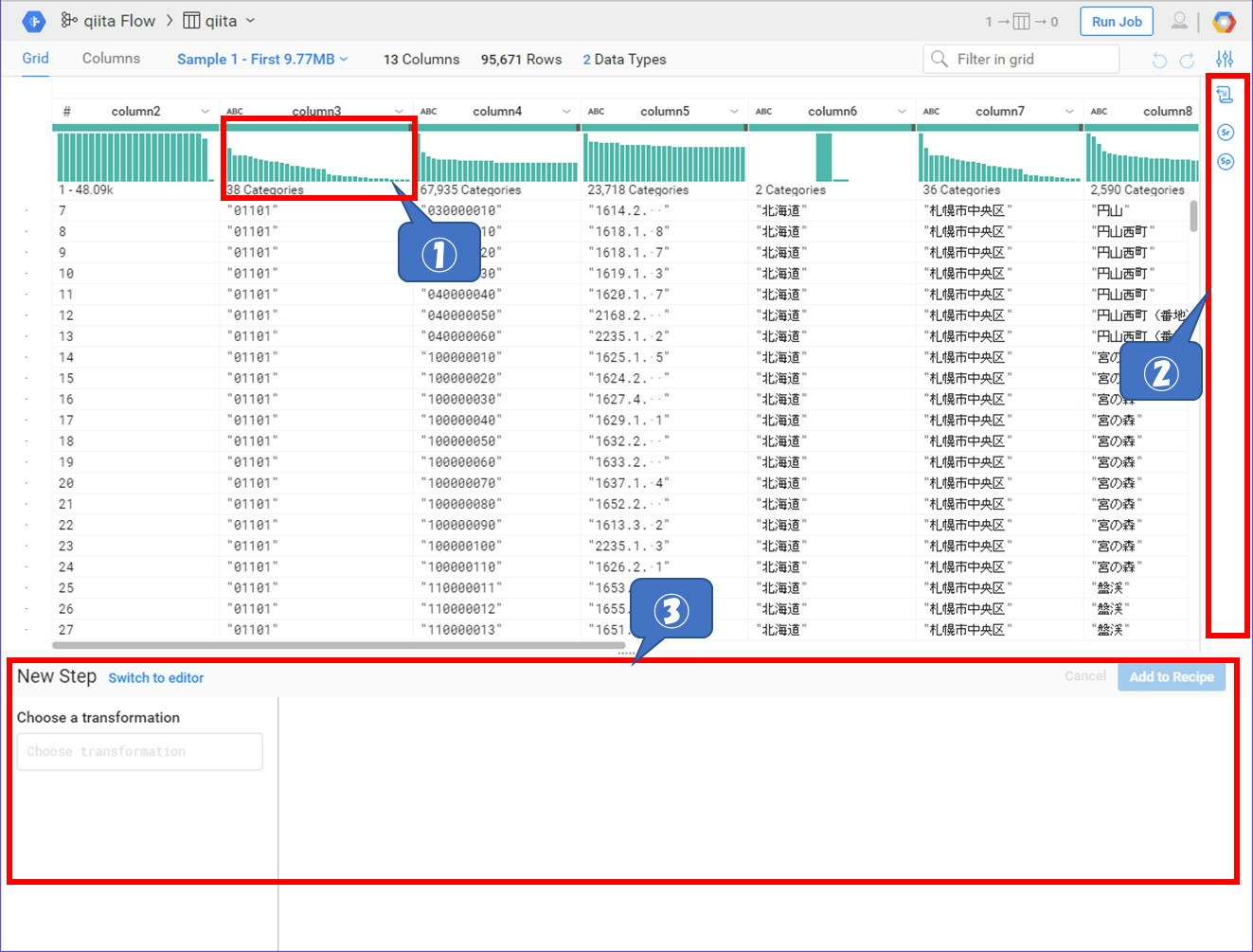
データ元を指定するとこのような画面が表示されます。サンプルとしてある程度のデータを読込み、そのサンプルを使ってプレビューしながら処理を作っていくこができます。
①はどのようなデータがどのぐらい入っているのか?などサマリ情報を表示してくれています。
②は処理の手順がアイコンで並んでいます。すでにデータ元を指定した時点で『ファイルを開く』『改行コードを読み込む』『カンマをデリミタとして扱う』という3つの処理が入ってこの画面が出ています。各アイコンをクリックするとプレビューの画面も変わっていきます。
③は実際の処理を書いていきます。
では、やっていきましょう。
文字列を置換する
BigQueryにデータを入れる際にはダブルクォーテーションは必要ありません。これを一括で削除します。
