この記事ではTwitter広告出稿前後におけるRやTwitterAPIの活用方法を検討します。
以前にも似たような記事を書いていますが、 趣味で広告運用する機会があったので一部内容が重複しますが運用を踏まえた上で改めて整理してみます。
目次
1. 事前の設定
2. フォロワーが似ているアカウントターゲティング
3. キーワードターゲティング
4. カスタムオーディエンスの作成
5. 散布図でコストパフォーマンス把握
6. 結果の母比率の信頼区間を可視化
おわりに
1. 事前の設定
事前にMeCabのインストール、パッケージの読み込み、Twitter OAuth Tokenの取得をしておきます。
MeCabのインストール
形態素解析のためにMeCabをインストールします。詳しい手順は以下のサイトを参考にしてください。
https://taku910.github.io/mecab/#install
環境構築が難しい場合にはColaboratoryのNotebookでも利用する形でもよいでしょう。
パッケージの読み込み
今回は以下のRパッケージを使用します。
library(tidyverse) # tidyなデータハンドリング
library(ggrepel) # ggplotのヘルパー
library(ggthemes) # ggplotのヘルパー
library(rtweet) # TwitterAPIラッパー
library(RMeCab) # MeCabラッパー
library(googlesheets4) #GoogleSheetsラッパー
library(wordcloud) ## ワードクラウド
Twitter OAuth Tokenの取得
TwitterAPIを利用するために各種キーをTwitter Developerから取得してOAuthトークンを生成します。
appname <- "app_name"
consumer_key <- "consumer_key"
consumer_secret <- "consumer_secret"
access_token <- "access_token"
access_secret <- "access_secret"
twitter_token <- create_token(
app = appname,
consumer_key = consumer_key,
consumer_secret = consumer_secret,
access_token = access_token,
access_secret = access_secret)
トークンの取得ができれば以下のような形で検索APIを叩くことができます。
search_tweets("ほげほげ") # "ほげほげ"でのツイート検索
search_users("ほげほげ") # "ほげほげ"でのユーザー検索
2. フォロワーが似ているアカウントターゲティング