まずはプレビュー画面のどこでも良いので『"』をマウスでドラッグしてみてください。すると処理を書くところで処理方法を提案してくれるのと、プレビュー画面のところで処理後のデータを表示してくれています。
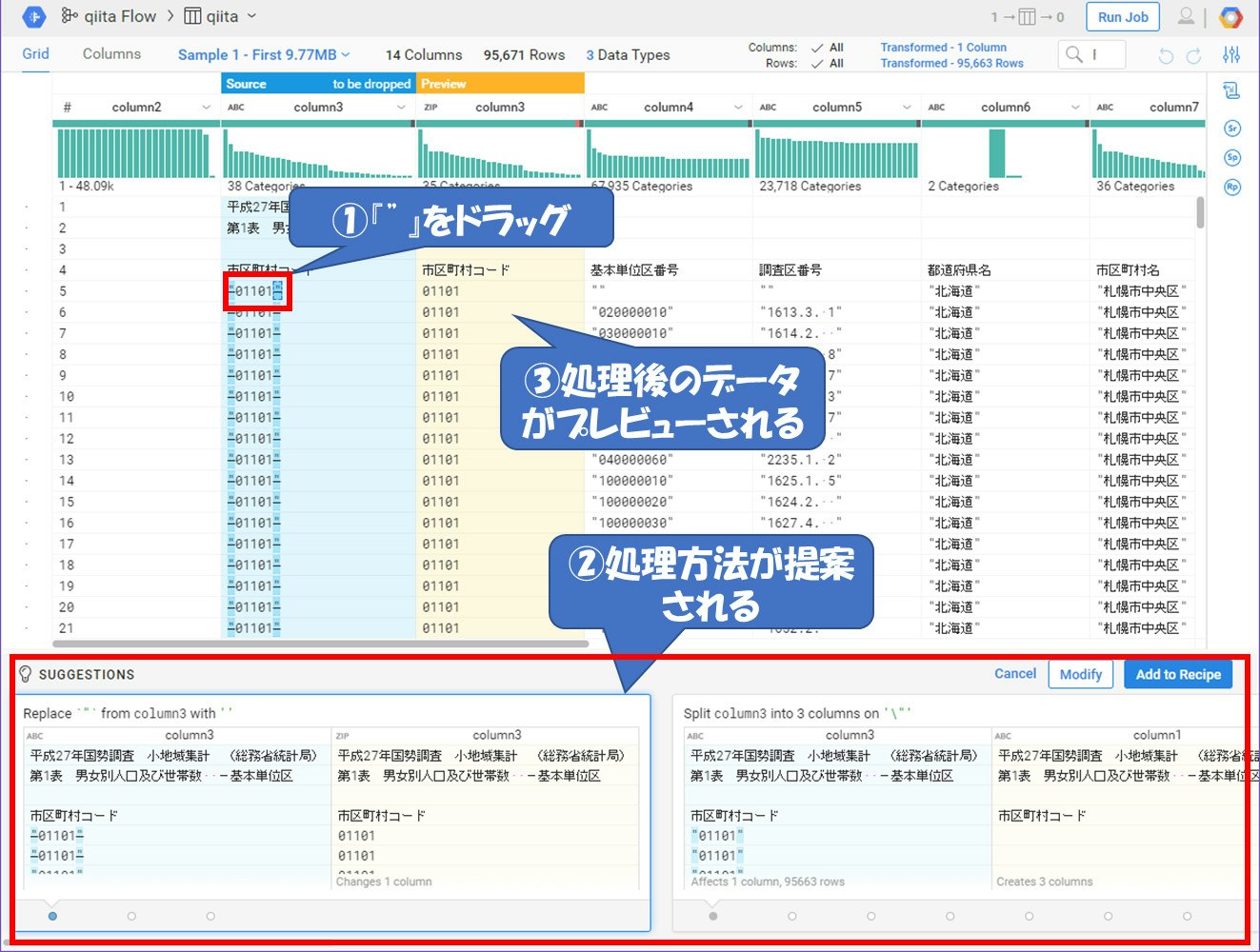
今回は『"』を削除しますので、一番左の処理を選択します。しかし、このままでは選択したカラムだけ処理されてしまいます。このデータ全体に対して処理を適用させたいので、処理の中身をカラム全体に変更したいと思います。画面右下の『Modify』を押下してください。
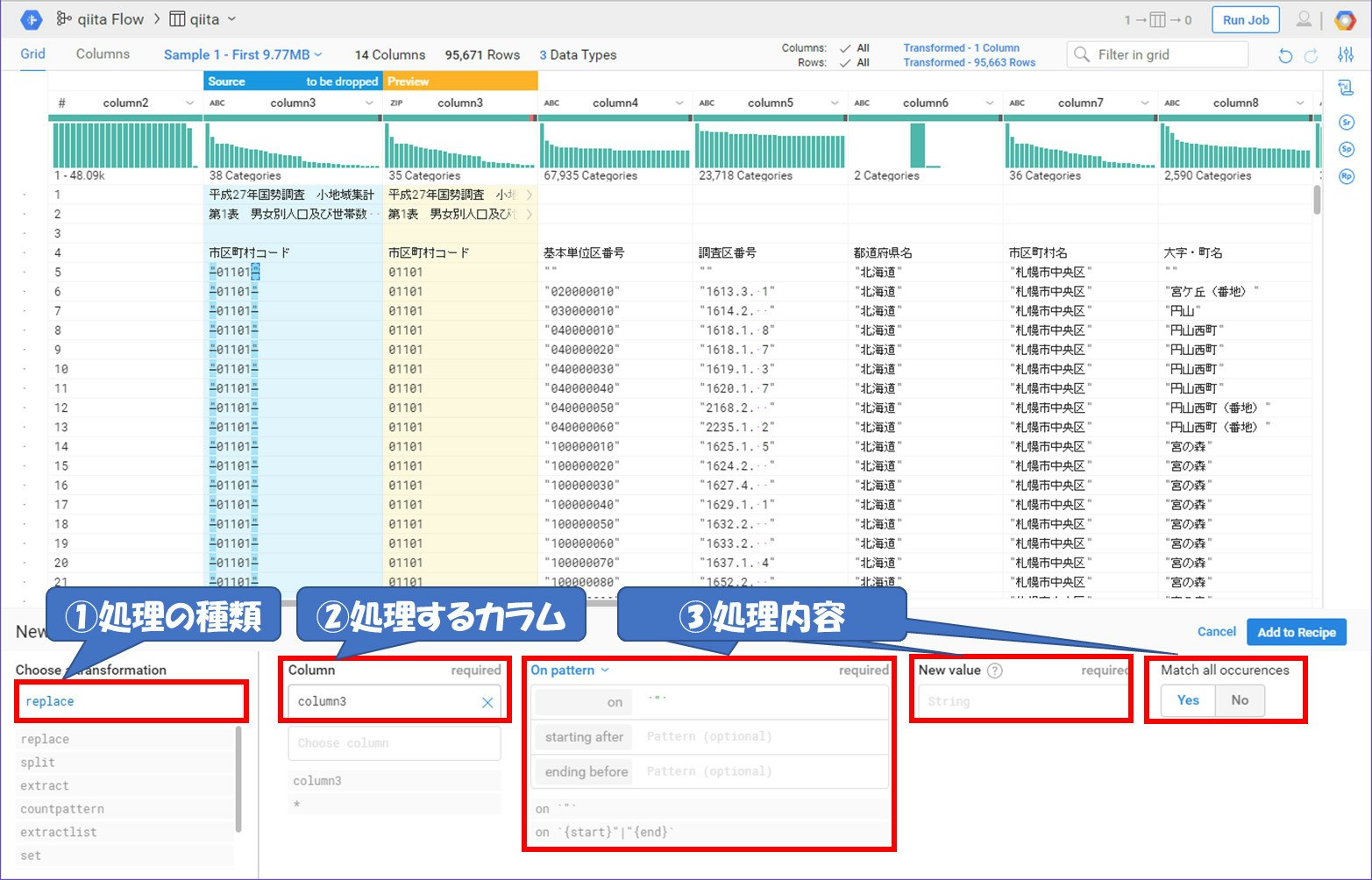
『Modify』を押下すると提案してくれた処理の内容が確認できます。今回は『"』を置換するので処理の種類(①)には『replace』が入っています。そして、全てのデータに適用するので『Column』(②)のところに『*』を入れてください。『New Value』には今回は削除するので何も値をいれません。入力内容を変更するとプレビュー画面もそれに応じて変わります。では『Add to Recipe』を押下して処理を適用させましょう。
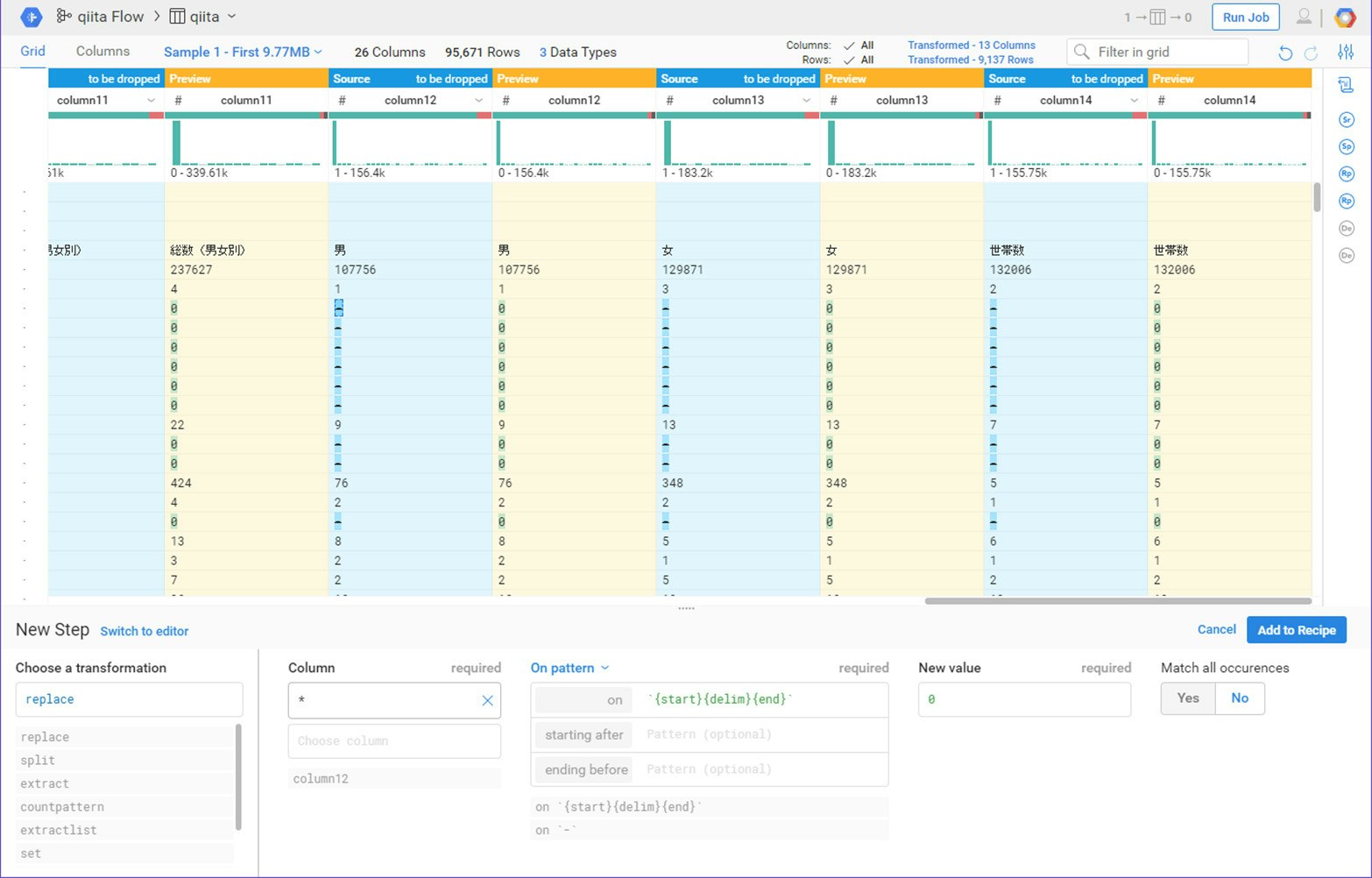
同じような処理をもうひとつ作ります。Column11以降には人口が入っているのですが、数値が0のところに『-』が入っています。このままでは文字列として扱われてしまうので、『-』を『0』に変換するような処理(『New Value』に『0』を入れる)を追加してください。
処理を手書きして必要の無い行を削除する