Twitter広告では「任意のアカウントのフォロワーと似ているアカウント」に対してターゲティングできますが、アカウントを一つ一つ探していたらとても時間がかかってしますし、商材のドメイン知識も必要となります。
そこでTwitterAPIのツイート検索を利用し、アカウント検討の効率化を図ります。
人気のツイートからアカウントを探す
任意のキーワード(aupay)を含むツイートを検索し、その中でリツイートの多いツイート順に並び替えてみます。
tweets <- search_tweets(q = "aupay", n = 3000) %>%
filter(is_retweet == "FALSE") %>%
arrange(desc(retweet_count)) %>%
select(screen_name, text, retweet_count)
以下のような結果となりました。
ローソンやポイ活系のアカウントが上位に浮上しています。
tweets
## # A tibble: 960 × 4
## screen_name status_id text retweet_count
## <chr> <chr> <chr> <int>
## 1 moppy_official 1488452070176804865 "【ぽいかのポイ活情報!!】… 708
## 2 akiko_lawson 1488301092114948101 "/今ならおトクau payで最… 124
## 3 haiji_doctor 1488156873564225536 "#お得な毎日2月1日(火)✅au… 85
## 4 au_official 1488316217471672320 "/3/15(火)まで!『#たぬき… 62
## 5 au_PAY_official 1488791436044607495 "\ #スターバックス × #au… 55
## 6 shinpoi_otoku 1488322639680905216 "きたぞ~~~ダイソー本日〜au… 37
## 7 miho_clover1 1488527811602169872 "10分だけください。肩コリ… 32
## 8 ktai_watch 1488354541070581761 "au pay、全国の「daiso/ダ… 31
## 9 dhy213 1488095989114146816 "【2022.02月】aupay・d払い… 30
## 10 chukenDr 1488319281641111558 "ダイソー、楽天pay対応キタ… 28
## # … with 950 more rows
フォロワー数の多いアカウントを探す
任意のキーワード(aupay)を含むツイートを検索し、その中でフォロワー数の多いアカウント順に並び替えてみます。
tweets <- search_tweets(q = "aupay", n = 3000) %>%
distinct(text, .keep_all = TRUE) %>%
users_data() %>%
distinct(user_id, .keep_all = TRUE) %>%