各ファイルの1~3行目はファイルの説明文が、4行目にはカラム名が入っています。また、今回のデータはありがたいことに行数のところでナンバリングしてくれています。それを利用して削除します。
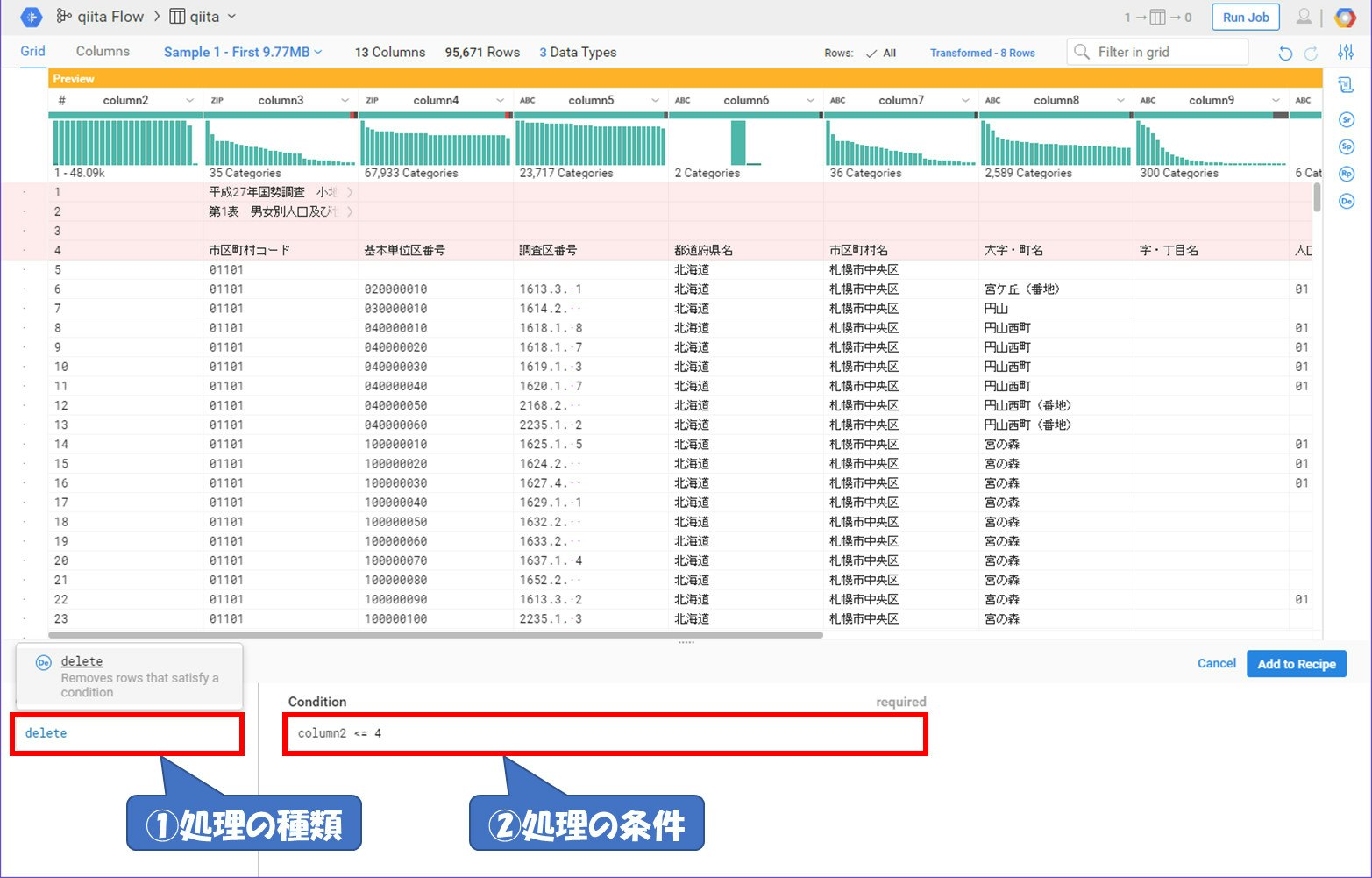
このように自分で処理の方法を書くこともできます。また、①のところのように入力すると補完してくれたりするので非常に楽に処理を書くことが出来ます。この画像は説明文のところを削除しました。では『Add to Recipe』を押下して処理を適用させましょう。
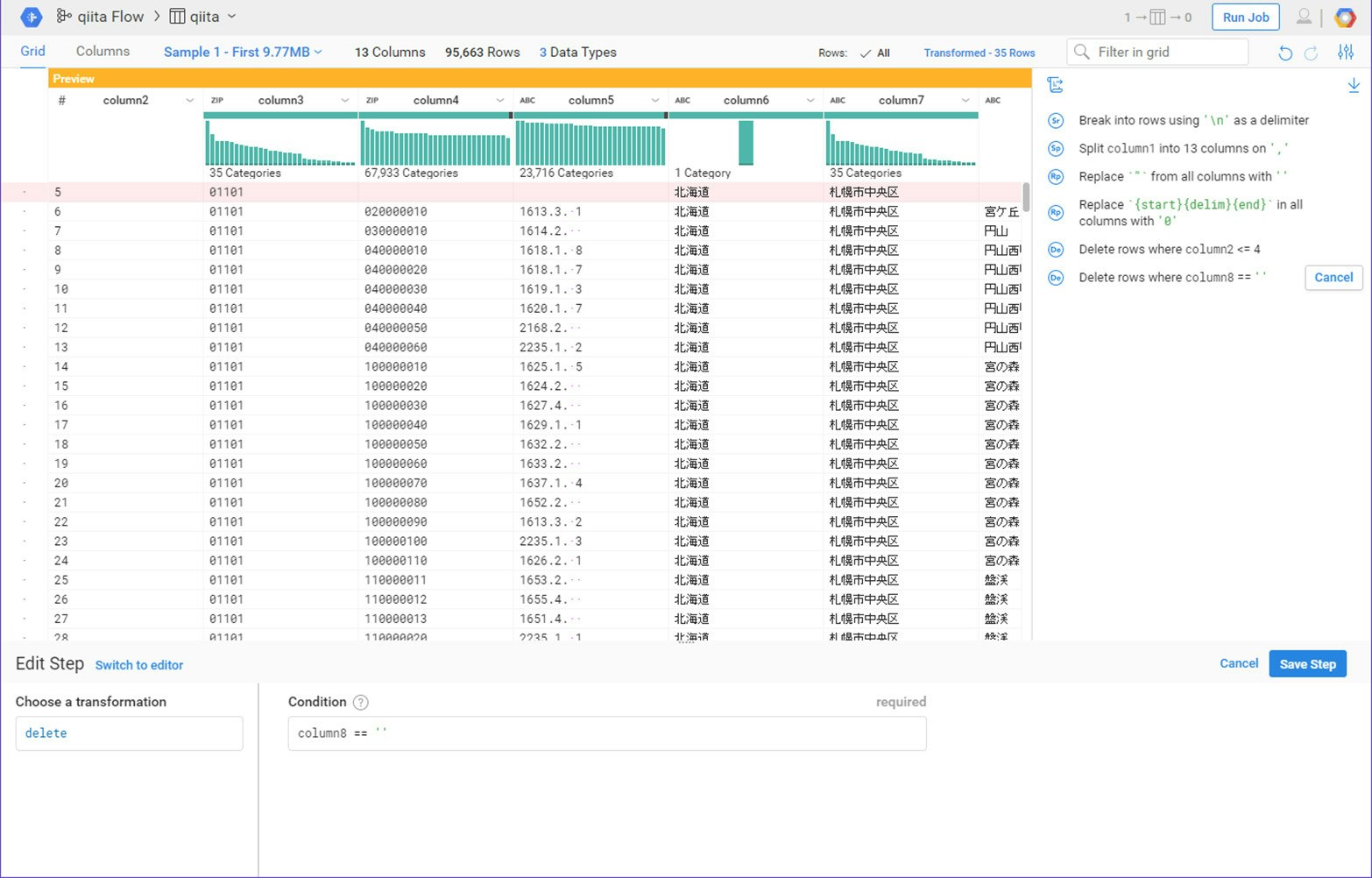
同じような処理をもうひとつ作ります。市区町村名で合算している行があります。これはColumn8に値が入っていない場合の行になります。それを利用して行を削除する処理を追加してください。
列を削除する
Column2やColumn5,Column10はあまり利用する価値のないデータです。今回はこの3つの行を削除します。
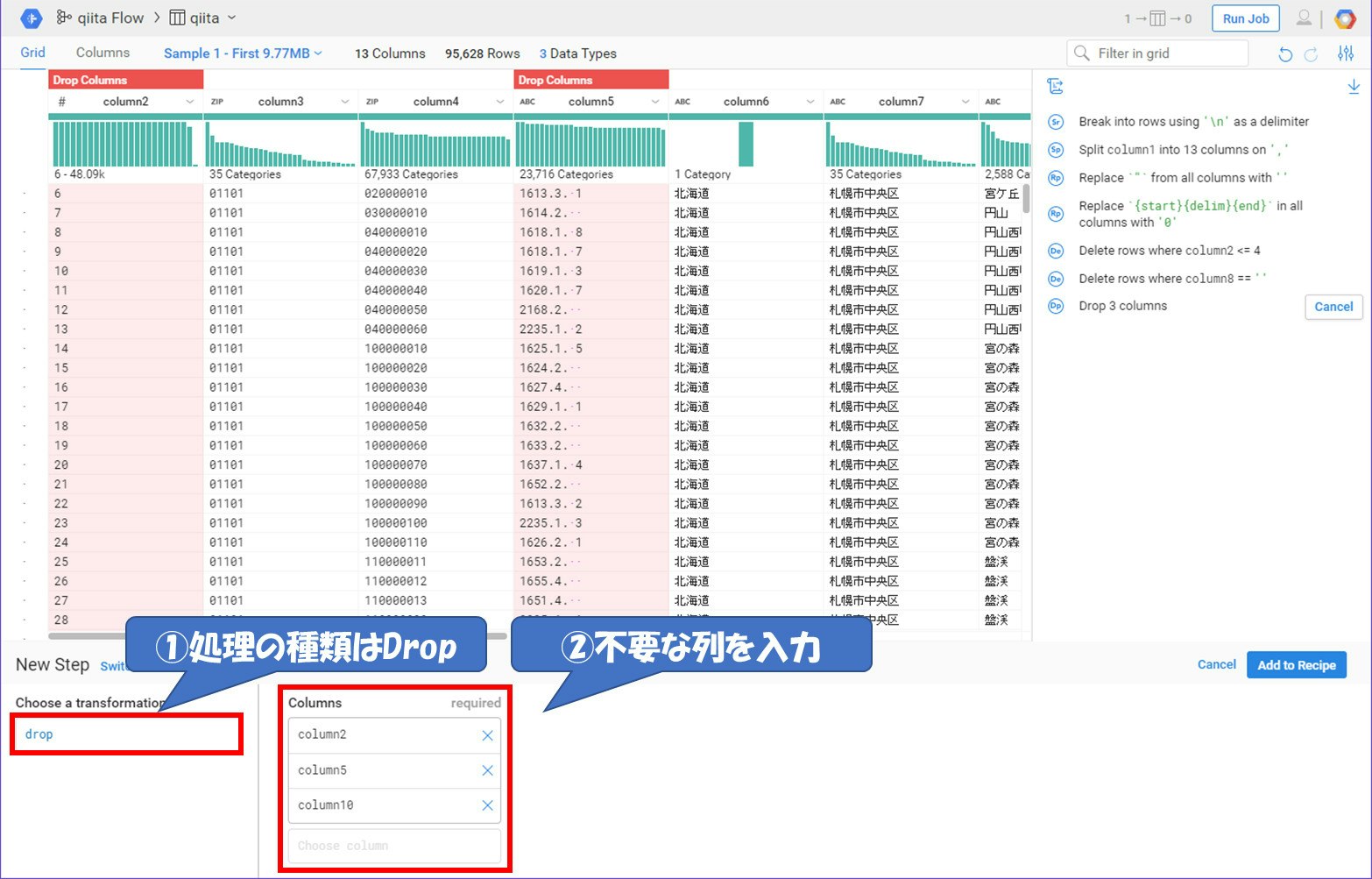
カラム名を変更する
BigQueryにデータを入れる際にカラム名がこのままでは使いづらくなります。各カラム名を変更していきます。
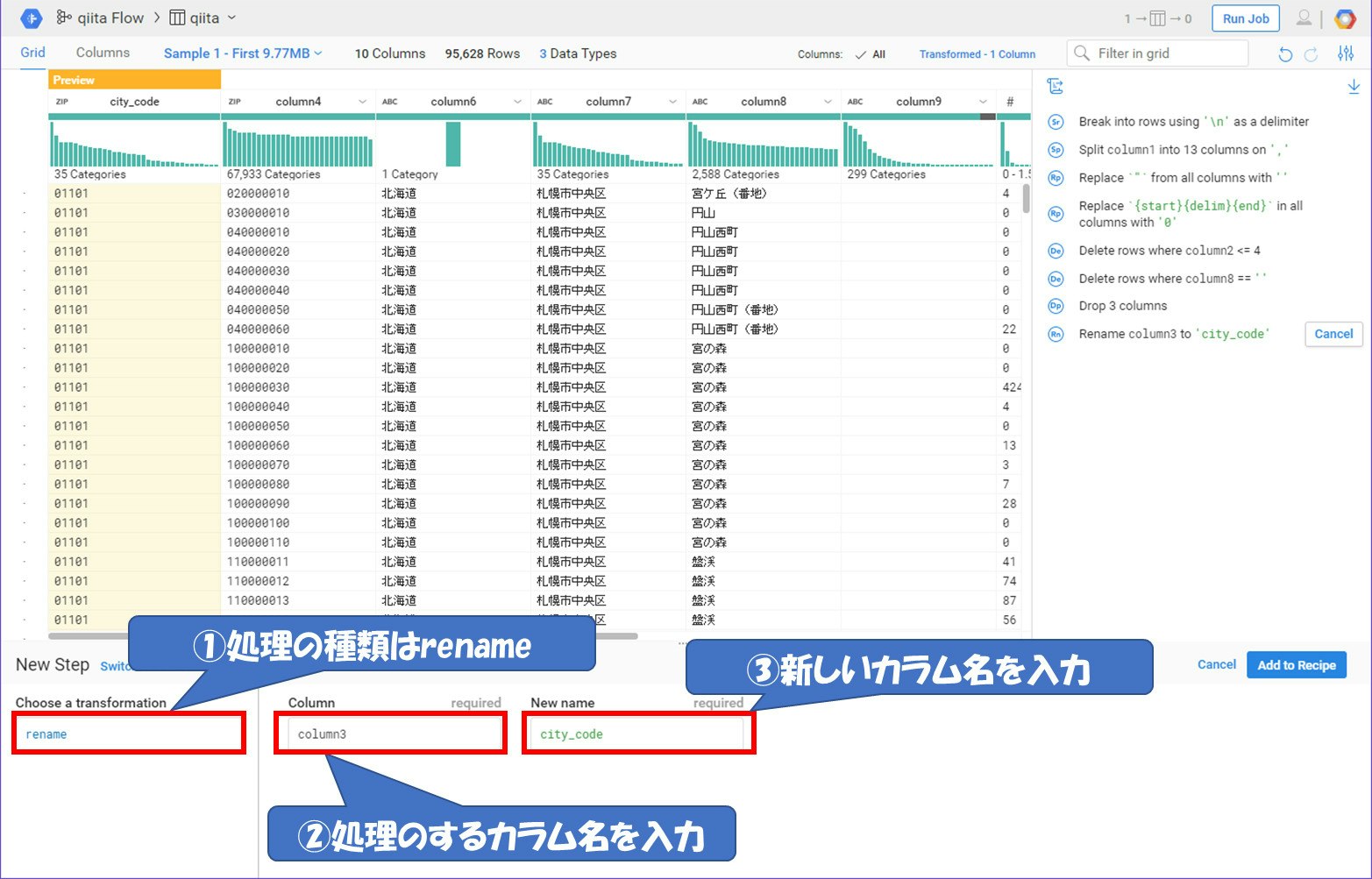
カラム名をすべて変更し、処理内容はこのようになります。
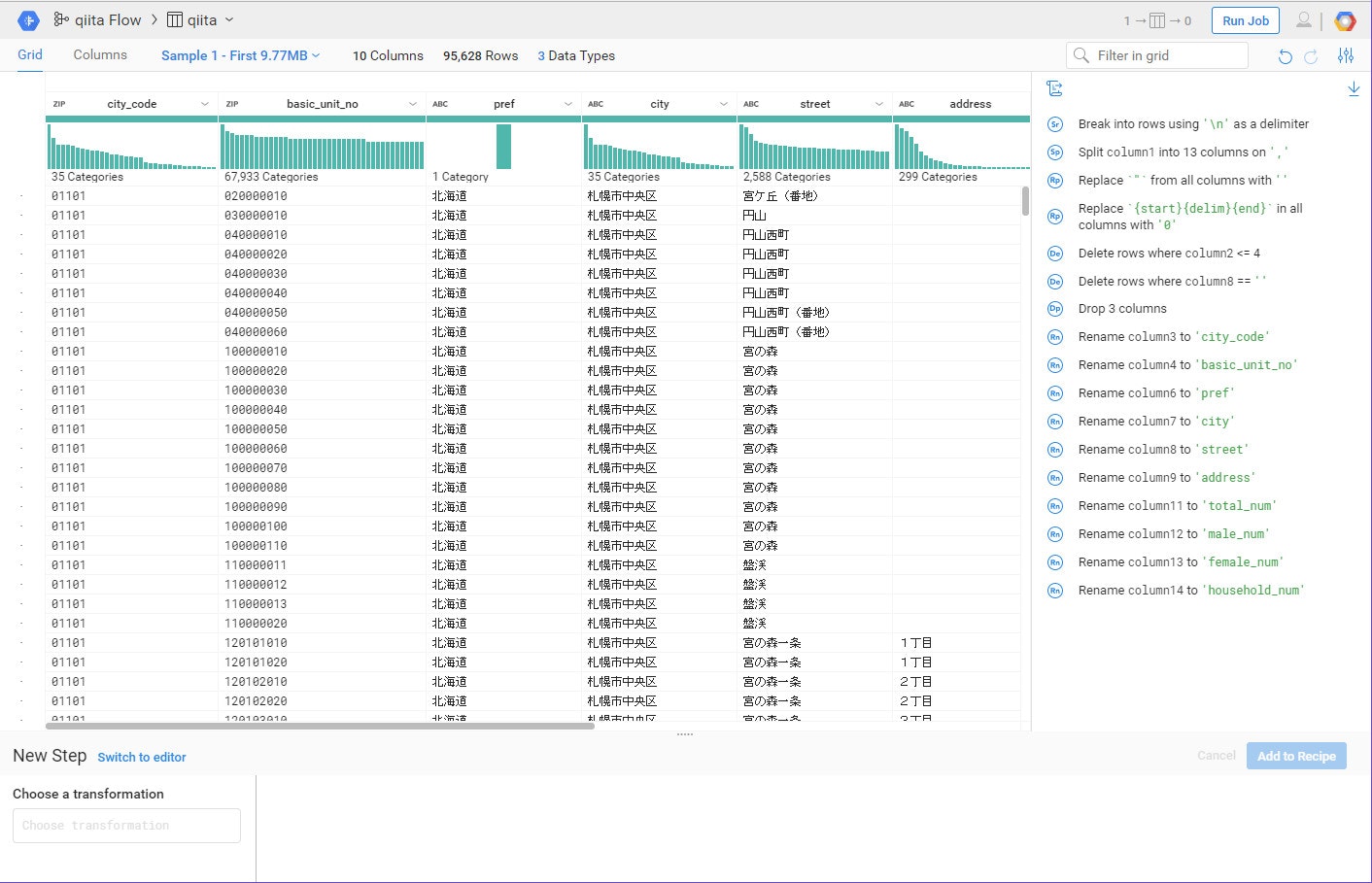
これでデータ処理部分は終了です。右上の『Run Job』を押下して、処理を実行させるところに移動しましょう。
BigQueryにデータを入れる
処理を実行させる画面に移動して出力先をBigQueryに変更します。
出力先を変更する