arrange(desc(followers_count)) %>%
select(screen_name, description, followers_count)
前述の結果と同様に、やはりポイ活系アカウントが多いようにみえます。
tweets
## # A tibble: 20 × 3
## screen_name description followers_count
## <chr> <chr> <int>
## 1 shizushin "ふるさとメディア「あなたの静岡新聞」から更… 108583
## 2 au_support "au公式のお客様サポートアカウントです。商品… 87412
## 3 haiji_doctor "お得情報を分かりやすく丁寧に発信。ポイ活数… 53960
## 4 MURA_mal "【お🉐情報活用×投資=FIREへの道を発信中📡】… 23005
## 5 CharlotteClarls "基本ライブ配信視聴。コレコレ、P丸様。、Cateen、… 16729
## 6 setusoku "節約速報:携帯一括キャッシュバック情報、乞… 16547
## 7 ruru_ruruman "💗息子LOVE💗食べる事大好き😋🍽ゴルフ⛳️懸賞🎯… 12170
## 8 keeping_safety "投資ブログを運営しています。米国・日本株へ… 10385
## 9 tomor1nn "お得情報を分かりやすく発信/図解投稿/paypay… 8393
## 10 tomicagogo "Sister blog https://t.co/O8f1VhXx4M https:/… 7366
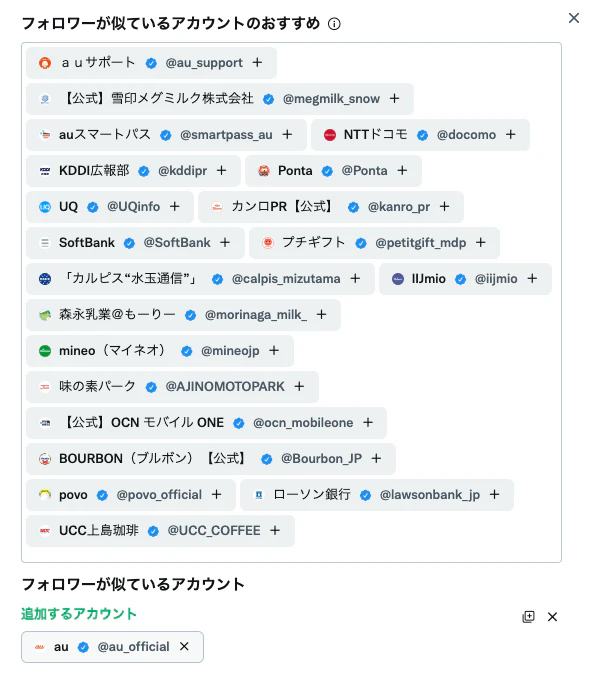
管理画面でのフォロワー探索
Twitter広告のキャンペーン作成画面から「任意のアカウントと類似しているアカウント」を選択することも可能です。
3. キーワードターゲティング
Twitter広告は任意のキーワードを呟いている人に出稿できる「キーワードターゲティング」があり、ユーザーのコンテクストに合わせた広告出稿が可能です。
コンテクストを持たせたターゲティングとして「黒にんにく」の例は有名です。
黒にんにくを売ろうとしている企業は、「にんにく」とツイートしている人に売ろうと考えてしまうかもしれませんが、黒にんにくが必要なのは疲れているときですよね。疲れた人が「疲れた」と言う媒体はSNSでもTwitterくらいですから、このようなマッチングが可能なんです。
商材に関係するキーワードの文脈を考えた上でターゲティングすることで、コンテクストに沿った広告マッチングが可能になるというわけです。
というわけで、ここからはキーワードとコンテクストの検討をします。
形態素解析
任意のキーワード(aupay)が含まれるツイートを検索し、そのツイート文を分解し頻出するキーワードを検索してみます。
形態素解析の説明は省略しますが、形態素解析エンジンのMeCabを利用し文章を単語ごとに分かち書きしていきます。