最初は出力先がCSVになっています。これを編集画面に移動し、BigQueryに変更します。
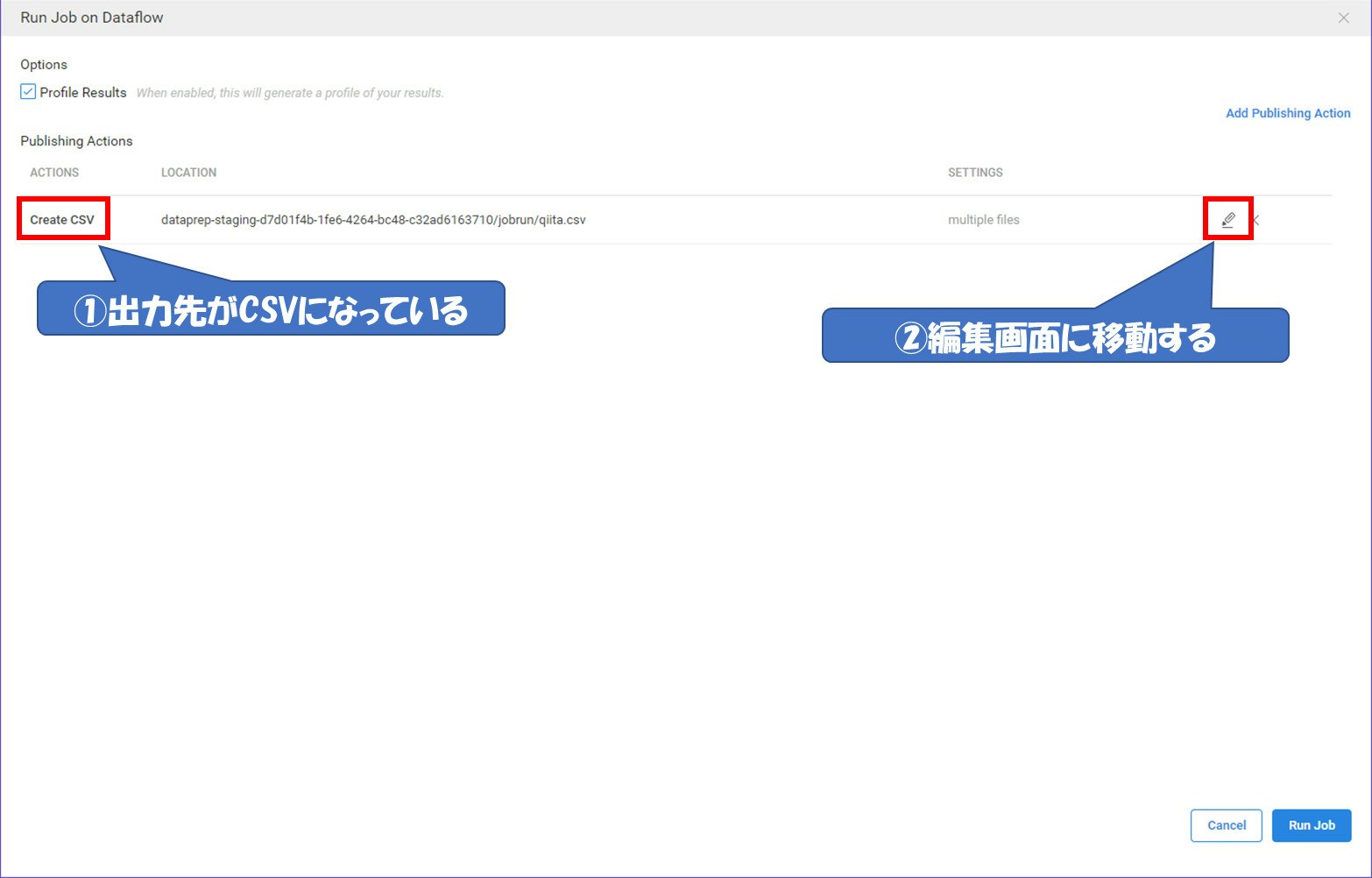
出力先をBigQueryに変更し、出力するDataset、テーブル名、オプションを選択します。
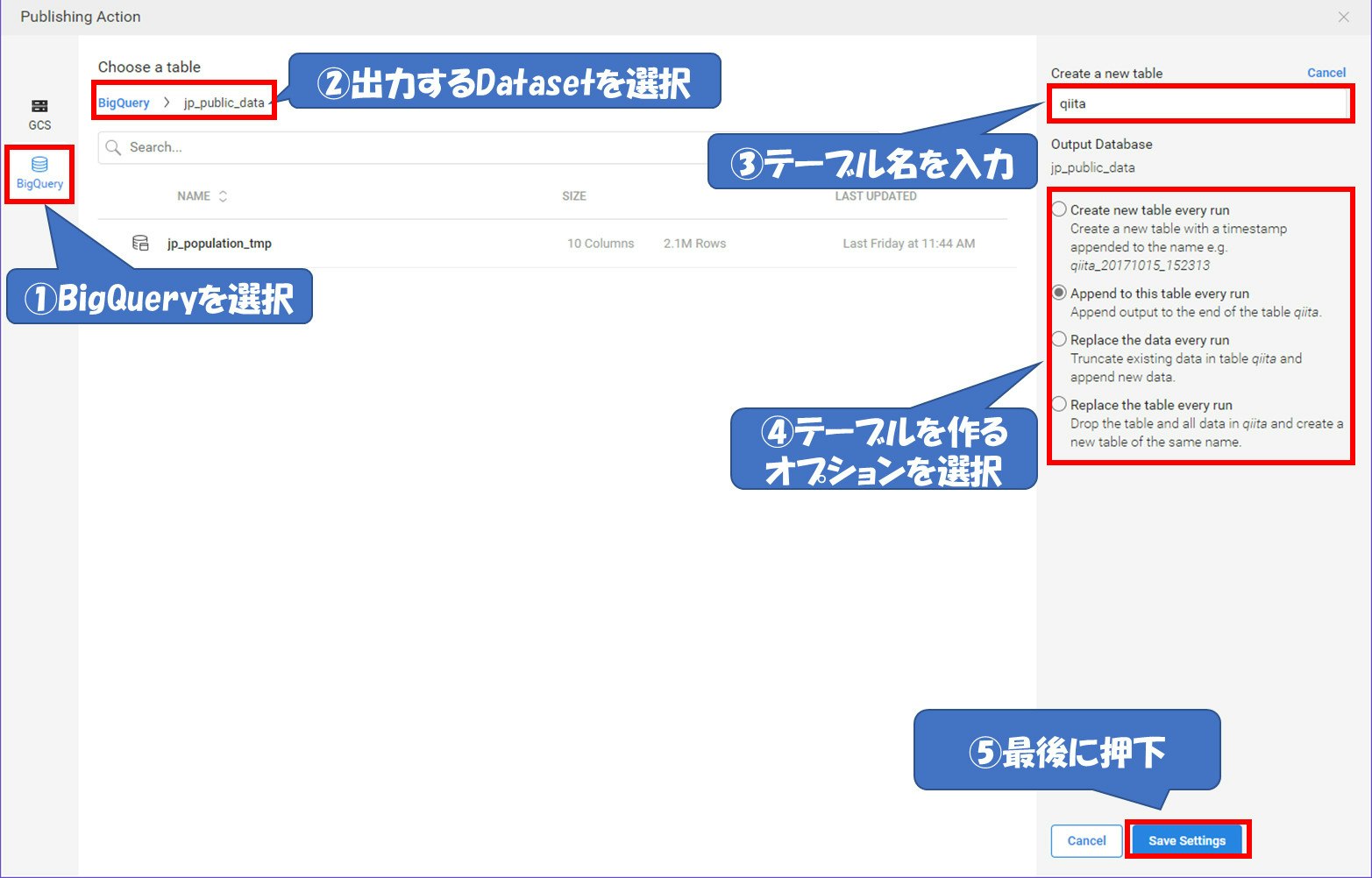
出力先が変更されれば『ACTIONS』のところが『Publish Bigquery』に変更されています。
『Run Job』を押下して処理を実行させます。
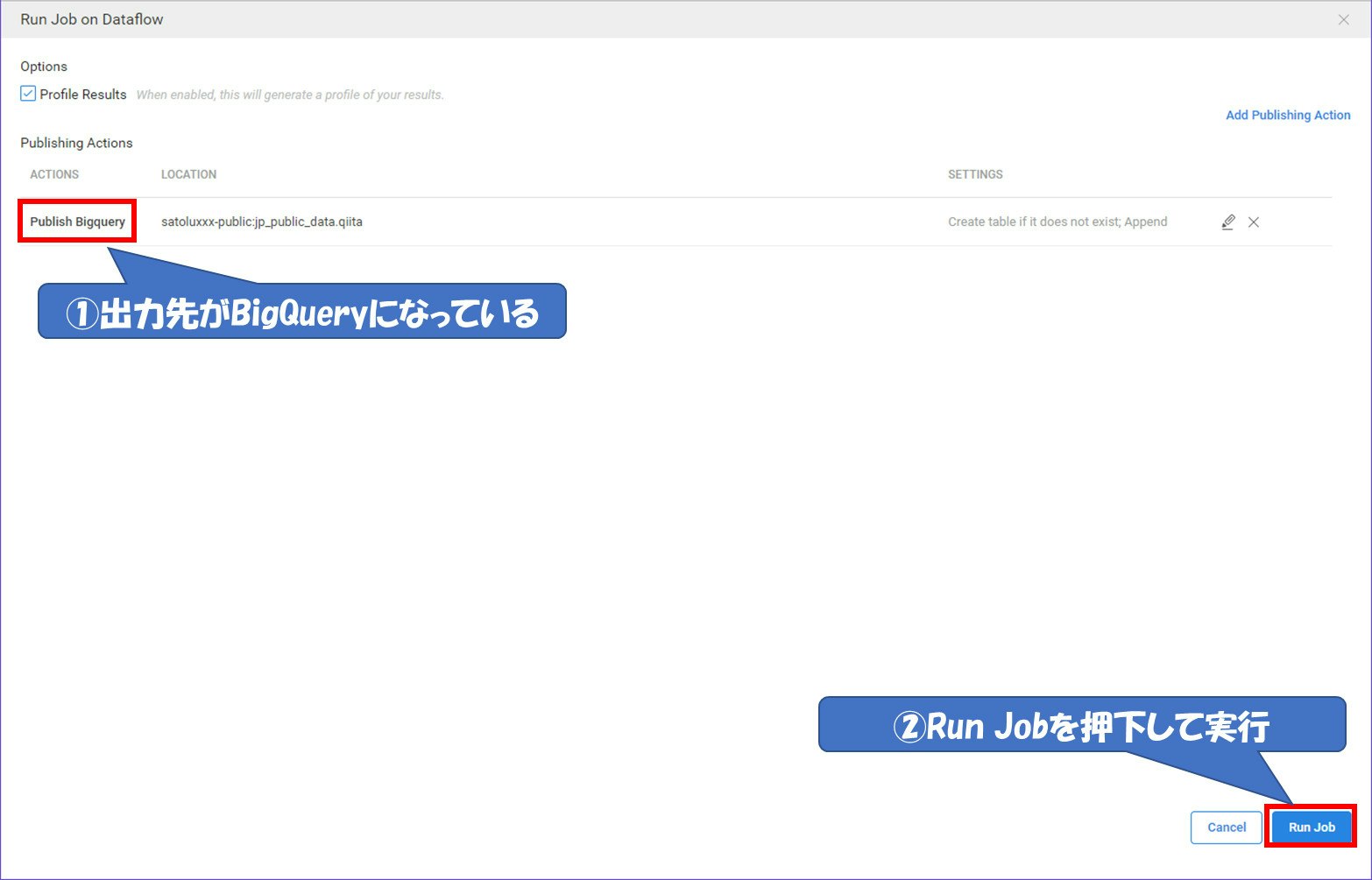
処理を実行する
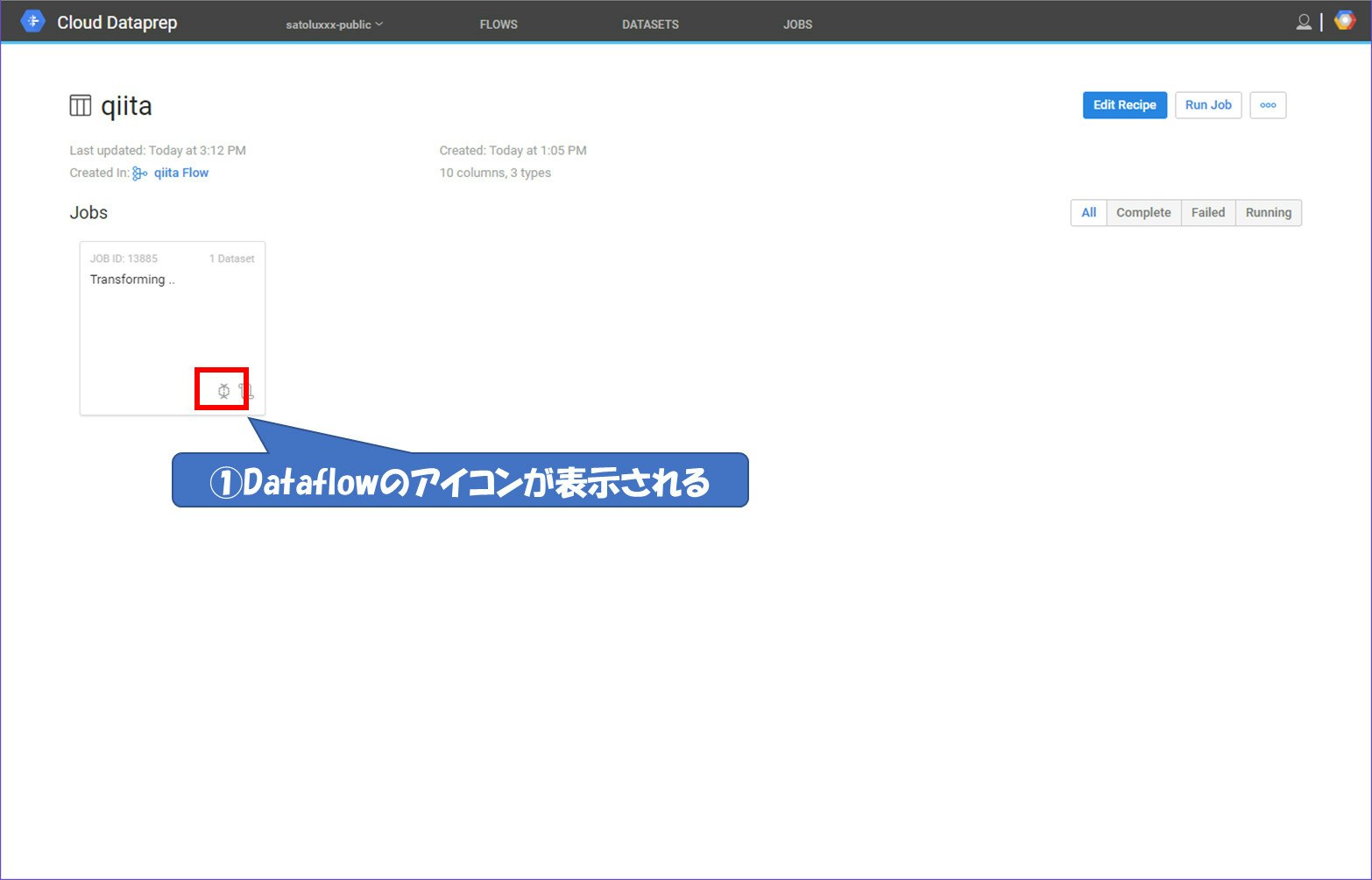
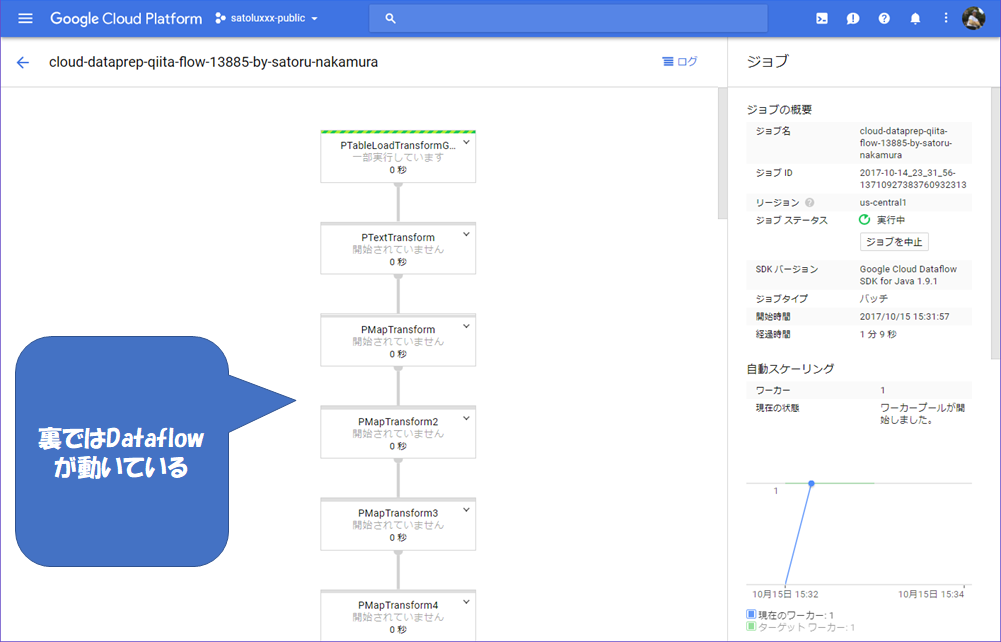