前処理
ツイート本文はそのままでは分析に適さないので前処理を施します。
具体的にはリツイートを除外、URL文字列や改行、絵文字を削除、大文字を小文字に変換します。bot等の重複投稿を除外するためにもツイート本文やスクリーンネームの重複を排除します。
fix_tweets <- tweets %>%
filter(is_retweet == "FALSE")%>%
select(screen_name, status_id, text, retweet_count) %>%
mutate(text = str_remove_all(text, regex(pattern = "http(s)?://([\\w-]+\\.)+[\\w-]+(/[\\w- ./?%&=]*)?"))) %>%
mutate(text = str_remove_all(text, regex(pattern = "\n",))) %>%
mutate(text = str_remove_all(text, regex(pattern = '[:emoji:]'))) %>%
mutate(text = str_to_lower(text)) %>%
distinct(text, .keep_all = TRUE) %>%
distinct(screen_name, .keep_all = TRUE)
MeCabで分かち書き
docDF()にツイート本文を渡し、単語n-gram(1-gram)として分解します。
tweet_ngram <- docDF(fix_tweets, col = "text", type = 1, N = 1)
キーワードごとの件数を可視化
分解された単語の数をカウントして、降順に並び替えます。
tweet_freq <- tweet_ngram %>%
mutate(freq = rowSums(.[4:ncol(tweet_ngram)])) %>%
select(TERM, POS1, POS2, freq) %>%
group_by(TERM) %>%
mutate(freq = sum(freq)) %>%
distinct(TERM, .keep_all = TRUE) %>%
filter(TERM != "auPAY", TERM != "au PAY") %>%
filter(POS1 == "名詞") %>%
filter(POS2 != "非自立", POS2 != "接尾", POS2 != "数", POS2 != "サ変接続") %>%
arrange(desc(freq))
「aupay」というキーワードは「ポイント」「paypay」「au」「マーケット」「カード」という文字が同時に含まれることが多いようです。
tweet_freq
## # A tibble: 2,199 × 4
## # Groups: TERM [2,199]
## TERM POS1 POS2 freq
## <chr> <chr> <chr> <dbl>
## 1 ポイント 名詞 一般 142
## 2 paypay 名詞 一般 91
## 3 au 名詞 固有名詞 80
## 4 マーケット 名詞 一般 72
## 5 カード 名詞 一般 70
## 6 キャンペーン 名詞 一般 56
## 7 Ponta 名詞 固有名詞 54
## 8 クーポン 名詞 一般 48
## 9 支払い 名詞 一般 47
## 10 au pay 名詞 一般 41
## # … with 2,189 more rows
ワードクラウドで可視化
視覚的に分かりやすなるようにワードクラウドで可視化します。
wordcloud(
tweet_freq$TERM,
tweet_freq$freq,
min.freq = 4,
color = brewer.pal(8, "Dark2"),
family = "HiraKakuPro-W3",
random.order = FALSE
)
各キーワードの相対的な出現頻度の把握が容易になりました。ワードクラウドにすることで一覧性も高くなりますね。

※ターゲティングの範囲について
Twitter広告のRTBは機械学習によって最適化されるため一定の広い範囲で学習させる必要があり、「ターゲティングは極端に狭めない方が良い」そうです。ターゲットの設定には100以上の対象があった方が良いとのことで、やはり一つ一つ手動で検討するのは限界があるため自動化の必要性がありそうです。
4. カスタムオーディエンスの作成
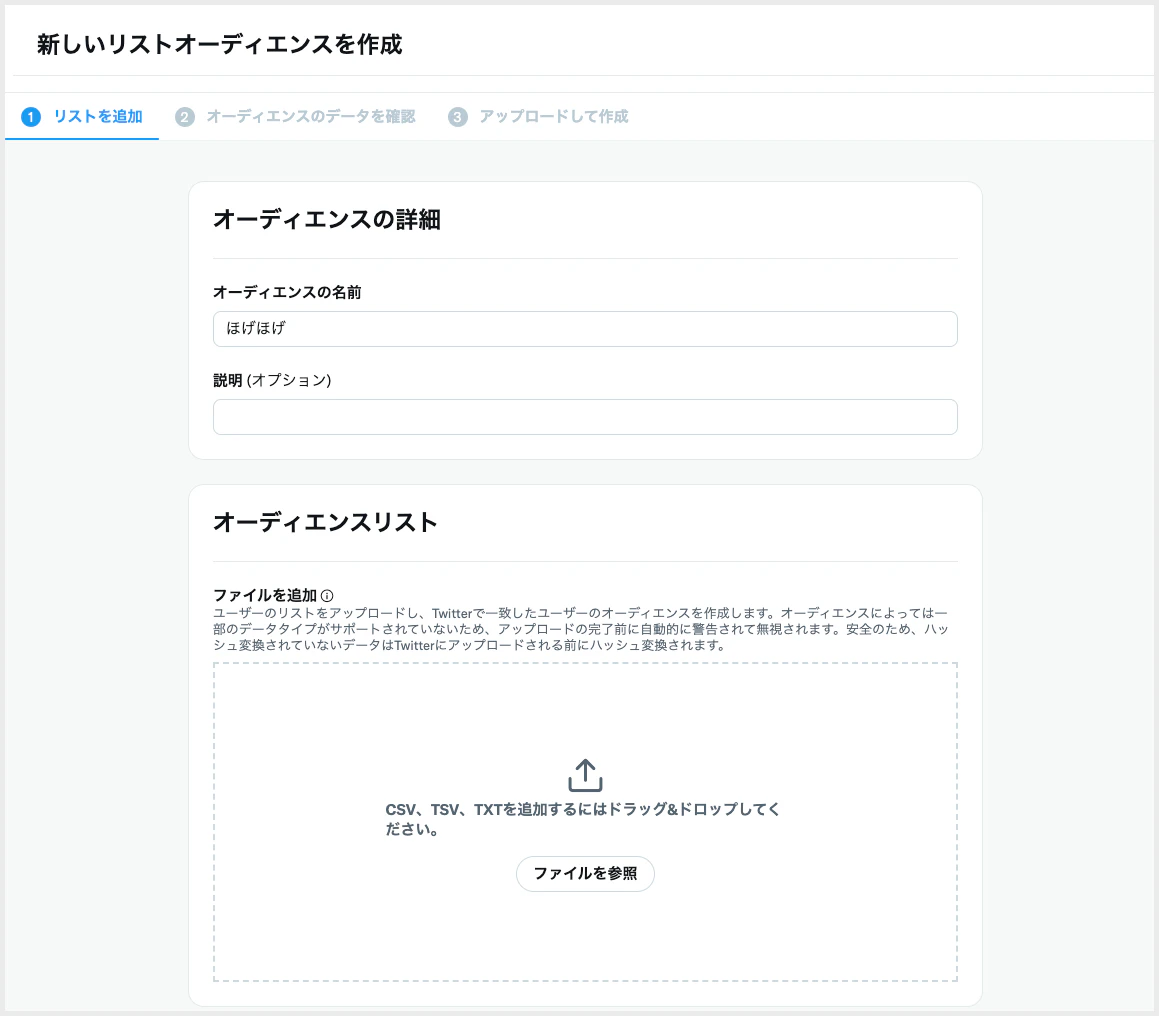
任意のTwitterアカウントの一覧があれば、カスタムオーディエンスとしてターゲティング利用することが可能です。
※最低でも300〜500程度のアカウント数が必要になります。
手順としてはアカウントのリストをカンマ区切りのCSVファイルとして作成し、広告マネージャーでアップロードする流れとなります。
CSVファイルの書き出し
2. フォロワーが似ているアカウントターゲティングのデータフレームを利用するとしたら以下のようになります。
スクリーン名をselect()して t()で転置行列を作成、さらにdataframe変換してwrite_csv()を実行しています。
tweets %>%
select(screen_name) %>%
t() %>%
as.data.frame() %>%
write_csv("./users.csv", col_names = FALSE)
Twitter側でオーディエンスを作成
書き出したCSVファイルを広告マネージャーにアップロードします。
オーディエンスサイズやファイル形式に問題がなければ48時間以内に「準備完了」と表示され、広告グループのカスタムオーディエンスで利用可能となります。
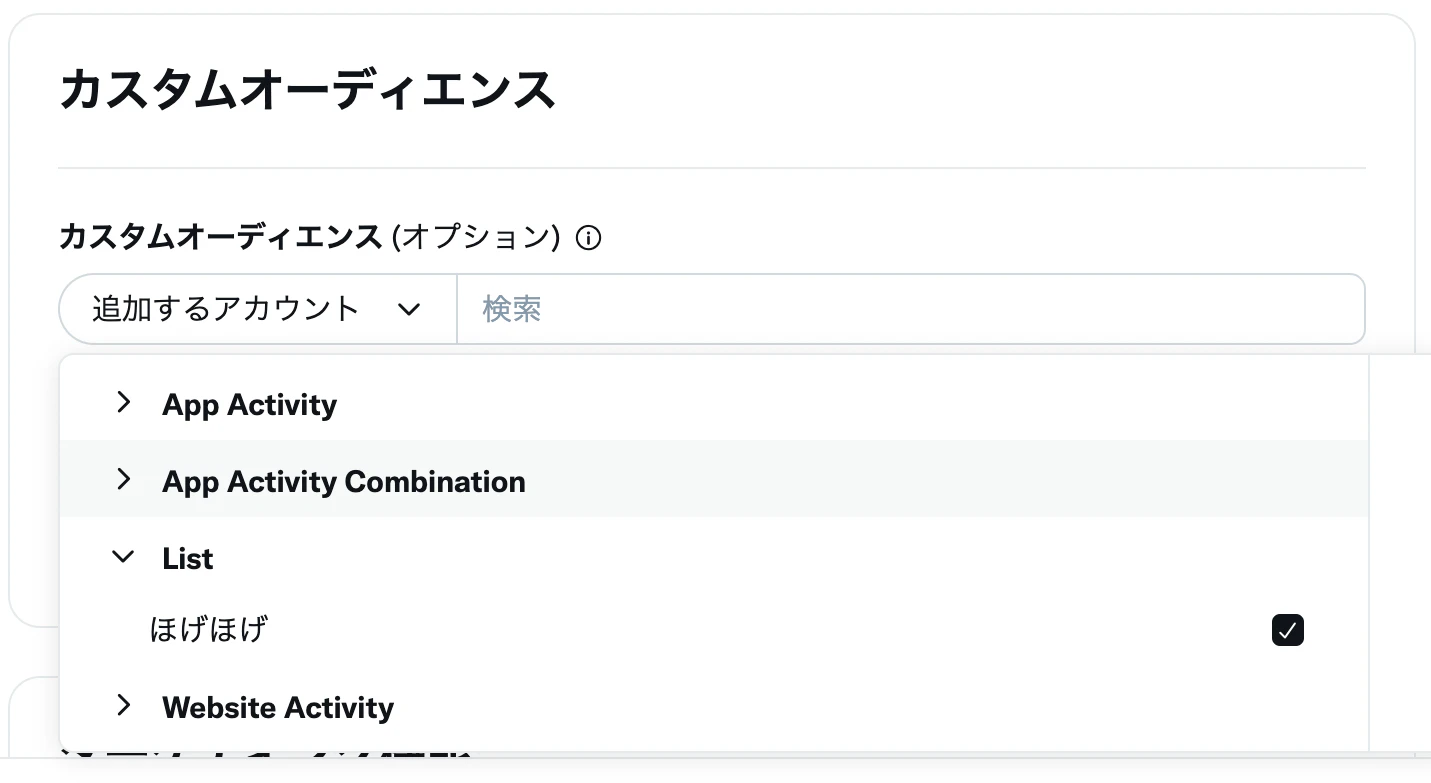
オーディエンスの利用
カスタムオーディエンスのListから今回作成したリストオーディエンスを選択します。