処理を実行すると以下のような画面に遷移します。ジョブのところを見てみるとDataflowのアイコンが表示されます。押下してみるとDataflowが動いているのがわかります。
処理が終了すると、結果画面が表示されます。
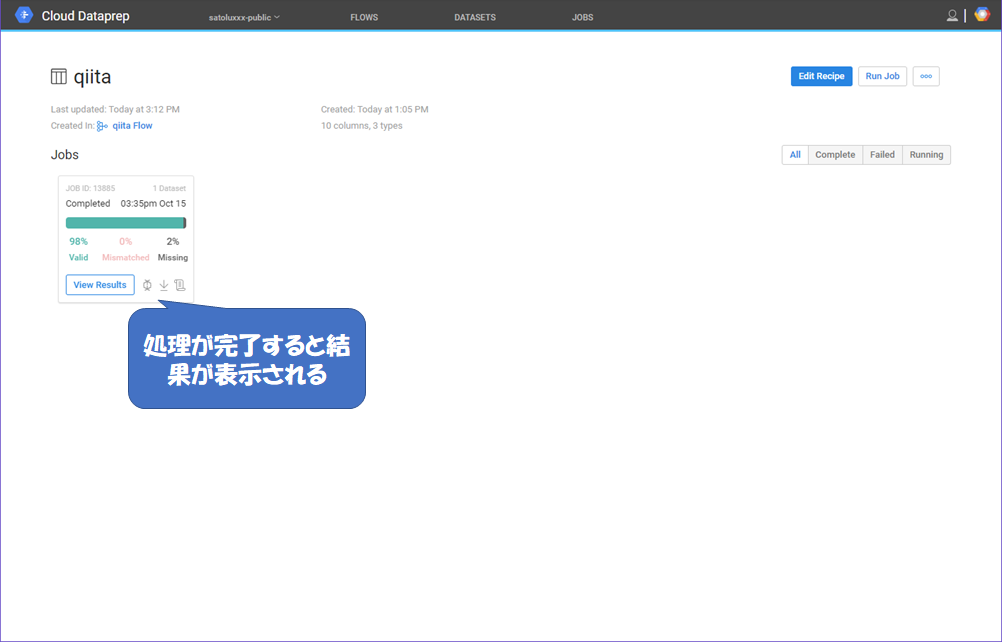
BigQueryを確認してみる
それではBigQuery側を確認してみましょう。
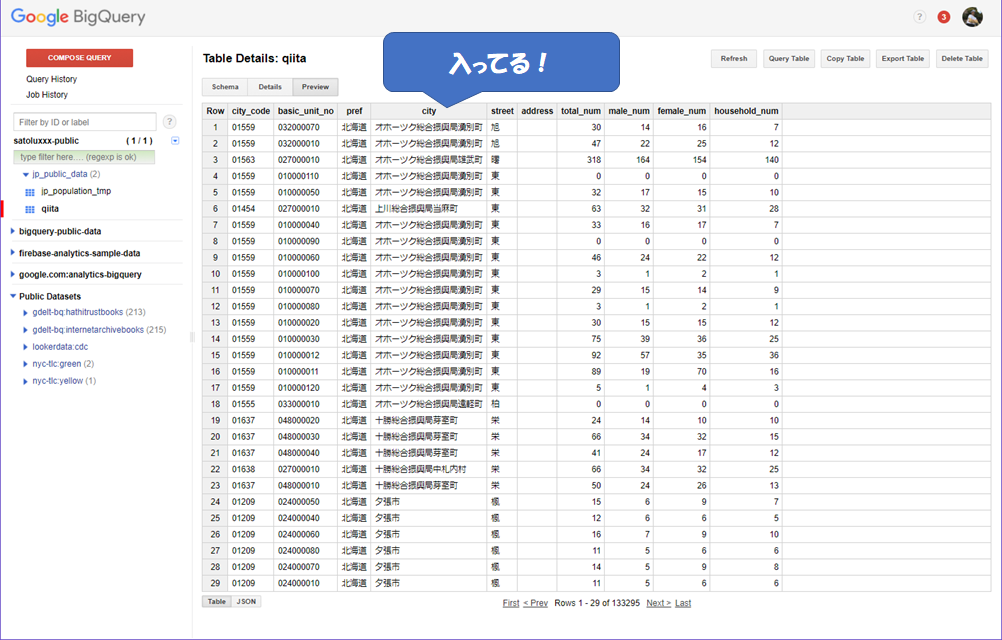
完璧です!!!
最後に①
このようにGUIで気軽にデータを処理することが出来ます。
今回はBigQueryにデータを入れましたが、逆にBigQueryをデータ・ソースとしてMLなどに食わすデータを作ることも簡単に出来ます。
国勢調査のデータのように数年に1回しかやらないとか、とりあえず面白そうなデータを入れてみたいけどデータ整形が面倒で断念していたものもこんなに簡単にやることが出来ます。是非チャレンジしてみてください。
(※GCSやBigQuery、今回のDataprepなどNoOpsでデータを気軽に使える。あぁ、良い世の中になったもんだ。)
最後に②
今後、国勢調査などの公開データをBigQueryに入れていきたいと思います。(趣味w)
このデータセット(satoluxxx-public.jp_public_data)は公開しているので、ちょくちょく見に来てもらえればと思います。10個ぐらいテーブルが出来たら、どこかで一覧を見れるようにしたいと思います。
ただ、あくまで趣味でやるのでそこまで期待しないでください。リクエストがあればコメント欄に記載ください。ベストエフォートで対応したいと思います。もしくは一緒にやりたい!って奇特な方がいらっしゃればご連絡ください!