なお、数百というアカウントを用意したところでターゲットは狭くリーチしませんので、カスタムオーディエンスでのリスト利用はあくまで「出稿の目的に応じて」 だとは思います。
5. 散布図でコストパフォーマンス把握
個々のターゲティングの相対的な関係性を散布図と回帰直線で可視化します。
広告マネージャーからCSVファイルをダウンロード
まずは広告マネージャー側から任意のキャンペーンデータをエクスポートします。
xlsxファイルがダウンロードされるのでGoogleSpreadSheetにアップロードしておきます。
SpreadSheetから読み込み
googlesheets4パッケージのread_sheet()を使って、スプレッドシートに接続しデータフレームを作成します。
df_raw <- read_sheet("https://docs.google.com/spreadsheets/d/~~~") %>%
rename(cost = "ご利用金額", engagement = "結果", keyword = "キーワード") %>%
select(keyword, cost, engagement)
散布図の可視化
ggplotのstat_smooth()でmethod=lmを指定し線形回帰の回帰直線を表示させます。またse(standard error)オプションでは標準誤差(95%信頼区間)を表示させることもできます。
geom_text_repel()はgeom_point()の各点に対してテキストやラベルを付与することができます。
ggplot(df_raw, aes(x = cost, y = engagement, label = keyword)) +
geom_point() +
stat_smooth(method = "lm", se = TRUE) +
geom_text_repel(family = "HiraKakuPro-W3")
以下のような形でキーワードごとのボリューム感と相対的なパフォーマンスを可視化できました。
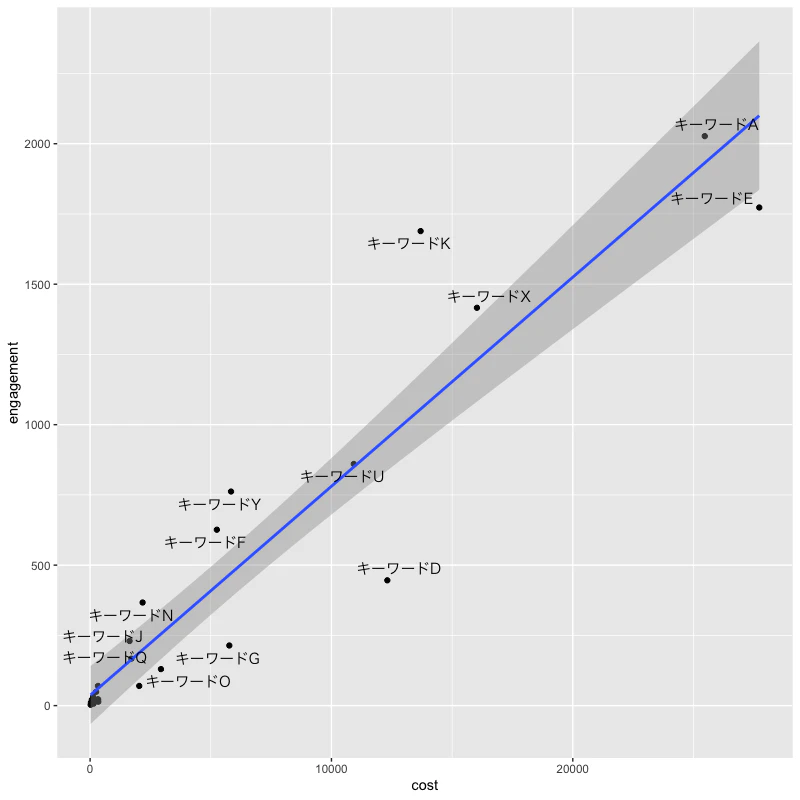
この例ではX軸を「広告費」、Y軸を「獲得したエンゲージメント」としています。
「広告費と広告の反応数は一定の線形関係にあるはず」と仮定すると、各キーワードは以下のような相対評価ができそうです。
- キーワードDは回帰直線よりも下側に離れておりコストパフォーマンスが悪そう
- キーワードKは回帰直線よりも上側に離れているためコストパフォーマンスが高そう。また、配信量は比較的多かった。
またキーワードA、キーワードEは配信量が特に多かったようです。
※ここではエンゲージメントの獲得を目的とした広告キャンペーン(CPE)を例にしています。
6. 結果の母比率の信頼区間を可視化
複数のターゲティングの有意差を比較するために、エラーバーで母比率の信頼区間(標準誤差)を可視化してみます。
データフレームの作成
qbinom()で任意の分位点を指定できるので、下限2.5%点と上限2.5%点における比率を計算します。
rate_by_keyword <- df_raw %>%
mutate(rate = engagement / impression) %>%
mutate(lower = qbinom(0.025, impression, rate) / impression) %>%
mutate(upper = qbinom(0.975, impression, rate) / impression) %>%
head()
rate列とlower列、upper列が追加されました。
rate_by_keyword
## # A tibble: 6 × 6
## keyword engagement impression rate lower upper
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 キーワードA 2027 56780 0.0357 0.0342 0.0372
## 2 キーワードB 70 608 0.115 0.0905 0.141
## 3 キーワードC 22 492 0.0447 0.0264 0.0630
## 4 キーワードD 446 43772 0.0102 0.00925 0.0111
## 5 キーワードE 1773 62069 0.0286 0.0273 0.0299
## 6 キーワードF 626 13830 0.0453 0.0419 0.0487
エラーバーの描画
ggplotではgeom_pointrange()でエラーバーを描画することができます。
ggplot(rate_by_keyword, aes(x = keyword, y = rate)) +
geom_line() +
geom_pointrange(aes(ymin = lower, ymax = upper, colour = keyword)) +
theme_gray(base_family = "HiraKakuPro-W3") +
scale_colour_tableau() +
scale_x_discrete(labels = NULL, breaks = NULL)
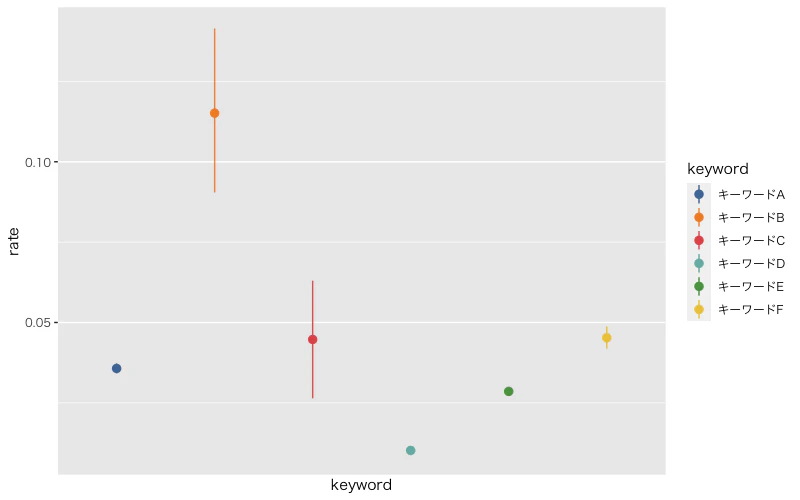
キーワードBは信頼区間は広いものの、他のキーワードと比べると有意に数値(エンゲージメント率)が高そうです。
キーワードCは信頼区間が広く、キーワードA,E,Fとの差は誤差の範囲かもしれません。
おわりに
予算が潤沢にあり予算消化が優先される場合にはターゲティングや分析の必要性は低いかもしれませんが、限られたわずかな予算で広告効果最大化が求められる場合には、今回紹介したような方法で運用の最適化を図ると良いと思います。
工夫次第でTwitter広告は低単価で高い効果を出すことができそうですし、データ分析担当が広告運用まで幅を広げてみると新しい気付きが得られるかもしれません。
参考URL